Splitting a Space
Assume the following use case where a space needs to be split into multiple parts:
“We have a Confluence space that contains information contributed by seven different teams. Each team’s content needs to be migrated to a separate SharePoint site.”
Let’s assume that all pages belonging to one team have a common parent page. That’s 7 parent pages for 7 teams.
How to migrate each of the 7 parent pages and all their decendants from Confluence to 7 different target sites in SharePoint?
With WikiTraccs, there are two approaches to selecting parts of a space for a migration:
- the Content ID selector
- the CQL selector
We’ll look at the Content ID selector in depth.
Use the Content ID Selector
With the Content ID selector you give WikiTraccs a list of page IDs to migrate.
How you assemble the list of page IDs is up to you. With Confluence Server and Data Center a common approach is via database query, in the Cloud other approaches are warranted.
In this section we are looking at:
- a sample tree to illustrate migrating a subtree of pages
- how to assemble a list of page IDs from the Confluence database
- how to properly format those page IDs
- how to create a Content ID selector entry in the Confluence Space Inventory list
- how the Space Inventory looks after configuration
One way to get page IDs is from the Confluence database using SQL queries.
Consider the following page tree. How to get all page IDs of the Special Content page and all its descendants (because we want to migrate those)?
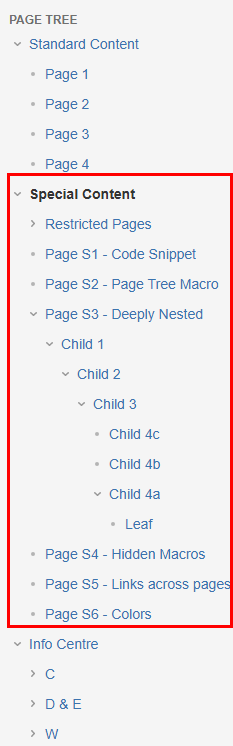
First we need the starting point, the page ID of the Special Content page, which is the root of the subtree.
To get the page ID for any page, open the Page Information page:
Then look at the browser bar that should show something like this: https://contoso.com/confluence/pages/viewinfo.action?pageId=65604.
The subtree root page ID in our case is 65604.
Now we can run the following SQL query on the Confluence database to get the list of descendants:
Note
Replace65604 in the following snippet with your subtree root page ID.SELECT c.contentid,
c.title
FROM content c
FULL OUTER JOIN confancestors ca ON ca.descendentid = c.contentid
WHERE ca.ancestorid = '65604'
AND c.content_status = 'current'
AND c.prevver IS NULL;
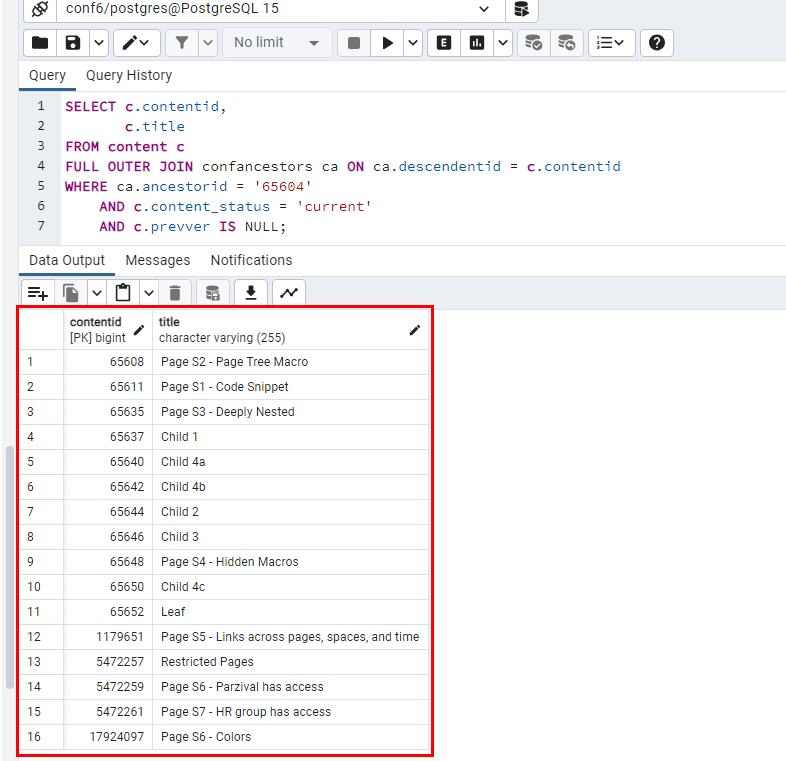
The result might look like this, but could also look different, depending on the tool that is being used:
WikiTraccs expects those IDs to be in a specific format, though. We use an adjusted SQL query to get the list of IDs in the expected format:
SELECT count(*), string_agg(contentId || ';#' || contenttype, ',') AS contentIdSelectorValue
FROM (
SELECT c.contentid,
LOWER(contenttype) AS contenttype,
c.title
FROM content c
FULL OUTER JOIN confancestors ca ON ca.descendentid = c.contentid
WHERE ca.ancestorid = '65604'
AND c.content_status = 'current'
AND c.prevver IS NULL
ORDER BY contenttype, contentId
) subquery;
The result now looks different:

This result contains the number of pages (16) and the list of IDs, including their type, in the expected format:
65608;#page,65611;#page,65635;#page,65637;#page,65640;#page,65642;#page,65644;#page,65646;#page,65648;#page,65650;#page,65652;#page,1179651;#page,5472257;#page,5472259;#page,5472261;#page,17924097;#page
Note
Make sure to update the space inventory before proceeding by clicking the Update Space Inventory in WikiTraccs site button in the blue WikiTraccs window:

This makes sure that the space inventory list exist and that it contains space information you can build on.
This step is also included in the quick start guide, so if in doubt, refer to that: Getting started.
We can now create the content ID selector in the Confluence Space Inventory.
Click Add new item to invoke the respective dialog:
You need to fill the following fields:
| Field | Meaning | Sample Value |
|---|---|---|
| Title | Not used, but it’s a mandatory field; enter anything | dummy |
| WT_In_CfSiteId | Confluence base address; look at the other entries in the space inventory list to see what to enter | https://contoso.com/confluence |
| WT_Setting_RequestTransformation | Check this box to migrate this selector | ☑ |
| WT_Setting_ContentSelectorValue | The list of IDs in the expected format | 65608;#page,65611;#page,65635;#page,65637;#page,65640;#page,… |
| WT_Setting_TargetSiteRootUrl | SharePoint target site for migrated pages | https://contoso.sharepoint.com/sites/ContentIDSelectorDemoTargetONE |
All other values can be left empty, as those are not required for the Content ID selector.
The space inventory list, after adding two Content ID selectors, might look like this:

Two things are important as well:
- Don’t forget to add the ancestor page to the ID list of the selector as it is NOT part of the SQL result above.
- Remove the entry for the space your are splitting from the space inventory. Otherwise link translation might get confused and link to the wrong target site, as pages would be included in two selectors at the same time.
Now start a migration.
WikiTraccs should migrate the pages indicated by each Content ID selector to the respective target page. Links will be transformed as well, based on the target site URL configuration.
Use the CQL Selector to Choose Pages for Migration
The CQL selector works similar to the Content ID selector, but instead of giving WikiTraccs a list of page IDs you give it a CQL query - a Confluence search query.
Using a CQL selector works just like the Content ID selector:
- create a new item in the space inventory list
- enter field values as described in the last section; there’s only one difference
- instead of the list of IDs you enter the CQL query into the
WT_Setting_ContentSelectorValuefield
Using a CQL query, you can refer to Confluence content by criteria you define. Let’s create a simple CQL query that refers to all pages that have the label migration set:
The CQL query that finds those pages is label = migration.
You should always test that your CQL query works, before using it as a selector for WikiTraccs. You’ll spot errors in the query much faster.
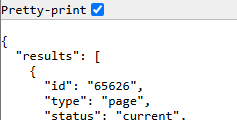
Testing CQL queries in Confluence is a bit cumbersome as you have to use the REST API. Assuming your Confluence base address is https://contoso.com/confluence, the address for testing above CQL query is https://contoso.com/confluence/rest/api/content/search?cql=label = migration. Navigate to this address and the result should show a list of pages in JSON format:
Have a look at the CQL selector documentation to learn more details and read about some caveats associated with this selector type.
Configuring the Page Tree in SharePoint
If you choose to migrate a subtree of pages and you opted to add the WikiPakk page tree to the game, it will work well.
After migrating a subtree, open the migrated root page. Then open the page tree panel and click Move to tree root.
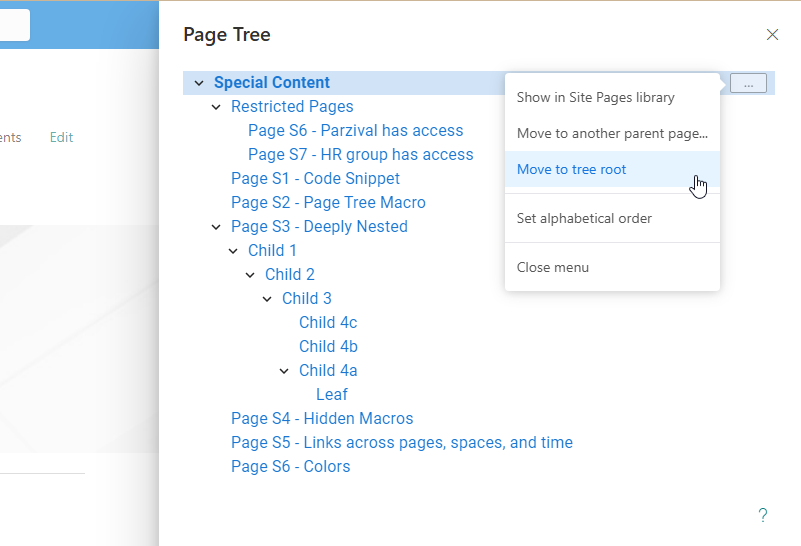
The subtree root will now always be shown when opening the page tree panel.
Note that this only works when migrating a subtree as this will also migrate the page hierarchy within the subtree. Migrating a list of arbitrarily picked pages won’t result in a proper tree in SharePoint.