Testing WikiTraccs for Markdown
This topic is part of WikiTraccs for Markdown and work in progress.
Join the waitlist and start publishing Markdown to SharePoint soon
The last blog post provided some background on how WikiTraccs for Markdown came to be.
This blog post shows how to publish Markdown files to SharePoint Online.
Sample Repository
We use a sample knowledge repository to test publishing Markdown to SharePoint Online. There is one available in our library: AI for Beginners Sample Repo.
This repository is a copy of one of Microsoft’s repositories about AI and contains lots of Markdown files, images, and folders:
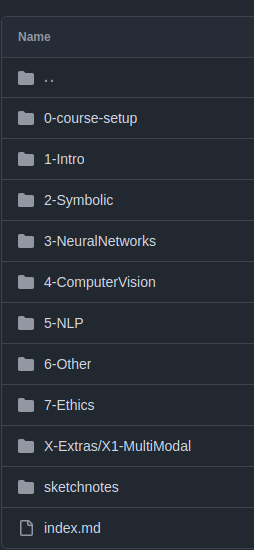
This is not an ideal structure, but taking something “from the wild” seems like a good test. WikiTraccs will make educated guesses about IDs, parent-child relationships and so on.
For testing, download the whole library repository as zip file and extract it. Then use the ai-for-beginners-sample-repo folder as base address for your test.
Publishing Markdown to SharePoint Online
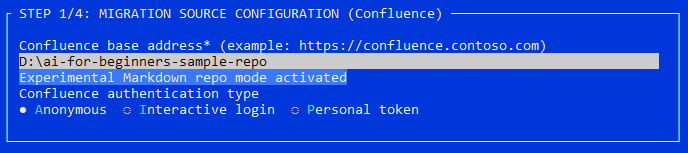
Starting with release v1.23.6, WikiTraccs supports file pathes as “Confluence” base address.
Enter the path to the ai-for-beginners-sample-repo folder:
Note
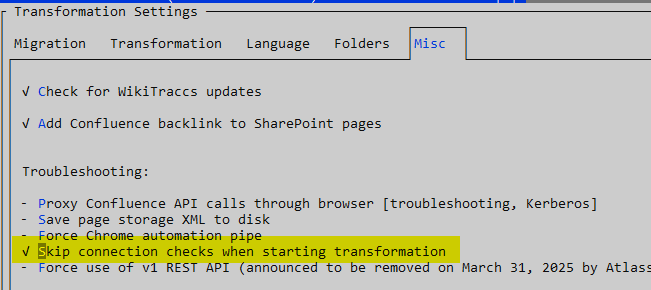
Naming throughout WikiTraccs is still focused on Confluence as sole data source. This will be adjusted in a later release.Make sure to activate the Skip Connection Checks setting as those are not required:
Then proceed as if you would migrate from Confluence:
- Update the space inventory
- Choose sources in the space inventory
- Start the migration
WikiTraccs should now start publishing Markdown to SharePoint Online.
Limitations and Work Items
This is a non-exhaustive list of things that need to be done before WikiTraccs for Markdown is ready for production use:
- auto-disable connection checks for Markdown source
- don’t use the folder path as source “Site ID”, as this makes migrating from different migration machines impossible
- optimize speed for larger repositories; currently it’s rather slow
- the page hierarchy is not yet properly migrated for the sample repo
- adjust the user interface to be “Confluence-free”
- figure out where to put images and files that are referenced by multiple pages; images currently are handled as “external” and duplicates are created per referencing page
- provide documentation on the expected source repository format and possible configuration options
- figure out a good format for IDs (numbers? GUIDs?) and how to make maintenance easy (e.g. preventing duplicates)
And probably more.