How to migrate only some pages?
Note
When talking about pages, this also means blog posts and the new cloud content types like whiteboards. A more common term would be content, but that does sound a bit generic and would also cover attachments. So let’s keep it at pages where it fits.With WikiTraccs, selecting pages for migration is always done in the Confluence Space Inventory list (short: space inventory).
The space inventory contains source selectors that tell WikiTraccs which pages to migrate.
In this blog post we’ll look at one specific source selector type that allows to select single pages for migration: the Content ID selector.
Note
Learn more about all available content selectors here: Confluence Space Inventory / Selectors.How to tell WikiTraccs which pages to migrate, by content ID
Everything in Confluence - pages, blog posts, attachments, comments, you name it - has an ID: the content ID.
For now, let’s assume you already have a list of content IDs you want to migrate (We’ll look at how to get those IDs in the next section). You would mark them for migration by creating a new source selector in the space inventory, like this:
- open the space inventory (note: this is a SharePoint list and can be used as such)
- add a new item
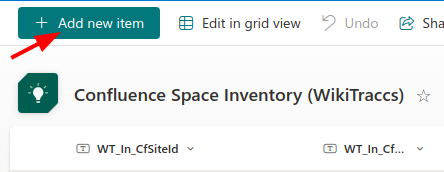
- enter the following data for the newly created item:
| Field | Sample Value | Remarks |
|---|---|---|
| Title | notused | the title is ignored, but is a mandatory field; enter anything here |
| WT_In_SiteId | https://CHANGEME.atlassian.net/wiki | enter your Confluence base URL; look at the other items in the space inventory and copy it from there |
| WT_Setting_RequestTransformation | Yes | mark the selector for migration |
| WT_Setting_TargetSiteRootUrl | https://contoso.sharepoint.com/sites/target | enter the target SharePoint site here |
| WT_Setting_ContentSelectorValue | 123456789;#page,987654321;#blogpost | this list of ID-type combinations tells WikiTraccs what to migrate; each value consists of the content ID (like 123456789) followed by the content type (page, blogpost, whiteboard, database, …), separated by ;# (like so: ID;#TYPE); multiple values are separated by comma (like so: ID;#TYPE,ID;#TYPE,ID;#TYPE) |
- the other fields are optional and can be left blank
When starting the next migration, WikiTraccs should process this selector and migrate the pages.
How to get content IDs and types?
Depending on your migration team’s level of access there are different ways to get content IDs and content types.
How to manually look up the content ID and type for a page
Any user that can view Confluence pages in the browser can do this.
Confluence Server and Data Center
In the browser, open the Confluence page you need the content ID for.
Open the Page Information for that page:
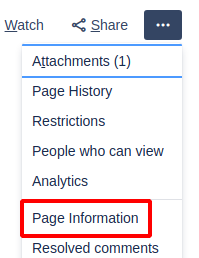
The browser will now show the page ID in its address bar; here it is 10387457:

The Page Information view and address bar will look similar for pages and blog posts. You can infer that you are looking at a blog post by looking at the breadcrumb, which contains a date:

Note: The Page Information view is also available in Confluence Cloud.
Confluence Cloud
In Confluence Cloud the content ID and type are always shown in the address bar of your browser when navigating pages.
Having open a page the address bar will look like this:
https://contoso.atlassian.net/wiki/spaces/SPACE/pages/123456789/Page+Title
The /pages/ part tells you that this is a page, and its ID is 123456789.
For a blog post this looks similar:
https://contoso.atlassian.net/wiki/spaces/SPACE/blog/2024/10/24/987654321/Blog+Title
The /blog/ part tells you that this is a blog post, and its ID is 987654321.
This works similarly for other content types like whiteboards.
How to use a space backup to look up content IDs and types
As Confluence system administrator, you can create a space backup. You’ll see content IDs and types in this backup.

Each space backup is a zip file that contains an entities.xml file.
You’ll find information about all pages (of the backed-up space) in this xml file:

The same for blog posts:
How to use SQL queries to look up content IDs and types (on-premises only)
This option is the most flexible one, but can only be applied with administrative access to the database server backing Confluence.
Have a look at this recipe on how to use SQL to get a list of pages for a space: Getting a list of pages per space [on-premises].
Use cases for the Content ID selector
The Content ID selector has several benefits:
- it allows selecting content to migrate based on criteria you define
- it works whether or not the migration account is included in page restrictions; this is a difference to the CQL selector
- it can work around the issue that some Confluence instances show with space selectors: Confluence might misreport space contents
The drawback of course is that you manually have to assemble the list of IDs. Using the space selector to migrate whole spaces is much more convenient.
Wrap
In this post we created a Content ID selector to migrate two selected pages. We also learned how to get the content IDs for pages. Depending on the permissions of the migration team, there are different ways to do that.