This is the multi-page printable view of this section. Click here to print.
News About WikiTraccs
- Migrating Page Author and Editor from Confluence to SharePoint (Video)
- Confluence Authentication Recommendation
- Syncing and updating the user mapping list
- Export Confluence Pages as Word Documents
- Migrating from a Read-Only Confluence Instance
- Nested Tables From Confluence to SharePoint
- Migrating Confluence Whiteboards as draw.io Files
- Inside Confluence Whiteboards: Why You Can't Really Export Them
- Configuring Sites.Selected Authentication for WikiTraccs
- Stop and Resume a Migration Run at Any Time
- Confluence Instances in the Wild
- How to get the Scroll PDF template ID
- Migrate historical Confluence page versions as PDF with Scroll PDF Exporter
- WikiPakk Is Not Affected by the SharePoint Add-In Retirement
- What if stuck on interactive Confluence login?
- Run an Automated Confluence to SharePoint Migration
- Skip Broken Confluence Attachments During Migration
- Confluence Authentication Improvements
- Adding Edge Browser Support
- WikiTraccs 2025 Recap
- Backing up Atlassian Marketplace Apps
- Question Time November 2025
- Table Size Optimization
- Why do customers pick Confluence?
- Using a Header Template for Migrated Pages
- Making Sure Migrated Links Work
- SharePoint Page Tree Groups News Posts by Date (WikiPakk Update)
- Migrating Communardo and Comala Metadata
- WikiTraccs Creates Images for Draw.io Pages
- Exporting Historical Page Versions - It's Complicated
- WikiTraccs Creates Draw.io Preview Images
- Using the PnP Page Navigator Web Part as Table of Contents Replacement
- How Are Excerpt Include Macros Handled?
- Support Case: Missing draw.io Images
- New WikiPakk Children Display Web Part and Usage Metrics
- How to Export a Link Map
- Sharing Content Across SharePoint Pages Is Impossible
- How Nested Confluence Macros Are a Migration Challenge
- M365 Authentication, API Requests, and Blocked Endpoints
- Migrating Confluence Cloud Whiteboards
- Harnessing the New SharePoint Page Format
- Splitting a Space
- Testing WikiTraccs for Markdown
- Finding the Confluence Version
- WikiTraccs for Markdown
- Making SharePoint Tables Look Pretty
- How much time will a Confluence to SharePoint migration take?
- Confluence Quirks
- Good Practices for your Confluence to SharePoint Migration
- Confluence Cloud Specialties
- WikiTraccs switches to Confluence Cloud v2 REST API
- Migrated SharePoint Page Names Explained
- How to migrate only some pages?
- Confluence vs. SharePoint - Part 1: Overall structure
- Confluence Link Types Explained
- Mapping user accounts from Confluence to SharePoint
- Confluence Authentication Overview
- Confluence might misreport space contents
- Can feature 'XYZ' be added to WikiTraccs?
- Converting Gliffy and draw.io to SVG
- Migrating Gliffy and draw.io macros to SharePoint Online
- Transforming even more colors from Confluence to SharePoint!
- How to run parallel WikiTraccs migrations?
- Fixing image positioning in SharePoint
- Broken inline image positioning in SharePoint
- How to migrate rich Confluence tables to limited SharePoint tables?
- Migrating large Confluence spaces to SharePoint
- Ignoring macros when migrating pages from Confluence to SharePoint
- Registering WikiTraccs as app in Azure AD
- Registering WikiTraccs as App in Entra ID
- The art of positioning images - part 2 of 2
- The art of positioning images - part 1 of 2
- Confluence Page Tree in SharePoint
- What about those Confluence Macros?
- What to expect from WikiTraccs?
- New attachments macro transformation
- Mapping principals and migrating permissions
- WikiTraccs Quick Start Video out now!
- New release - UI overhaul
- Measuring page migration success
- A new approach to configuring WikiTraccs
- Announcing WikiTraccs
Migrating Page Author and Editor from Confluence to SharePoint (Video)
WikiTraccs can migrate the creator and editor of Confluence pages to SharePoint, so the migrated SharePoint pages carry the same author and editor information.
This video shows the whole flow end to end: migrating a small space, how WikiTraccs discovers users and automaps them to Entra ID, why some users map and some do not, and how to fix the rest with an update run and bulk pre-filling.
Prefer to read, or want to jump to a specific part? Each section below links to the matching moment in the video.
Written, step-by-step versions
This post follows the video. For the detailed write-ups, see Mapping user accounts from Confluence to SharePoint and Syncing and updating the user mapping list.AI Note
The step-by-step instructions were automatically generated from the video transcript.What this walkthrough covers
The plan: migrate a few pages, look at the result, see what gets automapped and what does not, find out which pages are done and which are not, adjust the user mapping, run an update run that updates the creator and editor on SharePoint, and finally look at bulk options for users and groups.
▶️ Watch from the start · start 0:00 · duration 0:56
The Confluence space and its three pages
The source is an old local Confluence Server with a space that has three pages: a home page, a “Collab Page Adele”, and a “Collab Page Megan”. The Adele page was created by Adele (who has an email address) and last edited by an automation system user that has no email set. The Megan page was created by Megan (who has a Gmail address) and edited by Adele. The missing email and the Gmail address both matter later.
▶️ Watch this part · start 0:56 · duration 1:06
Running the migration in WikiTraccs
WikiTraccs is already configured for this Confluence and SharePoint. The demo uses certificate authentication, so there is no interactive login. Two SharePoint sites are involved: the WikiTraccs site that the tool manages, and one target site where the pages are created. Hitting start kicks off the migration.
▶️ Watch this part · start 2:02 · duration 1:19
How users land in the mapping list
The WikiTraccs site holds one list of interest: Confluence User and Group Mapping (WikiTraccs). It starts empty. While migrating, WikiTraccs reads metadata about each page (who created it, who edited it, plus any @mentions) and adds every new user account it finds to the list. In this run that is three accounts: Adele, Megan, and the system user. The email address, key, internal name, and display name all come from Confluence.
▶️ Watch this part · start 3:21 · duration 1:42
Automapping to Entra ID: who maps and who does not
To set the author and editor on SharePoint, WikiTraccs needs an Entra ID account for each user. That target account goes in the Map for data and mentions column. WikiTraccs automaps by taking the Confluence email address and looking for an Entra ID user with the same email. For Adele this succeeds. For Megan it fails, because her Gmail address has no matching Entra ID account. For the system user there is nothing to look up, because it has no email.
▶️ Watch this part · start 5:03 · duration 1:03
Created by and Modified by on the migrated pages
Created by and Modified by are standard SharePoint page columns. On the Adele page, WikiTraccs correctly set Adele as creator, but Modified by shows SharePoint app. Two things combine here: when no mapping is available, WikiTraccs falls back to the migration account that logs in to SharePoint, and under certificate authentication that account is shown as SharePoint app. The system user has no email to look up, so it is not mapped, which is why it ends up as SharePoint app. The Megan page shows SharePoint app as creator too, because Megan is not yet mapped. Its Modified by is correctly set to Adele, who is mapped.
▶️ Watch this part · start 6:06 · duration 3:31
The Check Principal Mapping done indicator
WikiTraccs marks pages that still need work with the Check Principal Mapping column in the Site Pages library. You may have to add the column via Add column, then Show or hide columns. A tick means a mapping was missing. The space home page, created and edited only by Adele, was fully mapped during migration, so it has no tick. The update run only touches pages that have a tick. You can set a tick by hand to force an update, and WikiTraccs clears it once both creator and editor are set. This makes the process iterative: add mappings, run an update, repeat, and the ticks disappear over time.
▶️ Watch this part · start 9:37 · duration 1:50
Adjusting a mapping and running the update run
In the mapping list, Megan is mapped to a system account by hand (using the grid view). Then, back in WikiTraccs, the update run is configured under Settings, Configure transformation, by choosing Update ‘Created by’ & ‘Modified by’ of already migrated content. Everything else stays the same, and the transformation is started again. WikiTraccs now looks only at migrated pages that have the Check Principal Mapping tick and updates their author and editor from the mapping list.
▶️ Watch this part · start 11:27 · duration 2:28
Checking the corrected author and editor
After the update run handles the two flagged pages, the SharePoint pages reflect the mapping. The Megan page now shows Megan as creator and Adele as editor. The Adele page shows Adele as creator and the mapped system account as editor. The Check Principal Mapping ticks are gone. This is the happy path; some things can go wrong, but those are out of scope for this video.
▶️ Watch this part · start 13:55 · duration 1:06
Pre-filling the list with Sync and Update User List
The mapping list normally grows while migrating, but you can also pre-fill it beforehand. Under Tools, Sync & Update User List (with content migration mode switched on), WikiTraccs first syncs the SharePoint list with its local cache. You then name one or more Confluence groups to pull members from. In the demo, a “space migration users” group with three members (Adele, Megan, the system account) is used.
Confluence Cloud
As of WikiTraccs v1.34.50, the Sync & Update User List tool also works with Confluence Cloud: it can discover groups and their members (by group name, or across all groups) and write them into the mapping list. Confluence Cloud’s group APIs do not return email addresses, though, so the email column stays empty on this path; you can add the emails via CSV import. On Confluence Data Center and Server, like in the video, emails are fetched directly (when email visibility is enabled in the Confluence administration).▶️ Watch this part · start 15:01 · duration 1:15
Fallback account and what stays manual
A fallback account can be set for users without a Confluence email, which is handy when you have many email-less system accounts that should all map to the same Entra ID account. After the run, Adele is automapped by email, the system account (no email) gets the fallback, but Megan stays empty. Her Gmail address is present, so the fallback (which only applies to empty emails) does not touch her, and there is no matching Entra ID account to automap to. Accounts like Megan are manual work: leave them unmapped (their pages get the migration account as author), or map them by hand or with a script such as PnP PowerShell.
▶️ Watch this part · start 16:16 · duration 3:51
Where this fits in a migration
Author and editor metadata is migrated in a separate pass after the content pass. See Migration Playbook: Pass 2 - Author & Editor Metadata for how it fits into the overall process.Confluence Authentication Recommendation
WikiTraccs supports several ways to authenticate with Confluence, and this post recommends the order to try them in - for an overview of all options see Authenticating with Confluence.
1. Interactive Authentication
Start with interactive login, it is the easiest option (Interactive Authentication). It also offers the broadest migration scope, as WikiTraccs will be able to access some endpoints that are not available when using token-based authentication.

WikiTraccs opens a browser, you log in with your migration account, and WikiTraccs takes over the session cookies to access Confluence as that user.
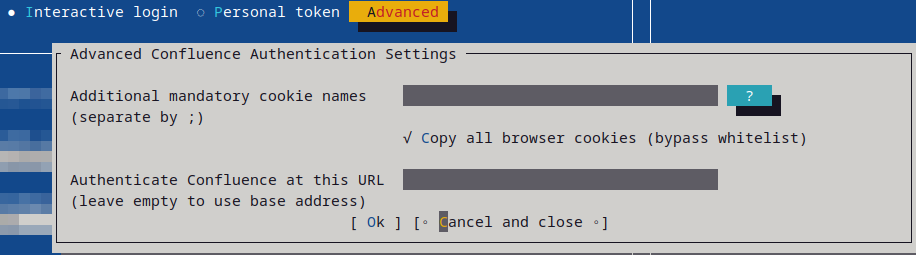
By default WikiTraccs only copies well-known authentication cookies, covering a wide range of authentication providers. If your login needs more cookies - for example with an SSO solution not covered - add their names to the cookie whitelist (Additional Mandatory Cookie Names).
If authentication still doesn’t work, enable Copy all browser cookies to bypass the whitelist and take over every cookie (Copy All Browser Cookies). Those two settings are the first thing to check when interactive login fails.
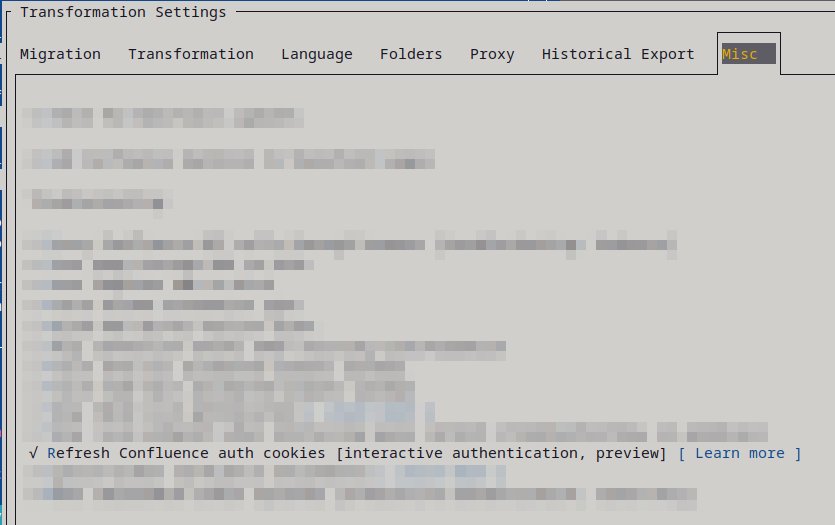
If your session tends to time out during longer migrations, turn on the optional cookie refresh (Interactive Authentication Cookie Refresh). It keeps a browser window open that refreshes the cookies while the migration runs.
2. Token-based Authentication
If interactive login doesn’t work for you, use a Personal Access Token (Token-Based Authentication).

Confluence Server and Data Center just need the token
This needs Confluence 7.9 or later, and it also works with Confluence Cloud.
Confluence Cloud needs the user login (email) in addition to the token
3. Selenium Proxy
As a last resort, use the Selenium Proxy, which is the Proxy Confluence API calls through browser setting (Proxy Confluence API calls through browser).
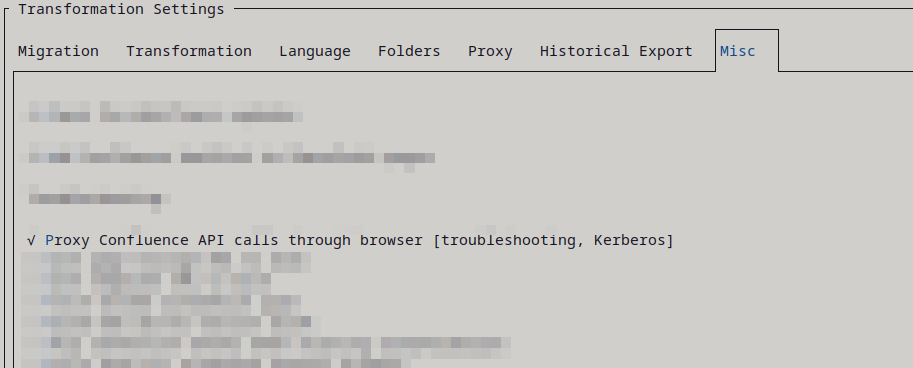
It routes every Confluence request through the browser, which works around tricky setups like Kerberos. This is slower than the other options, so only use it when nothing else works.
Syncing and updating the user mapping list
Confluence Cloud and on-prem
This tool works with both Confluence Data Center / Server and Confluence Cloud. One difference: Confluence Cloud’s group APIs do not return email addresses, so when fetching group members on Cloud the email column stays empty; add the emails via CSV import afterwards. On Data Center / Server, emails can be fetched directly, if enabled in the administration.Video walkthrough
Prefer to watch? The Migrating Page Author and Editor to SharePoint video covers the Sync & Update User List tool in its last sections, including the group pre-fill and the fallback account.Note: The Sync & Update User List tool is available as of WikiTraccs v1.34.35 for Confluence Data Center / Server, and as of v1.34.50 for Confluence Cloud.
During each migration run, WikiTraccs “collects” user account information from pages you migrate from Confluence to SharePoint, for example the creator and editor of each page.
WikiTraccs stores this Confluence user account information in a SharePoint list Confluence User and Group Mapping (WikiTraccs). It also tries to find a corresponding Entra ID account that has the same email address. This Entra ID account can then become the Author or Editor of a SharePoint page.
The procedure is outlined in this blog post: Mapping user accounts from Confluence to SharePoint.
But you might also encounter scenarios, where you want to pre-fill this SharePoint list with Confluence accounts, or where you want to update the user emails of accounts.
This is where the Sync & Update User List tool will help.
How to start the tool
Open the menu Tools, then click Sync & Update User List:
WikiTraccs asks for confirmation to synchronize the local user cache and the SharePoint user mapping list.
Storage Note
Confluence user account information is stored in two places: the “Confluence User and Group Mapping (WikiTraccs)” list, which is a SharePoint list, and a local cache. Those storage locations can get out of sync, for example when accounts are deleted from the SharePoint list, or the local cache is reset.
Click Yes, to synchronize in both directions. Locally stored accounts that are missing in SharePoint are added to the SharePoint list, and accounts from the SharePoint list missing in the local cache are downloaded.
Click Clean local cache, then Yes, to make the synchronization (kind of) one-way. Locally stored user accounts are removed from the local cache, unless the accounts are referenced by e.g. inventory data. After cleaning, the sync happens like described in the previous paragraph.
Click No to cancel and close the dialog.
Assuming you clicked Yes, WikiTraccs might now starting uploading user account information to the SharePoint list:
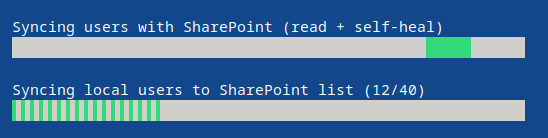
Speed Note
Uploading to SharePoint takes time as one-by-one account information is stored in the SharePoint list. Throttling by Microsoft restricts the speed of the operation.After this, the Sync & Update User List dialog opens:
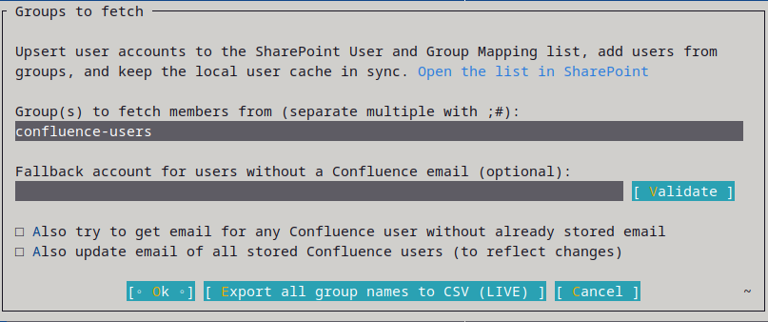
How to use the tool
At the top there is an Open the list in SharePoint link that takes you straight to the mapping list in SharePoint, so you can check the current state at any time.
The fields:
| Field | What it means |
|---|---|
| Group(s) to fetch members (incl. emails) from | The Confluence groups whose members you want to add to the user list. To name several groups, separate them with ;#. |
| Fallback account for users without a Confluence email (optional) | An Entra ID account that all email-less users get mapped to via the WT_Setting_MapForDataAndMentions and WT_Setting_MapForPermissions fields. Leave it empty to skip the fallback. Use the Validate button to check that the account exists in SharePoint before you run. |
| Checkbox Also try to get email for any Confluence user without already stored email | For users already in the list that have no email yet, WikiTraccs asks Confluence again for one. This option is helpful after toggling email visibility on for a Confluence site. |
| Checkbox Also update email of all stored Confluence users (to reflect changes) | For every user already in the list, WikiTraccs re-reads the email from Confluence and updates it. |
There is also an Export button that writes all Confluence group names to a CSV file, which you can use to learn about existing groups and to verify that WikiTraccs can see them. Note that the export can take a long time if there are thousands of groups and that there is no Cancel button. Close WikiTraccs to cancel.
Click Ok to start the synchronization.
WikiTraccs will fetch group members first:

Depending on group size, this might take a while. For each user account, WikiTraccs will reach out multiple times to Confluence to try to get the user’s email address. Note: this email lookup is for Confluence Data Center / Server. On Confluence Cloud, the group API does not return emails, so members come in without one (see the note at the top).
Then, WikiTraccs stores user account information in the SharePoint list.

Note that this also might take a long time, depending on the number of user accounts.
When done, WikiTraccs shows a summary:

What gets overwritten
WikiTraccs “owns” the Confluence part of the user account information in the SharePoint list. It might overwrite information like the user name or the Confluence email addresse when updating the SharePoint list.
Note
WikiTraccs only writes to the SharePoint mapping list, as well as the local cache. It never changes anything in Confluence, it just reads.WikiTraccs will also overwrite the mapping WT_Setting_MapForDataAndMentions and WT_Setting_MapForPermissions fields under the following circumstances:
- Mapping by email. When a user has an email (freshly fetched or refreshed), WikiTraccs looks up the matching Entra ID account and sets the mapping. If a mapping was already there, it is replaced to match the email. This is the same automapping that runs during a migration.
- When you set a fallback account, every email-less user that the run touches is mapped to that one account. This replaces whatever mapping the row had before, including a mapping you set by hand.
So, if you manually mapped Confluence user accounts to the right Entra ID account, you should be careful using any of the auto-update features, as this might replace your mapping.
Scenarios
Prefilling the list before migration
You want mappings ready before you migrate any pages.
- Open Tools, Sync & Update User List, confirm with Yes.
- Leave confluence-users in the group field (or name the groups you need).
- Leave the fallback empty and both checkboxes off.
- Run it.
All members of the groups are added to the mapping list, automapped by email where possible. You can then fill in the rest by hand (or script) before starting the content migration.
Pointing email-less accounts at a default account
You have accounts that will never get an email (local or service accounts) and want them all mapped to one default account instead of staying unmapped.
- Open Tools, Sync & Update User List, confirm with Yes.
- Enter the default account in Fallback account for users without a Confluence email and click Validate.
- Turn on Also try to get email for any Confluence user without already stored email so accounts that can still get a real email are mapped properly first.
- Run it.
Every account without an email ends up mapped to the default account. Remember that this also replaces any manual mapping those accounts had.
Filling in emails after making them public in Confluence
You switched the Confluence email visibility to public, so emails that were hidden before are now widely available, and you want the accounts already in the mapping list to pick them up.
- Open Tools, Sync & Update User List, confirm with Yes.
- Leave the fallback empty and the group field at its default.
- Turn on Also try to get email for any Confluence user without already stored email.
- Run it.
WikiTraccs re-asks Confluence for an email for every stored user that still has none, fills in the ones that are now available, and automaps those accounts by email. If you also want to catch emails that changed (not just newly appeared), turn on Also update email of all stored Confluence users (to reflect changes) as well for a full refresh.
Insights and control
When a run doesn’t do what you expect, for example accounts stay unmapped or emails don’t show up, the common log files tell you what happened for each account.
The tool covers the common cases. When you need finer control, for example to map specific accounts in bulk, clear mappings, or set fields the dialog doesn’t touch, you can edit the Confluence User and Group Mapping (WikiTraccs) list directly with a PowerShell script and PnP.PowerShell. This is the recommended approach when finer control is required.
Export Confluence Pages as Word Documents
Note: The functionality described in this post is available as of WikiTraccs 1.34.33
Prerequisites
This feature works on-premises only (Confluence Server / Data Center). Confluence Cloud is not supported and the option is skipped there.What This Does
Confluence has a built-in “Export to Word” function. WikiTraccs can use it during a migration.
When the option is on, WikiTraccs exports each in-scope page as a Word file (.doc) and attaches it to the migrated SharePoint page. The original page content still migrates as a normal SharePoint page; the Word file rides along as an extra attachment.
How to Turn It On
In the WikiTraccs.GUI Settings menu, click Configure Transformation to open the Transformation Settings dialog. Open the Historical Export tab.
The Word export toggle sits below the Scroll PDF settings. Check it to enable native Word export, then start your migration as usual.
What You Get
- One Word file (
.doc) per page, holding the page’s current version. - The file is stored together with the other page attachments.
Caveats
Export Takes Time
This is the main thing to plan for.
Each page needs a separate call to Confluence to produce its Word file. On large migrations this adds up and slows the run down noticeably.
Turn it on only when you actually need the Word files. Test with a few pages first to get a feel for the added time.
Failed Exports Are Visible
If a Word export fails for a page, WikiTraccs flags that page with a failed transformation and logs a warning.
Migrating from a Read-Only Confluence Instance
A recurring question: our Confluence license is about to expire and the instance will become read-only - can WikiTraccs still migrate?
This post is about Confluence Data Center, which is the case where an expiring subscription puts the instance into read-only mode. Confluence Server licenses are perpetual - an expiring Server maintenance period does not trigger read-only; the instance keeps working as before, just without support and upgrades. Confluence Cloud handles license lapses differently and is out of scope here.
Current State
Short answer: it should work. Longer answer below.
WikiTraccs only reads from Confluence. It never writes. As long as Confluence is reachable and the REST endpoints still answer, a migration can run. A read-only state caused by an expired license should not block the kind of access WikiTraccs needs.
This has been observed working against read-only Confluence instances in the past. Atlassian documents that a Data Center instance becomes read-only when the subscription expires, but the docs do not specify whether REST API endpoints stay fully reachable in that state. So while practical experience says yes, there is no Atlassian-side guarantee for every Data Center version.
Plugin Behavior Can Change
A separate angle: apps/plugins installed in Confluence may behave differently when the instance license is invalid, which can alter what their macros render - and therefore what WikiTraccs sees and migrates.
The same effect happens when an app license itself expires (independently of the Confluence license). Macros from such apps may render normally, render a license-expired notice, or refuse to render at all. WikiTraccs migrates what Confluence delivers - so if a macro renders a “license expired” message instead of its usual content, that is what ends up in SharePoint.
References
The claims above are backed by these sources:
Data Center subscription expiry triggers read-only mode
“If your subscription expires, Confluence will become read-only, which means you’ll be able to view pages, but not create or edit them.”
Managing your Confluence License - Atlassian Documentation (DC 10.2) Source: first-party Atlassian (confluence.atlassian.com). Last modified Oct 3, 2023.
Server licenses are perpetual (no read-only on maintenance expiry)
“As all server licenses are perpetual, you can use your software into perpetuity.”
What Happens When Your Jira Server or Data Center License Expires? - Atlassian Support Source: first-party Atlassian (support.atlassian.com). The article is Jira-titled, but the perpetual-licensing model is Atlassian-wide and applies to Confluence Server as well. Last updated Feb 12, 2026.
The same conclusion is echoed in a Confluence-specific community Q&A:
“As all Server licenses are perpetual, you can use your software into perpetuity. This means the server product will continue to operate in its current state after the maintenance period expires.”
Atlassian Community: what happens after (server) Confluence license expired? Source: Atlassian Community forum thread. Answer by Ollie Guan, “Community Champion” (community member, not Atlassian staff). Posted May 29, 2020.
Apps may behave differently in read-only mode
“Not all apps (also known as plugins or add-ons) are compatible with read-only mode, and may continue to allow users to create or update content while read-only mode is enabled.”
Using read-only mode for site maintenance - Atlassian Documentation (DC 10.2) Source: first-party Atlassian (confluence.atlassian.com). Last modified Mar 29, 2023.
The same Atlassian developer documentation explicitly states that apps must be made compatible with read-only mode by their developers - it is not automatic: How to make your app compatible with read-only mode. Source: first-party Atlassian (developer.atlassian.com). Last updated Feb 4, 2022.
Nested Tables From Confluence to SharePoint
Note: Nested-table support is available as of WikiTraccs v1.30.25, released in late September 2025.
Confluence lets editors put tables inside table cells. SharePoint pages, on the surface, do not. This post explains what WikiTraccs does about that, and the tradeoffs behind it.
TL;DR
- WikiTraccs keeps small nested tables nested where it can, and denests large ones where it has to.
- The behavior is gated by the Use non-standard table transformation Gray Setting (on by default).
- Denested tables are moved below the parent table and the original location gets a numbered marker so the relationship stays readable.
Background
Confluence supports nested tables out of the box. Migrating those was a long-standing pain point.
The SharePoint Pages browser editor does not expose nested tables in its toolbar - users cannot create them by clicking buttons. But the SharePoint Text web part can store and render nested tables correctly. Word also produces them when you paste nested tables to SharePoint.
WikiTraccs makes use of that gap: it creates nested tables that SharePoint saves and shows correctly, even though a user could not build the same thing by clicking around in the editor. That is the Gray Setting idea.
What Counts as a Nested Table
- A
<table>element living inside a<td>of another table. - Common sources in Confluence:
- Tables an author actually nested by hand.
- Section / Column macros - WikiTraccs maps those to tables, which can put the user’s own tables inside.
- Panel / Info / Note / Warning / Tip macros - the macro is rebuilt as a table, and any table content inside lands nested.
- Any custom macro that wraps content into a table-shaped layout.
When WikiTraccs Keeps a Table Nested
WikiTraccs decides per nested table whether keeping it in place would still produce a readable SharePoint page.
The decision weighs a handful of factors: how many columns the nested table has, how much text and how many images sit in its cells, how wide the parent table already is, and how deep the overall nesting goes.
Small, narrow tables with little content tend to stay nested. Wide tables, content-heavy tables, and tables that pile up inside an already wide parent tend to be moved out so the parent table’s columns don’t get squeezed into unreadable widths.
The exact thresholds are tuned over time and may shift between releases. The intent is stable, though: keep the structure where SharePoint can render it cleanly, denest where it cannot.
When WikiTraccs Denests
A nested table gets denested when:
- The Use non-standard table transformation setting is off.
- The thresholds above are exceeded, in which case denesting prevents a layout collapse.
What that looks like on the page:
- The nested table is moved out so it sits right after the table it used to live inside.
- In the original cell, a short note like “Nested table 1 moved here:” is left behind, so it’s clear where the moved table came from.
- If several tables are moved out from the same area, they are numbered, so the notes and the tables below match up.
Configuration
- Settings -> Migration tab -> Use non-standard table transformation (Gray Setting, on by default). Off means everything is denested, like the pre-v1.30 behavior.
- Skip table size optimization (Misc tab) is independent. It controls browser-based column width measurement; nesting decisions still apply either way.
Related Reading
- Making SharePoint Tables Look Pretty - cell colors, merged cells, and the broader Gray Setting that nesting now rides on.
- Table Size Optimization - how column widths are measured in a real browser; helps especially with nested tables.
- How Nested Confluence Macros Are a Migration Challenge - the macro side of nesting; complementary problem.
- How to Migrate Rich Confluence Tables to Limited SharePoint Tables - the original “tables are hard” post.
- Gray Settings reference - what gray settings are and why they exist.
Wrap
Nested tables used to always be denested. Today, small ones stay nested and only the ones that don’t fit get moved out.
The behavior is on by default, gated by a Gray Setting, and you can fall back to the old always-denest behavior by turning that setting off.
If you want to trace which tables were moved where after migration, watch for the placeholder markers in the cells they used to live in.
Migrating Confluence Whiteboards as draw.io Files
Note
This post is only relevant for Confluence Cloud.Note: The whiteboard to draw.io conversion is available as of WikiTraccs v1.34.1.
In the last blog post I wrote about why you can’t really export Confluence whiteboards - Atlassian only offers manual PNG / JPG / PDF export, no structured format, no supported API.
WikiTraccs now offers something on its side: a best-effort conversion of Confluence whiteboards into draw.io files, alongside the existing PNG migration.
What This Means
Instead of (or in addition to) a flat PNG image as page attachment, your migrated SharePoint page can carry a .drawio file that contains the whiteboard’s shapes, text, colors, and connectors as editable elements.
You can open .drawio files in:
- draw.io / diagrams.net (the web editor at https://app.diagrams.net/)
- The draw.io app for Confluence (if you’re using draw.io there too)
- The draw.io desktop app
- Various IDE plugins (VS Code, IntelliJ)
In short, the whiteboard becomes editable again, not just a screenshot.
How to Enable
It’s a Gray Setting - meaning it might not be fully supported by a vendor - and it’s labeled as best effort. Enable it in the WikiTraccs settings: Migrate whiteboards to draw.io file [Cloud, best effort].
This is independent of the existing Migrate whiteboards (export as image) setting. You can enable just one, both, or neither:
- Just the image - same flow as before, you get a PNG.
- Just the draw.io conversion - you get an editable
.drawiofile. - Both - both end up on the migrated page.
- Neither - whiteboards are skipped.
What to Expect
The conversion translates the whiteboard’s structure into draw.io’s diagram model:
- Shapes (rectangles, ellipses, rounded rectangles, …) - preserved with positions, sizes, fill and stroke colors.
- Text inside shapes and free-floating text labels - preserved.
- Connectors between shapes - preserved with their endpoints.
- Stickers (the Atlassian sticker library used in whiteboards) - included as best-effort image references. Not all stickers are supported yet; support will be extended over time.
- Stacking order - mostly preserved; what was on top in Confluence is on top in draw.io.
It is not a pixel-perfect copy. Whiteboards are a free-form canvas; draw.io is a diagram editor with stricter rules. Expect:
- Slight differences in spacing, padding, or font rendering.
- Some elements (highly custom text formatting, freehand drawings, certain stickers) may not transfer faithfully.
- Curves and complex connectors may straighten out, lose bending points, or bend differently.
- Stacking order is preserved in the common case, but on whiteboards with a long edit history it can occasionally come out different than what you see in Confluence.
Disclaimers - Same Spirit as the Image Export
Just like the image-based whiteboard migration, this is a workaround for something Atlassian doesn’t (yet) offer themselves. That means:
- WikiTraccs reads whiteboards the same way the Cloud editor does. When you open a whiteboard in Confluence, the editor pulls the same whiteboard data WikiTraccs reads for the conversion. So as long as a whiteboard renders in your browser, WikiTraccs has access to the same content. Atlassian just doesn’t offer a separate, supported export on top of that.
- When Atlassian evolves the whiteboard format, WikiTraccs follows. Confluence’s whiteboard product is under active development. When Atlassian changes how whiteboards are represented, WikiTraccs needs an update to keep up. Until then, the conversion may produce incomplete results for whiteboards that use the new format.
- Best effort means best effort. The converter understands the shapes, text, connectors, and other elements it has been taught about. If a whiteboard contains something the converter doesn’t yet recognize, that element will be missing or simplified in the
.drawiooutput; the rest of the whiteboard still comes across. New element types are added over time. - Confluence Cloud only. Server / Data Center whiteboards are a different product and are not covered by this conversion.
If a conversion looks wrong: file an issue and attach both the raw binary whiteboard data (.bin file) and the converted .drawio file so the converter can be improved. You can grab both either from the SharePoint page attachments of a migrated whiteboard page, or via the diagnostic exporter (see next section).
A Quick Way to Test the Whiteboard to Draw.io Conversion
You don’t have to start a full migration to see what your whiteboards look like as .drawio files.
WikiTraccs’s Diagnostic Bundle Export (Tools → Create Diagnostics Report → enter a whiteboard’s content ID → click Fetch Confluence XML → click Assemble + zip) packages a single whiteboard’s full data, including:
- the raw binary diagram data file (the whiteboard’s underlying snapshot),
- linked resources used by the whiteboard (e.g. images, stickers),
- the converted
.drawiofile.
Open the diagnostic bundle, find the .drawio file in the whiteboards/<id>/ folder, and open it in draw.io. That’s the same file you would get from a real migration with the setting enabled - minus all the rest of the migration plumbing.
It’s the fastest way to answer “would this whiteboard come out usable?” before committing to a migration run.
Wrap
The image export gives you a screenshot. The draw.io conversion gives you something you can keep editing.
Neither is officially supported by Atlassian, both are Gray Settings, and either can break when Confluence Cloud changes shape. They complement each other: PNG is the safe baseline, draw.io is the upgrade for when you actually want to keep working with the content after migration.
Try it on a representative whiteboard via the diagnostic bundle export, see how the conversion looks for your data, and turn the setting on for the migration run if it fits.
Inside Confluence Whiteboards: Why You Can't Really Export Them
Confluence Cloud whiteboards were announced in December 2022 as a rebranding of Fabric (an Atlassian Point A incubator product), with the Early Access Program starting in January 2023, public beta in mid-2023, and general availability rolling out into 2024.
Currently you only have limited options when it comes to exporting whiteboards from Confluence Cloud. You can only manually export whiteboards as PDF, PNG, or JPG:
When migrating whiteboards from Confluence to SharePoint, WikiTraccs currently uses a remote-controlled browser to open the whiteboard and export it as PNG, by automating the button clicks. This works, but doesn’t satisfy the common asks from users: export whiteboards as CSV, JSON, or any other format that can be processed further.
A proper whiteboard data export would benefit all users, whether they migrate to SharePoint Online or to other environments.
Demand for Whiteboard Exports
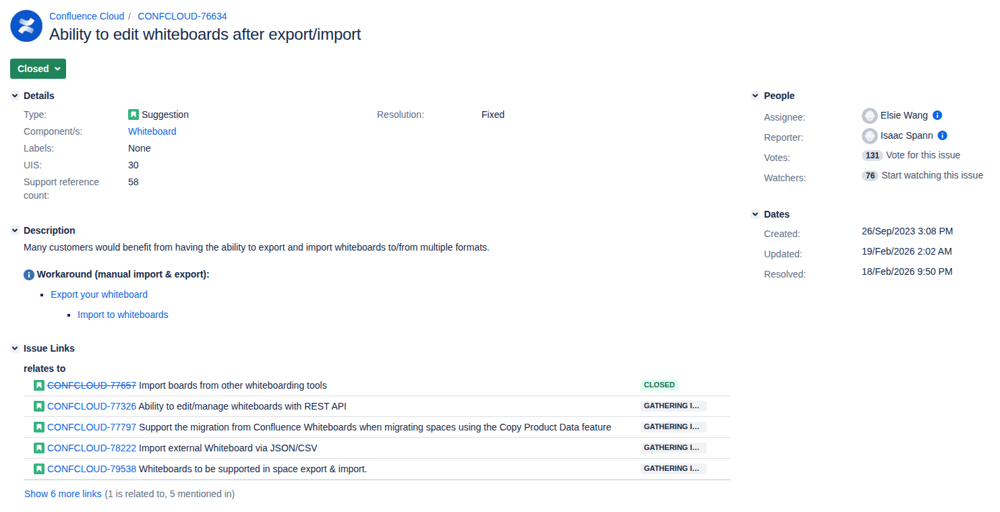
The main feature request seems to be CONFCLOUD-76634: “Ability to edit whiteboards after export/import”. It has (as of writing this) 131 votes, 76 watchers, and 58 linked support cases. It is the highest-voted whiteboard export ticket and was created in September 2023. Atlassian has since marked the ticket as Closed, even though no structured-export functionality has shipped to the public:
There are also quite a few community posts regarding importing and exporting whiteboards, for example this (“Can we export a Whiteboard other than an image, so it is still useful?”) and this (“How to export/import Whiteboards from one system to another?”).
Atlassian documents that native whiteboard export today is PDF, PNG, JPG only - no SVG, VSDX, draw.io, or any other structured format like JSON or CSV:

The public Confluence Cloud REST v2 supports only create / get / delete on whiteboard metadata (id, title, status, parent, space, author, owner, created date, version, links). It does not expose any elements, coordinates, shape definitions, connectors, text content, or other diagram content.
So, if there is no official means to export whiteboards, maybe we can build something ourselves?
How a Whiteboard Loads in the Browser
First, we need to understand how whiteboards work. We’ll focus on where the whiteboard data comes from, less on the actual rendering engine.
Each whiteboard has a UUID that looks like aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee - this is different from the usual page ID format.
When opening a whiteboard, it renders inside an iframe at https://COMPANY.atlassian.net/whiteboards/whiteboard/aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee?....
JavaScript for the whiteboard editor loads from (e.g.) canvas-frontend.prod-east.frontend.public.atl-paas.net, a publicly accessible endpoint.
Whiteboard data is loaded from https://COMPANY.atlassian.net/gateway/api/canvas-tenant-context/site/11111111-2222-3333-4444-555555555555/api/_internal/collab/aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee (11111111-2222-3333-4444-555555555555 is the Confluence site ID), an endpoint that is neither part of the official REST API, nor does it accept a personal access token for authentication.
Whiteboard media is loaded from https://api.media.atlassian.com/file/99999999-1234-5678-9abc-deadbeefcafe/binary?..., the same endpoint that powers page attachments.
Stickers are loaded from https://canvas-frontend.prod-east.frontend.public.atl-paas.net/assets/AtlassianStickers-<id>.<hash>.webp, a publicly accessible endpoint.
The Whiteboard Data Format
The data that goes over the wire when the editor calls https://COMPANY.atlassian.net/gateway/api/canvas-tenant-context/site/SITEID/api/_internal/collab/WHITEBOARDID is a Yjs CRDT update payload (binary). Yjs is open-source and MIT-licensed: https://github.com/yjs/yjs.
Yjs is schema-less by design. Each app that uses Yjs (BlockNote, tldraw, Excalidraw collab, Liveblocks, Confluence whiteboards…) stores its own scene model inside. Schemas are mutually unreadable and schema interpretation is per-application.
Atlassian internally calls their structured representation WDF - Whiteboards Document Format, described as “a serializable data format for making whiteboard content portable”. No public WDF schema, API, parser, or converter exists.
For AI-generated/edited whiteboards (Rovo Canvas), Atlassian uses SVG as an internal intermediate between the LLM and the native whiteboard, as documented in this Inside Atlassian blog post:

Existing Third-Party Converters
No public converter (that I know of) exists for: WDF → SVG, WDF → VSDX, WDF → draw.io, WDF → JSON Canvas, WDF → Excalidraw, WDF → tldraw, or any other target. Generic Y-Doc-to-X converters do not exist for the same reason WDF parsers don’t - Yjs is schema-less, every app’s scene model differs.
Takeaway and Next Steps
We now have two important pieces at our hands which can pave the way to exporting Confluence Cloud whiteboards to other data formats than just images:
- Whiteboard data is represented in a binary-encoded Yjs format; this (product-agnostic) format is documented and parsers are available
- WikiTraccs already opens a live browser that shows a whiteboard for image export; whiteboard data already lives in this browser
So, data is available and the general format is known. We only need a way to get the whiteboard data out of the browser and to understand the schema that Atlassian uses to represent whiteboard content.
In the next post, we’ll look at a WikiTraccs proof-of-concept that takes this all the way: extracting the Yjs payload from a live whiteboard, decoding Atlassian’s WDF scene model, and converting it into an editable draw.io diagram - a first structured export path for Confluence whiteboards.
Configuring Sites.Selected Authentication for WikiTraccs
Most WikiTraccs migrations sign in with a user account. For hands-on work that is the easiest path.
Some environments rule that out: automation is required, or the security team does not allow a tenant-wide app permission. The combination of Sites.Selected (app-only) and certificate authentication fits both cases. Access is granted per target site, and WikiTraccs signs in as the application itself.
Why Sites.Selected, and why a certificate?
There are two common drivers:
- Automation. A scheduled or scripted Confluence to SharePoint migration run cannot wait for a browser sign-in. Certificate authentication removes the migration user from the picture.
- Security posture. An app with
Sites.FullControl.Allat the tenant scope can reach every site.Sites.Selectedstarts with the app having no access at all; an admin adds it to each target site explicitly. Configuration stays auditable and easy to revoke.
Either motivation leads to the same setup: an Entra ID app with Sites.Selected application permission, a certificate credential, and a FullControl grant on every site WikiTraccs will touch.
How to grant per-site FullControl
Here are three options to grant an app permissions on specific sites:
- PnP PowerShell -
Grant-PnPAzureADAppSitePermission. One cmdlet per site. Requires PnP PowerShell and the PnP Management Shell app admin-consented in the tenant. - Microsoft Graph Explorer - a browser tool at developer.microsoft.com/graph/graph-explorer. REST calls pasted into the URL bar.
- Scripting Microsoft Graph directly - curl,
Invoke-RestMethod, or any HTTP client. Same calls as Graph Explorer.
All three call the same endpoint: POST /sites/{site-id}/permissions.
In this post we use the Microsoft Graph Explorer because it needs no installation.
Prerequisites
Accounts and roles
You need an account that:
- holds the SharePoint Administrator directory role (or higher), and
- can consent to
Sites.FullControl.Allfor Graph Explorer. A Global Administrator must grant that consent once - either tenant-wide, or individually for themselves.
Running the entire configuration as a Global Administrator is the simplest option. Global Admin covers the role requirement of POST /sites/{id}/permissions and can self-consent to Sites.FullControl.All without making the scope available tenant-wide.
Entra ID application
You need an app registration with a certificate. See Registering WikiTraccs as App in Entra ID for the basic registration flow.
For Sites.Selected, three details differ from the interactive-auth flow:
- Permission type: Under API permissions, pick Application permissions (not Delegated permissions).
- Permissions: Add
Sites.Selectedon both Microsoft Graph and SharePoint. WikiTraccs talks to SharePoint through both APIs; each needs its own grant. - Credential: Under Certificates & secrets, Certificates tab, upload the public key of your certificate (
.ceror.pem). The.pfxwith the private key stays on the migration machine. Do not upload the.pfx.
After adding both Sites.Selected rows, click Grant admin consent for [Tenant]. Both rows must show the green “Granted for [Tenant]” checkmark.
Note
Sites.Selected requires admin consent even though it grants no access on its own. Consent only tells Entra ID that the app may request site access. Each target site must still be granted separately.Target SharePoint sites
The following SharePoint sites matter:
- the WikiTraccs site, where WikiTraccs stores its lists (space inventory, user/group mapping, page transactions, content snapshots)
- the target sites, where Confluence content lands
Grant FullControl to the app on each. For multiple target sites, grant each one. Refer to the next section on how to do that via Microsoft Graph Explorer.
Configuring with Microsoft Graph Explorer
Open developer.microsoft.com/graph/graph-explorer and sign in with your Global Administrator account.
Consent to the required scope
Assumption
This walkthrough assumes thatSites.Selected has not yet been granted on the app registration. Under that assumption, a Global Administrator is needed for the steps below. Other flows can achieve the same goal; this post takes the most direct one.Open the Modify Permissions tab (next to Request Body, Request Headers, Access token). Find Sites.FullControl.All (Delegated) and click Consent.
When the sign-in dialog appears, leave the “Consent on behalf of your organization” checkbox unchecked. As a Global Administrator you can self-consent without granting the scope to every user in the tenant. Click Accept.
To verify that the scope landed on the token, open the Access token tab, copy the JWT, paste it into jwt.ms, and check that the scp claim contains Sites.FullControl.All. If consent was done mid-session and the token predates it, sign out and back in.
Resolve each site’s ID
Microsoft Graph identifies SharePoint sites by a composite ID of the form <hostname>,<site-collection-guid>,<web-guid>. Given a URL path, Graph Explorer returns that composite ID.
Set the verb dropdown to GET and paste this URL into the URL bar:
https://graph.microsoft.com/v1.0/sites/<tenant>.sharepoint.com:/sites/<SITENAME>
For a tenant called contoso and a site named Marketing, the URL looks like this:
https://graph.microsoft.com/v1.0/sites/contoso.sharepoint.com:/sites/Marketing
Click Run query.
Copy the id field from the response. For the example above, the response contains something like:
{
"id": "contoso.sharepoint.com,e3a1c643-6d61-4847-b4f2-b1449917e667,59c6df0e-f8b9-4069-a681-304929c3e132",
"webUrl": "https://contoso.sharepoint.com/sites/Marketing"
}
Repeat for every site. Keep the commas intact when pasting the ID later; do not URL-encode them.
Grant FullControl to the app
Switch the verb dropdown to POST and paste this URL into the URL bar:
https://graph.microsoft.com/v1.0/sites/<site-id>/permissions
For the site ID resolved in the previous step, the URL looks like this:
https://graph.microsoft.com/v1.0/sites/contoso.sharepoint.com,e3a1c643-6d61-4847-b4f2-b1449917e667,59c6df0e-f8b9-4069-a681-304929c3e132/permissions
In the Request Body tab, paste the JSON below:
{
"roles": ["fullcontrol"],
"grantedToIdentities": [
{
"application": {
"id": "<your-client-id>",
"displayName": "WikiTraccs Migration Tool"
}
}
]
}
Replace <your-client-id> with your Entra ID app’s client ID. The displayName is echoed back by Microsoft but not validated; any human-readable string works. A filled-in body looks like this:
{
"roles": ["fullcontrol"],
"grantedToIdentities": [
{
"application": {
"id": "823f5a22-be23-457a-beda-6adafc50d758",
"displayName": "WikiTraccs Migration Tool"
}
}
]
}
Click Run query. 201 Created means success. Repeat for every site.
Valid roles: read, write, manage, fullcontrol. WikiTraccs requires fullcontrol.
Verify the grants
Switch the verb dropdown back to GET, paste this URL into the URL bar, and click Run query:
https://graph.microsoft.com/v1.0/sites/<site-id>/permissions
For the site ID from the earlier example, the URL looks like this:
https://graph.microsoft.com/v1.0/sites/contoso.sharepoint.com,e3a1c643-6d61-4847-b4f2-b1449917e667,59c6df0e-f8b9-4069-a681-304929c3e132/permissions
Each site should show at least one entry with roles: ["fullcontrol"] and the application’s id set to your app’s client ID. The response looks like this:
{
"value": [
{
"id": "aTowaS50fG1zLnNwLmV4dHw4MjNmNWEyMi1iZTIzLTQ1N2EtYmVkYS02YWRhZmM1MGQ3NThAOWY0ZGMxODItMDM1My00ZWUxLWI5ZmEtMjI1Y2UxMDQ0MDZi",
"roles": ["fullcontrol"],
"grantedToIdentitiesV2": [
{
"application": {
"id": "823f5a22-be23-457a-beda-6adafc50d758",
"displayName": "WikiTraccs Migration Tool"
}
}
],
"grantedToIdentities": [
{
"application": {
"id": "823f5a22-be23-457a-beda-6adafc50d758",
"displayName": "WikiTraccs Migration Tool"
}
}
]
}
]
}
Common pitfalls
403 Forbiddenon the POST. Check in this order:- On the app registration’s API permissions page, both
Sites.Selectedrows show the green “Granted for [Tenant]” checkmark. Missing admin consent here is the most common cause. - The signed-in user has at least Read on the target site. This matters when the site was created by a different user - add the user to the site’s Visitors group and retry.
- Per Microsoft’s documentation, the signed-in user should also hold a SharePoint Administrator directory role or higher for this endpoint. Running the configuration as a Global Administrator satisfies this.
- On the app registration’s API permissions page, both
400 invalidRequestwith “application not found”. Client ID typo, or the app is in a different tenant than the signed-in account.
Using the certificate in WikiTraccs
Once the app has Sites.Selected consent and holds FullControl on every target site, WikiTraccs needs the tenant ID, the app’s client ID, and the certificate reference.
Via WikiTraccs.GUI (the blue window)
Note
GUI support for certificate authentication is available as of WikiTraccs v1.33.30.In WikiTraccs.GUI:
Under SharePoint authentication type, select Cert.
Fill Tenant ID and Entra ID Application Client ID in the corresponding fields shown above.
In the Certificate field, enter either:
- the path to the
.pfxfile (absolute or relative; relative paths resolve against the working directory), or - the SHA-1 thumbprint of a certificate in the Windows certificate store (
CurrentUser\MyorLocalMachine\My).
A 40-character hex string is treated as a thumbprint, anything else as a file path.
- the path to the
Click Verify. WikiTraccs loads the certificate and shows the subject and expiration date on success.
- For a PFX file path, WikiTraccs prompts for the password if the file is password-protected. The entered password is stored in plain-text in the configuration file, so subsequent runs do not prompt.
- For a thumbprint, no password prompt appears. The private key is already accessible through the Windows certificate store under the Windows user account that runs WikiTraccs.
At migration start, WikiTraccs loads the certificate again to verify that everything is still in place. If the cert cannot be loaded, the migration aborts with a clear error.
Reference: Certificate authentication.
Via WikiTraccs.Console (unattended)
For scheduled or automated runs, configure WikiTraccs via appsettings.json instead of the GUI. Set AuthenticationType to apponlywithcertificate and fill the AuthenticationParameterSetAppOnlyAadCertificate block with either a path + password or a thumbprint.
See Run an Automated Confluence to SharePoint Migration for the full sample configuration.
Known limitation: link fixer and SharePoint Search
WikiTraccs’ link fixer uses SharePoint Search as one of its fallbacks, and SharePoint Search is not available under Sites.Selected with app-only authentication. This is a limitation set by Microsoft.
The impact in WikiTraccs: migrations complete without errors. Link fixing itself continues to work - the ContentSnapshots list resolves most links, including cross-site ones. What becomes unavailable is the Search-based fallback used when the snapshot lookup misses. A small number of links may therefore stay unresolved.
Two workarounds exist: use delegated authentication, or swap Sites.Selected for Sites.FullControl.All (application). The second option defeats the point of this setup - it grants tenant-wide SharePoint access - and is mentioned only for completeness.
Why not delegated Sites.Selected?
Can the same per-site scoping be achieved with delegated Sites.Selected permissions and interactive sign-in? Unfortunately not. Microsoft added delegated Sites.Selected for the Microsoft Graph API in February 2024, but the SharePoint REST and CSOM endpoints, which WikiTraccs uses under the hood, do not honor that scope.
A change is unlikely in the near term. WikiTraccs cannot route everything through Microsoft Graph because the Graph Pages API does not yet cover the operations a migration needs; many operations still require SharePoint REST and CSOM. Until Microsoft closes the gaps, Sites.Selected scoping is only available in app-only mode with a certificate, as described in the rest of this post.
Wrap-up
Sites.Selected with certificate authentication is one of the most locked-down WikiTraccs setups, on par with delegated authentication where the migration user only has access to the target sites. Once configured, operation is clean: there is no migration user to maintain, and no tenant-wide app access to defend in security reviews. Each target-site grant is explicit and auditable.
Setup is one-time: register the app, upload the certificate public key, admin-consent the Sites.Selected rows, and run one POST /sites/{id}/permissions per site. Those steps can be automated, for example via PnP PowerShell.
For full migration automation, see Run an Automated Confluence to SharePoint Migration. That said, Interactive authentication remains the easiest option and can be just as secure when configured properly.
Try WikiTraccs!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
Stop and Resume a Migration Run at Any Time
Every migration run follows the same pattern: WikiTraccs connects to Confluence, asks which content needs to be migrated, then checks SharePoint for what is already there. Whatever is missing gets created. This makes every run inherently resumable.
How WikiTraccs Handles Existing Content
When WikiTraccs finds a page that already exists in SharePoint, it does one of two things depending on your configuration:
- Leave it alone (default): If the page already exists in SharePoint, WikiTraccs skips it and moves on to the next one.
- Overwrite outdated pages: If enabled, WikiTraccs compares the Confluence page’s last modification date with the date it was last transferred to SharePoint. If the page has been modified since, WikiTraccs overwrites the SharePoint page with the latest content.
The overwrite behavior is controlled by the Update outdated SharePoint pages setting. See Update Outdated Pages for details on how to enable it and what it does.
Stop and Resume
You can stop a migration run at any time by clicking the Stop run button in the WikiTraccs GUI (since WikiTraccs 1.33.21), or by pressing Ctrl+C in the black console window. The current page transfer completes, then the application shuts down gracefully.
To resume, just start the migration again. WikiTraccs will check Confluence and SharePoint, determine what is still missing, and continue from there. Pages that were already migrated are either skipped or updated, depending on your settings.
This also covers unplanned interruptions. If the application crashes, your machine restarts, or the network drops - simply run the migration again. WikiTraccs picks up where it left off. No manual bookkeeping, no restart files, no risk of duplicating content.
Confluence Instances in the Wild
This is a growing collection of publicly accessible Confluence instances found on the web by automated scanning. It serves as a research resource to understand which Confluence versions and macros are in use out there.
Public Live Instances
| URL | Title | Version | Type | Last Accessed |
|---|---|---|---|---|
iesckb.info-electronics.net | Info-Electronics KB | 5.6.3 | Server | 2026-04-07 |
confluence.logix-works.com | Logix Works Confluence | 7.7.2 | Server | 2026-04-07 |
conf.casualarts.uk | Casual Arts Confluence | 7.12.3 | Server | 2026-04-07 |
confluence.jet-stream.nl | Jet-Stream Confluence | 7.13.7 | Server | 2026-04-07 |
docs.mayeryn.com | Mayeryn Docs | 7.15.0 | Server | 2026-04-07 |
conftest.itdepcat.tech | ITDepCat Confluence (Test) | 7.19.5 | Server? | 2026-04-07 |
wiki.rice.edu/confluence | Rice University Campus Wiki | 7.19.16 | Server? | 2026-04-06 |
teamwork.gigaset.com/gigawiki | Gigaset PRO Public Wiki | 7.19.17 | Server? | 2026-04-06 |
wiki.gamesmaster-hamburg.de | HAW Hamburg GamesLab Wiki | 7.19.17 | Server? | 2026-04-06 |
public.o-ran.org | O-RAN Portal | 7.19.17 | Server? | 2026-04-07 |
csv-letovice.cz | ČSV Letovice | 7.19.17 | Server? | 2026-04-07 |
vm-atlas.psur.cornell.edu | Cornell PRL Service Bureau | 7.19.18 | Data Center | 2026-04-07 |
wikis.mit.edu/confluence | MIT Wiki Service | 7.19.30 | Data Center | 2026-04-06 |
confluence.droplet-innovations.de | Droplet Innovations Confluence | 8.5.3 | Data Center | 2026-04-07 |
confluence.cradle.buas.nl | BUas CRADLE Confluence | 8.5.4 | Data Center | 2026-04-07 |
imi.buas.nl | BUas IMI Confluence | 8.5.4 | Data Center | 2026-04-07 |
confluence.getxray.app | GetXray Documentation | 8.5.4 | Data Center | 2026-04-07 |
wiki.freifunk-muensterland.de | Freifunk Münster Wiki | 8.5.4 | Data Center | 2026-04-07 |
support.stresstimulus.com | StresStimulus Documentation | 8.5.4 | Data Center | 2026-04-07 |
confluence.nanofab.ualberta.ca | nanoFAB Knowledge Base | 8.5.5 | Data Center | 2026-04-06 |
confluence.geacom.cloud | Geacom Confluence | 8.5.5 | Data Center | 2026-04-07 |
workflowhelp.kodak.com | Kodak Workflow Documentation | 8.5.5 | Data Center | 2026-04-07 |
conflux.uni-leipzig.de | Uni Leipzig Conflux | 8.5.6 | Data Center | 2026-04-07 |
hilfe.telematica.at | Telematica Help | 8.5.6 | Data Center | 2026-04-07 |
wiki.alabs.space | ALabs Wiki | 8.5.16 | Data Center | 2026-04-07 |
confluence.lowell.edu | Lowell Observatory Confluence | 8.5.21 | Data Center | 2026-04-07 |
confluence.skatelescope.org | SKA Observatory Confluence | 8.5.26 | Data Center | 2026-04-06 |
confluence.ecmwf.int | ECMWF Confluence Wiki | 8.5.27 | Data Center | 2026-04-06 |
info.cis.kit.ac.jp | KIT Confluence (Kyoto Inst. of Technology) | 8.5.28 | Data Center | 2026-04-07 |
cwiki.apache.org/confluence | Apache Software Foundation | 8.5.31 | Data Center | 2026-04-06 |
wiki.lyrasis.org | LYRASIS Wiki | 8.5.31 | Data Center | 2026-04-06 |
wiki.refeds.org | REFEDS Wiki | 8.5.31 | Data Center | 2026-04-06 |
wiki.jmehan.com | wiki.jmehan.com | 8.5.31 | Data Center | 2026-04-06 |
confluence.ggwork.org | GGWork Confluence | 8.9.3 | Data Center | 2026-04-07 |
confluence.designplanet.ua | Design Planet Confluence | 8.9.8 | Data Center | 2026-04-07 |
dallas9-confluence.radbeedev.com | Dallas9 Confluence | 9.2.0 | Data Center | 2026-04-07 |
confluence.paradigm.plan-sys.com | Paradigm Confluence | 9.2.1 | Data Center | 2026-04-07 |
wiki.credit.club | CreditClub Confluence | 9.2.3 | Data Center | 2026-04-07 |
confluence.cwf.org | CWF Confluence | 9.2.7 | Data Center | 2026-04-07 |
wiki.ohie.org | OpenHIE Wiki | 9.2.10 | Data Center | 2026-04-06 |
wiki.ncsa.illinois.edu | NCSA Wiki | 9.2.10 | Data Center | 2026-04-06 |
confluence.norbit.com | Norbit Confluence | 9.2.10 | Data Center | 2026-04-07 |
confluence.i2cat.net | i2CAT Confluence | 9.2.12 | Data Center | 2026-04-07 |
confluence.cornell.edu | Cornell University Wiki | 9.2.13 | Data Center | 2026-04-06 |
confluence.atlassian.com | Atlassian Documentation | 9.2.13 | Data Center | 2026-04-06 |
wiki.qlever.com | Qlever Confluence | 9.2.13 | Data Center | 2026-04-07 |
wiki.nci.nih.gov | National Cancer Institute - DTRSS Wiki | 9.2.15 | Data Center | 2026-04-06 |
confluence.slac.stanford.edu | SLAC Confluence | 9.2.15 | Data Center | 2026-04-06 |
wiki.sei.cmu.edu/confluence | SEI CMU Wiki | 9.2.15 | Data Center | 2026-04-06 |
servicedesk.surf.nl/wiki | SURF User Knowledge Base | 9.2.15 | Data Center | 2026-04-06 |
portal.nordu.net | NORDUnet Portal | 9.2.15 | Data Center | 2026-04-06 |
confluence.softronic.se | Softronic Confluence | 9.2.15 | Data Center | 2026-04-07 |
wiki.sunet.se | Sunet Wiki (Swedish University Network) | 9.2.15 | Data Center | 2026-04-07 |
portal.ziton.eu | ZITON Portal | 9.2.15 | Data Center | 2026-04-07 |
confluence.som.yale.edu | Yale SOM Confluence | 9.2.15 | Data Center | 2026-04-07 |
confluence.uwf.edu | UWF Public KB | 9.2.15 | Data Center | 2026-04-07 |
mywiki.leuphana.de | Leuphana University Wiki | 9.2.15 | Data Center | 2026-04-07 |
wiki-test.k10plus.de | K10plus Wiki | 9.2.15 | Data Center | 2026-04-07 |
wiki.geant.org | GÉANT Federated Confluence | 9.2.17 | Data Center | 2026-04-06 |
confluence.terena.org | GÉANT Federated Confluence (TERENA) | 9.2.17 | Data Center | 2026-04-06 |
wiki.openjdk.org | OpenJDK Wiki | 9.2.17 | Data Center | 2026-04-06 |
infos.seibert.group | Seibert Group Info Portal | 9.2.17 | Data Center | 2026-04-06 |
confluence.csiro.au | CSIRO Confluence | 9.2.17 | Data Center | 2026-04-06 |
wiki.earthdata.nasa.gov | Earthdata Wiki (NASA) | 9.2.17 | Data Center | 2026-04-06 |
wiki.ucar.edu | UCAR Wiki | 9.2.17 | Data Center | 2026-04-06 |
confluence.rowan.edu | Rowan University Confluence | 9.2.17 | Data Center | 2026-04-06 |
confluence.snomedtools.org | SNOMED Tools Confluence | 9.2.17 | Data Center | 2026-04-06 |
www.wiki.ed.ac.uk | Wiki Service (University of Edinburgh) | 9.2.17 | Data Center | 2026-04-06 |
wiki.ut.ee | TÜ Wiki (University of Tartu) | 9.2.17 | Data Center | 2026-04-07 |
docs.cipher.com.ua | Cipher Confluence | 9.2.17 | Data Center | 2026-04-07 |
confluence.devops.va.gov | US Veterans Affairs Confluence | 9.2.17 | Data Center | 2026-04-07 |
ns-glassboro-confluence.rowan.edu | Rowan University Confluence (Glassboro) | 9.2.17 | Data Center | 2026-04-07 |
kid.hebis.de | HeBIS KID | 9.2.17 | Data Center | 2026-04-07 |
kb.ucar.edu | NCAR/UCAR Knowledge Base | 9.2.17 | Data Center | 2026-04-07 |
pconfkb.mcmaster.ca | McMaster University KB | 9.2.17 | Data Center | 2026-04-07 |
docs.axxonsoft.com/confluence | AxxonSoft Documentation | 9.4.1 | Data Center | 2026-04-07 |
confluence.tracon.fi | Tracon Confluence | 10.0.3 | Data Center | 2026-04-07 |
confluence.wjd.de | WJ Deutschland Confluence | 10.2.1 | Data Center | 2026-04-07 |
confluence.ifca.es | IFCA Confluence | 10.2.1 | Data Center | 2026-04-07 |
wiki.unece.org | UNECE Wiki | 10.2.2 | Data Center | 2026-04-06 |
userwikis.fu-berlin.de | Userwikis der Freien Universität | 10.2.6 | Data Center | 2026-04-07 |
confluence.infn.it | INFN Confluence (Italian Nuclear Physics) | 10.2.6 | Data Center | 2026-04-07 |
wiki.ceh.ac.uk | CEH Wiki (UK Centre for Ecology & Hydrology) | 10.2.7 | Data Center | 2026-04-06 |
wiki.bwa.no | BWA Wiki | 10.2.7 | Data Center | 2026-04-07 |
conf.n3.com.ua | Foxtrot Service Portal | 10.2.7 | Data Center | 2026-04-07 |
confluence.omegav.no | OmegaV Wiki | 10.2.7 | Data Center | 2026-04-07 |
unlimited.ethz.ch | ETH Zurich Confluence | 10.2.7 | Data Center | 2026-04-07 |
Restricted Live Instances
These instances require sign-in but expose their version number on the login page or via the REST API. Useful for tracking which versions are in active use.
| URL | Version | Type | Last Accessed |
|---|---|---|---|
support.leadpoint.com | 6.5.2 | Server | 2026-04-07 |
wiki.crccredc.com | 6.9.3 | Server | 2026-04-07 |
confluence.ph2m.fr | 6.15.2 | Server | 2026-04-07 |
quectel.com | 7.13.2 | Server | 2026-04-07 |
wiki.ib-fennen.com | 7.13.7 | Server | 2026-04-07 |
za-confluence1.inline.de | 7.13.7 | Server | 2026-04-07 |
ingenta.com | 7.13.7 | Server | 2026-04-07 |
civicahealth.com.au | 7.19.7 | Data Center | 2026-04-07 |
td-berlin.com | 7.19.11 | Data Center | 2026-04-07 |
wiki.collab.cra.com | 7.19.16 | Server? | 2026-04-07 |
caelum.aimservices.tech | 7.19.17 | Server? | 2026-04-07 |
qm.eagletech.net.au | 7.19.17 | Server? | 2026-04-07 |
confluence.gk-software.com | 7.19.17 | Server? | 2026-04-07 |
confluence.marketcomllc.com | 7.19.19 | Data Center | 2026-04-07 |
atomi.com.vn | 7.19.30 | Data Center | 2026-04-07 |
confluence.7puentes.com | 8.5.4 | Data Center | 2026-04-07 |
doku.dart-racing.de | 8.5.4 | Data Center | 2026-04-07 |
boxed-it.com | 8.5.4 | Data Center | 2026-04-07 |
confluence.cuas.at | 8.5.4 | Data Center | 2026-04-07 |
confluence.intert.co.kr | 8.5.5 | Data Center | 2026-04-07 |
confluence.einstein-motorsport.com | 8.5.5 | Data Center | 2026-04-07 |
confluence.cursor.agency | 8.5.6 | Data Center | 2026-04-07 |
data4group.com | 8.5.10 | Data Center | 2026-04-07 |
ods-confluence-data-center.do.gitguardian.dev | 8.5.15 | Data Center | 2026-04-07 |
confluence-vnv.vinova.sg | 8.5.16 | Data Center | 2026-04-07 |
base.tokenique.org | 8.5.17 | Data Center | 2026-04-07 |
wiki.silverrailtech.net | 8.5.18 | Data Center | 2026-04-07 |
confluence.tekmates.pro | 8.5.19 | Data Center | 2026-04-07 |
togg.com.tr | 8.5.19 | Data Center | 2026-04-07 |
elektro-stoll.de | 8.5.24 | Data Center | 2026-04-07 |
hyperproof.us | 8.6.1 | Data Center | 2026-04-07 |
doc.dipnet.vn | 8.7.1 | Data Center | 2026-04-07 |
conf.x-or.cloud | 8.7.2 | Data Center | 2026-04-07 |
confluence.kash.uz | 8.8.1 | Data Center | 2026-04-07 |
wiki.egi.eu | 8.9.8 | Data Center | 2026-04-07 |
confluence.aurma.kz | 9.0.3 | Data Center | 2026-04-07 |
confluence.switch.ch | 9.2.1 | Data Center | 2026-04-06 |
fcdarwin.org.ec | 9.2.3 | Data Center | 2026-04-07 |
confluence.d3cyber.eu | 9.2.7 | Data Center | 2026-04-07 |
wiki.twn.ee | 9.2.9 | Data Center | 2026-04-07 |
sonimcloud.com | 9.2.12 | Data Center | 2026-04-07 |
confluence.mytechfriends.com | 9.2.13 | Data Center | 2026-04-07 |
confluence.siemens-healthineers.com | 9.2.13 | Data Center | 2026-04-07 |
confluence.bsh-group.com | 9.2.13 | Data Center | 2026-04-07 |
share.getty.edu | 9.2.15 | Data Center | 2026-04-07 |
team.innogames.de | 9.2.15 | Data Center | 2026-04-07 |
iridium.com | 9.2.15 | Data Center | 2026-04-07 |
confluence.axway.com | 9.2.15 | Data Center | 2026-04-07 |
wiki.codev.mitre.org | 9.2.15 | Data Center | 2026-04-07 |
confluence.uoregon.edu | 9.2.15 | Data Center | 2026-04-07 |
confluence.tup.com | 9.2.15 | Data Center | 2026-04-07 |
confluence.smhi.tds.tieto.com | 9.2.15 | Data Center | 2026-04-07 |
confluence.hs-osnabrueck.de | 9.2.15 | Data Center | 2026-04-07 |
confluence.magnaint.net | 9.2.15 | Data Center | 2026-04-07 |
confluence.nttdata-solutions.com | 9.2.15 | Data Center | 2026-04-07 |
plex.init.mpg.de | 9.2.15 | Data Center | 2026-04-07 |
cmext.ahrq.gov/confluence | 9.2.17 | Data Center | 2026-04-06 |
kb.data-experts.de | 9.2.17 | Data Center | 2026-04-07 |
confluence.zenseact.com | 9.2.17 | Data Center | 2026-04-07 |
wiki.qa-app.pconnect.biz | 9.2.17 | Data Center | 2026-04-07 |
confluence.bg-prevent.de | 9.2.17 | Data Center | 2026-04-07 |
adesso-mobile.de | 9.2.17 | Data Center | 2026-04-07 |
confluence.mobilife.io | 9.3.1 | Data Center | 2026-04-07 |
confl.syntech-gmbh.com | 9.3.2 | Data Center | 2026-04-07 |
confluence.paymatrix.me | 9.3.2 | Data Center | 2026-04-07 |
confluence.skymasters.ae | 10.1.0 | Data Center | 2026-04-07 |
confluence.gpgov.us | 10.2.1 | Data Center | 2026-04-07 |
iotsquared.io | 10.2.2 | Data Center | 2026-04-07 |
confluence.disc-soft.com | 10.2.3 | Data Center | 2026-04-07 |
aeolus.esa.int | 10.2.6 | Data Center | 2026-04-07 |
confluence.perbility.de | 10.2.7 | Data Center | 2026-04-07 |
confluence.cdrin.com | 10.2.7 | Data Center | 2026-04-07 |
confluence.supanz.net | 10.2.7 | Data Center | 2026-04-07 |
Inaccessible, Protected, or Gone Instances
These URLs were candidates but could not be automatically verified. They may still be Confluence instances behind authentication, firewalls, or have migrated to Cloud.
Authentication Required (401/403)
| URL | Status | Last Accessed |
|---|---|---|
confluence.jaytaala.com | 401 Unauthorized | 2026-04-06 |
wiki.nci.nih.gov (homepage) | 403 Forbidden | 2026-04-06 |
confluence.si.edu | 403 Forbidden | 2026-04-06 |
confluence.hl7.org | 405 Method Not Allowed | 2026-04-06 |
wiki.surfnet.nl | JavaScript required (WAF) | 2026-04-06 |
infinetwireless.com/wiki | Geo-blocked | 2026-04-06 |
docs.wso2.com | 403 Forbidden | 2026-04-06 |
confluence.appstate.edu | 403 Forbidden | 2026-04-06 |
confluence.columbia.edu/confluence | 403 Forbidden | 2026-04-06 |
confluence.cern.ch | Requires login | 2026-04-06 |
spaces.at.internet2.edu | 403 Forbidden | 2026-04-06 |
confluence.man.poznan.pl | 403 Forbidden | 2026-04-06 |
confluence.pnnl.gov | SSO redirect (Microsoft) | 2026-04-06 |
confluence.admin.cam.ac.uk | 403 Forbidden | 2026-04-06 |
www.baruch.cuny.edu/confluence | 403 Forbidden | 2026-04-06 |
demonstration.linchpin-intranet.net | ECONNREFUSED (Confluence) | 2026-04-06 |
wikis.nyu.edu | Certificate error | 2026-04-06 |
Connection Refused / Offline
| URL | Status | Last Accessed |
|---|---|---|
confluence.ucr.edu | ECONNREFUSED | 2026-04-06 |
confluencewiki.ucdavis.edu | ECONNREFUSED | 2026-04-06 |
confluence.dimdi.de | ECONNREFUSED | 2026-04-06 |
confluence.rutgers.edu | ECONNREFUSED | 2026-04-06 |
confluence.sfu.ca | ECONNREFUSED | 2026-04-06 |
confluence.ow2.org | ECONNREFUSED | 2026-04-06 |
wiki.panosc.eu | ECONNREFUSED | 2026-04-06 |
wiki.carnet.hr | ECONNREFUSED | 2026-04-06 |
wiki.osg-htc.org | ECONNREFUSED | 2026-04-06 |
confluence.csc.fi | ECONNREFUSED | 2026-04-06 |
confluence.oceanobservatories.org | ECONNREFUSED | 2026-04-06 |
confluence.exoplatform.org | ECONNREFUSED | 2026-04-06 |
wiki.scinethpc.ca | ECONNREFUSED | 2026-04-06 |
confluence.anu.edu.au | ECONNREFUSED | 2026-04-06 |
confluence.casel.org | ECONNREFUSED | 2026-04-06 |
wiki.dfg.de | ECONNREFUSED | 2026-04-06 |
wiki.kuali.org | ECONNREFUSED | 2026-04-06 |
confluence.educopia.org | ECONNREFUSED | 2026-04-06 |
confluence.govinfosecurity.com | ECONNREFUSED | 2026-04-06 |
wiki.canisius.edu | ECONNREFUSED | 2026-04-06 |
wikis.uit.tufts.edu/confluence | ECONNREFUSED | 2026-04-06 |
wiki.ohdsi.org | ECONNREFUSED | 2026-04-06 |
wiki.sonatype.org | ECONNREFUSED | 2026-04-06 |
wikihub.berkeley.edu | ECONNREFUSED | 2026-04-06 |
wiki.umms.med.umich.edu | ECONNREFUSED | 2026-04-06 |
wiki.med.umich.edu | ECONNREFUSED | 2026-04-06 |
tomtools.cern.ch/confluence | ECONNREFUSED | 2026-04-06 |
lib-confluence.princeton.edu | ECONNREFUSED | 2026-04-06 |
wiki.comalatech.com | ECONNREFUSED | 2026-04-06 |
transform.aia.org/confluence | ECONNREFUSED | 2026-04-06 |
wiki.itap.purdue.edu | ECONNREFUSED | 2026-04-06 |
wiki.csuchico.edu/confluence | ECONNREFUSED | 2026-04-06 |
Timeout
| URL | Status | Last Accessed |
|---|---|---|
wiki.onosproject.org | Timeout | 2026-04-06 |
wiki.cac.washington.edu | Timeout | 2026-04-06 |
confluence.its.virginia.edu | Timeout | 2026-04-06 |
wiki.doit.wisc.edu/confluence | Timeout | 2026-04-06 |
wiki.state.ma.us/confluence | Timeout | 2026-04-06 |
wiki.dlib.indiana.edu | Timeout | 2026-04-06 |
confluence.fnal.gov | Timeout | 2026-04-06 |
wiki.vg | Timeout | 2026-04-06 |
wiki.library.ucsf.edu | Timeout | 2026-04-06 |
wiki.bath.ac.uk | Timeout | 2026-04-06 |
Migrated to Cloud (301 to *.atlassian.net)
| URL | Redirects To | Last Accessed |
|---|---|---|
wiki.opnfv.org | lf-anuket.atlassian.net | 2026-04-06 |
wiki.onap.org | lf-onap.atlassian.net | 2026-04-06 |
wiki.openmrs.org | openmrs.atlassian.net | 2026-04-06 |
confluence.sakaiproject.org | sakaiproject.atlassian.net | 2026-04-06 |
wiki.opendaylight.org | lf-opendaylight.atlassian.net | 2026-04-06 |
wiki.hyperledger.org | lf-hyperledger.atlassian.net | 2026-04-06 |
wiki.jasig.org | apereo.atlassian.net | 2026-04-06 |
confluence.cc.lehigh.edu | lehigh.atlassian.net | 2026-04-06 |
wiki.harvard.edu/confluence | harvardwiki.atlassian.net | 2026-04-06 |
confluence.umd.edu | umd-dit.atlassian.net | 2026-04-06 |
wiki.duraspace.org | wiki.lyrasis.org | 2026-04-06 |
wiki.anuket.io | lf-anuket.atlassian.net | 2026-04-06 |
spaces.redhat.com | redhat.atlassian.net | 2026-04-06 |
wiki.imperial.ac.uk | imperialcollege.atlassian.net | 2026-04-06 |
wiki.nps.edu | SSO redirect (Microsoft) | 2026-04-06 |
community.icann.org | icann-community.atlassian.net | 2026-04-06 |
confluence.linuxfoundation.org | linuxfoundation.atlassian.net | 2026-04-06 |
wiki.pentaho.com | pentaho-public.atlassian.net | 2026-04-06 |
wikis.utexas.edu | cloud.wikis.utexas.edu (Cloud) | 2026-04-06 |
w3.alfresco.com/confluence | alfresco.atlassian.net | 2026-04-06 |
wiki.umbc.edu | umbc.atlassian.net | 2026-04-06 |
wissen.jugendpresse.de | jugendpresse.atlassian.net | 2026-04-06 |
contentanalytics.digital.accenture.com | acn-jirasca.atlassian.net | 2026-04-06 |
wiki.lfnetworking.org | lf-networking.atlassian.net | 2026-04-06 |
confluence.usf.edu | usfjira.atlassian.net | 2026-04-06 |
wikispaces.psu.edu | SharePoint (retired) | 2026-04-06 |
confluence.sdl.com | rws-dev.atlassian.net | 2026-04-06 |
confluence.dimagi.com | dimagi.atlassian.net | 2026-04-06 |
wiki.vcu.edu | wiki-vcu.atlassian.net | 2026-04-06 |
Not Confluence (Anymore)
| URL | Status | Last Accessed |
|---|---|---|
wiki.eclipse.org | 404 (not Confluence) | 2026-04-06 |
wiki.archlinux.org | Anubis protection (not Confluence) | 2026-04-06 |
wiki.documentfoundation.org | Anubis protection (not Confluence) | 2026-04-06 |
wiki.mozilla.org | 404 (not Confluence) | 2026-04-06 |
wiki.openstack.org | 404 (not Confluence) | 2026-04-06 |
wiki.shibboleth.net | 404 (not Confluence) | 2026-04-06 |
confluence.desy.de | Redirects to XWiki | 2026-04-06 |
confluence.qps.nl | Redirects to Scroll Help | 2026-04-06 |
wiki.dbpedia.org | Redirects to dbpedia.org | 2026-04-06 |
wiki.cantara.no | Redirects to GitHub Pages | 2026-04-06 |
wiki.ihe.net | 404 (not Confluence) | 2026-04-06 |
wiki.eosc-hub.eu | Certificate expired | 2026-04-06 |
confluence.wiki.com | 404 (not Confluence) | 2026-04-06 |
confluence.jetbrains.com | 404 (not Confluence) | 2026-04-06 |
wiki.magnolia-cms.com | 503 Service Unavailable | 2026-04-06 |
confluence.terracotta.org | 404 (not Confluence) | 2026-04-06 |
docs.jboss.org | 404 (not Confluence) | 2026-04-06 |
apps.icts.uiowa.edu/confluence | 404 (shut down Jan 2024) | 2026-04-06 |
wiki.automotivelinux.org | DokuWiki (not Confluence) | 2026-04-06 |
confluence.aps.anl.gov | Maintenance/failover page (not Confluence) | 2026-04-06 |
blink.ucsd.edu | 404 (not Confluence) | 2026-04-06 |
ccdsupport.com/confluence | Redirects to help center (not Confluence) | 2026-04-06 |
confluence.puppetlabs.com | Redirects to puppet.com (not Confluence) | 2026-04-06 |
wiki.asterisk.org | Redirects to docs.asterisk.org (not Confluence) | 2026-04-06 |
wiki.bethesda.net | XWiki (not Confluence) | 2026-04-06 |
wiki.uiowa.edu | Shut down (Jan 2024) | 2026-04-06 |
Macros in Use
Note: Work in progress. This list will grow as above publicly accessible instances are subjected to inventory scans using WikiTraccs.
| Instance | Macros |
|---|---|
wikis.mit.edu/confluence | composition-setup, section, column, excerpt-include, deck, card, toggle-cloak, cloak, note, code, roundrect, viewxls, viewdoc |
How to get the Scroll PDF template ID
If you configure WikiTraccs to export historical page versions through Scroll PDF Exporter, you might need the template ID of the Scroll PDF template you want to use.
WikiTraccs uses that ID in the Template ID setting of the historical PDF export configuration. If you need the broader context, read Migrate historical Confluence page versions as PDF with Scroll PDF Exporter.
There are two straightforward ways to get the template ID.
Option 1: Use the Scroll PDF template administration
This is your option if you can access the Scroll PDF Exporter administration in a Confluence space.
Open the Scroll PDF Exporter app in the space tools:
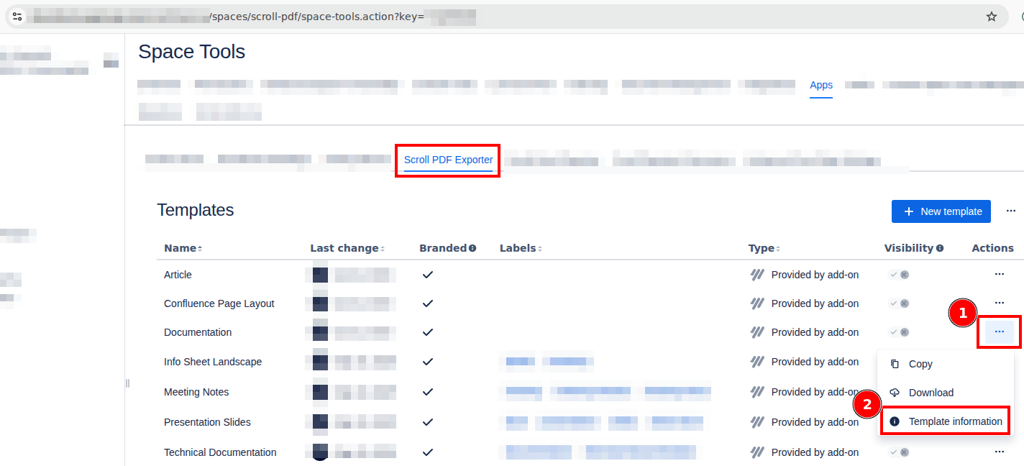
- Click the three dots to open the action menu of the desired template
- Click Template information
The dialog shows the template details, including the ID you can copy:
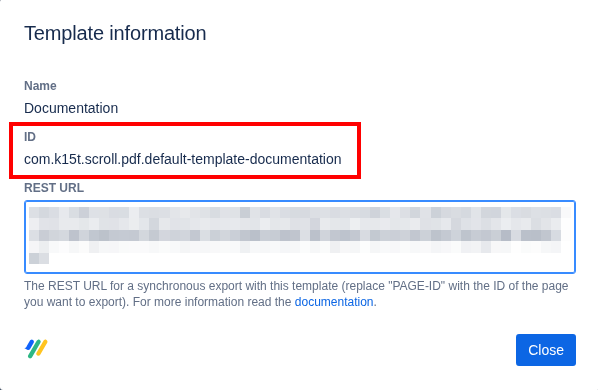
The value highlighted is the Scroll PDF template ID.
Option 2: Use the browser’s developer tools
If you want to confirm which template ID Confluence actually sends during export, or if the administration view is not available, you can inspect the export request in the browser.
- Open a Confluence page
- Open the browser Developer Tools (by pressing F12 or using the appropriate menu entry of your browser)
- Switch to the Network tab
- Start a manual Scroll PDF export with the template you want to use
- Find and click the
exportsrequest - Open the Payload tab
- Look for the
templateIdvalue
The export request payload contains the templateId value that was used for the manual export.
Wrap Up
You can get the Scroll PDF template ID either from the Scroll PDF Exporter administration or from the templateId field in the browser’s exports request payload.
That is the value used in WikiTraccs’ Template ID field for Scroll PDF Exporter integration.
Migrate historical Confluence page versions as PDF with Scroll PDF Exporter
Note: The functionality described in this post is available as of WikiTraccs 1.32.51
Prerequisites
The functionality described in this post does only work on-premises, using either WikiTraccs’ Interactive Authentication or token-based authentication. Confluence Cloud is not supported.WikiTraccs normally does not migrate historical page versions to SharePoint. Nevertheless, customers suggested that exporting older page versions as PDF files would help meet certain regulatory requirements. WikiTraccs now supports this with the help of the Scroll PDF Exporter plugin for Confluence.
Plugin Note
The Scroll PDF Exporter plugin is a commercial plugin and requires a license.
Export was tested on Confluence Data Center 8.9.8 with Scroll PDF Exporter 6.2.5 and Confluence Data Center 9.2.15 with Scroll PDF Exporter v6.3.1. Versions much older or newer than that might not work.
Tip
Read Exporting Historical Page Versions - It’s Complicated why the built-in Confluence PDF export is no good candidate for exporting historical page versions.Some customers want to limit the version export to page versions that are or were in Comala Document Management’s final state. WikiTraccs does support that as well.
Plugin Note
The Comala Document Management plugin is a commercial plugin and requires a license.
Final-state version selection was tested on Confluence Data Center 9.2.15 with Comala Document Management 7.14.6. Versions much older or newer than that might not work.
Configuration
In the WikiTraccs.GUI Settings menu, click Configure Transformation to open the Transformation Settings dialog. Click the Historical Export tab:
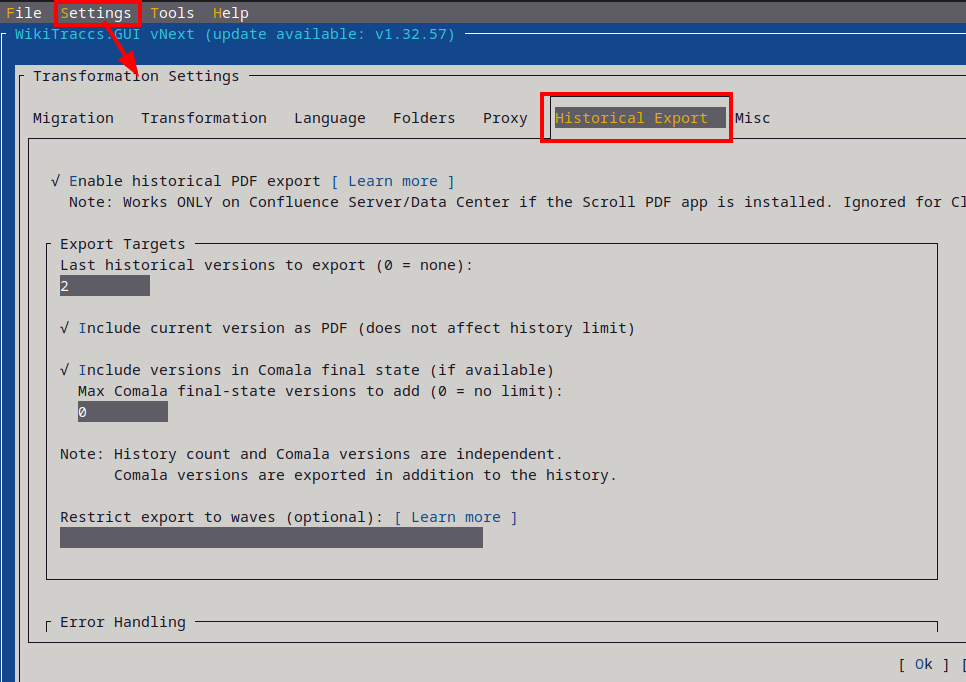
PDF export-related settings. Note that labels might have been changed, please refer to the text documentation below.
First, check Enable historical PDF export at the top. Then configure the sections below.
Export Targets
- Last historical versions to export - Number of most recent page versions to export from the Confluence history API. Set to
0to skip history-based export. This is independent of Comala final-state versions. - Include current version as PDF - Also export the current (latest) page version as a PDF file. This does not count toward the history limit above.
- Include versions in Comala final state - Look up page versions that Comala marked as final and export those as well. Comala versions are exported in addition to the history count.
- Max Comala final-state versions to add - Limit how many Comala final-state versions to include. Set to
0for no limit. - Restrict export to waves - Optional wave filter expression. Only pages matching the selected waves are exported. Use this if you want to (for example) export the history only from certain spaces.
Error Handling
- Continue when an export fails - If checked, WikiTraccs continues exporting remaining versions when one version fails. If unchecked, it stops exporting further versions for that page. Enabled by default.
- Retry attempts - Number of retry attempts per failed export. Set to
0for no retries.
Advanced (Scroll PDF Plugin)
These settings control how WikiTraccs interacts with the Scroll PDF Exporter REST API. The defaults work for most setups.
- Template ID - The Scroll PDF template to use. Leave empty for the default template (
com.k15t.scroll.pdf.default-template-documentation). - Page set - The Scroll PDF page set. Leave empty for
current(exports the page itself, without child pages). - Poll interval (ms) - Interval in milliseconds between export status polls. Minimum
100, default1000. - Max wait (sec) - Maximum seconds to wait for an export to finish. Minimum
1, default180.
If you need to look up the template ID, read How to get the Scroll PDF template ID.
Plugin Availability Detection
WikiTraccs checks the availability of both Scroll PDF Exporter and Comala Document Management by probing their API endpoints. If this check fails repeatedly, WikiTraccs internally recognizes them as unavailable and stops using them. This is done whether they are installed or not, so you’ll find log entries related to those checks.
Notes Related to Comala Document Management
Below sections are relevant if you select the Include versions in Comala final state option to export “Comala-published” page versions.
Page Activity vs. Document Activity
Comala Document Management - as of version 7 - implements two technical approaches to handling and showing workflow activities: Page Activity and Document Activity. Both can co-exist in the same Confluence instance.
Page Activity is the legacy implementation of versions before 7. If a space is in legacy mode, it can be upgraded.
Document Activity is the implementation used by default for new spaces, starting with Comala Document Management 7.
The administration provides a report that shows which spaces need an upgrade, including links to related documentation:
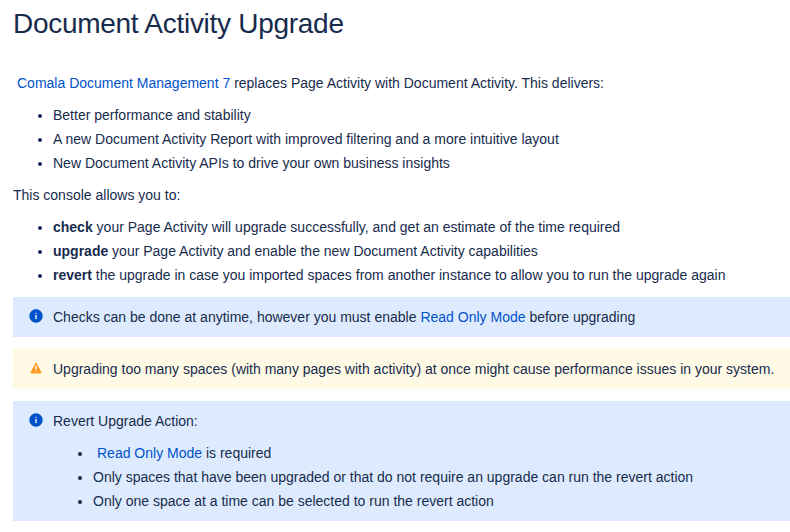
WikiTraccs is able to work with both approaches.
“Final” States
When selecting “Comala-published” page versions for PDF export, WikiTraccs searches for historical versions that entered the final workflow state.
WikiTraccs does not rely on specific state names like “Published” or “Approved”, if there is a workflow state marked as final.
This matters because workflow state names can vary between workflows and installations, while the final marker is the stable signal for any kind of “Published” or “Approved” workflow state.
Some workflows do not expose any state that is officially flagged final, even though they still have a (seemingly) obvious final state. For those cases, WikiTraccs supports a (configurable, via appsettings.json) fallback list of workflow state names and, by default, treats Approved, Done, and Finished as final, together with their lower-case and upper-case variants, when there is no state carrying the official final-state flag.
Renamed States
Renaming the final state of a workflow can mess with both the reporting of Comala Document Management and WikiTraccs’ historical version selection. The behavior will also differ between the legacy Page Activity and new Document Activity mode a page is in.
In the legacy Comala Page Activity mode, renaming a final state will exclude older page versions that entered that state (when it still had the old name) from being exported.
In Document Activity mode, it seems to be possible to export older page versions which entered renamed final states, despite the renaming. You might run into the situation where WikiTraccs exports those historical versions, while the Comala UI doesn’t show them because of the name mismatch.
It might be possible that this behavior changes in the future, depending on changes made by the app vendor.
Permissions
WikiTraccs retrieves Comala data through the Comala REST API. Access to that API is controlled by a Comala configuration setting called Workflow Activity and Drafts Visibility (found in the Comala global and space-level settings). This setting determines how much Confluence permission the migration account needs:
- If set to “Anyone with view permission” - the migration account only needs Confluence VIEW permission on the pages.
- If set to “Space admins and page editors” (this is the default) - the migration account needs one of the following:
- Confluence EDIT permission on the pages, or
- Space admin permission in the respective spaces, or
- Confluence administrator status
In practice, the simplest approach is to either give the migration account EDIT permission in the relevant spaces, or change the Comala visibility setting to Anyone with view permission for the duration of the migration.
Success Metrics
Once Comala Document Management history has been retrieved successfully, WikiTraccs writes a structured label to the migrated SharePoint page. This label encodes every Comala final-state version that was discovered, whether it was selected for export, and whether the PDF file was verified as present in SharePoint after upload.
The label is stored as part of the page’s Confluence: Labels (WikiTraccs) field and follows this structure:
migration:[comala.finalStateHistoricTargets=v6|id=2195470|sel=1|ok=0|by=admin|fn=My%20Page-v6-2195464-2195470.pdf,v5|id=2195469|sel=0|ok=1|by=]
Each comma-separated entry represents one Comala final-state version:
- v{N} - the Confluence version number
- id={HistoricPageId} - the historical content ID of that version
- sel=1/0 - whether this version was selected for PDF export (
1= selected,0= not selected, e.g. because of the max count limit) - ok=1/0 - whether the exported PDF file was verified as present in SharePoint
- by={user} - the Confluence user who triggered the final-state transition
- fn={encoded filename} - the URL-encoded PDF file name in SharePoint (only present for selected versions)
The ok value is determined as follows:
- For versions that were not selected for export (
sel=0),okis always1(no upload expected, so nothing to verify). - For versions that were selected (
sel=1),okstarts at0. After the PDF has been uploaded to SharePoint, WikiTraccs verifies the upload. If the Verify Attachments After Provisioning feature is enabled (which is the default), it checks whether a file with a matching name and non-zero size exists in the SharePoint folder. Otherwise, it checks whether the file was part of the successful upload batch. If the verification succeeds,okis set to1. If the file is missing or has zero bytes,okstays at0and a warning is logged.
Comala PDF File Names
For PDFs exported because of a Comala final-state match, WikiTraccs builds the file name from the page title and version metadata, then appends a Comala-specific suffix:
{PageTitle}-v{VersionNumber}-{CurrentPageId}-{HistoricPageId}-final-{byflag|byname}-{StateName}.pdf
Example:
Space with history-v6-2195464-2195470-final-byflag-Final state.pdf
The parts mean:
- {PageTitle} - the Confluence page title of the exported version, sanitized so it can be stored in SharePoint
- v{VersionNumber} - the Confluence version number, like
v6 - {CurrentPageId} - the current Confluence page ID of the page the version belongs to
- {HistoricPageId} - the historic Confluence content ID of the exported version
- final - a marker showing that this PDF was added because of Comala final-state detection
- {byflag|byname} - how WikiTraccs determined that the version was final:
- byflag - official final flag from the Comala workflow state
- byname - match by state name against configured final-state names
- {StateName} - the workflow state name that caused the version to be treated as final
For historical PDFs that come only from the regular Confluence history selection and not from Comala final-state detection, the Comala suffix is omitted, so the file name looks like this:
{PageTitle}-v{VersionNumber}-{CurrentPageId}-{HistoricPageId}.pdf
Comala Metadata Retrieval Failures
When Comala Document Management metadata retrieval fails completely you should see Warnings and Errors in the WikiTraccs log. WikiTraccs probes the Comala API a few times and then stops calling it for the remainder of the run.
If you see such messages, check that the migration account has the required permissions and that Comala Document Management is properly licensed and working.
Tip
Test the historical PDF export with a few representative pages and spaces before running a full migration.WikiPakk Is Not Affected by the SharePoint Add-In Retirement
WikiPakk is not affected by the SharePoint Add-In retirement. WikiPakk is a SharePoint Framework (SPFx) solution - not a SharePoint Add-In.
The Question
A customer recently asked:
With Microsoft retiring SharePoint Add-Ins, how does that impact WikiPakk?
This is a reasonable concern given the retirement announcement by Microsoft. But the premise is incorrect: WikiPakk is not a SharePoint Add-In.
What Microsoft Is Retiring
Microsoft is retiring the SharePoint Add-In extensibility model in SharePoint Online, effective April 2nd, 2026. This is a legacy development model. The official FAQ makes it very clear:
Is SharePoint Framework (SPFx) impacted by these retirements?
No, SharePoint Framework (SPFx) is the recommended development model for SharePoint extensibility and is not impacted by these retirements. These retirements only affect SharePoint Add-Ins (a legacy development model) and Azure ACS (a legacy auth model).
Why WikiPakk Is Not Affected
WikiPakk is built on the SharePoint Framework (SPFx), the modern and recommended extensibility model. It is deployed as an .sppkg package via the SharePoint app catalog - which Microsoft also explicitly confirms will continue to work:
Both tenant and site collection app catalogs are an essential part of the SharePoint developer ecosystem. They’re used for both Add-Ins (retired) and SharePoint Framework (SPFx) based solutions (not retired). Using the app catalogs for SharePoint Framework solution deployment will continue to be fully supported; no changes!
WikiPakk updates are delivered through the same SPFx app catalog mechanism. Nothing changes here.
Summary
| SharePoint Add-In | WikiPakk (SPFx) | |
|---|---|---|
| Technology | Legacy Add-In model | SharePoint Framework (SPFx) |
| Affected by retirement? | Yes | No |
| Deployment | Add-In catalog (retired) | App catalog (fully supported) |
| Updates | No longer possible after April 2026 | Continue as before |
If you have questions about WikiPakk, feel free to reach out.
What if stuck on interactive Confluence login?
When using interactive Confluence authentication, WikiTraccs opens Confluence in an automated web browser.
You log in to Confluence and WikiTraccs detects the login mainly by checking whether required cookies are available in the browser.
If a required cookie is missing, the browser window does not close automatically after login. WikiTraccs keeps waiting for the expected cookies, and the interactive login eventually times out.
Cookies
After you sign in, the browser stores authentication cookies and sends them back to Confluence on later requests. In Confluence Cloud, this is usually a small set of cookies such as cloud.session.token and tenant.session.token, while JSESSIONID appears to be phased out by Atlassian as of February 2026. WikiTraccs copies a whitelist of relevant cookies, and for a long time JSESSIONID was mandatory.
Solution for Confluence Cloud
If you are connecting to Confluence Cloud, open Settings and enable Make JSESSIONID cookie optional [interactive authentication, Cloud only]. For Cloud, this fixes the issue in nearly all cases.
Solution for other cookie issues
If the problem is caused by a different missing or unusual cookie, open the Advanced Confluence Authentication Settings dialog and enable Copy all browser cookies (bypass whitelist). Use this when your SSO sets cookies that are not covered by the default whitelist.
Run an Automated Confluence to SharePoint Migration
Note: Automated migration is fully supported starting with v1.32.21 as setting the certificate password wasn’t possible in earlier releases and some quirks around certificate-based authentication have been resolved.
Normally you run WikiTraccs with a graphical user interface sometimes referred to as WikiTraccs.GUI. It is a distinct blue window. You enter the configuration and start the migration. When starting the migration, a second console application will open that is responsible for the actual migration - WikiTraccs.Console.
When looking into any WikiTraccs release file you download, you’ll find both WikiTraccs.Console.exe and WikiTraccs.GUI.exe in there.
You can use WikiTraccs.Console to automate your migration and skip the “human” part of the configuration.
Configuring WikiTraccs for Automation
Ignore WikiTraccs.GUI, find WikiTraccs.Console.exe.
Place an appsettings.json file in the same folder where you find WikiTraccs.Console.exe. When starting WikiTraccs.Console, it will read its configuration from this file.
Find sample configurations below.
For Confluence on-premises (PAT auth):
{
"CustomSettings": {
"Features": {
"InteractiveAuthKeepAliveEnabled": false
},
"AttachmentRegistryRootPath": "/tmp/wikitraccs-attachmentregistry",
"TempPath": "/tmp/wikitraccs-temp",
"TargetTenants": [
{
"HumanReadableId": "SharePoint",
"SharePointRootUrl": "https://contoso.sharepoint.com",
"Tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"ClientId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"AuthenticationType": "apponlywithcertificate",
"AuthenticationParameterSetAppOnlyAadCertificate": {
"CertificatePath": "/path/to/certificate.pfx",
"CertificatePassword": "YourPasswordHere",
// OR
"CertificateThumbprint": "YourThumbprintHere"
},
"TargetSites": [
{
"HumanReadableId": "WikiTraccsDefaultTarget",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/migration-target"
},
{
"HumanReadableId": "WikiTraccs",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/wikitraccs-site"
}
]
}
],
"TransformationMappings": [
{
"SourceTenantHumanReadableId": "MyConfluenceOnPrem",
"TargetTenantHumanReadableId": "SharePoint",
"TargetSiteHumanReadableId": "WikiTraccsDefaultTarget"
}
],
"SourceTenantIncludeList": [
{
"TenantId": "https://confluence.mycompany.com",
"HumanReadableId": "MyConfluenceOnPrem",
"AuthenticationType": "bearer",
"PersonalAccessToken": "CONFLUENCE_PERSONAL_ACCESS_TOKEN",
"SpaceTransfer": {
"Enabled": true,
"SpaceIncludeList": [
{ "SpaceKey": "SPACE1" },
{ "SpaceKey": "SPACE2" },
{ "SpaceKey": "SPACE3" }
],
"Operations": [ "retrievecontents" ]
},
"PermissionTransfer": {
"Enabled": false,
"SpaceIncludeList": []
}
}
]
}
}
For Confluence Cloud (API Token Auth):
{
"CustomSettings": {
"Features": {
"InteractiveAuthKeepAliveEnabled": false
},
"AttachmentRegistryRootPath": "/tmp/wikitraccs-attachmentregistry",
"TempPath": "/tmp/wikitraccs-temp",
"TargetTenants": [
{
"HumanReadableId": "SharePoint",
"SharePointRootUrl": "https://contoso.sharepoint.com",
"Tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"ClientId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"AuthenticationType": "apponlywithcertificate",
"AuthenticationParameterSetAppOnlyAadCertificate": {
"CertificatePath": "/path/to/certificate.pfx",
"CertificatePassword": "YourPasswordHere",
// OR
"CertificateThumbprint": "YourThumbprintHere"
},
"TargetSites": [
{
"HumanReadableId": "WikiTraccsDefaultTarget",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/migration-target"
},
{
"HumanReadableId": "WikiTraccs",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/wikitraccs-site"
}
]
}
],
"TransformationMappings": [
{
"SourceTenantHumanReadableId": "MyConfluenceCloud",
"TargetTenantHumanReadableId": "SharePoint",
"TargetSiteHumanReadableId": "WikiTraccsDefaultTarget"
}
],
"SourceTenantIncludeList": [
{
"TenantId": "https://mycompany.atlassian.net/wiki",
"HumanReadableId": "MyConfluenceCloud",
"AuthenticationType": "basic",
"BasicAuthUsername": "[email protected]",
"PersonalAccessToken": "ATLASSIAN_API_TOKEN",
"SpaceTransfer": {
"Enabled": true,
"SpaceIncludeList": [
{ "SpaceKey": "SPACE1" },
{ "SpaceKey": "SPACE2" },
{ "SpaceKey": "SPACE3" }
],
"Operations": [ "retrievecontents" ]
},
"PermissionTransfer": {
"Enabled": false,
"SpaceIncludeList": []
}
}
]
}
}
SharePoint Online Authentication Notes
The key part for SharePoint Online is this part of the appsettings.json:
"Tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"ClientId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"AuthenticationType": "apponlywithcertificate",
"AuthenticationParameterSetAppOnlyAadCertificate": {
"CertificatePath": "/path/to/certificate.pfx",
"CertificatePassword": "YourPasswordHere",
// OR
"CertificateThumbprint": "YourThumbprintHere"
},
| Setting | Description |
|---|---|
| Tenant | The tenant ID (GUID) of your SharePoint Online tenant. |
| ClientId | The application (client) ID of the Entra ID app registration used for authentication. |
| AuthenticationType | Must be set to apponlywithcertificate for certificate-based app-only authentication. |
| CertificateThumbprint | The thumbprint of the certificate in the Windows certificate store (CurrentUser\My or LocalMachine\My). The certificate must include a private key, and that private key must be accessible to the account running WikiTraccs. Note: When using this setting, no CertificatePath or CertificatePassword is used. |
| CertificatePath | The file system path to the .pfx certificate file used for authentication. Note: Only used if no CertificateThumbprint is set. |
| CertificatePassword | The password protecting the .pfx certificate file. Note: Only used if no CertificateThumbprint is set. |
Refer to Registering WikiTraccs as App in Entra ID for instructions on creating the Entra ID app registration. Note that for app-only authentication you need to use application permissions instead of delegated permissions, and upload your .cer certificate file to the Entra ID app.
See Configuring Sites.Selected Authentication for WikiTraccs for the end-to-end walkthrough.
Note
Starting with WikiTraccs v1.33.30, the certificate used for SharePoint app-only authentication can also be configured directly in the blue WikiTraccs.GUI window.How to Cancel a Migration
WikiTraccs.Console will close automatically after migrating all pages from the configured selectors.
If you want to close WikiTraccs.Console prematurely, send Ctrl+C to the console window. Or just kill the process.
Wrap
Automating WikiTraccs is possible using appsettings.json.
Skip Broken Confluence Attachments During Migration
Note: This setting is available as of WikiTraccs v1.32.29.
Sometimes Confluence attachments are broken, triggering connection resets or other errors during download. Every once in a while, a customer discovers such broken attachments and the root cause often is some corrupted state in either the Confluence database, or a corrupted attachment file.
By default, a single broken attachment fails the entire page. A new setting lets you skip those and keep migrating.
How to Spot Broken Attachments?
When an attachment download fails, the WikiTraccs common log files show errors like these:
[ERR] [https://wiki.contoso.com] Exception while downloading
'https://wiki.contoso.com/download/attachments/12345678/broken-file.zip':
System.IO.IOException: Unable to read data from the transport connection:
An existing connection was forcibly closed by the remote host.
---> System.Net.Sockets.SocketException (10054): An existing connection
was forcibly closed by the remote host.
at System.Net.Sockets.Socket.AwaitableSocketAsyncEventArgs...
at System.Net.Security.SslStream.<FillBufferAsync>...
at System.Net.Http.HttpConnection.SendAsync(...)
This then cascades into:
[ERR] Cannot store or apply content. Additional information: job result
details: 'Storing the page snapshot returned false, something is wrong',
status code: InternalServerError.
The page then is either missing in SharePoint, or created empty with a Failed Transformations count of 9001 (which is a marker value).
You can also verify the brokenness of an attachment by downloading it manually in the browser. This will often fail, or only succeed after several retries - clearly indicating that there is an issue with it.
How to Skip Over Broken Attachments?
Note: This setting is available as of WikiTraccs v1.32.14
In WikiTraccs.GUI, in the menu bar, click Settings -> Configure Transformation. Then go to the Misc tab and check Ignore broken Confluence attachments.
With this setting active:
- WikiTraccs catches attachment download errors and skips the broken attachment instead of failing the whole page
- The page is still created in SharePoint - with all attachments that did download successfully
- The skipped attachment is logged as an error in the log file:
[ERR] Failed to download attachment 'broken-file.zip' for page 12345678; URL was 'https://wiki.contoso.com/download/attachments/...'; skipping attachment because IgnoreBrokenAttachments is enabled - The Failed Transformations count on the SharePoint page reflects the skipped attachment, so you can filter the Site Pages library to find affected pages
Workarounds
If you don’t want WikiTraccs to skip over broken attachments, there are ways to manually work around the issue.
You can delete the offending attachments in Confluence. This might be an option if losing those files is of no concern. This will unblock page migration.
An alternative approach is re-uploading the attachment. If you can download the file in the browser (and that might not be the case), download the attachment and re-upload it again. Sometimes this fixes the underlying issue in Confluence.
Wrap
This setting trades completeness for progress - pages with broken attachments get migrated nevertheless. Review the log file and the Failed Transformations column in Site Pages to identify which attachments were skipped.
Confluence Authentication Improvements
WikiTraccs provides different ways to authenticate with Confluence. You’ll find an overview here: Authenticating with Confluence.
One of the ways to authenticate with Confluence is Interactive Authentication. Using this, a browser window will open when you start the migration, and you’ll authenticate with Confluence using a migration account. WikiTraccs will then take over the user session and add the session cookies to all requests it issues to Confluence.
Interactive Authentication (Session Cookies) vs. Personal Access Token
Why not always use personal access tokens (PATs) to access Confluence, you might ask.
Firstly, the use of PATs might be prohibited when multi-factor authentication (MFA) is enforced. So, using a PAT from the internal company network might work, but using a PAT from outside the internal network (e.g. from your home office without a VPN) might fail. This is most common with Confluence on-premises.
Secondly, PATs only allow access to endpoints officially supported by Atlassian. There are certain cases where WikiTraccs has to use internal or undocumented endpoints to migrate content that would otherwise not be accessible. This is most common with Confluence Cloud.
At the time of writing this, one example of missing endpoints is the “dynamic data card”, whose content cannot be retrieved via official APIs. I asked about that in 2024, but so far there doesn’t seem to be a solution yet. Using interactive authentication and session cookies, WikiTraccs can use the same endpoints that the Confluence browser UI uses.
Interactive Authentication Cookie Refresh
One caveat to interactive authentication and reusing session cookies is that those cookies might have a limited lifetime. They might need regular refreshes. This usually happens when you navigate Confluence in the browser.
Since WikiTraccs v1.32.2, cookie refresh is supported. This feature is optional and needs to be turned on when required. Note that over a period of about 3 years while serving hundreds of customers, there was only one case where such a refresh caused issues due to sessions timing out during the migration. That’s why the setting is considered optional and located in the Misc section of the Transformation Settings dialog:
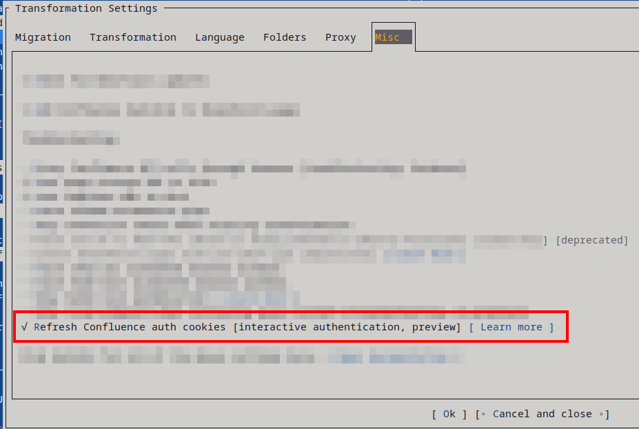
When this option is checked, you’ll notice a difference during the migration. One additional browser window will stay open that periodically refreshes Confluence in the browser. WikiTraccs will look for changed cookies and take them over to use them when issuing requests to Confluence.
The feature is currently marked as a preview, as I’d like to get feedback about its usefulness and usability.
Known issue: When finishing or stopping a migration run, WikiTraccs sometimes fails to close the browser window it uses to keep the cookies fresh. If that happens, close it manually, or try closing all browser windows and restarting WikiTraccs (before starting a new migration run).
Adding Edge Browser Support
Note: Edge support is available as of WikiTraccs 1.32.2
WikiTraccs so far has been exclusively relying on Google Chrome as its built-in “automated browser”.
Now WikiTraccs adds the Microsoft Edge as an alternative - an often asked-for feature in corporate environments where Chrome might be hard to set up.
What Chrome is Being Used For
The automated browser is used whenever WikiTraccs needs a real browser session, for example, to interactively authenticate to Confluence or when Confluence features are only accessible through the UI.
Chrome currently powers:
Interactive Login (cookie-based authentication) via a WikiTraccs-controlled browser window: Interactive Confluence Authentication
Proxy Mode, routing Confluence API calls through the authenticated browser session: Confluence Authentication Overview
Confluence Cloud whiteboard export (UI automation): Migrating Confluence Cloud Whiteboards
draw.io preview image generation (render/export via the draw.io viewer): WikiTraccs Creates Draw.io Preview Images
Under the hood, WikiTraccs controls Chrome using Google’s Chrome WebDriver (ChromeDriver).
Usually, this works out of the box (Chrome installed + WebDriver auto-download), but in locked-down environments you may need to allowlist endpoints or configure paths explicitly, which can be tedious (for example ChromeBinaryPath, WebDriverDirPath, ChromeDriverVersionOverride).
Information about Chrome, its prerequisites, and troubleshooting can be found here:
Using Edge Instead of Chrome
You can tell WikiTraccs to use Edge instead of Chrome in the settings.
In WikiTraccs, click Configure Transformation in the menu bar, then check Use Edge browser instead of Chrome. From then on, WikiTraccs will use Edge instead of Chrome.
Note that Chrome is the default setting, so when you don’t configure anything, WikiTraccs will use Chrome.
Documentation will be updated accordingly, but it may take a bit of time to reflect that change in all relevant places. When reading “Chrome”, add “or Edge” in your mind.
WikiTraccs 2025 Recap
The year 2025 was a busy one for WikiTraccs.
Many improvements were made, most notably concerning output quality, macro coverage, and operational versatility. Pages look nicer in SharePoint and migrations are easier to control.
This post is a recap of the roughly 50 releases shipped in 2025.
1| New SharePoint Page Format (CK5): Styling Got a Serious Upgrade
2025 was the year the new SharePoint page editor format was stable enough to make it the default.
This new format comes with a lot of visual improvements like better handling of text colors and background highlights, improved paragraph spacing, new citation styles, and more.
This is one of those changes where the impact is immediate: migrated pages simply look more “finished”.
2| Page Refinement: Fixing Broken Links After Migration
The reality of real-world migrations showed a pattern:
- You migrate in waves
- Target site mappings change
- Some links will inevitably be wrong at some point in time
In 2025, WikiTraccs gained Page Refinement mode to handle that.
- Log broken links
- Fix broken links (pages, attachments, and more)
If you want the details, I wrote this up here: Making Sure Migrated Links Work.
3| Tables: More Realistic Results (Including Nested Tables)
Tables are excessively used in Confluence and notoriously hard to migrate to SharePoint due to size and formatting limitations. Yet they are one of the biggest quality makers for migrated pages.
In 2025, table transformations got major improvements, including:
- Nested table support (where it makes pages less cluttered)
- Table size optimization using browser automation, so tables end up with more realistic widths in SharePoint
If you’re curious about the reasoning and a before/after example: Table Size Optimization.
4| Macro Coverage Expanded
2025 added support for many popular Confluence apps and macro types.
That includes new and improved transformations across:
- Formatting macro suites (like Mosaic / Aura and friends)
- Excerpt / Include scenarios
- Diagrams (including more draw.io variants)
- Roadmap, Table chart, and other “image-like” macros
Every additional macro that “just works” reduces manual follow-up work.
5| Diagrams & Visual Content: draw.io, Whiteboards, and More
There were a lot of improvements around “image-like” content:
- Draw.io preview image generation and better draw.io handling
- Whiteboard transformation adjustments (Cloud)
- Better resilience around edge cases (missing previews, unusual references, etc.)
6| Cloud & On-Prem Resilience
Boring, but crucial: many improvements that keep migrations running reliably despite:
- API deprecations and API changes (Cloud)
- Authentication edge cases and proxy configurations
- Large instances and performance constraints
Closing Note
That’s the 2025 recap.
Looking ahead, I’ll write another post that picks up from here, covering what’s coming in 2026, which is quite a lot.
Backing up Atlassian Marketplace Apps
Note: This feature is available as of WikiTraccs v1.31.23
Imagine your Confluence environment being broken so that you have to rebuild it. Or a botched app update that needs to be rolled back. Or you need to rebuild an environment to access a specific backup.
Ideally you have backed up everything in your Confluence environment, including the required apps. But let’s assume not.
You might need to reinstall apps to your Confluence environment
Now imagine going to the Atlassian marketplace to download the right app version - just to find that it is not available anymore.
WikiTraccs helps to prepare for that exact scenario by offering to download all versions of an app from the Atlassian marketplace.
How can apps disappear from the Atlassian marketplace?
Atlassian might decide to remove on-premises apps in their push to the cloud.
Vendors might decide to have apps or app versions removed.
You can already find cases of missing app versions in the marketplace:
While testing the app backup function of WikiTraccs, I found several cases of missing app versions. When you click the download button in the marketplace, an error page is shown in those cases, and the page address contains MISSING_ARTIFACT.
Not sure if those missing artifacts are deliberate removals, or if that is an error on Atlassian’s side.
How to back up an app from the Atlassian marketplace?
Let’s use PlantUML as an example. Here’s the marketplace link to the Confuence Data Center version: PlantUML for Confluence.
Of course you could manually download all 74 app versions from the app’s Version history page.
But you can now also use WikiTraccs to do that for you a bit faster.
In the WikiTraccs menu bar, click Tools > Back up Atlassian Marketplace Apps.

A dialog opens.
It shows you where downloaded app files will be stored and you can click the path to open the location in a file browser. The path is relative to the configured attachment registry folder path (which you can change in the settings):
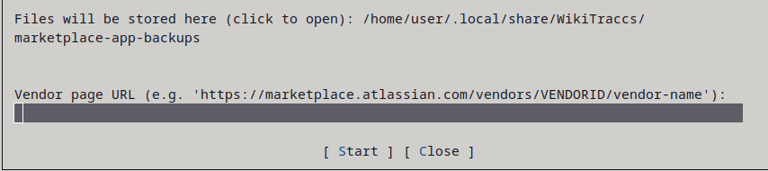
Enter the vendor page URL that you can find in the marketplace by copying the vendor link. For PlantUML the vendor link will be https://marketplace.atlassian.com/vendors/747510/avono-ag:

In WikiTraccs, after entering the vendor page URL, click Start to close the dialog and start downloading.
WikiTraccs will now download all apps of that vendor. Currently, there is no way to restrict that to a single app. Also, all Server and Data Center versions are downloaded.
WikiTraccs shows status information about the download:
To stop the download, close WikiTraccs. To resume an interrupted download, simply start it again - it will continue downloading where it left off.
Notes
The backup feature may break if Atlassian makes changes to the marketplace.
The backup feature is not polished and primarily designed to get the job done.
WikiTraccs will create .DONE_MARKER files in the download folder to mark apps it downloaded all versions for. When you start a download, it will detect that such a file is present and skip over the app. This also allows you to delete the downloaded app files, for example after copying them to a backup location. The .DONE_MARKER file prevents WikiTraccs from downloading the files again. Delete the .DONE_MARKER file to have WikiTraccs reconsider the app for downloading.
Question Time November 2025
I got the following questions.
- How to migrate a page that has been updated in Confluence?
- Is there a migration report showing whether a space has been completely migrated to SharePoint?
- Is it possible to hide the remains of (defunct in SharePoint) macros on the migrated pages?
- How to check how many cross-space links there are in a Confluence space?
- We want to keep the links to Confluence in some spaces - is that possible?
- We want to rewrite some of the migrated Confluence-links to a new Confluence instance - is that possible?
- Should the migration run as system user or personal account? Where is the name of this account surfaced in SharePoint?
Let’s dive in.
1. How to migrate a page that has been updated in Confluence?
If - after a migration - users keep working on pages in Confluence, you might end up with already migrated pages that were updated in Confluence since the migration.
WikiTraccs can detect those pages and can overwrite the already migrated pages in SharePoint Online.
Have a look at Updating Previously Migrated Pages to learn how to do that and some constraints that apply.
2. Is there a migration report showing whether a space has been completely migrated to SharePoint?
Yes.
First of all, there are two simple number indicators available in the Space Inventory, showing how many pages where found for each source selector and how many have been migrated to SharePoint.
You can gain deeper insights using progress log files. Please refer to the following article for details: Monitoring Confluence to SharePoint Migration Progress - Overview.
3. Is it possible to hide the remains of (defunct in SharePoint) macros on the migrated pages?
Yes, for many macros.
WikiTraccs will add macro placeholders to migrated pages showing that a macro had no representation in SharePoint and that it thus was replaced by a text placeholder. Read more about the general approach here: Macro Placeholders. This page also shows where to find transformation templates that WikiTraccs internally uses.
You can change the placeholder texts for most macros, using Macro Transformation Templates.
Advanced Configuration
This configuration is considered advances as mis-configuring transformation templates can introduce hard to find migration errors.4. How to check how many cross-space links there are in a Confluence space?
WikiTraccs automatically transforms all Confluence-internal links to proper SharePoint links. This covers cross-space links.
As of now, there is no output of links that would be accessible for you.
5. We want to keep the links to Confluence in some spaces - is that possible?
There is an appsetting.json-based setting that can be used to keep the Confluence links if a target site cannot be resolved.
{
"CustomSettings": {
"Features": {
"LinkTransformationMode": "needexplicittargetsite"
}
}
}
If a target site cannot be determined based on a space inventory mapping, the original Confluence link will be kept.
This might help, although this is a rarely used feature.
6. We want to rewrite some of the migrated Confluence-links to a new Confluence instance - is that possible?
As of now, there is no way to configure the link transformation such that you could rewrite Confluence-internal links.
7. Should the migration run as system user or personal account? Where is the name of this account surfaced in SharePoint?
For Confluence, use a migration account that is space owner in all to-be-migrated spaces. But better, us a Confluence admin. Administrative access allows retrieving metadata related to user account, page restrictions, and restricted page contents.
For SharePoint Online no system admin permissions of any sorts (SharePoint admin, tenant admin, …) are required. Use a user account that is site owner in all target sites for the migration. This level of access allows setting the creation and modification dates of pages, as well as author and editor.
The M365 migration account is used to create SharePoint pages and might be shown as author and editor of pages and files. You can configure a user mapping to show the original Confluence users instead. Read more about that here: Mapping user accounts from Confluence to SharePoint.
Consider using accounts that don’t have a forced reauthentication configured as this might temporarily interrupt the migration until you reauthenticate.
Table Size Optimization
Release v1.30 of WikiTraccs introduces a new way to measure and optimize table sizes.
Let’s look at one example that shows the reasoning behind this new feature.
Consider the following narrow table in Confluence:
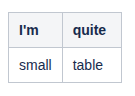
Migrating this to SharePoint without table size optimization so far produced the following wide SharePoint table:

The reason for that size difference is that the table in Confluence carries no explicit size information (at least until you manually resize the columns), and the browser decides how wide a table is (based on Confluence’s internal styling). For SharePoint, styling is different and the table becomes page-wide.
How could WikiTraccs learn about the real tables size, if this information is only available in the browser?
The answer is browser-based table size optimization: WikiTraccs copies each table to a real browser. The browser decides about the size of each table cell, table column, and ultimately the table itself. Now WikiTraccs just needs to read those numbers from the browser and apply that to the table in SharePoint.
After applying table sizes gotten from the browser, the result for above sample table looks like this in SharePoint:
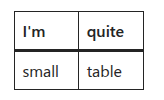
Much better, right? This benefits especially larger table, tables with images, and nested tables.
The results are so promising that table size optimization is enabled by default.
If you see any issues with calculated table sizes, please report those and consider turning table size optimization off; you can do that in the WikiTraccs Misc settings, using the Skip table size optimization setting.
Why do customers pick Confluence?
When it comes to making SharePoint attractive for typical Confluence customers, you have to answer the question Why do customers pick Confluence in the first place?.
For me, it’s not that easy to answer since I’m mainly in touch with teams moving away from Confluence to SharePoint. Often, Confluence has been around for more than a decade. But what I see is common usage patterns that allow insights into why Confluence was chosen in the past.
👉 You’ll find a list of common Confluence use cases below.
I’m vocal on LinkedIn and X when it comes to SharePoint’s limitations with regard to the wiki use case (Confluence is an enterprise wiki) - and there are quite some.
👉 You’ll find a list of the most blocking SharePoint limitations below.
To get started, let’s have a look at the most mentioned reasons for moving away from Confluence - because this doesn’t seem to have anything to do with functionality.
Reasons to Move From Confluence to SharePoint Online
The following points are not a recommendation, but input I got from nearly a hundred demo sessions for WikiTraccs (the Confluence to SharePoint migration tool) and WikiPakk (the SharePoint page tree).
The main two reasons for moving away from Confluence are:
- The cost of Atlassian products is increasing steadily. SharePoint licenses are available in the company, so those should be used instead.
- Strategic decision for the Microsoft ecosystem, consolidation of products and services.
And that’s basically it. It’s either cost, or strategy, or both.
Notable other reasons were:
- “Somebody long time ago set up Confluence, we don’t really know how that happened but it isn’t properly aligned.”
- “Our Confluence admin left.”
- A reduction of vendor lock-in in general, with the goal to be independent of any vendor at all (that’s where my WikiTraccs for Markdown proof of concept came from).
Common Confluence Use Cases
When talking with customers, I commonly see the following use cases in Confluence.
Team Knowledge Base & Technical Documentation
Teams use Confluence to document everything related to software development, hardware development, and whatever needs to be documented in their specific sector.
The content is “functional” - lots of plain text, code snippets, images, tables, and so on. Not necessarily pretty.
The content lives potentially forever.
Project Documentation & Collaboration
When a project starts, a Confluence space is created for project documentation, collaborative meeting notes, and progress tracking.
Project spaces contain technical documentation, but there will also be a lot of management focused content (progress tracking, meeting notes).
When the project ends, the space usually can be archived.
The migration result in SharePoint usually looks pretty good, as there is not too much effort put into the looks of the content.
Process Documentation & Work Instructions
Drafting and publishing mission-critical content, keeping information in a manner that survives an audit.
Intranet & News Authoring
There are many Confluence-based intranets out there, often themed by third-party solutions. Those are hard to migrate because nearly all the styling and layouting will be gone in SharePoint.
Confluence supports news (called blog posts) which can be shown on the intranet start page. This is comparable to SharePoint news posts.
General Observations
The more third-party styling and layouting plugins are installed to Confluence (for example AURA content formatting macros, see animation in next section), the harder content is to migrate, as folks will use those.
The longer content is supposed to live, or the more complex content is, the more of third-party styling and layouting macros will be used (for example Navitabs navigation and tabs macros).
Technical Limitations of SharePoint Compared to Confluence
What would make migrating to SharePoint easier?
Inlining & Nested Macros
SharePoint does not allow extensions inside text web parts - little pieces of functionality that float with the text. Micro parts.
Having that would allow dynamic @-mentions, little status lozenges, the current date - you name it.
And how about nesting whole macros? How about a macro around a text web part? Applying formatting, a border, reusability, and such?
Nested Tables
Please. Just enable that in the editor. I know that technically SharePoint supports that.
Reusable Content
This is a really big one. There is no way in SharePoint to create reusable content snippets or to embed pages in pages. I this this being heavily used in Confluence to avoid duplication of content.
Here’s my blog post about that pain: Sharing Content Across Pages Is Impossible.
Toggle Visibility of Content
This is a huge one as well. Confluence has the Expand macro that allows to expand and collapse a section of content. Tabs also fall into that category.
All in One Animation
Here is an example, showing all of the above features in one example.
The animation shows:
- nested content (multiple levels) (note: third party solution)
- inline content (status, date) (note: mix of third party and out of the box solutions)
- toggling the visibility of content (note: out of the box functionality)
- nested tables (note: out of the box functionality)
- tabbing (note: third party solution)
- wide page real estate for content
- a content snippet being reused on the same page (note: there are both out of the box and third party solutions that can do that)

You might say: nobody does what I did in that video. But I’ve seen it all. And more.
Using a Header Template for Migrated Pages
I acknowledge that there is the need to change how migrated pages look in SharePoint, based on some kind of page template.
Some requests I got are
- modifying the number of columns on the page,
- adding additional web parts to migrated pages, or
- modifying how the header looks.
In general, my approach to templating is that “it’s complicated” and be left to post processing using PowerShell scripts. That’s why WikiTraccs (at least for now) only supports the latter of the above points - page header templates.
How to Create a Page Header Template
WikiTraccs can apply the settings of a template Banner web part to the header of migrated pages (which also have a Banner web part as header).
Here’s how to create a template, in the same site where the template should be applied:
- Create a new SharePoint page template (note: first create a page, then promote as page template)
- Change the file name of the page template file to
migration-template.aspx; WikiTraccs will look for this exact name in theTemplatesfolder of the Site Pages library:
The template page with name (not title!) page-template.aspx.
- Edit the page template and configure the Banner web part as you like
Sample screenshot of a Banner web part being configured on a properly named template page:
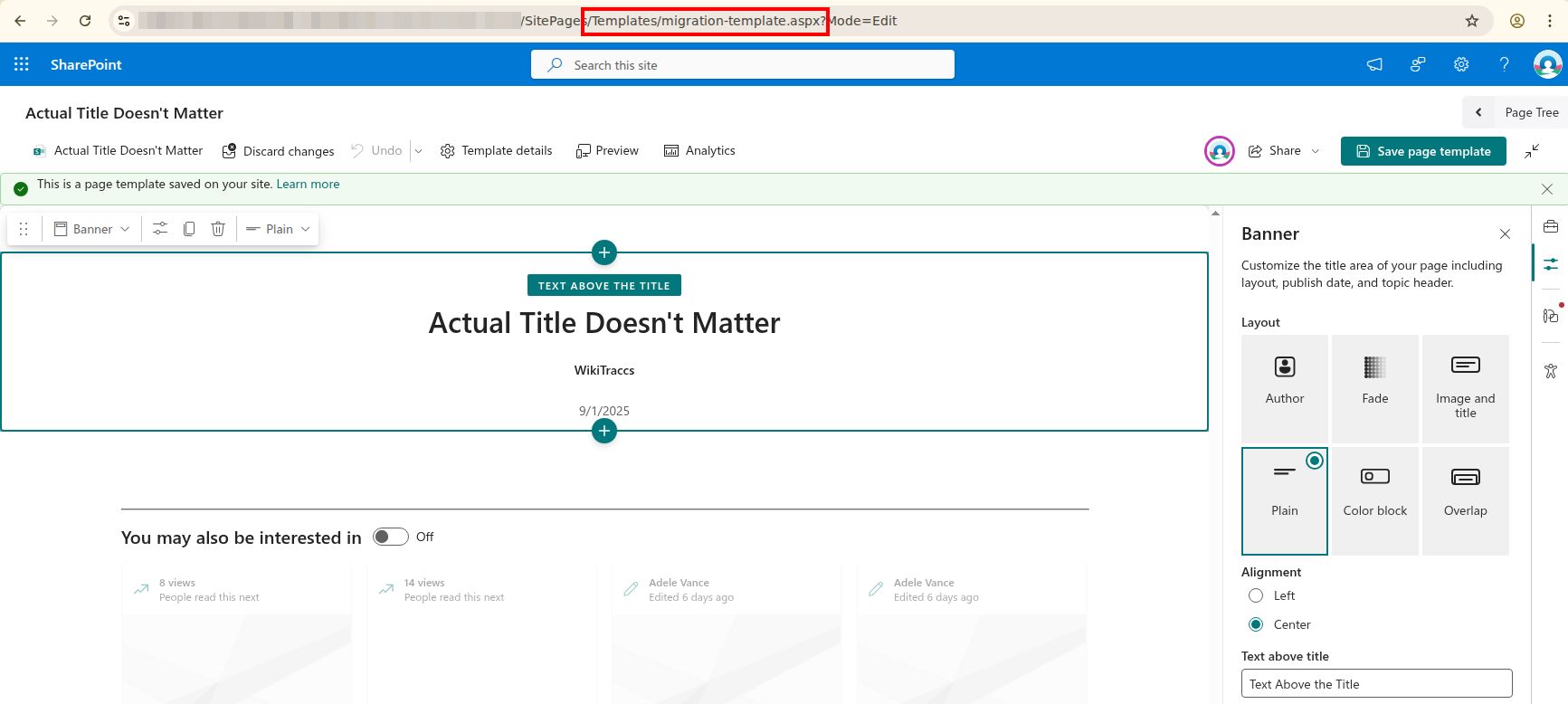
WikiTraccs will now apply the Banner web part settings from this template page to all newly migrated pages.
Note
A template is only applied to pages in the site the template has been created in. If you want to apply a template in 10 sites, you have to create 10 template pages; one in each respective site.
While this can be cumbersome, it allows for a different configuration in each site.
A Look at the Result
After adding a template page to a SharePoint site as described in the previous section, pages migrated to that site should take over the Banner web part settings:
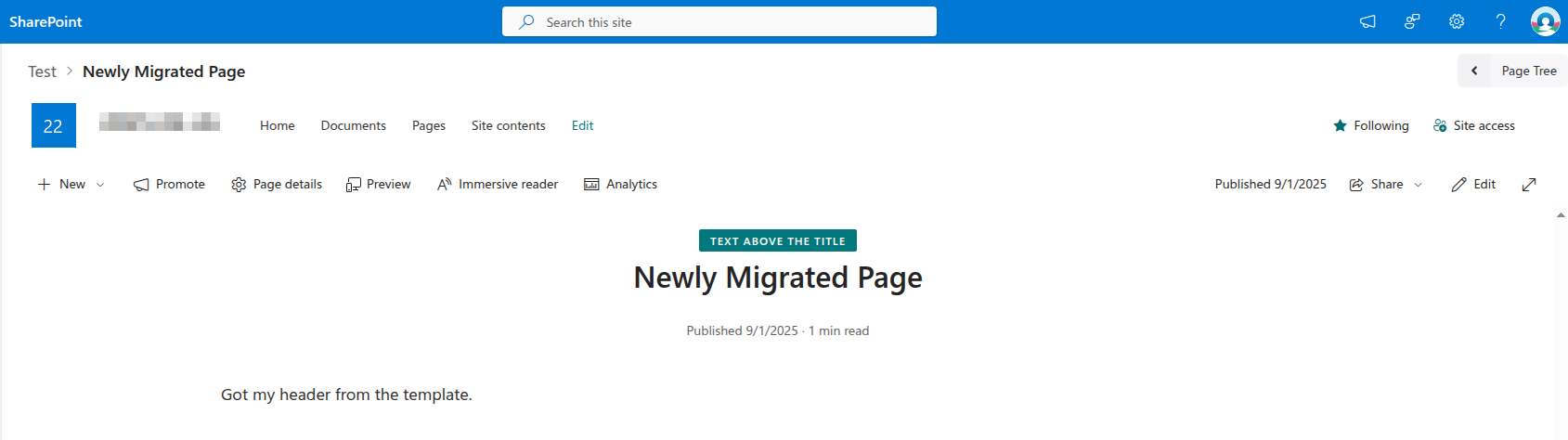
Note that the page publisher (if to be shown in the header) might not be shown until the page is edited and published again. This is a known technical limitation as SharePoint seems to have very specific and undocumented expectations as to how this publishing account is referenced by the web part.
Making Sure Migrated Links Work
Important questions you might have about link migration:
Will links keep working after migrating from Confluence to SharePoint?
Yes. WikiTraccs takes care of this. Links between Confluence pages are converted to links between SharePoint pages; the same applies to attachments.
Do I have to migrate everything in one go for links to work in SharePoint?
No. You don’t have to migrate everything in a single run; you can migrate in waves over time.
A key element is that WikiTraccs can create links to content that has not yet been migrated, by “calculating” links.
How does link migration work and how should you prepare?
Take Those Two Steps to Make Links Work in SharePoint
Configure target site mappings before you start the migration. Run the link fixer after each migration wave.
Configure a Complete Target Site Mapping (BEFORE MIGRATING)
Before you start a migration, tell WikiTraccs which Confluence content to migrate (using selectors), and where to migrate to in SharePoint, by mapping selectors to target sites.
You configure the target site mapping in the Space Inventory, a SharePoint list. Most importantly for links, it tells WikiTraccs which SharePoint sites to store the migrated pages in.
If you’ve ever migrated content with WikiTraccs, you’ve had the Space Inventory open at least once, to tick a selector for transformation.
Here’s the recommendation:
Configure a complete target site mapping for all selectors before migrating the first Confluence page. This tells WikiTraccs where content will end up in SharePoint when selectors are migrated. You don’t have to migrate everything right away - just define where the content will end up later.
Run Page Refinement to Fix Broken Links (AFTER MIGRATING)
Using Page Refinement, WikiTraccs can detect and fix broken links. WikiTraccs acts as a “link fixer.”
After migration, refer to Page Refinement about the general concept and specifically to Page Refinement - Fix Broken Links.
Version Note
Use WikiTraccs v1.29.7 or higher for a good coverage of links which can be fixed.How are Page Links “Calculated” by WikiTraccs?
Note
You don’t really need to know how WikiTraccs calculates links. But I got this question so often, that I decided to document how it works. Feel free to skip this section.How can WikiTraccs “calculate” links to SharePoint pages without having to migrate their content first?
Let’s look at the address of a migrated SharePoint page:
https://contoso.sharepoint.com/sites/People-Portal/SitePages/HR-New-Hire-Guide-12345.aspx
WikiTraccs can create the SharePoint page file name from any Confluence page’s space key (HR), page title (New Hire Guide), and page ID (12345).
To find the target SharePoint site (People-Portal) WikiTraccs looks at the Space Inventory and expects to find a target site mapping, that includes the linked-to page.
In this example, WikiTraccs might find a space selector for the HR space that is mapped to the target site https://contoso.sharepoint.com/sites/People-Portal. It thus knows that all pages from the HR space will at some point be migrated to the People-Portal SharePoint site.
If WikiTraccs cannot find a target site configuration for a linked-to page, it uses the default target site value that you entered in the blue WikiTraccs window.
How Can Links Be Dead in SharePoint?
A dead link is a link that shows a “page not found” (or 404) error when you click it.
During migration, there are often dead links on already migrated pages.
Let’s look at the two most common causes for dead links.
Missing Target Page (Will be Migrated Later)
The target page of the link might not have been migrated, yet. It can be as simple as that.
WikiTraccs can “calculate” links to any page, migrated or not, as shown in the previous section. As soon as the target page has been migrated, the link starts working.
Nothing to do here.
Changing Target Site Mappings Can Cause Dead Links
Broken links are often a result of changing target site mappings mid-migration.
Let’s assume the following selector-to-target-site mapping in the Space Inventory:
- “all pages of the HR space shall be migrated to the SharePoint site https://contoso.sharepoint.com/sites/People-Portal”
This is just a mapping; let’s assume the HR space has not been migrated, yet.
When a page is migrated that links to the New Hire Guide page (which lives in the HR space), the following link will be calculated by WikiTraccs and inserted into the page:
https://contoso.sharepoint.com/sites/People-Portal/SitePages/HR-New-Hire-Guide-12345.aspx
WikiTraccs used metadata available at the time of migration (target site, space key, page title, page ID) to calculate the link.
Now, before migrating the HR space, suppose you change its target site mapping to:
- “all pages of the HR space shall be migrated to https://contoso.sharepoint.com/sites/HR-Hub”
Then, after you migrate the HR space, you’ll find the migrated New Hire Guide page at:
https://contoso.sharepoint.com/sites/HR-Hub/SitePages/HR-New-Hire-Guide-12345.aspx
Since pages from HR will now end up in the HR-Hub site, links to the People-Portal site (created based on the initial target site mapping) are now dead.
This is resolved by the link fixer, which will - in our case - adjust the target site part from People-Portal to HR-Hub in all links it can find.
Recommendations
Run the Page Refiner with Log action first: Page Refinement - Log Broken Links. Review the text file it creates. It lists all links that need fixing, and the new target for each link (if one could be found).
After reviewing, run the Page Refiner with Fix action: Page Refinement - Fix Broken Links. This will fix the links by editing affected pages.
Running the page refiner on migrated SharePoint pages is about ten times faster than migrating them.
You can run the Page Refiner repeatedly.
Notes
This post mostly talks about page links, but everything also applies to attachment links.
SharePoint Page Tree Groups News Posts by Date (WikiPakk Update)
The latest WikiPakk release v2.10.0 adds an often-asked-for feature: automatic grouping of news posts by date (as known from Confluence).
Here’s a sample page hierarchy, covering news posts from several years. Those have been automatically grouped based on their publishing date:
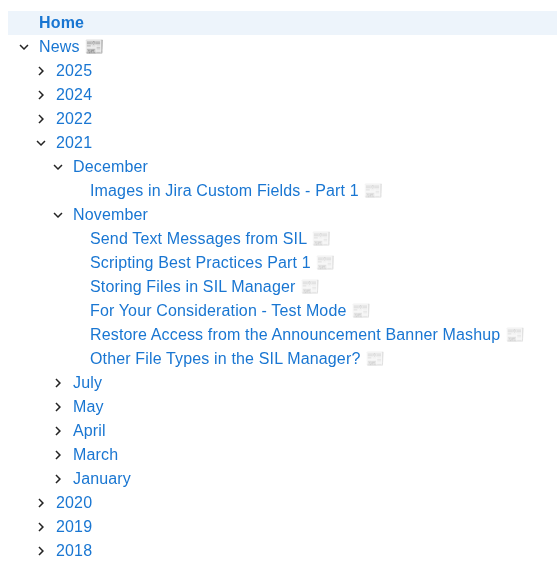
Here’s a quick GIF showing the tree in action:

The page tree shows years and months that had news published in. You can drill down accordingly.
Video Introduction: WikiPakk Page Tree - Automatic Grouping of News Posts by Date
The following video shows automatic news grouping in action:
The page tree will also show whether a news post is a draft or not.
The page tree is still fully compatible with multilingual news pages, using the out-of-the box feature of SharePoint that is based on creating a different page for each language.
Video Introduction: WikiPakk Page Tree - Configuring Automatic Grouping of News Posts by Date
This video shows settings for the news grouping:
- How to change the root label from “News” to something different?
- How to disable automatic grouping of news posts by date?
Migrating Communardo and Comala Metadata
WikiTraccs now migrates metadata from Comala Document Management (former Comala Workflows) and Communardo Metadata for Confluence.
Note: Both transformations are only supported for Confluence on-premises.
Where to Find Migrated Metadata in SharePoint?
WikiTraccs migrates metadata as page labels. You can see them in SharePoint in the Site Pages library. Note that you might have to add the Confluence: Labels (WikiTraccs) column to the current Site Pages list view, to see the labels.
For Communardo Metadata for Confluence you’ll see labels like those, representing metadata that was attached to the Confluence page:
migration:[communardometadata.global.metadatafield.orgunit=Atlassian Solutions]migration:[communardometadata.global.metadatafield.state=Finalized]migration:[communardometadata.global.metadatafield.continue=No]migration:[communardometadata.global.metadatafield.fiscalyear=2025/2026]migration:[communardometadata.global.metadatafield.quarter=]
For Comala Document Management you’ll see those entries:
migration:[comala.workflowName=Review Workflow]migration:[comala.state.name=Active]migration:[comala.state.dueDate=1748516063000]
Those are the workflow name, the name of the current state, and the due date (in Comala-native format).
Labels that were added by WikiTraccs have the migration: prefix to separate them from regular page labels, which mostly have the global: prefix.
Technical Notes
Metadata migration is always enabled when starting a migration run.
When starting a migration run, WikiTraccs will check if programming endpoints from both Communardo and Comala plugins are available. If they are available, metadata will be retrieved for every page. If those endpoints are not available, WikiTraccs will disable metadata migration efforts for those plugins after some retries.
How to Use the Metadata in SharePoint?
Since metadata from the Comala and Communardo plugins ends up in plain text format in a text column in SharePoint, you’ll probably need post processing to do something meaningful with that data.
I recommend using PnP PowerShell to read the labels, transform them to a format that’s useful to you, and store them at a place that makes sense in your context.
WikiTraccs Creates Images for Draw.io Pages
Note
The functionality described in this blog post is available as of WikiTraccs v1.27.1.This post builds on the last one that highlighted how WikiTraccs can create missing draw.io preview images: WikiTraccs Creates Draw.io Preview Images.
But why stop at missing draw.io preview images? Let’s apply the export logic to draw.io diagram pages as well.
How Do Diagram Pages Work in Draw.io?
Draw.io diagrams can contain multiple diagram pages which are represented as tabs at the bottom of the draw.io editor.
Here is a simple sample diagram, showing the first of three pages:

Clicking a tab will switch to the corresponding diagram page.
A draw.io macro by default shows a single diagram page, although you can cycle through the pages:
In the draw.io macro settings you can select the diagram page to show when opening the Confluence page:
When you migrate a Confluence page (that contains draw.io) to SharePoint and not all diagram pages are shown via draw.io macros, most diagram pages tended to be invisible in SharePoint.
WikiTraccs changes that.
Creating Draw.io Page Images in SharePoint
WikiTraccs can create images for all diagram pages in a draw.io diagram:
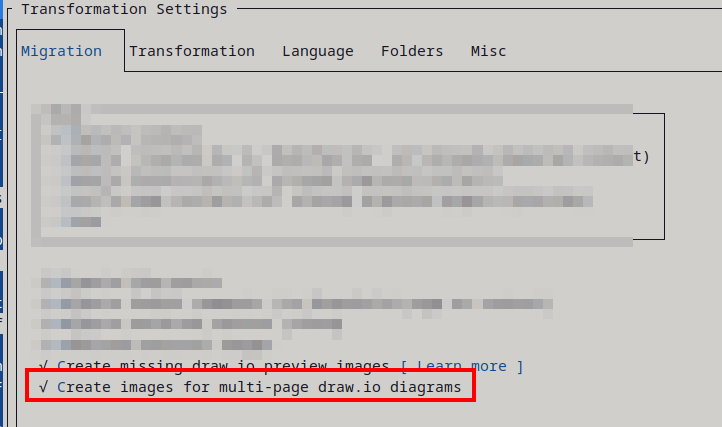
It doesn’t matter if all those diagram pages are shown on a Confluence page.
The moment a single diagram page is shown on a Confluence page, WikiTraccs will export all diagram pages as images and migrate those to SharePoint Online.
You’ll see a collapsed section labeled Page Snapshots of Draw.io ‘DIAGRAMNAME’:

Expanding this section shows all diagram pages:

As shown in above screenshot, WikiTraccs will:
- create a section that is add after the section that contains the first draw.io diagram page
- create an image for each of the diagram pages
- format those images using a layout table, as SharePoint otherwise is not able to put images next to each other
Each of the exported diagram page images is stored as additional attachment of the SharePoint page. Those pages are marked with the -wt suffix.
Note
WikiTraccs will export images from the latest version of the draw.io diagram file. Draw.io macros in Confluence might’ve referenced an older version, so there could be visual differences between those macros and the exported images shown in SharePoint. A note in the section title will hint at the fact that the images are from the latest diagram version (’latest version’).I’m not yet satisfied with how the section looks in SharePoint. Is it at the right place? Should the section be lower in the page? How about a section background color? Should the formatting table have borders? I appreciate feedback on this matter.
Known Limitations
When there are multiple multi-page diagrams on a page, the sections in SharePoint will be generated in reverse order.
Exporting Historical Page Versions - It's Complicated
The origin of this post is the requirement to migrate historical page versions to SharePoint Online. WikiTraccs currently doesn’t do that.
Could WikiTraccs migrate historical page contents? It’s complicated and also a matter of expectations.
In this post, we first look at Confluence’s own limits in properly representing page history. We then look at how macros behave. We’ll also explore options to export historical page versions from Confluence. And finally we look at what that means for WikiTraccs in the context of Confluence to SharePoint migrations.
Let’s start with breaking page history by messing with attachments.
Version Note
The tests in this article were conducted in Confluence 8.7.1.Changing Attachments Changes Page History
The following steps show how to change page history by overwriting an attachment file that is used by the historical page. The historical page will show the updated file (but shouldn’t).
This page shows two old Atlassian logos:
The attachments for this page show the two image files as atlassian-logo.png and atlassian-logo2.png:
Now let’s assume Atlassian rebrands and the page is updated with the new logo (creating a new page version):
The image file for the new logo is uploaded as atlassian-logo.png, overwriting the existing file that has the same name. The other attachment, atlassian-logo2.png is not needed anymore and thus deleted:
Looking at the page history, we now have two page versions:
And now things get weird.
Comparing the two page versions makes it evident that changing the attachments also changed the page’s history:
Let’s export the page as PDF using the built-in Export to PDF function that Confluence offers.
Here’s how the export looks for the current version of the page; this looks correct:

Now switch to the older page version (you guess where this is going…). This is Confluence showing version 1 of the page:

Here’s how the export looks for the old page version; this does look unexpected, as both the historical images and the historical text are absent:
Exporting old page versions to PDF is not supported. Confluence always exports the current version.
Exporting Old Page Versions to PDF is Not Supported by Confluence
Just to make that really clear: using the out-of-the-box PDF export of Confluence, you can only export the current page version. Even when viewing a historical version, using the export function will export the current version. This also applies to the Word export, by the way.
There might be third-party solutions available that solve this problem. But we are looking at out-of-the-box features.
Unclear What to Expect from Macros
Let’s see how macros handle being shown on historical page versions. The results will differ from macro to macro and are not always correct.
Children Display Macro
Here’s the built-in Children Display macro added to our sample page, correctly showing one child page:
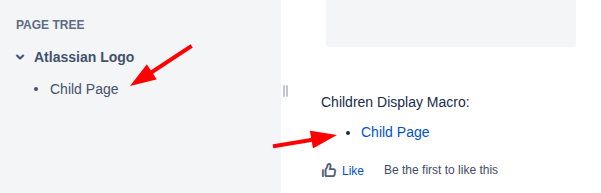
By editing the page to add the macro, we created a new page version. When viewing a historical version of the page, the expectation could be to see exactly the above state, showing the one child page (spoiler: that doesn’t work).
Now we edit the page and add some text, while at the same time adding a second child page. The result is additional text on the page and the macro showing two child pages:
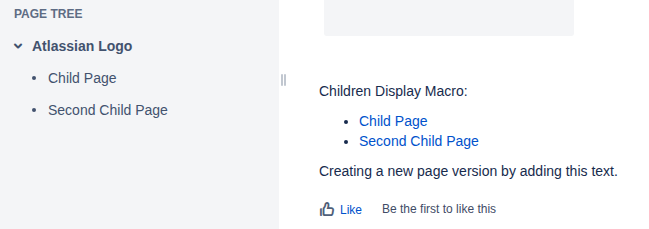
Now let’s go back in history and view the previous page version:
To be honest, I did not expect this. I expected the Children Display macro to show up and to show the current state of the page tree (so, two child pages).
Apparently the Children Display macro cannot handle history, at least in Confluence version 8.7.1.
Team Calendar
How is the Team Calendars macro handled when going back in page history?
Here’s our modified sample page, showing a Team Calendar with Adele’s vacation:
Editing the page (creating a new page version), we change the macro configuration to show all vacations as a list. Also, Parzival’s vacation has been added, making it two entries in the list:
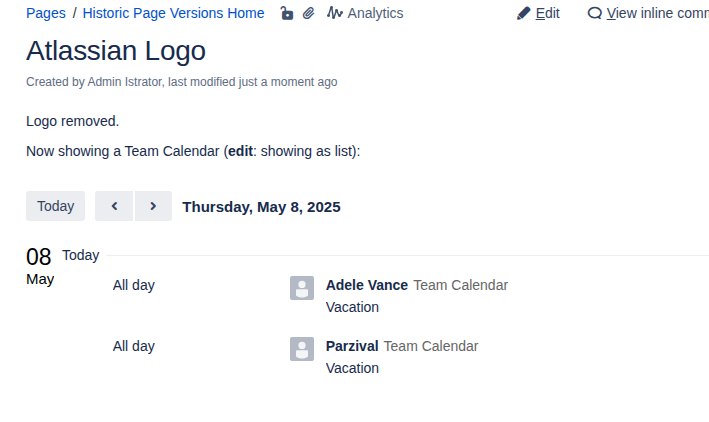
Now let’s go back in page history, viewing the previous page version.
The historical Team Calendar macro correctly applies the old configuration (showing a calendar, not a list), but the vacation data is current. It shows both vacations, even though at the time this page version was created, only Adele’s vacation existed:
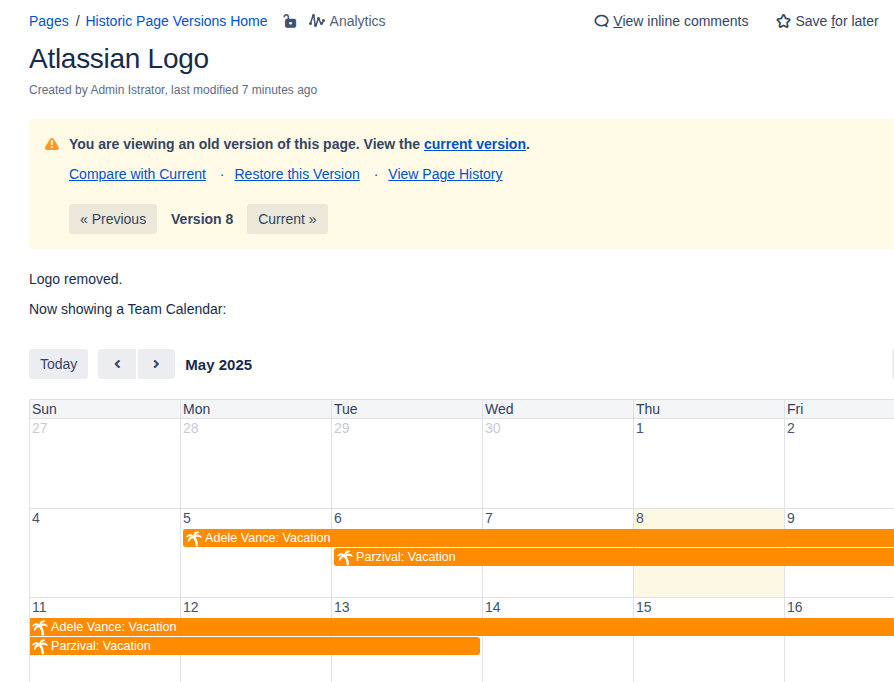
The result is a mix of historical macro configuration and current data.
By the way, exporting the current page version to PDF is broken as the calendar content is missing entirely:
How about Migrating Historical Page Versions to SharePoint Online?
In my view, Confluence fails to properly show and export historical page versions. In many cases there are valid technical reasons for that, but that doesn’t help.
On top of that, historical page behavior depends on how macros are implemented, which differs from vendor to vendor.
WikiTraccs cannot change any of the above if it tried to migrate historical Confluence page versions to historical SharePoint page versions.
Given the limitations and behavioral differences of SharePoint, the migration result for historical page versions would be even less appealing than it currently is using out-of-the-box tooling in Confluence.
There is one approach, however, that would allow migrating historical Confluence page versions to SharePoint while staying as close as possible to what Confluence offers - and that is printing the page.
Printing Historical Pages to PDF
The approach really is that simple: open a historical page version in the browser; print the page to PDF using the browser.
Here’s different versions of our sample page printed to PDF:
The current page version.
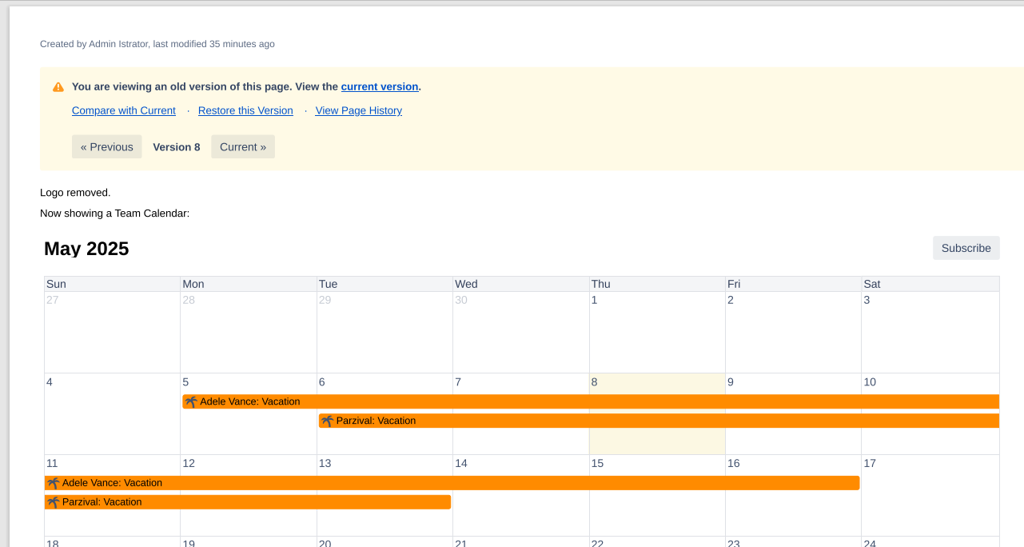
Historical page version, showing the Team Calendar as calendar.
Historical page version, showing the broken Children Display macro.
The very first historical page version, showing the modified images.
Printing pages to PDF has the following benefits:
- the historical content should be near identical to what Confluence shows in the browser when viewing a historical page version (although there seem to be styling deviations)
- the PDF contains information like author, version, labels etc. - which can be a benefit
- the printed PDF seems to capture more content than the built-in PDF export as the Team Calendars sample showed
There are also challenges with printing pages to PDF:
- very wide pages might get cut off if the PDF page is not wide enough
- Confluence Cloud adds floating menus and headers to the page that appear when printing the page, which might overlap with page content
- Contents in tab-like macros, collapsed Expand macros, etc. aren’t covered, as the printed PDF only shows what’s visible when opening the page initially
- there might be challenges with multilingual pages, where the current page content looks different, depending on the user’s chosen language
How about Third-Party Solutions?
So far, we looked at the Confluence standard.
There might be third-party solutions out there that allow exporting historical pages properly. If such a third-party solution would provide a REST API then WikiTraccs could leverage that to export pages.
Let me know if you know any good third-party solutions that could help.
Wrap Up
Confluence fails to meet expectations with regard to showing and exporting historical page versions.
Also, behavior of “historical macros” will differ from vendor to vendor.
Historical page versions might show broken macros, show a mix of historical macros and current data, and cannot be exported to PDF (using the out-of-the-box method).
WikiTraccs currently does only migrate the latest page version to SharePoint Online and - given all the limitations Confluence has when it comes to historical page versions - will not try to be smarter than Confluence.
Printing historical pages to PDF might be an option to migrate historical page snapshots to SharePoint Online, while staying as close to the Confluence standard as possible.
WikiTraccs Creates Draw.io Preview Images
Note
The functionality described in this blog post is available as of WikiTraccs v1.26.11.In Migrating Gliffy and draw.io Macros to SharePoint Online we briefly looked into how draw.io macros are migrated to SharePoint Online.
In Support Case: Missing draw.io Images we looked at how draw.io preview images are used by Confluence and WikiTraccs, and how they can be missing.
In this post we work towards a solution to create missing preview images and thus get our images back on migrated SharePoint pages.
Video Introduction to Draw.io Migration and Preview Image Generation
This 8-minute video briefly goes into how draw.io macros are migrated, why draw.io preview images are important for the migration, and how you can use WikiTraccs to bring them back if they are missing:
How WikiTraccs Can Create Missing Draw.io Preview Images
Since the only way to export a draw.io diagram is to show it in a browser first, WikiTraccs will do exactly that.
When encountering a draw.io diagram in Confluence where the preview image is missing, WikiTraccs tries to open the draw.io diagram in the browser to export it as image.
Here’s how that works:
- a page with draw.io diagram
diagram1is being migrated by WikiTraccs - WikiTraccs looks for the
diagram1.pngpreview image; if it is present: fine, us that; if it is missing, continue - WikiTraccs opens a browser to show the draw.io viewer, as documented here: https://www.drawio.com/doc/faq/embed-mode
- WikiTraccs loads
diagram1into the viewer (the diagram should be visible now) - WikiTraccs exports the diagram to a PNG image file and uses that from now on
Now there should be a diagram image on the migrated SharePoint page as well.
Note: This works for draw.io diagrams that are stored as direct Confluence page attachment. It won’t work for diagrams that are embedded to the Confluence page from an external location like OneDrive.
Prerequisites for Draw.io Preview Image Generation
Note
If you use Interactive as authentication mode for Confluence, you should be good to go; interactive mode also opens a browser window controlled by WikiTraccs.The following prerequisites need to be met:
- WikiTraccs must be able to start and control Chrome/Edge (depending on your configuration) to show the draw.io diagram viewer in the browser, and to be able to export the diagram; specifically:
- Google Chrome or Microsoft Edge must be installed on the machine WikiTraccs is running on
- Certain Endpoints must be available for WikiTraccs to download the WebDriver required to remote-control Chrome/Edge
- No cookies.txt authentication workaround is being applied (note: this is a rarely used configuration)
- Additional endpoints required by the draw.io diagram viewer need to be accessible from Chrome/Edge, where the diagram view will be shown by WikiTraccs
https://viewer.diagrams.net- to load the viewer and image resources- potentially more, depending on diagram content
Firewall
If you are in a locked down environment where outgoing connections need to be whitelisted, you will have to adjust the configuration to allow loading the diagram viewer resources fromviewer.diagrams.net.Draw.io Diagram Viewer Showcase
Below you see how the diagram viewer opened by WikiTraccs will look like.
If you see the diagram, the viewer resources seem to be accessible at least from this browser:
To verify the result, here’s a screenshot of how above diagram should look:
Screenshot of the draw.io diagram that should be shown in the diagram viewer above.
How to Enable Draw.io Preview Image Generation
In the WikiTraccs Settings dialog, check Create missing draw.io preview images:
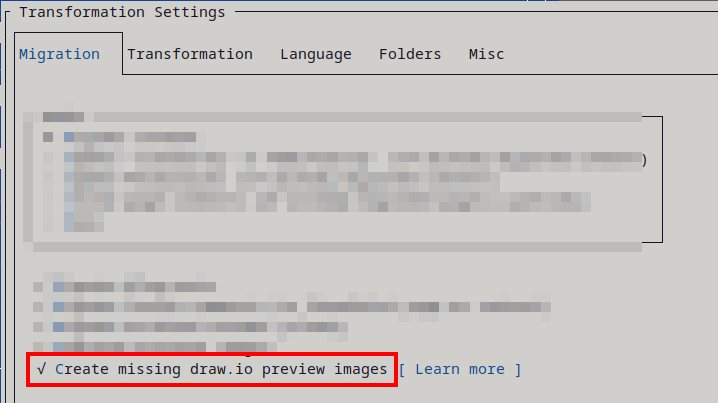
Known Limitations
Currently, there is no indication about external resources in diagram files. (Note: This will change in a future release.) If icons fail to be downloaded by the draw.io diagram viewer, those icons might be missing in the preview image as well. See also the sections External Resources and Blocking External Resources below.
Preview image generation works for draw.io diagram files that are page attachments in Confluence. There is an option to embed draw.io diagrams from external services like OneDrive or Google Drive - those cannot be handled.
In the wild WikiTraccs encountered a broken (?) draw.io macro that failed to properly reference the shown diagram layer which lead to a preview image being empty. So far, this was encountered once but if there is one case, there might be other such cases. Please report if preview images (generated by WikiTraccs) are empty.
WikiTraccs will export images from the latest version of the draw.io diagram file. Draw.io macros in Confluence might reference an older revision, so there could be visual differences between those macros and the exported images shown in SharePoint. I’m not sure if this is even an issue as the draw.io macro itself seems to prefer the latest diagram version (at least when linking across sites). A note above the image will hint at the fact that the image shows the latest version (example: ’note: latest version instead of v1’).
Privacy Notes
Diagram data stays local.
To cite drawio.com:
Our […] editor is loaded as a static application […], but the diagram data is passed entirely client-side between windows, it’s never sent back to, or sourced from, the draw.io application server. This means you control and store your data […].
So, while the editor is loaded from viewer.diagrams.net into the browser (to have a canvas to draw the diagram to), diagram data is processed locally.
External Resources
If a diagram contains links to external resources (for example external images not directly embedded in the diagram), the diagram viewer will download those resources. The external host will receive and can observe that request.
Blocking External Resources
When you block direct access to external resource hosts, the diagram viewer doesn’t give up; instead, it downloads resources via a proxy endpoint. This proxy is hosted on viewer.diagrams.net.
A call to the proxy endpoint looks like this: https://viewer.diagrams.net/proxy?url=https://upload.wikimedia.org/512px-Teams.png
So, when you block access to (for example) upload.wikimedia.org in your environment, and if viewer.diagrams.net can be connected to, the proxy will get the image for you.
In this process, the proxy learns about the URL of the external image.
If you want to prevent the proxy learning about external resource URLs, block the proxy endpoint as well. External resources will now be missing in the exported diagram, e.g. icons or images.
Note
Above information only applies to resources which are not part of the diagram file (thus being external). In most cases, icons, images, lines, text, etc. are part of the draw.io diagram file, which makes them internal resources that don’t need to be loaded from external hosts.Using the PnP Page Navigator Web Part as Table of Contents Replacement
With release v1.26.1 WikiTraccs introduced macro transformation templates that allow converting macros to SharePoint web parts.
Let’s try converting the Table of Contents macro to the PnP Page Navigator web part, which provides similar functionality.
What is PnP Page Navigator?
The PnP Page Navigator web part shows the headings of the SharePoint page it’s placed on. Clicking the heading entry will jump to the heading.
The Page Navigator is a SPFx solution that is developed by the PnP community, a group of people that creates open source solutions for the Microsoft 365 ecosystem.
The web part is available in the sp-dev-fx-webparts repository on GitHub: Page Navigator.
It seems to be distributed as source code, so normally you’d have to set up a development environment and build it for yourself. I did this for the current version 1.10 (released on March 15, 2025).
You can download the SPFx solution package for version 1.10 of the Page Navigator here: react-page-navigator.sppkg.
Note that I take no responsibility what’s in the solution. I merely followed the instructions on the solution’s README and built it from source code.
Creating a Macro Transformation Template
To tell WikiTraccs to transform the Table of Contents macro to the Page Navigator web part we need to create a macro transformation template.
It looks like this:
<script id="data-sp-webpartdata" type="application/json">
{
"id": "bcac4d9d-adf5-4462-97c5-e5f3e97dd518",
"instanceId": "{{{RandomGuid1}}}",
"title": "Page Navigator",
"description": "Page Navigator builds a navigation structure on the page, based on the headers in your text.",
"audiences": [],
"serverProcessedContent": {
"htmlStrings": {},
"searchablePlainTexts": {},
"imageSources": {},
"links": {}
},
"dataVersion": "1.0",
"properties": {
"stickyMode": false,
"stickyParentDistance": "1"
},
"containsDynamicDataSource": false
}
</script>
<div data-wikitraccs-webpart-template="true" data-sp-controldata="data-sp-controldata" data-sp-webpartdata="data-sp-webpartdata">🚧 Moved Page Navigator web part as it cannot be embedded here</div>
Note
Store this template as toc.hbs in WikiTraccs’ template folder to activate it.Note: At the time of writing this above template is not yet available in the WikiTraccs templates folder, but it will be in one of the next WikiTraccs releases.
Testing the Transformation from Macro to Web Part
Note
For the Page Navigator web part to be available in a site, the solution package must have been installed to an app catalog and the app been added to the site you want to use the web part in.Here’s our Confluence test page:
Note that table of contents macro at the start of the page.
Here’s the modern SharePoint Online page that WikiTraccs creates:
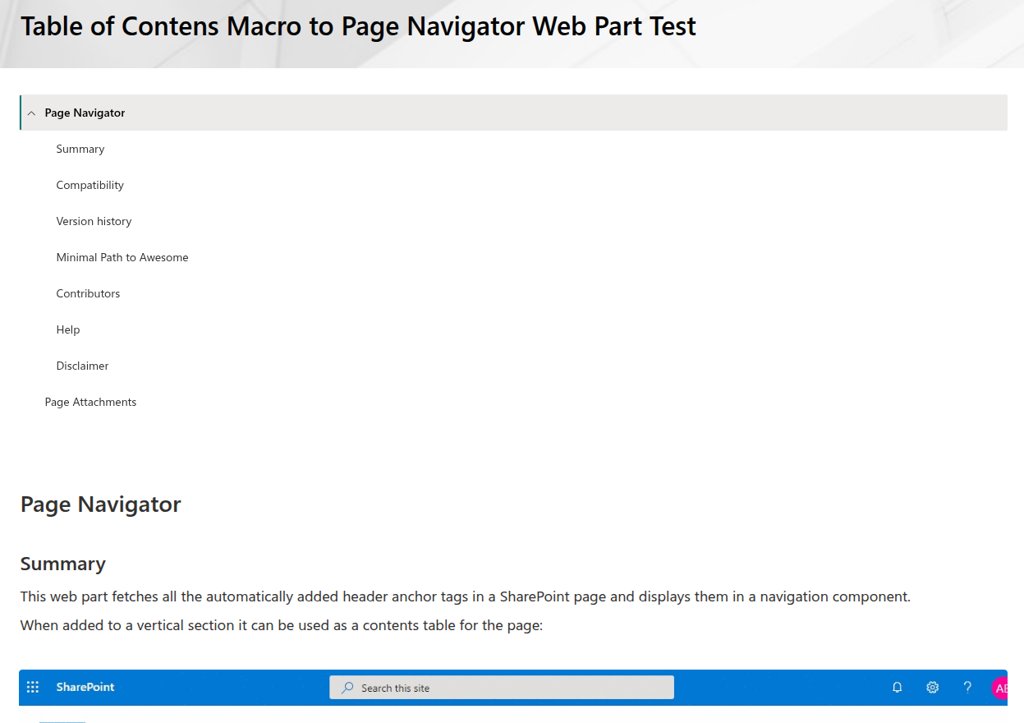
Note that the Table of Contents macro has successfully been transformed to the Page Navigator web part.
Closing Notes
While testing I stumbled over some effects that look like bugs in the Page Navigator web part:
- React-Page-Navigator - List View Threshold Error in Sites with More than 5000 Pages
- React-Page-Navigator - Empty Page Navigator If Page File Name has a + (Plus Sign) in It
I find it also important to note that the Page Navigator web part loads the whole page content again, to scan for headings. This might be a strain on mobile connections and something to consider when targeting environments where the amount of transferred data matters.
How Are Excerpt Include Macros Handled?
In Confluence it is common to reuse parts of a page in other pages.
One way to do that is using the Excerpt macro to define a reusable content snippet and then, on another page, the Excerpt Include macro can be used to reference and show that reusable snippet.
In SharePoint there is nothing that compares to this function as I outlined in Sharing Content Across Pages Is Impossible.
So, when encountering those macros, how does WikiTraccs handle them?
Excerpt, Multiexcerpt
Let’s look at the source of the reusable snippets.
WikiTraccs currently handles Excerpt and Multiexcerpt explicitly.
The body content of those macros will be migrated as if it was normal page content.
The enclosing macro does matter in one regard - it has a hidden parameter. This parameter specifies if the macro is visible on the page or not.
How does WikiTraccs handle the value of the hidden parameter? That depends on the macro transformation templates for Excerpt and Multiexcerpt.
At the time of writing this, hidden Excerpt macros are skipped (the migrated page does not contain its content), but the content of hidden Multiexcerpt macros is migrated and marked as originating from a macro. This has historical reasons. The behavior can be changed by changing the macro transformation templates.
Excerpt Include, Multiexcerpt Include
Let’s look at the macros that can show the reusable content snippets defined by Excerpt and Multiexcerpt: Excerpt Include and Multiexcerpt include. Those are the two that WikiTraccs handles (at the time of writing this).
When encountering one of those Excerpt/Multiexcerpt Include macros, WikiTraccs loads the referenced page that contains the corresponding Excerpt/Multiexcerpt macro, copies its body content, and inserts it into the referencing page at the place of the Include macro.
WikiTraccs takes care of adjusting links and image references in the copied content so that they continue to work in the new context.
What WikiTraccs doesn’t do is copying images (or other attachments). If the resusable snippet contains an image, this image will be referenced also by the content that WikiTraccs copies to other pages. So, the image is not copied to other pages.
Transformation Templates
The handling of the Excerpt Include and Multiexcerpt Include macros is somewhat special in that they use the new (note: as of WikiTraccs v1.26.0) macro transformation stages builtin and postbuiltin.
When handling the Excerpt Include and Multiexcerpt macros in the builtin stage of macro transformation WikiTraccs does not yet remove those macros from the source page tree, but enriches them with the copied macro body of the corresponding Excerpt and Multiexcerpt macro on the referenced page.
Now that the macros have a body, the transformation template for the next stage, the postbuiltin stage, takes care of replacing the macro with its body content and marking it.
The excerpt-include[postbuiltin].hbs transformation template is responsible for marking the copied content with two dividers and the link to the source page.
Support Case: Missing draw.io Images
Update
WikiTraccs can now bring missing preview images back! See WikiTraccs Creates Draw.io Preview Images.In Migrating Gliffy and draw.io Macros to SharePoint Online I briefly explained how draw.io macros are migrated to SharePoint.
The post briefly describes how there are two assets for each draw.io diagram in Confluence:
- the draw.io raw diagram file (file without extension)
- a preview image of the diagram (PNG file)
From time to time clients encounter cases in their environment where the preview image is missing. What are the consequences of a missing preview image?
How Is the Preview Image Used in Confluence?
Let’s look at this page, which has two diagrams, one with its preview image missing:
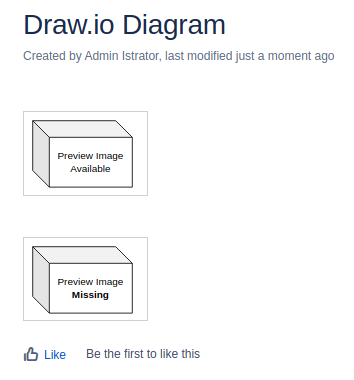
The attachments list looks like this; note there is only one preview image present (preview-image-available.png), I manually deleted the other one:
Looking at above screenshots, let’s start with the one place where the missing preview image is no issue: the actual diagram on the Confluence page. So, you don’t immediately notice that the preview image is missing when looking at the page, as the diagram is properly shown.
Missing in Page Edit Mode
When editing the page this looks different. Apparently the preview image is required here:
Sometime a placeholder is shown, like above, sometimes there is a “broken image” icon.
Missing in Page Exports
The diagram will be missing in page exports.
Here’s the PDF export of our sample page that contains two draw.io diagrams; but only one shows up in the export:
Missing in Emails
There are use cases in which Confluence page content is sent via email. Those uses cases also rely on the preview images being present.
If the preview image is missing, the image won’t show up in the email that gets sent.
Missing in REST API Integrations
There are REST endpoints that can be used to export macros in automated scenarios.
Normally, data returned by those endpoints contains the image (if the macro has one). The PlantUML macro is one such example where a proper image is being generated and returned. Or the Roadmap macro.
Those REST endpoints can be used by tools like WikiTraccs to further process the page, or other script-based solutions that further process the page.
For draw.io, if the preview image is missing, it will be missing for all REST API consumers as well.
Missing on Migrated Page in SharePoint
WikiTraccs relies on the preview image to be present. It’s what’s shown on the SharePoint page.
If the preview image is missing, no image can be shown.
Note that the raw draw.io diagram file will be migrated as page attachment and could theoretically be downloaded and opened in the draw.io desktop application.
How to Check If I Am Affected?
Draw.io provides a built-in integrity checker that is available to Confluence administrators:
The integrity check will also check for missing preview images.
The integrity check result then looks like this:
The following diagram images were not found:
Total: 1
Macro: drawio, on page: http://wiki.contoso.com/pages/viewpage.action?pageId=22183937, Diagram image file not found: preview-image-missing.png (version: 1)
Unfortunately, draw.io doesn’t provide a repair function.
Version Note: Tested on Confluence Data Center 8.7.1 with draw.io version 13.1.10.
How to Get The Preview Image Back?
Update
WikiTraccs can now bring missing preview images back! See WikiTraccs Creates Draw.io Preview Images.There seems to be only one way, to get the preview image back: edit and save the draw.io diagram in the browser.
Saving the diagram is the moment where the preview image is created and stored.
The preview image seems to be created in the browser, which would explain why there is no other mechanism to trigger the generation of this image. The draw.io diagram has to be open in a browser. Only then is it available to be saved to file by the draw.io editor.
Let me know if you know of another way to get the preview image back.
Note
While testing the draw.io integrity checker, I noticed that it failed to recognized re-created preview images. They still showed up as missing. Not sure if that is an issue of my test environment, or a general one.Confluence Cloud and External Sources
In Confluence Cloud, using the Embed draw.io Diagram macro, it’s possible to include draw.io diagrams that are stored in OneDrive and other cloud locations.
When you visit a page with OneDrive integration for the first time, the following message will be shown:
"Authorize draw.io to access OneDrive"
When clicking the message, you’ll be asked to authorize draw.io:
"Authorize draw.io to access OneDrive"
After giving authorization, the diagram should be shown. Unless there is a permission error.
In case of permission error, the following message will be shown:

"Error: Access Denied. File not found or you do not have permission to access 'diagramname.drawio' on OneDrive."
When the access issue is resolved, the diagram will be shown.
Now the caveat.
In none of the above cases - even if the diagram is shown - will the preview image of the diagram be generated. Thus, there will be no image in SharePoint Online since it’s only in the diagram macro that the image is being rendered.
This is a technical limitation.
New WikiPakk Children Display Web Part and Usage Metrics
The latest WikiPakk release v2.9.0 addresses two often mentioned use cases.
Children Display Web Part
You can now use the Children Display web part to show child pages of the current page.
Note
The Children Display web part is a new web part. So, there are now two WikiPakk web parts available - Children Display, and the Page Tree Editor.Take this page tree for example:

Now, placing the Children Display web part on the Testspace Migration page shows all of its four children:
The hierarchy information for the Children Display web part is the same as for the page tree and breadcrumb.
The Children Display web part makes it super easy to navigate to child pages.
This three-minute video shows how it works:
Optional Usage Metrics Recording
How much value are your users getting from WikiPakk?
I understand that this question needs to be addressed to allocate budget for a solution like WikiPakk.
WikiPakk has now optional telemetry built in that can be switched on to record usage metrics. It’s turned off by default and needs to be explicitly configured.
When turned on, all data stays within your SharePoint tenant. And again, by default it’s off.
This eight-minute video shows how to set it up:
Above video walks you through:
- setting up a central site to store the data
- pointing WikiPakk to this central location
- creating the SharePoint list that is used to store the data
- watching recorded usage events
Note
Your central site might already have been configured if you chose to store your WikiPakk license key there.Please check the WikiPakk Telemetry article for additional permission-related steps you need to take: How to Set Up Telemetry.
Addressed Issues
The breadcrumb sometimes showed the previous page after navigating. This has been addressed.
The page tree editor web part sometimes failed to save a drag operation. This has been fixed.
Furthermore, the breadcrumb bar was shown when embedding a page using the Embed web part. This has been addressed. When the embed URL contains the IsDlg or env query parameters the breadcrumb bar now stays hidden.
Other Changes
You can now check for updates by clicking the Check for new version link in the about dialog:
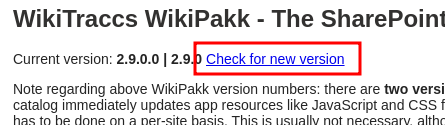
Both the Children Display and Page Tree Editor web part got a loading indicator providing better visual feedback than before:

How to Update
The update is available from Microsoft AppSource.
This article shows how to update: Update WikiPakk.
After the update, there should now be two WikiPakk web parts available:
- Children Display (WikiPakk)
- Page Tree Editor (WikiPakk)
Staged Deployment
In case of a staged deployment you will have to update the WikiPakk solution in both the site collection app catalog of your staging site, and the tenant app catalog.If you don’t see the two web parts, then you still need to update to the latest version. Refer to Check the Current and Available Version of WikiPakk for details on how to check which version you are on.
How to Export a Link Map
When migrating pages from Confluence to SharePoint WikiTraccs makes sure to transform links as well.
Links between Confluence pages will become links between SharePoint pages.
When you change Confluence links in external systems to SharePoint links it might be handy to have a link mapping file that - for each old Confluence page link - shows the new SharePoint page link.
This post shows how you can generate such a link mapping file using a PowerShell script.
Note about Scripting
PowerShell scripting is out of scope for WikiTraccs, but at the same time a part of most migration projects. Scripts of any sort can be used to automate tasks.
Feel free to take the library script that is presented in this post and adapt it to your needs. Please understand that I cannot support custom script development and that you’ll need somebody who can run, modify, and extend PowerShell scripts.
Outline
You’ll use a PowerShell script to create the link mapping file. A sample PowerShell script is available in the library.
Running the PowerShell script requires PowerShell 7 to be installed. Furthermore, the PnP.PowerShell module must be installed.
The PowerShell script connects to SharePoint Online and needs an Entra ID Application Registration Client ID for that. You already have such a client ID if you are migrating pages with WikiTraccs. You can use the same client ID that you enter in the blue WikiTraccs window.
Running the Library PowerShell Script to Create The Link Mapping
In a minute, you’ll run a script that processes the metadata of all migrated pages in a SharePoint site collection and calculates the original Confluence links from this metadata.
Download the Wiki Transformation Project libray as zip file:
Unzip the file you downloaded. (Note: You could also use Git to clone the repository.)
Open scripts/post-migration/create-link-mapping/CreateLinkMapping.ps1 and adjust the parameters at the top of the script, mainly the client ID and the site collection URL.
Note
I recommend using Visual Studio Code and the PowerShell extension to run PowerShell scripts. This allows for easy configuration, debugging, and modification.Run the PowerShell script.
A new browser tab will open, prompting you to authenticate with Microsoft 365. This is required for the PowerShell script to read page metadata from the Site Pages library.
After authenticating the script should show console output for each page it processes, which could look like on the following image:

The link mapping result is written to a text file called linkmapping.csv which is stored to the current directory.
The content looks like this:
"SharePointPageLink","PageTitleLink","PageTitleLinkAlt","PageIdLink","PageTinyLink"
"/sites/migtarget1/SitePages/TM-Page-S1---Code-Snippet-106070257.aspx","http://localhost:8090/wiki/display/TM/Page+S1+-+Code+Snippet","http://localhost:8090/wiki/pages/viewpage.action?spaceKey=TM&title=Page S1 - Code Snippet","http://localhost:8090/wiki/pages/viewpage.action?pageId=106070257","http://localhost:8090/wiki/x/8YBSBg"
"/sites/migtarget1/SitePages/TM-Page-S6---Table-Cell-Colors-110464825.aspx","http://localhost:8090/wiki/display/TM/Page+S6+-+Table+Cell+Colors","http://localhost:8090/wiki/pages/viewpage.action?spaceKey=TM&title=Page S6 - Table Cell Colors","http://localhost:8090/wiki/pages/viewpage.action?pageId=110464825","http://localhost:8090/wiki/x/OY_VBg"
"/sites/migtarget1/SitePages/TM-Page-S2---Page-Tree-183861249.aspx","http://localhost:8090/wiki/display/TM/Page+S2+-+Page+Tree","http://localhost:8090/wiki/pages/viewpage.action?spaceKey=TM&title=Page S2 - Page Tree","http://localhost:8090/wiki/pages/viewpage.action?pageId=183861249","http://localhost:8090/wiki/x/AYD1Cg"
Using Confluence page title, page ID, and tiny link (all migrated by WikiTraccs) the script calculated possible Confluence links, as those link types are known and follow a common scheme.
The script creates the most common Confluence (on-prem) link types: title link, pageId link, and tiny link.
Note
Confluence Cloud introduced new link types, those are not yet covered. Feel free to share the extended script if you add those.The script connects to a single site collection at a time. Reconfigure and run this for every site collection you need the link map for. Or extend the script to take care of that and merge the mapping files.
Wrap
In this blog post we looked at how we can use migrated page metadata and a PowerShell script to create a mapping file that maps Confluence page links to the new SharePoint page links.
This can be helpful, for example, when searching and translating Confluence links in third-party systems.
Sharing Content Across SharePoint Pages Is Impossible
OK, technically speaking, sharing content across pages is possible; however, it’s neither usable, nor does it look good.
Let’s quickly look at the use case then we try different approaches.
Use Case
Sometimes the same content needs to be shown on multiple pages.
Instead of copying the same content into multiple pages, we want to have one place to author the content.
In Confluence this is easy using different excerpt and include macros. You can embed whole pages into other pages, or excerpts of pages into other pages.
This is what we need in SharePoint as well, at least when coming from and knowing the capabilities of Confluence.
Let’s do it.
Embedding a List Item with Rich Text Content
This approach seemed like a really good one.
We can store shared content snippets in a SharePoint list. SharePoint lists supports rich text columns that can contain formatted content.
In modern SharePoint pages, we can then use the Embed web part to embed the list item we want to show.
Technically, this works; but here is how it looks:
Note that the content we want to embed is just the text “Item content”, nothing else.
Furthermore, the web part is way too high, the formatting and positioning is off, and there are user interface elements that we don’t need.
Here’s the URL that was used to embed the item:
https://contoso.sharepoint.com/sites/2025-01-embedding/Lists/Excerpts2/DispForm.aspx?ID=1&Env=embedded
So this is no good.
I also played with JSON-based list formatting but all to no avail. If you know a way to embed a single field of a list item to a SharePoint page, without pulling in a clunky UI around that, let me know.
Embedding Another Page
Maybe we could store shared snippets as separate pages. A little heavyweight, but maybe this works?
Let’s see how that looks, again using the Embed web part to embed another page:
Nearly the same result as with the list item.
The web part doesn’t adapt to the page content’s size, formatting is off, user interface elements are shown that we don’t need.
Even worse - for the embedded page to load, you have to hover the mouse cursor over the web part. Until you do that, the web part looks like this:
No good.
Embedding Another File
Let’s go another route and put our shared content into a Markdown file.
We can embed the Markdown file using the Embed web part as well. The result is comparable to embedding a page, and the user also needs to hover the mouse over the web part for it to show the actual file content.
There is one alternative to the Embed web part, though.
Using the File and Media web part, it is possible to make the file content show immediately, without having to hover over the web part.
Here is the File and Media webpart showing Markdown content from a file:
And again, the web part is way too high and there is no way to adjust that.
Just no good.
Now I’m out of ideas.
Wrap
In SharePoint Online, using modern pages and without using third-party tools, there doesn’t seem to be a way to share content across multiple pages.
This is disappointing since it is the easiest thing in Confluence.
A migration tool like WikiTraccs thus has only two options when migrating shared content from Confluence to SharePoint: copy content to multiple pages, or link to the source page. Both approaches have drawbacks, so it would be nice to see SharePoint ramping up its wiki game here.
How Nested Confluence Macros Are a Migration Challenge
We’ll look at how macros are nested, if and how that can be done in SharePoint as well, and how WikiTraccs approaches this during a migration.
How to Nest Macros in Confluence?
Let’s look at some examples.
If macros have a body, it is often possible to nest other macros in that body.
Here we have a Warning macro nested in an Info macro:
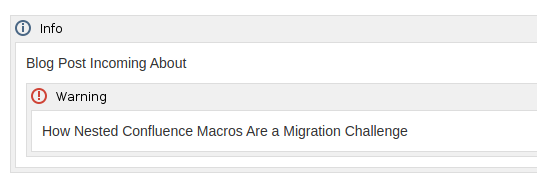
Edit Mode
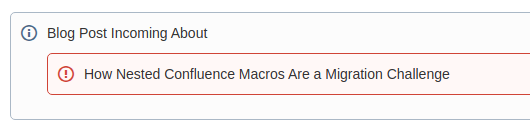
View Mode
Here are Code Block macros nested in a table:
Edit Mode
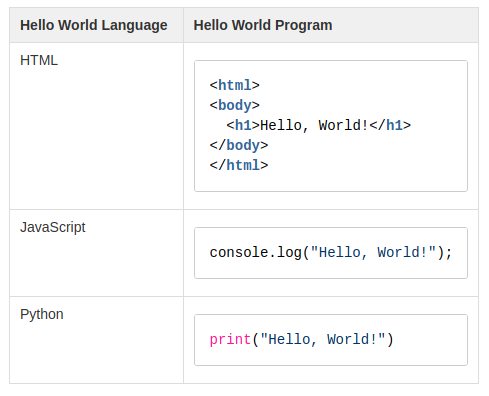
View Mode
Here’s a more complex setup using the Column, Section, and Panel macros to put text and Code Block macros in a column layout:
Edit Mode
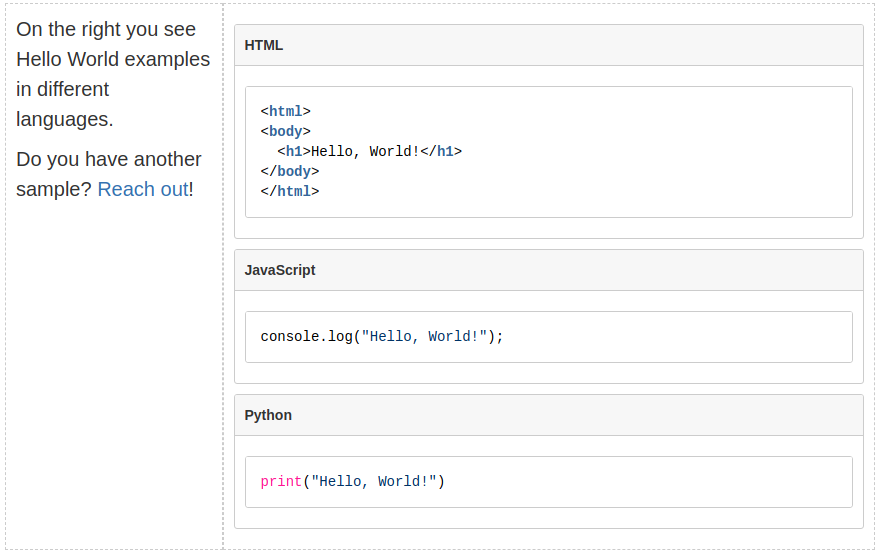
View Mode
How to Nest Web Parts in SharePoint Online?
It’s not possible.
In SharePoint Online, on modern SharePoint pages, you cannot nest web parts.
SharePoint web parts are put onto the page one after another; here a Text web part, followed by a Code Snippet web part:
It is technically impossible to put the Code Snippet web part into the Text web part.
This is a huge restriction compared to what you can do with Confluence macros.
What Does Missing Nesting in SharePoint Mean for Macro Migrations?
When trying to make nested macros compatible with SharePoint, here are the workarounds that can be applied:
- Converting nested macros to text so everything fits into a Text web part
- Moving nested macro content to another web part, e.g. moving the code macro to a separate Code Snippet web part
SharePoint also knows page sections, so there might be a chance one can get creative with those. But they are pretty heavyweight and cannot be nested as well.
How Does WikiTraccs Handle Nested Macros?
Let’s see the two de-nesting approaches in action with this Info macro that contains a Code Block macro:
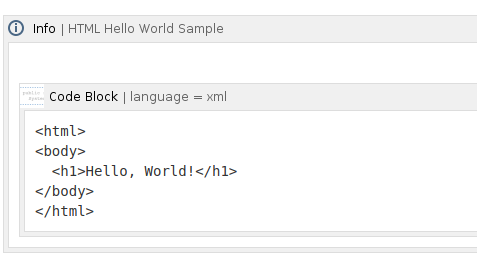
Code Block Nested Inside Info Macro
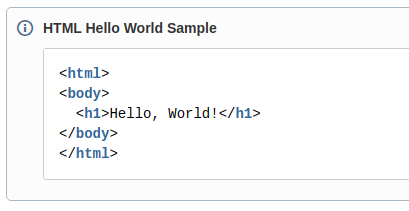
View Mode
When encountering this in a migration, WikiTraccs does the following:
- Convert the Info macro to a table in the SharePoint Text web part to make it look like in Confluence
- Create a Code Snippet web part below the Text web part, move the code there
- Create a note where the Code Block macro used to be about the de-nesting
- Create yet another Text web part right above the Code Snippet web part marking the moved code snippet
The result looks like this (in SharePoint page edit mode):
Note: The dottet lines highlight the three involved web parts; those are not normally there in SharePOint and have been added for emphasis.
Above image also highlights another challenge when splitting content into multiple SharePint web parts. There is a pretty large gap between web parts that can look awkward. But there is nothing that can be done about that.
Update: Improvements Since This Post Was Written
Update (May 2026)
Two changes since this post was originally written reduce how much de-nesting actually happens. The macro story above is unchanged, but several common cases now stay inline.Plain Nested Tables Are Now Preserved
A <table> nested directly inside another table cell, without a macro in between, often stays in place now. With the Use non-standard table transformation setting (on by default since WikiTraccs v1.24.20), nested tables are kept inside the SharePoint Text web part where the structure allows; particularly complex nestings may still be de-nested.
This does not change the macro de-nesting described above. A Code Block macro inside a table cell is still a web part nesting problem, not a table nesting problem, so it still moves to a separate Code Snippet web part below.
Small Code Block Macros Stay Inline as Monospace Paragraphs
Short code blocks no longer get extracted into a separate Code Snippet web part either. By default, Code Block macros up to a configurable line count are converted to monospace paragraphs that stay inside the Text web part. Only code blocks that exceed the threshold are moved into a separate Code Snippet web part below.
The threshold is configurable in the WikiTraccs Settings dialog. Raise it to keep more code inline and avoid the gap between web parts shown earlier in this post. Set it to 0 to restore the previous behavior of always extracting code blocks into their own web part.
Wrap
Nested Confluence macros, but also macros in tables and those that are used inline, pose challenges for the migration.
There is only so much a migration tool like WikiTraccs can do, given the limitations that SharePoint Online has.
For the future, I hope and wish that Microsoft further expands the capabilities of SharePoint pages and web parts. I know that the third-party component backing the SharePoint text web part supports something like macros and I’d really like to see the Expand macro implemented in SharePoint.
M365 Authentication, API Requests, and Blocked Endpoints
A recent customer support case required deeper insights into the API requests originating from WikiTraccs. A list of endpoints was required to whitelisting those at the proxy level.
While the WikiTraccs Endpoint Reference already covers endpoints, they weren’t detailed enough.
How to get more details?
I’ll describe how to use Microsoft’s Dev Proxy tool to get a list of endpoints.
Using Dev Proxy to Log API Requests
Dev Proxy is a small command line tool that creates a local proxy that can be used to log and change API requests of applications. It’s provided by Microsoft and free to use.
We’ll use Dev Proxy to log all API requests that WikiTraccs makes.
Note
Please refer to the Dev Proxy documentation on how to install it.Once installed, we configure it. Configuration is done via a JSON file.
The following configuration instructs Dev Proxy to log all requests to the console:
{
"$schema": "https://raw.githubusercontent.com/dotnet/dev-proxy/main/schemas/v0.24.0/rc.schema.json",
"plugins": [
{
"name": "UrlDiscoveryPlugin",
"enabled": true,
"pluginPath": "~appFolder/plugins/dev-proxy-plugins.dll",
"urlsToWatch": [
"https://*/*"
]
}
],
"logLevel": "information",
"newVersionNotification": "stable",
"showSkipMessages": true,
"showTimestamps": true
}
Save above text to devproxy.json.
Now we start Dev Proxy and instruct it to monitor WikiTraccs-related processes. Run the following command in a Terminal:
devproxy --config-file "C:\path\to\file\here\devproxy.json" --watch-process-names WikiTraccs.GUI WikiTraccs.Console conhost chromedriver chrome
Note
The--watch-process-names WikiTraccs.GUI WikiTraccs.Console conhost chromedriver chrome parameter restricts Dev Proxy’s operation to those processes. Omit the parameter to cover all applications running at the moment.Dev Proxy will now log all API requests done by WikiTraccs or the Chrome browser.
API Request for Authenticating with Microsoft 365
Since the customer that triggered this investigation reported problems when authenticating with Microsoft 365, let’s have a look at the API calls that go over the wire when doing that.
When hitting the Test SharePoint Connection button in the blue WikiTraccs.GUI window, the following endpoints are called:
https://login.microsoftonline.com/common/discovery/instance?api-version=1.1&authorization_endpoint=https://login.microsoftonline.com/421cd8a4-daf6-434c-8eae-a685c9af1808/oauth2/v2.0/authorizehttps://login.microsoftonline.com/421cd8a4-daf6-434c-8eae-a685c9af1808/oauth2/v2.0/authorize?scope=https://contoso.sharepoint.com/.default+openid+profile+offline_access&response_type=code&client_id=b05e893b-866e-40d3-be10-75e44e5c38c2&redirect_uri=http://localhost:64189&client-request-id=bbc47ed0-c9e4-44e5-b1df-72c6589892e8&x-client-SKU=MSAL.NetCore&x-client-Ver=4.61.3.0&x-client-OS=Microsoft+Windows+10.0.22000&prompt=select_account&code_challenge=snip&code_challenge_method=S256&state=snip&client_info=1https://login.microsoftonline.com/421cd8a4-daf6-434c-8eae-a685c9af1808/reprocess?ctx=snip&sessionid=a11f9fda-ae88-4a93-8d8b-68a3dd193e7bhttps://login.microsoftonline.com/421cd8a4-daf6-434c-8eae-a685c9af1808/oauth2/v2.0/tokenhttps://contoso.sharepoint.com/sites/testing/_api/Web?$select=Id,Url,RegionalSettings/*,RegionalSettings/DateFormat&$expand=RegionalSettings,RegionalSettings/TimeZone- … more calls of the SharePoint API
Note that
421cd8a4-daf6-434c-8eae-a685c9af1808is the SharePoint tenant IDb05e893b-866e-40d3-be10-75e44e5c38c2is Entra ID application client IDhttps://contoso.sharepoint.comis the SharePoint tenant URL
Unblocking above endpoints should make the authentication succeed.
Note
You might see calls to Google-related endpoints likehttps://accounts.google.com/ListAccounts - those are done by Chrome. They are not required by WikiTraccs and may safely be blocked, as long as Chrome keeps working.Simulating Blocked Connections
Keep reading if you want to know how to simulate slow network connections or incomplete proxy configuration.
This is one of the value propositions of Dev Proxy: you can see how applications behave in unexpected circumstances.
I’d like to emulate a proxy that delays responses of certain endpoints related to Microsoft 365 authentication.
Let’s extend the configuration file for Dev Proxy as follows:
{
"$schema": "https://raw.githubusercontent.com/dotnet/dev-proxy/main/schemas/v0.24.0/rc.schema.json",
"plugins": [
{
"name": "UrlDiscoveryPlugin",
"enabled": true,
"pluginPath": "~appFolder/plugins/dev-proxy-plugins.dll",
"urlsToWatch": [
"https://*/*"
]
},
{
"name": "LatencyPlugin",
"enabled": true,
"pluginPath": "~appFolder/plugins/dev-proxy-plugins.dll",
"configSection": "latencyPlugin1",
"urlsToWatch": [
"https://login.microsoftonline.com/common/discovery/instance*"
]
},
{
"name": "LatencyPlugin",
"enabled": true,
"pluginPath": "~appFolder/plugins/dev-proxy-plugins.dll",
"configSection": "latencyPlugin2",
"urlsToWatch": [
"https://login.microsoftonline.com/421cd8a4-daf6-434c-8eae-a685c9af1808/oauth2/v2.0/token*"
]
}
],
"latencyPlugin1": {
"minMs": 180000,
"maxMs": 180000
},
"latencyPlugin2": {
"minMs": 86400000,
"maxMs": 86400000
},
"logLevel": "information",
"newVersionNotification": "stable",
"showSkipMessages": true,
"showTimestamps": true
}
This configuration file adds the LatencyPlugin that slows down responses for endpoints. It is added two times, for two different endpoints, to set two different delays.
Endpoint one is https://login.microsoftonline.com/common/discovery/instance - this gets a response delay of 3 minutes (180000 ms).
Endpoint two is https://login.microsoftonline.com/421cd8a4-daf6-434c-8eae-a685c9af1808/oauth2/v2.0/token - this gets such a high response delay that it is equivalent with the proxy stalling forever.
Running Dev Proxy with above configuration has the following effects on WikiTraccs, both when testing the SharePoint connection and when starting a migration:
- the browser tab for logging in to SharePoint Online will only appear after a 3-minute delay
- after (seemingly) successful authenticating with SharePoint Online, WikiTraccs will wait for 100 seconds and run into a timeout, never completing the authentication
While waiting, WikiTraccs will appear stuck, not giving any feedback at all. This is something that needs to be addressed in a future update.
PnP.PowerShell
A quick aside about PnP.PowerShell which you might use in Microsoft 365-related projects.
Note
If you are not using PnP.PowerShell, yet, you should! It’s great for scripting everything related to SharePoint Online and Microsoft 365 in general.Under the hood, WikiTraccs uses the same authentication mechanism as PnP.PowerShell.
This is why the Dev Proxy configuration from the last section will also make PnP.PowerShell fail when connecting.
Here’s the PnP.PowerShell command that corresponds to what WikiTraccs does when connecting to SharePoint Online:
Connect-PnPOnline -Url https://contoso.sharepoint.com/sites/testing -LaunchBrowser -ClientId b05e893b-866e-40d3-be10-75e44e5c38c2 -Interactive -Tenant 421cd8a4-daf6-434c-8eae-a685c9af1808
In this command:
-Url https://contoso.sharepoint.com/sites/testingis the SharePoint site to connect to-LaunchBrowsertells it to open a tab in a browser where you can re-use an existing login-ClientId b05e893b-866e-40d3-be10-75e44e5c38c2is the Entra ID application client ID; this can be the same you use for WikiTraccs-Interactivesays that you’ll sign in with account credentials-Tenant 421cd8a4-daf6-434c-8eae-a685c9af1808is the tenant ID to use; you can copy that from the blue WikiTraccs.GUI window
So, if you ever want to test how your PowerShell scripts behave in “special” circumstances - you now know how.
Wrap
In this post we looked at the API endpoints that WikiTraccs uses when logging in to Microsoft 365 and how to assemble this list using Microsoft’s Dev Proxy tool.
As an aside we also looked at how to use Dev Proxy to simulate “special” network conditions and hint at how to test PowerShell scripts under similar conditions.
Migrating Confluence Cloud Whiteboards
Note
This post is only relevant for Confluence Cloud.Whiteboard migration can be enabled in the WikiTraccs settings:
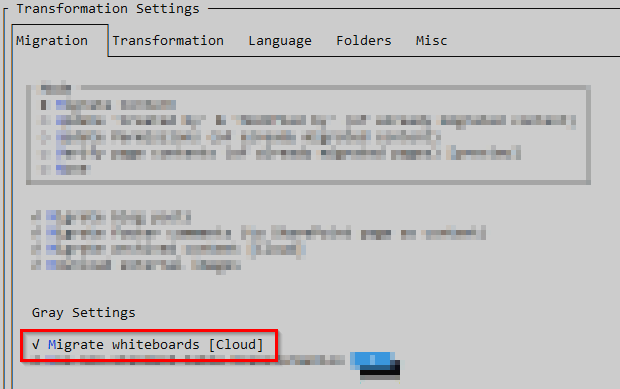
This will export Confluence whiteboards as image to SharePoint.
It’s a Gray Setting which means it might not be fully supported by a vendor.
Whiteboard Export is Not Supported by Atlassian
Let’s get that out of the way. Atlassian does not provide a supported programmatic export API for whiteboards at the moment.
The only way to export a whiteboard as image is to click the right buttons in the browser.
Here is one of the many whiteboard-related issues in the Atlassian Jira: Ability to export/import whiteboards (CONFCLOUF-76634). Please vote.
So…
How Does WikiTraccs Export Whiteboards?
WikiTraccs can export whiteboards as images.
It does it exactly like any user would do: by clicking the right buttons.
That means, WikiTraccs knows how the current Confluence Cloud user interface looks, how to find the right buttons, and how to click them, to start the image export.
After clicking the export button, it grabs the exported image from the download folder and that’s it.
Sounds rickety? It kind of is.
The export works, as long as the user interface does not change.
It can break if Atlassian changes the user interface of Confluence Cloud.
This video shows how it looks like, when WikiTraccs exports a whiteboard (32 seconds):
The following happens in this video:
- WikiTraccs discoveres a whiteboard to migrate
- WikiTraccs opens a browser under its control and navigates to the whiteboard (note: I had to move the browser window over from the second monitor)
- WikiTraccs clicks all the right buttons to export the whiteboard
- Chrome/Edge saves the downloaded image as Whiteboard.png
- WikiTraccs migrates Whiteboard.png to SharePoint, as page attachment
Everything that happens inside the browser is done by WikiTraccs, there was no user interaction (apart from moving the browser into view).
The resulting SharePoint page shows the exported image:
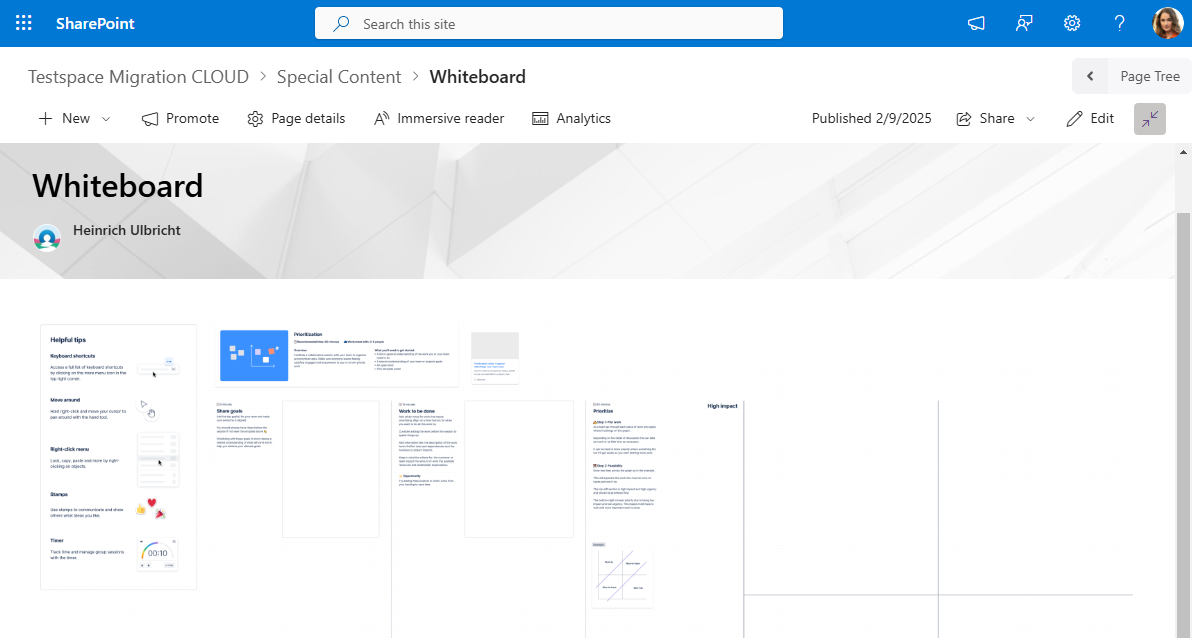
(Note: the whiteboard image can be huge, depending on the size of the original whiteboard. Clicking the image in SharePoint will expand it. It can also be downloaded to view it in full size.)
What Could Go Wrong?
As long as Atlassian doesn’t change the Confluence Cloud UI in a way that changes the buttons needed for the export, the process is pretty stable (although quite slow). So far, it broke about once in three months.
What sometimes happens is that remote-controlling the browser window fails for some reason. Might be a Chrome/Edge update, might be some Windows shenanigans. If that is the case, close WikiTraccs and all browser windows and restart the migration.
Note
You can restart the migration at any time. When starting a migration, WikiTraccs always checks what’s there in Confluence, what’s there in SharePoint, and it will migrate what is missing in SharePoint.What sometimes happens is that Atlassian is showing some advertisement for a new feature in the browser. Often, this ad is an overlay that is being shown until you manually dismiss it by clicking the X or Cancel. This might interfer with the export.
If there is an overlay or dialog being shown that blocks the export, simply close it. The whiteboard migration might continue, but restarting might be necessary as well.
If the export breaks, WikiTraccs probably will require an update.
Hardware Acceleration Required
Confluence whiteboards render via WebGL and need hardware-accelerated graphics in the browser. Without it, Atlassian’s whiteboard canvas may refuse to render and show a notice like “Your browser settings are slowing down your whiteboard” or “Update your display driver” - and WikiTraccs cannot export an image.
This commonly happens on virtual machines without GPU passthrough, for example a vanilla Azure Windows Server VM or a Hyper-V guest. The guest OS only sees a software display adapter (such as Microsoft Hyper-V Video or Microsoft Basic Display Adapter), Chrome/Edge falls back to software rendering or refuses WebGL outright, and the whiteboard never paints.
To fix it:
- run WikiTraccs on a physical machine or a GPU-enabled VM
- in Chrome or Edge, make sure Settings → System → Use hardware acceleration when available is on - corporate-managed browsers sometimes have it off by default
WikiTraccs’s status cockpit shows a GPU acceleration row that flags the most common cases as a quick heuristic. The authoritative source is chrome://gpu inside the browser WikiTraccs is using - if that page reports software-only WebGL, the host may need GPU acceleration before whiteboard export can work:

Output of chrome://gpu on a GPU-less host.
Under the Hood
To find the right button to click in the Confluence Cloud user interface, WikiTraccs uses CSS and XPath selectors.
You find those in a TOML file that is located at WikiTraccs.Console\Templates\BrowserAutomation\export-whiteboard.toml.
It contains selectors like this one:
[selectors.three-dot-menu]
description = "Three-dot menu in the upper right corner of a page"
language = "css"
query = "#more-actions-trigger"
This selector describes how to find the three dot menu button for a Confluence page.
There is a chance that, if whiteboard export breaks due to user interface changes, adjusting those selectors can fix the issue.
This approach to user interface automation is often used when programmatically testing user interfaces of web applications. WikiTraccs makes use of that approach to export whiteboards.
Authentication
Since WikiTraccs needs to open the whiteboard in the browser, this approach only works with Interactive Login where an account is logged in to Confluence to look at the whiteboard. It won’t work with Personal Access Tokens.
Wrap
In this blog post we looked at the current state of whiteboard exportability in Confluence Cloud, at how WikiTraccs does it and how it could break.
We all agree that this is a temporary solution and we hope that Atlassian provides an official export API in the near future (although I personally don’t believe that).
Harnessing the New SharePoint Page Format
In 2024, Microsoft upgraded the internal page format for SharePoint modern pages. The new format comes with an updated page editor and new formatting capabilities.
This change rolled out over the course of 2024 and now all new SharePoint pages use the new format.
But what about older pages?
How Microsoft Upgrades Older Pages
When a SharePoint page is edited in the browser, a (Microsoft-owned) script processes the page and - if required - upgrades it to the new page format.
This page upgrade happens only when a page is edited in the browser, so you can see the result immediately. During the upgrade, the styling of page elements might change.
What Microsoft doesn’t do is bulk-upgrading pages in the SharePoint backend. The upgrade only happens on a page-per-page basis when editing a page.
Here’s a sample of how the page upgrade looks:
This is what happens in the video:
- a SharePoint page is open in the browser
- the user clicks the Edit button to edit the page
- the content of the text web part briefly disappears
- the content of the text web part reappears, now upgraded
This video also illustrates one of the older (and now resolved) issues that could happen during page upgrade (the table ends up way too narrow).
Nowadays SharePoint also shows a progress message:

Page Upgrade Issues
There were several issues with the way Microsoft upgraded pages that were created in the pre-2024 format, e.g. with tables looking awful after the upgrade (as can be seen in above video), or lists that couldn’t contain images anymore. Most issues seem resolved.
One remaining issue affects larger pages with images.
When upgrading a SharePoint page, the upgrade script converts embedded images to a new format. Unfortunately, this process sometimes fails.
Note
This issue only affects the image display on pages. The actual image files (page attachments) are always present and available.What has usually helped so far is to wait a bit and avoid scrolling while the page upgrade is in progress. Alternatively, trying a different browser or closing and reopening the browser before editing a long page can help (I suspect memory might be an issue during page upgrade).
Essentially, keep trying until it works.
Before each new try, always revert the page to the previous page version. Reverting to the previous version makes the images reappear. After that, the page can be edited again, and hopefully, the upgrade script will complete successfully.
A Microsoft support ticket might also help, but I’ve had to do this a few times with regard to SharePoint pages, and it’s usually a slow process with moderate success. So far repeated attempts always resolved the issue.
Note
This issue should be gone with the new page format.What’s New in the New Pages?
In my view, the Text web part is the one that gets the most out of this page upgrade.
It gained the following new capabilities:
- line height settings
- more versatile spacing settings (space before, space after)
- new color options
- different styles for citations
- … and more
Overall, the new pages appear visually more balanced and appealing than their older counterparts.
How Does WikiTraccs Handle Old and New Pages?
WikiTraccs up until version v1.23 creates pages in the older format.
Going forward, since the new SharePoint page format seems to have stabilized, WikiTraccs will create pages in the new format.
Creating pages in the new format is opt-in.
How to Opt-In to New Pages?
Use WikiTraccs release v1.24.0 or newer and make sure to UNcheck Create SharePoint pages with pre-2024 type in the WikiTraccs Settings:
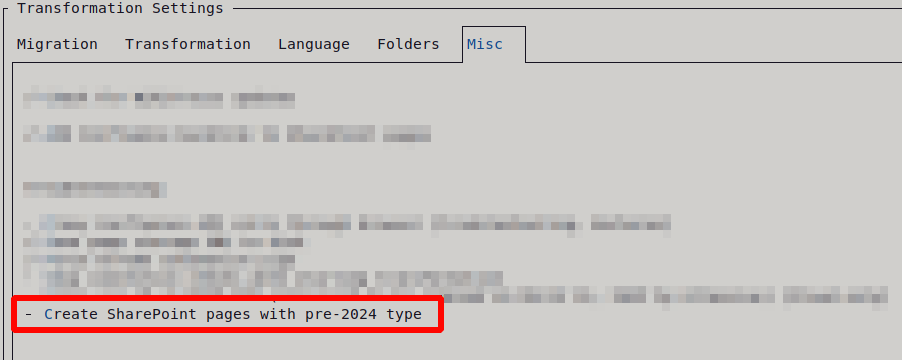
While creating pages in the new format is currently an opt-in setting, it will be the default in a future WikiTraccs release.
For now, you have to explicitly choose to have new pages created.
Wrap
Creating SharePoint pages in the new page format is a big change for WikiTraccs and allows using the full set of features that those pages bring.
Please report any issues that you see with the new pages.
Splitting a Space
Assume the following use case where a space needs to be split into multiple parts:
“We have a Confluence space that contains information contributed by seven different teams. Each team’s content needs to be migrated to a separate SharePoint site.”
Let’s assume that all pages belonging to one team have a common parent page. That’s 7 parent pages for 7 teams.
How to migrate each of the 7 parent pages and all their decendants from Confluence to 7 different target sites in SharePoint?
With WikiTraccs, there are two approaches to selecting parts of a space for a migration:
- the Content ID selector
- the CQL selector
We’ll look at the Content ID selector in depth.
Use the Content ID Selector
With the Content ID selector you give WikiTraccs a list of page IDs to migrate.
How you assemble the list of page IDs is up to you. With Confluence Server and Data Center a common approach is via database query, in the Cloud other approaches are warranted.
In this section we are looking at:
- a sample tree to illustrate migrating a subtree of pages
- how to assemble a list of page IDs from the Confluence database
- how to properly format those page IDs
- how to create a Content ID selector entry in the Confluence Space Inventory list
- how the Space Inventory looks after configuration
One way to get page IDs is from the Confluence database using SQL queries.
Consider the following page tree. How to get all page IDs of the Special Content page and all its descendants (because we want to migrate those)?
First we need the starting point, the page ID of the Special Content page, which is the root of the subtree.
To get the page ID for any page, open the Page Information page:
Then look at the browser bar that should show something like this: https://contoso.com/confluence/pages/viewinfo.action?pageId=65604.
The subtree root page ID in our case is 65604.
Now we can run the following SQL query on the Confluence database to get the list of descendants:
Note
Replace65604 in the following snippet with your subtree root page ID.SELECT c.contentid,
c.title
FROM content c
FULL OUTER JOIN confancestors ca ON ca.descendentid = c.contentid
WHERE ca.ancestorid = '65604'
AND c.content_status = 'current'
AND c.prevver IS NULL;
The result might look like this, but could also look different, depending on the tool that is being used:
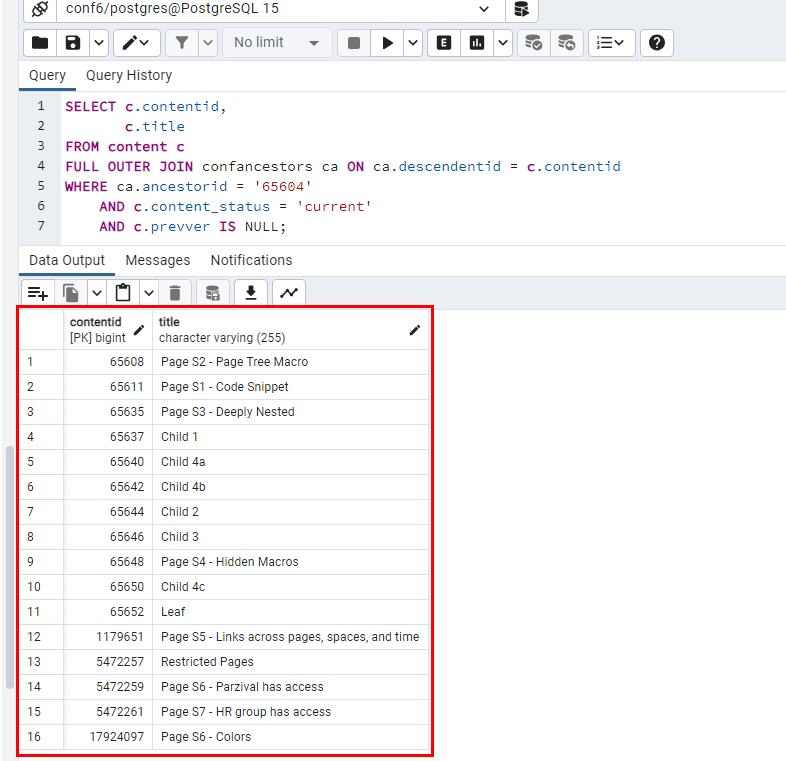
WikiTraccs expects those IDs to be in a specific format, though. We use an adjusted SQL query to get the list of IDs in the expected format:
SELECT count(*), string_agg(contentId || ';#' || contenttype, ',') AS contentIdSelectorValue
FROM (
SELECT c.contentid,
LOWER(contenttype) AS contenttype,
c.title
FROM content c
FULL OUTER JOIN confancestors ca ON ca.descendentid = c.contentid
WHERE ca.ancestorid = '65604'
AND c.content_status = 'current'
AND c.prevver IS NULL
ORDER BY contenttype, contentId
) subquery;
The result now looks different:

This result contains the number of pages (16) and the list of IDs, including their type, in the expected format:
65608;#page,65611;#page,65635;#page,65637;#page,65640;#page,65642;#page,65644;#page,65646;#page,65648;#page,65650;#page,65652;#page,1179651;#page,5472257;#page,5472259;#page,5472261;#page,17924097;#page
Note
Make sure to update the space inventory before proceeding by clicking the Update Space Inventory in WikiTraccs site button in the blue WikiTraccs window:

This makes sure that the space inventory list exist and that it contains space information you can build on.
This step is also included in the quick start guide, so if in doubt, refer to that: Getting started.
We can now create the content ID selector in the Confluence Space Inventory.
Click Add new item to invoke the respective dialog:
You need to fill the following fields:
| Field | Meaning | Sample Value |
|---|---|---|
| Title | Not used, but it’s a mandatory field; enter anything | dummy |
| WT_In_CfSiteId | Confluence base address; look at the other entries in the space inventory list to see what to enter | https://contoso.com/confluence |
| WT_Setting_RequestTransformation | Check this box to migrate this selector | ☑ |
| WT_Setting_ContentSelectorValue | The list of IDs in the expected format | 65608;#page,65611;#page,65635;#page,65637;#page,65640;#page,… |
| WT_Setting_TargetSiteRootUrl | SharePoint target site for migrated pages | https://contoso.sharepoint.com/sites/ContentIDSelectorDemoTargetONE |
All other values can be left empty, as those are not required for the Content ID selector.
The space inventory list, after adding two Content ID selectors, might look like this:

Two things are important as well:
- Don’t forget to add the ancestor page to the ID list of the selector as it is NOT part of the SQL result above.
- Remove the entry for the space your are splitting from the space inventory. Otherwise link translation might get confused and link to the wrong target site, as pages would be included in two selectors at the same time.
Now start a migration.
WikiTraccs should migrate the pages indicated by each Content ID selector to the respective target page. Links will be transformed as well, based on the target site URL configuration.
Use the CQL Selector to Choose Pages for Migration
The CQL selector works similar to the Content ID selector, but instead of giving WikiTraccs a list of page IDs you give it a CQL query - a Confluence search query.
Using a CQL selector works just like the Content ID selector:
- create a new item in the space inventory list
- enter field values as described in the last section; there’s only one difference
- instead of the list of IDs you enter the CQL query into the
WT_Setting_ContentSelectorValuefield
Using a CQL query, you can refer to Confluence content by criteria you define. Let’s create a simple CQL query that refers to all pages that have the label migration set:
The CQL query that finds those pages is label = migration.
You should always test that your CQL query works, before using it as a selector for WikiTraccs. You’ll spot errors in the query much faster.
Testing CQL queries in Confluence is a bit cumbersome as you have to use the REST API. Assuming your Confluence base address is https://contoso.com/confluence, the address for testing above CQL query is https://contoso.com/confluence/rest/api/content/search?cql=label = migration. Navigate to this address and the result should show a list of pages in JSON format:
Have a look at the CQL selector documentation to learn more details and read about some caveats associated with this selector type.
Configuring the Page Tree in SharePoint
If you choose to migrate a subtree of pages and you opted to add the WikiPakk page tree to the game, it will work well.
After migrating a subtree, open the migrated root page. Then open the page tree panel and click Move to tree root.
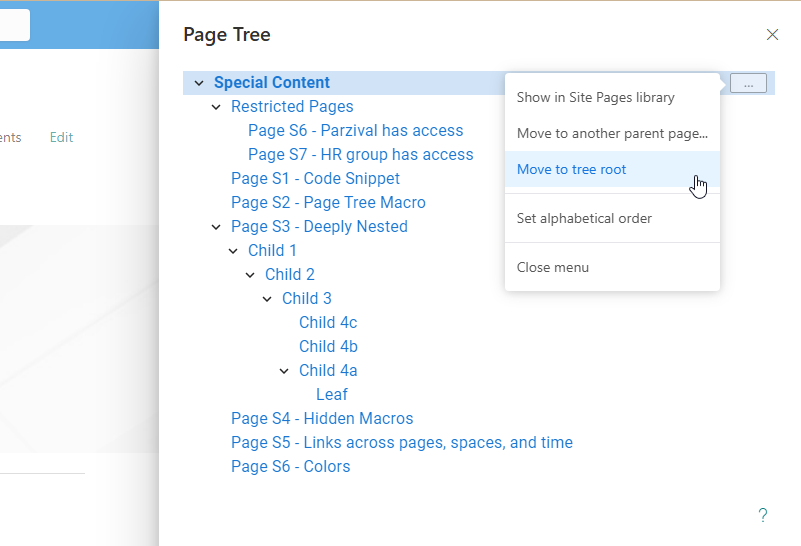
The subtree root will now always be shown when opening the page tree panel.
Note that this only works when migrating a subtree as this will also migrate the page hierarchy within the subtree. Migrating a list of arbitrarily picked pages won’t result in a proper tree in SharePoint.
Testing WikiTraccs for Markdown
This topic is part of WikiTraccs for Markdown and work in progress.
Join the waitlist and start publishing Markdown to SharePoint soon
The last blog post provided some background on how WikiTraccs for Markdown came to be.
This blog post shows how to publish Markdown files to SharePoint Online.
Sample Repository
We use a sample knowledge repository to test publishing Markdown to SharePoint Online. There is one available in our library: AI for Beginners Sample Repo.
This repository is a copy of one of Microsoft’s repositories about AI and contains lots of Markdown files, images, and folders:
This is not an ideal structure, but taking something “from the wild” seems like a good test. WikiTraccs will make educated guesses about IDs, parent-child relationships and so on.
For testing, download the whole library repository as zip file and extract it. Then use the ai-for-beginners-sample-repo folder as base address for your test.
Publishing Markdown to SharePoint Online
Starting with release v1.23.6, WikiTraccs supports file pathes as “Confluence” base address.
Enter the path to the ai-for-beginners-sample-repo folder:
Note
Naming throughout WikiTraccs is still focused on Confluence as sole data source. This will be adjusted in a later release.Make sure to activate the Skip Connection Checks setting as those are not required:
Then proceed as if you would migrate from Confluence:
- Update the space inventory
- Choose sources in the space inventory
- Start the migration
WikiTraccs should now start publishing Markdown to SharePoint Online.
Limitations and Work Items
This is a non-exhaustive list of things that need to be done before WikiTraccs for Markdown is ready for production use:
- auto-disable connection checks for Markdown source
- don’t use the folder path as source “Site ID”, as this makes migrating from different migration machines impossible
- optimize speed for larger repositories; currently it’s rather slow
- the page hierarchy is not yet properly migrated for the sample repo
- adjust the user interface to be “Confluence-free”
- figure out where to put images and files that are referenced by multiple pages; images currently are handled as “external” and duplicates are created per referencing page
- provide documentation on the expected source repository format and possible configuration options
- figure out a good format for IDs (numbers? GUIDs?) and how to make maintenance easy (e.g. preventing duplicates)
And probably more.
Finding the Confluence Version
Time and again the question comes up: which Confluence version am I running on?
One way of finding the Confluence version is as easy as scrolling down on any Confluence page. The version might be written there:
If you don’t see any version information in the page footer you might be using a theme that hides that information.
You can always resort to the /rest/applinks/1.0/manifest endpoint that shows the Confluene version as well:
- if your Confluence is available at
https://confluence.contoso.comthe address to navigate to would behttps://confluence.contoso.com/rest/applinks/1.0/manifest - if your Confluence is available at
https://contoso.com/confluencethe address to navigate to would behttps://contoso.com/confluence/rest/applinks/1.0/manifest
Navigate to the address in a browser where you are logged-in to Confluence and the page that opens shows the Confluence version:
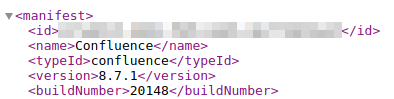
Here the Confluence version would be 8.7.1.
This also works in Confluence Cloud. The version number for Confluence Cloud always start with 1000.
WikiTraccs for Markdown
This topic is part of WikiTraccs for Markdown and work in progress.
Join the waitlist and start publishing Markdown to SharePoint soon
When demoing Confluence to SharePoint migrations with WikiTraccs, I sometimes get approached with something different in the context of a broader strategy shift.
Client are consolidating their knowledge repositories to cut costs, reduce complexity, and to be AI-ready.
In-house CMS systems are being sundowned, Confluence content is being moved to SharePoint Online (but only for so long).
One goal is to break free of any specific system for documentation and knowledge management, while still having the choice to publish to any service to make information available to users.
Clients are switching to Markdown.
So far, WikiTraccs transforms Confluence pages to SharePoint pages.
Here’s the question that I get asked: Can WikiTraccs also transform Markdown to SharePoint pages?
Soon, the answer will be Yes.
Publish Markdown to SharePoint Online
WikiTraccs for Markdown will be your tool to publish from Markdown to SharePoint.
Many other (free) tools are available to create, edit, and publish Markdown. WikiTraccs will help you with publishing to SharePoint Online.
I’m currently gathering information on how a Markdown-based knowldge base repository can compete with third-party services like a Confluence Enterprise wiki. Read more about that here: Strategy Shift to Text Files for Knowledge Repositories.
Proof of Concept
WikiTraccs for Markdown is currently in a proof of concept phase.
It can already pick up Markdown files from the files system and publish those to SharePoint Online, including page attachments and images.
WikiTraccs can already publish this Microsoft AI starter repository to SharePoint: AI for Beginners.
Here’s a page from that GitHub repository, as shown on GitHub:
And here’s the SharePoint page published by WikiTraccs:

Both pages are based on this Markdown file: README.md.
The Proof of Concept already raised some questions, among those are:
- What’s a common layout for the Markdown-based knowledge repository?
- How many pages and files might such a repository contain?
- How are attachments and pages related; how common is image-reuse?
- Is page attachments still the way to go in SharePoint, or should attachments be stored in separate Document Libraries?
- While Markdown files are perfect for being stored in a version control system, how about large attachment files?
Get in touch if you’d like to provide your thoughts or want to learn more.
Making SharePoint Tables Look Pretty
Outdated
This blog post is outdated. See the Update banners below for the current state. The body of the post is kept for historical reference.Update
As of April 2025 you can merge table cells in the SharePoint page editor. Microsoft added support for that.Update 2
As of May 2025 you can set the table cell background color and configure the border style.
So, all table formattings discussed in this post are finally also available in the browser-based SharePoint page editor.
You cannot create tables in SharePoint Online that have colored or merged cells.
(The blog post could should end here.)
But this is not entirely true. What is true is that, when creating a new SharePoint page, there are no tools that you could click in the text web part’s tool bar. There is no “merge cells” button and no color picker for cell backgrounds.
Nevertheless, it is possible to copy a table from Microsoft Word and paste it to a SharePoint page. Now, if that is officially supported (and I don’t know if it is), WikiTraccs could use the underlying mechanism as well.
This is why WikiTraccs introduces the Use non-standard table transformation setting, and we’ll look at why it’s named like that further down.
Copying tables from Word to SharePoint preserves styles
Take this table for example, created in Word Online:

This table can be copied to the clipboard:
And from the clipboard, the table can now be pasted into a SharePoint page, preserving its style:
Apparently copying and pasting a table from Word carries over cell colors and merged cells. And even more important: those styles stay in place when editing and saving the SharePoint page.
I had multiple clients reach out to me asking for this to be added to WikiTraccs.
WikiTraccs adds support for cell colors and merged cells
Note: this is available as of WikiTraccs v1.22.5.
WikiTraccs can now transform Confluence tables such that cell colors and merged cells are preserved.
This feature is opt-in, you have to activate it in the WikiTraccs settings. Note: This feature is on by default starting with WikiTraccs v1.24.20.
Here’s how to de/activate the feature:
- in the blue WikiTraccs.GUI window, click Settings in the menu bar to open the Settings dialog
- in the Settings dialog, in the Migration tab, un/check the option Use non-standard table transformation
Is this supported by Microsoft?
I don’t know if those copied-over tables are officially supported, as end users can not create them in the text web part editor. Copy and pasting seems to be the only way.
At the same time, I heard from clients that they use this functionality and also that this seemed to be advertised by Microsoft as a feature some time ago.
Why am I cautious?
I’m cautious because page content that cannot be created in the browser editor, by the user, by clicking buttons, might cease to work with a future update (by Microsoft) of the text web part. This might also affect how pages behave when being edited; styles might change or content even disappear.
Will that be the case in the future? I don’t know. I hope not.
Is there a way out if something happens in the future? There certainly is, by modifying page contents via PowerShell.
As long as there is this uncertainty, the setting is placed in the Gray Settings area of the Settings dialog, and it carries the non-standard hint in its name.
Visual comparison
Here’s a colorful Confluence table that already appeared in a blog post:
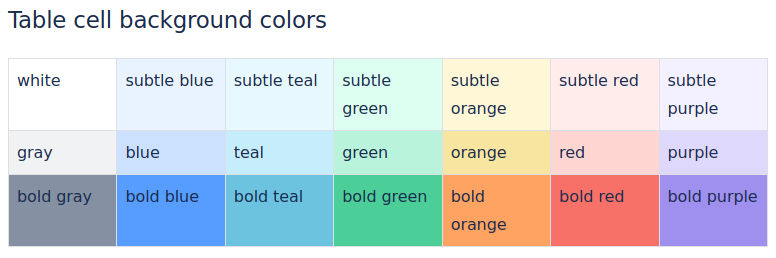
Table in Confluence
Here’s how that looks in SharePoint with the new setting enabled:
Table in SharePoint, now with colored cells
And here’s how the table would normally look, with the new setting disabled:
Table in SharePoint, new setting disabled
Another Confluence table that uses merged cells:

Table in Confluence
Here’s how that looks in SharePoint with the new setting enabled:
Table in SharePoint, now with merged cells
Here’s how the table would normally look, with the new setting disabled:
Table in SharePoint, new setting disabled
Note that in above image the presence and the direction of cell merging is hinted at by arrows.
Overall, real merged cells are a lot more pleasant to look at.
Wrap
In this blog post we looked at a way to create tables with colored and merged cells in SharePoint Online modern pages, by copying and pasting styled tables from Word.
We also looked at a new WikiTraccs setting that can leverages this behavior.
There is no documentation by Microsoft (that I know of) that describes this as an official feature and words of caution have been written.
If somebody can find official documentation by Microsoft that this is an actual feature that is officially supported, please let me know.
How much time will a Confluence to SharePoint migration take?
The migration time depends heavily on the source content in Confluence, and the network speed, both for downloads and uploads.
We’ll do some test migrations to have real-world data to look at.
Summary (TL;DR)
Here are the average migration times per page, taken from test migrations detailed further down this post:
- 07 seconds (~2h per 1000 pages) (note: few attachments)
- 11 seconds (~3h per 1000 pages)
- 12 seconds (~3h per 1000 pages)
- 12 seconds again
- 13 seconds (~4h per 1000 pages)
- 13 seconds again
- 15 seconds (~4h per 1000 pages)
- 20 seconds (~6h per 1000 pages)
- 35 seconds (~9h per 1000 pages) (note: lots of attachments)
Read further to get details.
⏱ Estimate your own timeline
Use the Migration Duration Estimator to calculate a first timeline with your own page count, attachments, links, and transfer speeds.How does the source content influence migration speed?
The following list shows migration activities that are always present and can take quite some time:
- creating a page in SharePoint and setting up the metadata around it
- uploading files to SharePoint Online (mainly on slow connections)
- downloading files from Confluence (mainly on slow connections)
Here are some activities that also take time, but are not always needed, depending on the source content:
- resolving Confluence links - WikiTraccs will check every link it finds to know where the link links to, to properly transform the link
- resolving @-mentions - this involves looking up user information, writing this to the user mapping table, and trying to find the user in SharePoint
- transforming Jira macros - this involves reaching out to Jira; Confluence’s Jira integration is rather slow
If you migrate pages with only text content and no attachments they’ll migrate in no time.
If you migrate pages with 500 attachments each, it might take minutes for each page to be migrated.
Using live migration metrics to get insights
Note
Those metrics are only available in Migrate content mode.With release v1.22.1, WikiTraccs introduced live metrics that show how long migrating pages take (those are also written to the log file). Those metrics also provide insights into which of the mentioned activities - downloading and uploading content, resolving links, etc. - happen, and how much time they take.
You can read more about those live metrics here: Live Progress Indicators.
Since the migration times depend on the source content, we need some source content to perform actual migrations, to get actual data to look at.
Thankfully, there are plenty of open Confluence sites available to run some measurements; some run by hobbyists, many by universities, some by non-profits and NGOs.
Testing migrations using open Confluence sites
We’ll pick some of those open Confluence sites, not based on the meaning of their content, but on the amount and type of their content. I’m not affiliated with any of those sites. They just provide a great way to test one thing or another.
Note: over time the accessibility of those sites will change. Some will close, some will move. The number of Confluence on-prem instances decreases, the number of Confluence cloud sites increases.
Note
“Open site” means a Confluence site on the internet that has anonymous access enabled, so that content is freely accessible by everyone visiting the site, and also indexed and discoverable by search engines like Google.Again: those sites are purely chosen by googling for site:atlassian.net and clicking through sites until finding some that have a decent amount of spaces and pages.
Migration machines used for test migrations
Test migrations were performed on the following migration machines:
“Mig VM”
An Azure VM with the following characteristics:
- Operating System: Windows 10
- Size: B2s
- vCPUs: 2
- RAM: 4 GB
- Max IOPS: 1280
- Cost per month: €32.80
- Download speed: 1200 Mbps
- Upload speed: 1800 Mbps
“Mig Laptop”
A laptop:
- Operating System: Debian Linux
- vCPUs: 6
- RAM: 40 GB
- Download speed: 93 Mbps
- Upload speed: 38 Mbps
Download and upload speed were determined using one of the many free internet sites that measure those values.
Confluence Cloud Site: University of Texas at Austin
The UT is providing us with an site that has over 300 spaces, many small, but two bigger ones.
Migration Metrics for Space 1
- Migration Machine: Mig VM
- Migrated number of pages: 801
- Migration duration: 92 minutes
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 410 pages:
Median time (IQR) : 4 s/item
Median time : 4 s/item
75th percentile (IQR): 7 s/item
75th percentile : 9 s/item
Mean time (IQR) : 5 s/item
Mean time : 8 s/item
Avg links transformed: 2/item
Have files : 22% of items
File count avg : 2.3 per item that has files
File size avg : 1649 KB/file
Download speed : ~485 KB/s
Upload speed : ~373 KB/s
File size sum down : 1299.6 MB
File size sum up : 1293.5 MB
Top activities were:
(SharePoint, Page, Content) : 28,52 min
(SharePoint, WikiTraccs, Prerequisites) : 14,98 min
(Confluence, Page, Link_Soft) : 14,69 min
There are only a few attachments in this space, only every fifth page has about 2 attachments. This is probably the reason why file upload and download are not in the top activities.
Most present are activities that require a lot of calls to APIs, like checking prerequisites, prepping the page, setting its content, and setting metadata for page and attachment folder.
In the end, looking at the overall migration duration and number of pages, the average migration duration was 7 seconds per page.
Migration Metrics for Space 2
- Migration Machine: Mig VM
- Migrated number of pages: 1233
- Migration duration: 12h 10m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 140 pages:
Median time (IQR) : 11 s/item
Median time : 13 s/item
75th percentile (IQR): 27 s/item
75th percentile : 31 s/item
Mean time (IQR) : 17 s/item
Mean time : 25 s/item
Avg links transformed: 15/item
Have files : 56% of items
File count avg : 13.6 per item that has files
File size avg : 1235 KB/file
Download speed : ~297 KB/s
Upload speed : ~218 KB/s
File size sum down : 425.6 MB
File size sum up : 427.5 MB
Top activities were:
(SharePoint, File, Content) : 17.19 min
(SharePoint, Page, Content) : 10.21 min
(Confluence, File, Content) : 9.86 min
Compared with the first space, pages in this space have a lot of attachments. Half of the pages have an average of 13 attachments, each about 1,5 MB in size. That’s why the download and upload activities take more time in this space. All page metrics that measure time are about triple of what they were for the first space.
Remember, those values are measured over a period of 60 minutes. Let’s look at how the values changed after 4 hours of migration, covering 89 page-like contents:
Median time (IQR) : 29 s/item
Median time : 29 s/item
75th percentile (IQR): 47 s/item
75th percentile : 50 s/item
Mean time (IQR) : 35 s/item
Mean time : 40 s/item
Avg links transformed: 3/item
Have files : 91% of items
File count avg : 19.6 per item that has files
File size avg : 499 KB/file
Download speed : ~495 KB/s
Upload speed : ~357 KB/s
File size sum down : 919.3 MB
File size sum up : 957.0 MB
Top activities were:
(SharePoint, File, Content) : 24.83 min
(Confluence, File, Content) : 14.17 min
(SharePoint, Page, Content) : 7.61 min
All times went up. The number of pages having attachments went from 56% to 91% - those file downloads and uploads take time.
In the end, looking at the overall migration duration and number of pages, the average migration duration was 35 seconds per page.
Confluence Cloud Site: Geocaching.com Wiki
This site had one space.
Migration Metrics for Space
- Migration Machine: Mig Laptop
- Migrated number of pages: 262 (whole site)
- Migration duration: 53 minutes
Metrics for all 262 pages:
Median time (IQR) : 5 s/item
Median time : 5 s/item
75th percentile (IQR): 12 s/item
75th percentile : 14 s/item
Mean time (IQR) : 8 s/item
Mean time : 12 s/item
Avg links transformed: 4/item
Have files : 35% of items
File count avg : 2.5 per item that has files
File size avg : 382 KB/file
Download speed : ~173 KB/s
Upload speed : ~96 KB/s
File size sum down : 234.7 MB
File size sum up : 234.7 MB
Top activities were:
(SharePoint, Page, Content) : 22.15 min
(Confluence, Page, Link_Soft) : 12.91 min
(Confluence, Page, Transformation_Macro_Other) : 12.12 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 12 seconds per page.
Confluence Cloud Site: Xilinx Wiki
This site had one space.
Migration Metrics for Space
- Migration Machine: Mig VM
- Migrated number of pages: 1284 (whole site)
- Migration duration: 7h 22m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 221 pages:
Median time (IQR) : 10 s/item
Median time : 10 s/item
75th percentile (IQR): 18 s/item
75th percentile : 21 s/item
Mean time (IQR) : 14 s/item
Mean time : 15 s/item
Avg links transformed: 7/item
Have files : 61% of items
File count avg : 6.7 per item that has files
File size avg : 1419 KB/file
Download speed : ~724 KB/s
Upload speed : ~434 KB/s
File size sum down : 1264.3 MB
File size sum up : 1264.3 MB
Top activities were:
(SharePoint, File, Content) : 22.25 min
(Confluence, Page, Transformation_Macro_Other) : 20.55 min
(SharePoint, Page, Content) : 15.97 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 20 seconds per page.
Confluence Cloud Site: Duke Universtiy
This site had 120 spaces.
Migration Metrics for whole Site
- Migration Machine: Mig Laptop
- Migrated Migrated number of pages: 3117 (whole site)
- Migration duration: 12h 46m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 330 pages:
Median time (IQR) : 5 s/item
Median time : 5 s/item
75th percentile (IQR): 11 s/item
75th percentile : 13 s/item
Mean time (IQR) : 8 s/item
Mean time : 10 s/item
Avg links transformed: 2/item
Have files : 43% of items
File count avg : 2.6 per item that has files
File size avg : 421 KB/file
Download speed : ~239 KB/s
Upload speed : ~104 KB/s
File size sum down : 463.5 MB
File size sum up : 463.5 MB
Top activities were:
(SharePoint, Page, Content) : 23.05 min
(SharePoint, File, Content) : 15.38 min
(SharePoint, WikiTraccs, Prerequisites) : 11.04 min
Let’s look at how the values changed after 4 hours of migration, covering 110 page-like contents:
Median time (IQR) : 14 s/item
Median time : 14 s/item
75th percentile (IQR): 59 s/item
75th percentile : 59 s/item
Mean time (IQR) : 32 s/item
Mean time : 32 s/item
Avg links transformed: 0/item
Have files : 65% of items
File count avg : 17.8 per item that has files
File size avg : 399 KB/file
Download speed : ~444 KB/s
Upload speed : ~212 KB/s
File size sum down : 567.1 MB
File size sum up : 587.2 MB
Top activities were:
(SharePoint, File, Content) : 35.10 min
(Confluence, File, Content) : 15.23 min
(SharePoint, Page, Content) : 10.87 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 15 seconds per page.
Confluence Cloud Site: Harvard University
This site had 46 spaces.
Migration Metrics for whole Site
- Migration Machine: Mig VM
- Migrated Migrated number of pages: 6647 (whole site)
- Migration duration: 20h 23m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 211 pages:
Median time (IQR) : 7 s/item
Median time : 9 s/item
75th percentile (IQR): 15 s/item
75th percentile : 17 s/item
Mean time (IQR) : 10 s/item
Mean time : 17 s/item
Avg links transformed: 6/item
Have files : 50% of items
File count avg : 4.2 per item that has files
File size avg : 822 KB/file
Download speed : ~371 KB/s
Upload speed : ~199 KB/s
File size sum down : 1200.9 MB
File size sum up : 1200.9 MB
Top activities were:
(SharePoint, Page, Content) : 14.74 min
(SharePoint, File, Content) : 13.92 min
(Confluence, Page, Link_Soft) : 10.44 min
Let’s look at how the values changed after 4 hours of migration, covering 325 page-like contents:
Median time (IQR) : 4 s/item
Median time : 4 s/item
75th percentile (IQR): 9 s/item
75th percentile : 11 s/item
Mean time (IQR) : 7 s/item
Mean time : 11 s/item
Avg links transformed: 2/item
Have files : 35% of items
File count avg : 2.6 per item that has files
File size avg : 558 KB/file
Download speed : ~165 KB/s
Upload speed : ~105 KB/s
File size sum down : 340.8 MB
File size sum up : 340.7 MB
Top activities were:
(SharePoint, Page, Content) : 22.18 min
(SharePoint, File, Content) : 12.34 min
(SharePoint, WikiTraccs, Prerequisites) : 11.77 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 11 seconds per page.
Confluence Cloud Site: Hyperledger Foundation
This site had 74 spaces.
Migration Metrics for whole Site
- Migration Machine: Mig VM
- Migrated Migrated number of pages: 9238 (whole site)
- Migration duration: 32h 40m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 390 pages:
Median time (IQR) : 7 s/item
Median time : 7 s/item
75th percentile (IQR): 9 s/item
75th percentile : 9 s/item
Mean time (IQR) : 7 s/item
Mean time : 9 s/item
Items per hour : 400-514 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 3/item
Have files : 62% of items
File count avg : 1.1 per item that has files
File size avg : 294 KB/file
Download speed : ~679 KB/s
Upload speed : ~94 KB/s
File size sum down : 1618.1 MB
File size sum up : 1619.3 MB
Top activities were:
(Confluence, Page, Link_Soft) : 53.22 min
(SharePoint, Page, Content) : 29.33 min
(Confluence, Page, Transformation_UserMention) : 17.99 min
Let’s look at how the values changed after 4 hours of migration, covering 239 page-like contents:
Median time (IQR) : 14 s/item
Median time : 14 s/item
75th percentile (IQR): 18 s/item
75th percentile : 18 s/item
Mean time (IQR) : 14 s/item
Mean time : 15 s/item
Items per hour : 200-257 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 4/item
Have files : 53% of items
File count avg : 1.6 per item that has files
File size avg : 370 KB/file
Download speed : ~102 KB/s
Upload speed : ~81 KB/s
File size sum down : 93.1 MB
File size sum up : 93.1 MB
Top activities were:
(SharePoint, Page, Content) : 24.94 min
(SharePoint, File, Content) : 13.86 min
(Confluence, Page, Link_Soft) : 13.01 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 13 seconds per page.
Confluence Cloud Site: logica.atlassian.net
This site had 19 spaces.
Migration Metrics for whole Site
- Migration Machine: Mig VM
- Migrated Migrated number of pages: 1494 (whole site)
- Migration duration: 5h 9m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 489 pages:
Median time (IQR) : 4 s/item
Median time : 4 s/item
75th percentile (IQR): 4 s/item
75th percentile : 6 s/item
Mean time (IQR) : 4 s/item
Mean time : 7 s/item
Items per hour : 900-900 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 1/item
Have files : 13% of items
File count avg : 1.5 per item that has files
File size avg : 372 KB/file
Download speed : ~127 KB/s
Upload speed : ~99 KB/s
File size sum down : 294.0 MB
File size sum up : 294.2 MB
Top activities were:
(SharePoint, Page, Content) : 30.43 min
(Confluence, Page, Link_Soft) : 17.85 min
(SharePoint, WikiTraccs, Prerequisites) : 17.11 min
Let’s look at how the values changed after 4 hours of migration, covering 255 page-like contents:
Median time (IQR) : 4 s/item
Median time : 4 s/item
75th percentile (IQR): 7 s/item
75th percentile : 11 s/item
Mean time (IQR) : 6 s/item
Mean time : 14 s/item
Items per hour : 514-600 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 1/item
Have files : 30% of items
File count avg : 2.9 per item that has files
File size avg : 2069 KB/file
Download speed : ~705 KB/s
Upload speed : ~451 KB/s
File size sum down : 13192.5 MB
File size sum up : 13828.6 MB
Top activities were:
(SharePoint, Page, Content) : 14.34 min
(SharePoint, WikiTraccs, Prerequisites) : 8.29 min
(SharePoint, File, Content) : 7.54 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 12 seconds per page.
Confluence Cloud Site: vzvz.atlassian.net
This site had 26 spaces.
Migration Metrics for whole Site
- Migration Machine: Mig VM
- Migrated Migrated number of pages: 8541 (whole site)
- Migration duration: 31h 45m
Here are the metrics (as logged into the common log files) 1 hour into the migration, based on data of this hour, covering 369 pages:
Median time (IQR) : 6 s/item
Median time : 6 s/item
75th percentile (IQR): 13 s/item
75th percentile : 13 s/item
Mean time (IQR) : 8 s/item
Mean time : 9 s/item
Items per hour : 276-450 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 3/item
Have files : 47% of items
File count avg : 3.4 per item that has files
File size avg : 271 KB/file
Download speed : ~219 KB/s
Upload speed : ~103 KB/s
File size sum down : 173.9 MB
File size sum up : 174.7 MB
Top activities were:
(SharePoint, Page, Content) : 27.74 min
(Confluence, Page, Link_Soft) : 22.21 min
(SharePoint, File, Content) : 20.38 min
Let’s look at how the values changed after 4 hours of migration, covering 255 page-like contents:
Median time (IQR) : 10 s/item
Median time : 10 s/item
75th percentile (IQR): 13 s/item
75th percentile : 15 s/item
Mean time (IQR) : 11 s/item
Mean time : 13 s/item
Items per hour : 276-327 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 1/item
Have files : 26% of items
File count avg : 1.9 per item that has files
File size avg : 533 KB/file
Download speed : ~134 KB/s
Upload speed : ~84 KB/s
File size sum down : 68.5 MB
File size sum up : 67.4 MB
Top activities were:
(SharePoint, Page, Content) : 30.62 min
(SharePoint, WikiTraccs, Prerequisites) : 12.94 min
(Confluence, Page, Link_Soft) : 11.94 min
In the end, looking at the overall migration duration and number of pages, the average migration duration was 13 seconds per page.
Wrap
In this blog post we looked at some metrics from real test migrations to get a feeling about how long a migration can take.
Live metrics can only predict the future if we assume that pages are comparable in their characteristics (mainly number of attachments), which might not be the case. Thus, the metrics will change over the course of the migration as metrics are always calculated based on data from the last 60 minutes.
So far it seems that the metrics Mean Time (IQR) and 75th percentile (IQR) could be predictors for the overall migration time within a space.
Over time, I’ll add more samples to this blog post and might also update the values, as the metrics calculation evolves.
Confluence Quirks
When speaking about page migrations failing, I mean the things on this page. All those tripped up page migration at some point, those are now known and worked around by WikiTraccs (where possible).
This list is more like a “fun” documentation of things, I never thought could happen.
- page with empty title; how is that even possible?
- duplicate attachments:

- attachment name that looks like a path; can’t be downloaded:

- attachments that differ only by Unicode Normalization Form; names look the same, but are differently encoded; depending on the application that handles those files, they are treated as duplicate - or not
- attachments that are listed in the attachment list, but are missing when trying to download them
- attachments that are listed in the attachment list, but give an error when trying to download them:

- note that in above case the image preview for this image was missing as well, but clicking this “broken image” placeholder did show the image:

- note that in above case the image preview for this image was missing as well, but clicking this “broken image” placeholder did show the image:
- attachments names with special characters that are valid on Linux, but not on Windows
- attachment file sizes reported by Confluence are wrong
This list will be extended as more quirks are uncovered.
Good Practices for your Confluence to SharePoint Migration
Often I get asked about best practices around Confluence to SharePoint migrations and WikiTraccs.
Please note that I am not directly involved in migration projects. If there is a perfect project where the client doesn’t need my help because WikiTraccs does its job, I’ll never hear from them.
What I hear about are issues. Issues with tooling, but also non-technical issues.
Recommendations
Here’s a collection of things I recommend.
Prepare users for SharePoint
I often hear phrases like “Leadership has decided” to proceed with moving content to SharePoint. However, some users may not have had any prior experience with SharePoint. Familiarize them with SharePoint or, at the very least, help them anticipate that SharePoint will be different from Confluence.
Test the migration
Perform a test migration using WikiTraccs. Evaluate the results. Purchase only, if the results match your expectations. Depending on how well your stakeholders know SharePoint, expectations vary wildly.
Expect layout changes. SharePoint is no Confluence. SharePoint doesn’t offer the same formatting and layouting features as Confluence. You’ll see that for example with images, where SharePoint is not capable of showing them side by side 😔.
Prepare for macros being gone
Most of the Confluence macros don’t exist in SharePoint. Identify key use cases that exist in Confluence and rely on specific macros or metadata. Manually try to rebuild those cases in SharePoint. WikiTraccs might help you with that, but you will also have to think about using extensions like PnP Search web parts. You’ll probably also use services outside SharePoint to re-implement those use cases, like the Power Platform, Loop, Teams, or others.
Prepare your service desk for hypercare questions
After the migration users will ask questions. Provide them with a channel to get those questions answered.
Example questions:
- Why does the table of contents doesn’t update in SharePoint?
- Answer: because the list of links is static and the table of contents macro is gone.
- Why are child pages not showing up on the page?
- Answer: because the children macro is gone.
Don’t do a permission migration
Confluence and SharePoint behave differently when it comes to permissions. Confluence can have page hierarchies. In Confluence, you can restrict pages to a more narrow circle of users with each hierarchy level. In SharePoint, there is just one level. Multiple levels of Confluence page restrictions need to be combined to just one SharePoint page.
For a more complex hierarchy of restrictions in Confluence it is nearly impossible to map that 1:1 to SharePoint.
That being said, WikiTraccs supports migrating permissions, to the extend it is possible. But a permission migration might give you a headache.
Archive older content to one site
Identify old Confluence content to archive and migrate this content to one SharePoint archival site.
Skip personal Confluence spaces
Prepare users to manually move content they need from their personal spaces.
Don’t change networking infrastructure during the migration
One client upgraded Confluence to TLS 1.3 during the migration. This caused issues in combination with Windows 10. Everything can be solved, but this can cause interruptions that should be prevented during a migration.
Plan all target sites before the migration
You should know which Confluence content will be migrated to which target SharePoint site. Enter target site URLs in the Space Inventory list. This is required for the link transformation to be successful throughout the migration as WikiTraccs will look up those sites when transforming cross-space links.
Note that WikiTraccs doesn’t create those sites, you create them, or choose from existing ones.
Check the WikiTraccs settings
The blue WikiTraccs window has a menu bar with a Settings option. Click that and click through the tabs in the Settings window to familiarize yourself with the settings. Some choices are to be made like whether blogposts should be migrated or not.
Use migration waves for larger space counts
You can define migration waves. If you have hundreds of spaces, it might be beneficial to not choose all at once for migration, but to give them wave numbers and migrate each wave separately, or even (some) in parallel.
Bring the page tree to SharePoint Online
The number one missing productivity feature in SharePoint with regard to pages is the page tree. WikiPakk finally brings the page tree to SharePoint.
Repeat migration runs
During longer migration runs there can be connection issues that prevent single pages to migrate. Re-run the migration to get those pages over as well.
With WikiTraccs, you can re-run the migration multiple times. Before each run, WikiTraccs checks which pages are missing in SharePoint and only migrates those that are missing. This proved beneficial especially in environments with an unstable internet connection.
Only when a migration run doesn’t seem to migrate any more pages you go ahead and look at the progress log files to check the final result.
Check the playbook
The Migration Playbook provides guidance about configuring WikiTraccs and evaluating migration results.
Additional topics
Some additional topics that often come up.
How many SharePoint sites do we need?
I cannot answer that as this is up to your information architecture.
What I often see is a 1:1 relationship between spaces and sites. So, all pages of a Confluence space are migrated to a target SharePoint site.
How long will the migration take?
This is hard to answer as it depends on a number of factors. The FAQ has some thoughts about that: How much time does it take to migrate?
Quick planning shortcut
Use the Migration Duration Estimator to estimate migration times.Confluence Cloud Specialties
Note
This post is only relevant for Confluence Cloud.To migrate content from Confluence Cloud to SharePoint Online, WikiTraccs needs to access content in Confluence Cloud to download it. Content means page content, attachments, metadata, macro details, new content types like whiteboards, and more.
There are two ways to get content from Confluence Cloud: using a programming interface that is officially supported by Atlassian, and using internal interfaces.
Ideally, only officially supported interfaces are used; for Confluence Cloud, that would be the REST API.
Since this post exists, you might already guess where this is leading. Not every content is accessible using official ways.
Content that can only be migrated via workarounds
There are Confluence elements which cannot be accessed using officially documented interfaces (as the Confluence Cloud REST API would be one).
WikiTraccs tries to work around those limitations.
Here’s the list of (currently known) elements that need a workaround to be migrated:
- Jira issue lists
- Whiteboards
Let’s look at each of those.
Jira issue lists
WikiTraccs takes static snapshots of Jira issue lists so that the migrated SharePoint page contains a static issue table as well.
In Confluence Cloud the endpoint to do that conversion is not officially accessible (WikiTraccs issue #123).
WikiTraccs works around this limitation by using the same endpoint that Confluence uses when you work in the browser.
Prerequisite: This workaround is only available to WikiTraccs when using Interactive Login. It is not supported when using API tokens or Anonymous access.
Whiteboards
Read this blog post to learn how WikiTraccs works around the missing Confluence Cloud export functionality at the ramifications: Migrating Confluence Cloud Whiteboards
Closing notes
WikiTraccs uses workarounds to migrate content that otherwise is not accessible to apps via official Atlassian interfaces.
Those workarounds are based on internal interfaces and they might break at any time since Atlassian is not required to announce changes. So, it might happen that a workaround stops working temporarily, might require a WikiTraccs update, or might stop working at all. There is nothing that can be done about that, apart from lobbying for Atlassian to provide proper interfaces for exporting all content.
WikiTraccs uses workarounds exclusively for content that otherwise would not be accessible at all and would thus be missing in migrated pages.
WikiTraccs switches to Confluence Cloud v2 REST API
Note
The information in this post is relevant for Confluence Cloud only. There are no changes for Confluence on-premises.Background
Confluence Cloud so far provided programming interfaces (APIs) that allowed applications like WikiTraccs to treat it as no different that Confluence Server or Confluence Data Center.
Those days are over.
Atlassian is removing critical parts of the v1 REST API (that provided access compatible with the on-prem Confluence versions). Instead, applications are now forced to use the v2 REST API, starting December 2, 2024.
Note
Atlassian extended the deadline to March 31, 2025, shortly after writing this post.Here is the announcement by Atlassian:

What does this mean for users of WikiTraccs?
Ideally there should be no noticable difference. But the v2 API, in my view, is a step back in terms of developer convenience. More work has to be done to retrieve the same data as before.
From now on it takes both more time and more transmitted data to get the same work done as before.
WikiTraccs Update Required by December 2, 2024
Starting with version v1.21.3 WikiTraccs uses the new v2 REST API instead of deprecated v1 endpoints when talking to Confluence Cloud.
Starting December 2, 2024, using this or a newer WikiTraccs version is mandatory for Confluence Cloud to SharePoint migrations (unless Atlassian extends the deadline).
Until December 2, 2024, switching back to v1 API is possible. You can use the Force use of v1 REST API setting to switch back to v1:
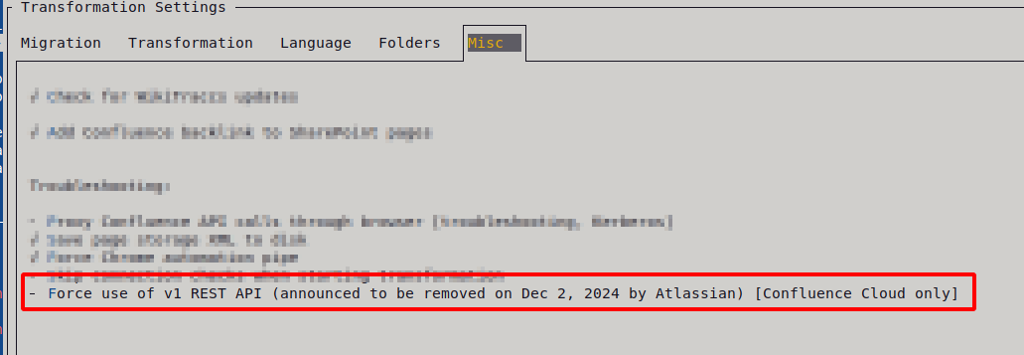
If there are unforseeable issues, this setting can be used to check if those are caused by the switch to v2. It shouldn’t be necessary.
If you find issues, use any of the support channels to get in touch.
Migrated SharePoint Page Names Explained
SharePoint pages migrated by WikiTraccs all follow the same naming scheme. We’ll take a look at how those names look and why this scheme is applied.
How WikiTraccs names migrated pages
In contrast to Confluence, SharePoint pages are files and those files have a file name and a title. When migrating a Confluence page to SharePoint, WikiTraccs has to set both the file name and the title.
We’ll focus on the file name (also referred to as page name or just name).
Note
The naming scheme is only applied to the file name of SharePoint pages, NOT the page title. The page title (that is visible to the end user in most places) can have arbitrary values and is set to the original Confluence page title by WikiTraccs.The SharePoint page file name will be derived from
- the Confluence space key (soon: space alias)
- the Confluence page title, and
- the Confluence page ID.
For a space key of HR, a title of Onboarding, and a page ID of 123456789, the SharePoint page name will be HR-Onboarding-123456789.aspx.
This scheme WikiTraccs applies is fixed and cannot be changed.
Why WikiTraccs names pages like it does
The naming scheme presented in the previous section is applied so that WikiTraccs can create SharePoint links between pages, without having to actually migrate all pages that link to each other. It can infer page names from page metadata.
An example of two pages and a link
Let’s look at an example of two pages (space key, page title, page ID):
- HR, Onboarding, 123456789
- IT, Welcome Package, 987654321
The HR Onboarding page links to the IT Welcome Package page.
Now you task WikiTraccs to migrate all Confluence pages of space HR to SharePoint.
When migrating the HR Onboarding page, WikiTraccs needs to transform the (Confluence) link to the IT Welcome Package page to a SharePoint link.
SharePoint links in general
In general, SharePoint page links look like https://yourcompany.sharepoint.com/sites/<SITENAME>/SitePages/<PAGENAME>.
For each link to a Confluence page, attachment, or space, WikiTraccs needs to create the corresponding SharePoint link.
So, WikiTraccs has to figure out the SITENAME and PAGENAME parts of the each SharePoint link it creates.
WikiTraccs creates the SharePoint link
For the PAGENAME part of the SharePoint link, WikiTraccs applies the naming scheme that is the focus of this post. It knows that the IT Welcome Package page, once migrated, will get the page name IT-Welcome Package-987654321.aspx.
The SITENAME part of the link is looked up in the Space Inventory.
Having both PAGENAME and SITENAME, the final SharePoint link might look like this:
https://yourcompany.sharepoint.com/sites/ITS/SitePages/IT-Welcome Package-987654321.aspx
How to name pages differently?
Currently there is no way to change the SharePoint page file names that WikiTraccs creates during the migration as it relies on those names to creates links between pages.
Can I rename pages later?
After finishing all migration tasks, you might choose to rename pages via PowerShell. Since I did not conduct large-scale tests in this direction, I cannot say how well SharePoint handles renamed pages and especially linking to those renamed pages from other pages and web parts.
One sample of a working rename operation can be found in the WikiTraccs discussions.
Wrap
In this post we looked at how SharePoint pages are being named by WikiTraccs and how the naming scheme looks. We also looked into how the naming helps to create links between pages.
How to migrate only some pages?
Note
When talking about pages, this also means blog posts and the new cloud content types like whiteboards. A more common term would be content, but that does sound a bit generic and would also cover attachments. So let’s keep it at pages where it fits.With WikiTraccs, selecting pages for migration is always done in the Confluence Space Inventory list (short: space inventory).
The space inventory contains source selectors that tell WikiTraccs which pages to migrate.
In this blog post we’ll look at one specific source selector type that allows to select single pages for migration: the Content ID selector.
Note
Learn more about all available content selectors here: Confluence Space Inventory / Selectors.How to tell WikiTraccs which pages to migrate, by content ID
Everything in Confluence - pages, blog posts, attachments, comments, you name it - has an ID: the content ID.
For now, let’s assume you already have a list of content IDs you want to migrate (We’ll look at how to get those IDs in the next section). You would mark them for migration by creating a new source selector in the space inventory, like this:
- open the space inventory (note: this is a SharePoint list and can be used as such)
- add a new item
- enter the following data for the newly created item:
| Field | Sample Value | Remarks |
|---|---|---|
| Title | notused | the title is ignored, but is a mandatory field; enter anything here |
| WT_In_SiteId | https://CHANGEME.atlassian.net/wiki | enter your Confluence base URL; look at the other items in the space inventory and copy it from there |
| WT_Setting_RequestTransformation | Yes | mark the selector for migration |
| WT_Setting_TargetSiteRootUrl | https://contoso.sharepoint.com/sites/target | enter the target SharePoint site here |
| WT_Setting_ContentSelectorValue | 123456789;#page,987654321;#blogpost | this list of ID-type combinations tells WikiTraccs what to migrate; each value consists of the content ID (like 123456789) followed by the content type (page, blogpost, whiteboard, database, …), separated by ;# (like so: ID;#TYPE); multiple values are separated by comma (like so: ID;#TYPE,ID;#TYPE,ID;#TYPE) |
- the other fields are optional and can be left blank
When starting the next migration, WikiTraccs should process this selector and migrate the pages.
How to get content IDs and types?
Depending on your migration team’s level of access there are different ways to get content IDs and content types.
How to manually look up the content ID and type for a page
Any user that can view Confluence pages in the browser can do this.
Confluence Server and Data Center
In the browser, open the Confluence page you need the content ID for.
Open the Page Information for that page:
The browser will now show the page ID in its address bar; here it is 10387457:

The Page Information view and address bar will look similar for pages and blog posts. You can infer that you are looking at a blog post by looking at the breadcrumb, which contains a date:

Note: The Page Information view is also available in Confluence Cloud.
Confluence Cloud
In Confluence Cloud the content ID and type are always shown in the address bar of your browser when navigating pages.
Having open a page the address bar will look like this:
https://contoso.atlassian.net/wiki/spaces/SPACE/pages/123456789/Page+Title
The /pages/ part tells you that this is a page, and its ID is 123456789.
For a blog post this looks similar:
https://contoso.atlassian.net/wiki/spaces/SPACE/blog/2024/10/24/987654321/Blog+Title
The /blog/ part tells you that this is a blog post, and its ID is 987654321.
This works similarly for other content types like whiteboards.
How to use a space backup to look up content IDs and types
As Confluence system administrator, you can create a space backup. You’ll see content IDs and types in this backup.

Each space backup is a zip file that contains an entities.xml file.
You’ll find information about all pages (of the backed-up space) in this xml file:

The same for blog posts:
How to use SQL queries to look up content IDs and types (on-premises only)
This option is the most flexible one, but can only be applied with administrative access to the database server backing Confluence.
Have a look at this recipe on how to use SQL to get a list of pages for a space: Getting a list of pages per space [on-premises].
Use cases for the Content ID selector
The Content ID selector has several benefits:
- it allows selecting content to migrate based on criteria you define
- it works whether or not the migration account is included in page restrictions; this is a difference to the CQL selector
- it can work around the issue that some Confluence instances show with space selectors: Confluence might misreport space contents
The drawback of course is that you manually have to assemble the list of IDs. Using the space selector to migrate whole spaces is much more convenient.
Wrap
In this post we created a Content ID selector to migrate two selected pages. We also learned how to get the content IDs for pages. Depending on the permissions of the migration team, there are different ways to do that.
Confluence vs. SharePoint - Part 1: Overall structure
Note
When talking about Confluence pages, blog posts are also meant, because they are basically pages with another name. When looking at the cloud there is more than pages and blog posts but let’s keep things simple by looking at what is at the core of Confluence: pages.Confluence
When looking at a Confluence page the basic structure looks like this:
A Confluence page
The following parts make up a Confluence page:
- Page Content, including
- Versions
- Inline Comments
- Inline Tasks
- @-Mentions
- Macros
- Attachments, including
- Versions
- Comments
- Footer Comments
- like page content…
- Restrictions
- Metadata, including
- Title
- Creator, Author
- Creation Date, Modification Date
- Likes
- Labels
Each page lives in a Confluence space where each space can contain hundreds, thousands, or even tens of thousands of pages.
Pages within a space usually form a hierarchy. This means there are parent pages, child pages, and leaves, like a tree:
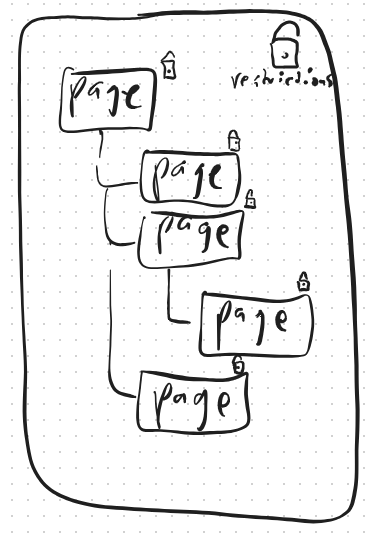
A Confluence space contains many pages
Access to pages can be restricted at each level of the tree, which also affects all child pages. If a user is not allowed to access a parent page, they cannot access any of the child pages as well.
Confluence can have many spaces. A typical instance has dozens or a couple of hundred space, but there’s also instances with a couple of thousand spaces.
The following parts make up a Confluence space:
- Pages
- Metadata
- Title
- Description
- Archived or not
- Restrictions
Spaces have no hierarchy:
Confluence organizes content in spaces
SharePoint
While Confluence consists of spaces, SharePoint consists of sites, which serve a similar purpose.
The following parts make up a SharePoint site:
- Lists (note: those are like a table)
- List Items
- Item Data in List Columns
- List Item Permissions
- List Permissions
- List Items
- Document Libraries (note: those are like a drive or folder)
- Files
- File Metadata in List Columns
- File Permissions
- Document Library Permissions
- Files
- Site Permissions
- Apps
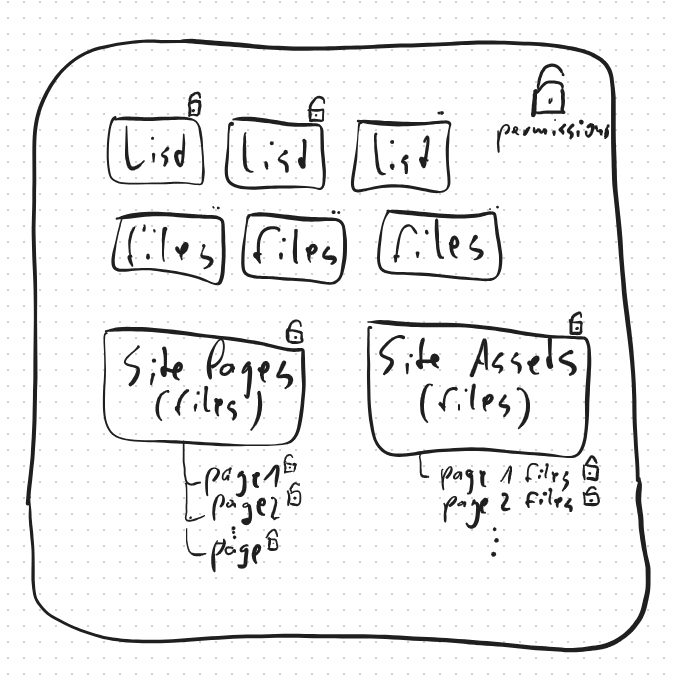
A SharePoint site
Some SharePoint document libraries are “special” in that they serve a specific purpose. With regard to pages, there’s the Site Pages library and the Site Assets library.
All SharePoint pages are stored in the Site Pages library. For SharePoint, pages are just files with some metadata. There is no page hierarchy and all pages are stored flat in the Site Pages library.
Page attachments are stored in the Site Assets library, in a folder that belongs to the page. Each page has its own folder.
When setting the permissions for a SharePoint page, SharePoint takes care of setting those permissions on the page’s folder as well.
How does it map?
Often Confluence spaces are compared to SharePoint sites.
I’d say this is a fair comparison, when focusing on wiki functionality.
Confluence spaces and SharePoint sites have some things in common. Both:
- have a title and description
- have owners
- can be access restricted to users and groups
- contain wiki pages and files
- have their content indexed by search
- have no strict technical hierarchy (bear with me on this one)
- have their permissions inherited by pages, but pages can also have their own
Confluence pages and SharePoint pages also have some things in common. Both:
- support the basic text formatting capabilities, like bold, headings, tables, images, etc.
- can be created from templates
- can have sections to structure page content
- can contain “blocks of functionality” - macros in Confluence, web parts in SharePoint
Here are the areas where Confluence and SharePoint differ:
| Confluence | SharePoint Online |
|---|---|
| pages form a hierarchy (with parent and child pages) | pages are flat, without a hierarchy |
| page breadcrumb navigation above pages | no page breadcrumb navigation |
| pages have attachments | pages have associated files in a special folder (we can make it look like attachments using a web part) |
| attachments (files) are bound to pages | files are stored in document libraries and linked to by pages |
| pages seem a bit better suited for documenting knowledge | pages seem a bit too much focused on presenting content nicely |
| macros can be nested | web parts cannot be nested |
| page restrictions have a hierarchy | item level permissions for pages have no hierarchy |
| rich app marketplace | marketplaces are not Microsoft’s strength |
| pages support @-mentioning other users | no @-mention support on pages |
| comments under pages with rich formatting, deeply nested | plain text comments under pages, 2 levels |
| inline comments on pages | no inline comments |
| inline tasks on pages | no inline tasks |
| integration with Jira | no integration with Jira |
| pages can easily be moved to other Confluence spaces (due to their self-contained nature) | pages cannot easily be moved to other SharePoint sites (at least not without breaking links or attached metadata) |
Confluence Cloud introduces some new restrictions compared to Confluence Server and Data Center, for example with regard to formatting content and nesting macros.
Confluence Link Types Explained
Migration tools like WikiTraccs needs to take care of Confluence links, because otherwise those are broken after a migration.
WikiTraccs will translate links within Confluence to proper SharePoint links. This includes page links, space links, and attachment links.
There is one challenge for migration tools when analyzing Confluence links and that is properly detecting both the two link types (soft links and hard links), and the different hard link variations.
What’s the difference between soft links and hard links?
I get that asked quite a lot. From an end user perspective the difference normally is not visible.
Here is an example of one soft link and one hard link, both linking to another Confluence page, as seen by an end user:
Can you spot the difference?
The difference can only be seen when looking at the page’s storage format, which looks like this:
<ac:link>
<ri:page ri:space-key="linktarget" ri:content-title="Get the most out of your team space"
ri:version-at-save="1" />
<ac:link-body>Get the most out of your team space</ac:link-body>
</ac:link>
<a
href="//wikitransformationproject.atlassian.net/wiki/spaces/linktarget/pages/60162329/Get+the+most+out+of+your+team+space">Get
the most out of your team space
</a>
This is how tools like WikiTraccs “see” the page when migrating it to SharePoint Online, or processing it in any other way.
The first link - a soft link - is represented as ac:link element that has metadata attached that allows WikiTraccs to look up information about this page.
The soft link contains readily available metadata, like the target space key (linktarget) and the title of the page (Get the most out of your team space). This is easy to handle for a tool like WikiTraccs. And most importantly, Confluence is able to keep this link up-to-date even if the target page changes.
The second link - a hard link - is a plain HTML link. It also points to the target page, but uses the absolute page address to do so.
The hard link doesn’t contain easily accessible page metadata. If you look closely you’ll see information like the space key, page ID, and so on; those certainly help, but there are many variations of those links, and we look at those further down. Confluence will not keep hard links up-to-date, so, if the target page changes, the link might be broken.
Note
Note that both soft and hard links are HTML elements, <a> and ac:link respectively.
A piece of text that looks like a link, but is neither <a>, nor <ac:link>, is not a hard link. It’s just text content that happens to look like a link. WikiTraccs won’t touch those as they might be part of some documentation and transforming them would introduce errors.
How are hard links created?
Let’s create one.
Ideally, there shouldn’t be hard links at all. When pasting a link onto a Confluence page, Confluence analyzes the link, detects the content it links to, and creates a proper soft link.
Nevertheless, hard links are often present in more complex content that has been copy and pasted into pages. Confluence’s hard link conversion does not always kick in.
Here’s a sample of how to fool the hard link detection and create a soft link and a hard link:
Above animation shows the following:
- we copy a link to a Confluence Cloud page to the clipboard
- we paste the link as plain text
- Confluence recognizes that this is a hard link and converts it to a soft link
- we change the settings of that soft link to look like a regular link
- we paste the link a second time
- we edit the second link to remove the
https:part; the result is still a proper and valid hard link, but it fools Confluence’s logic and it leaves the hard link in place - we save the page
The result is a page containing one soft link and one hard link.
How is it relevant if links are hard links or soft links?
It is relevant if you migrate content from one Confluence environment into another environment.
So, it is relevant for those use cases:
- Confluence Cloud site to site migrations
- Confluence Data Center to Confluence Cloud migrations
- Confluence to SharePoint Online migrations
- …
In all those cases, links between migrated pages will be broken, as well as links from external systems, like Jira descriptions and comments.
To fix those broken links, you need to:
- identify the links
- modify the links to point to the new location (or redirect)
Knowing that hard links and soft links exist is crucial for identifying the links in the first place.
Ideally, migration tools cover that, so you don’t have to care. WikiTraccs covers this.
What hard link variations are there?
We used a very simple hard link example so far (from Confluence Cloud):
wiki/spaces/linktarget/pages/60162329/Get+the+most+out+of+your+team+space
This link contains lots of metadata to look up the target content:
- content type (page)
- content ID (60162329)
- space key or alias (linktarget)
Here’s a list of other hard link variations:
wiki/display/Test(space link)wiki/spaces/Test(space link, cloud)wiki/pages/viewpage.action?pageId=10162329(page link)wiki/pages/viewpage.action?pageId=10162329&pageVersion=1(link to page version)wiki/x/xYBtAQ(tiny page link)wiki/display/Test/news(page link)wiki/spaces/Test/blog/2024/10/24/181542831/news(blog post link, cloud)wiki/spaces/Test/blog/181542831(blog post link, cloud)wiki/spaces/Test/pages/edit-v2/2123259301(page edit link, cloud)wiki/pages/viewpageattachments.action?pageId=60162247&preview=/60162247/174891441/image.png(attachment view link)wiki/download/attachments/10162247/image.png(attachment download link)wiki/spaces/Test/overview?homepageId=3020326337(page link)
Wrap
In this post we learned about soft link and hard links, and looked at different hard link variations.
When moving content from one Confluence environment to another environment (Confluence, SharePoint Online, …) links to pages, attachments, and spaces will break. Those links need to be taken care of, either by tools like WikiTraccs, or proxy solutions that recognize those links and redirect to the new location.
Mapping user accounts from Confluence to SharePoint
In this blog post we’ll create a Confluence page, look at author and editor, migrate the page, configure user mappings, look at the resulting SharePoint page, and update the page’s metadata - to demonstrate how to map users from Confluence to SharePoint.
Video walkthrough
Prefer to watch? The same flow is shown end to end in the Migrating Page Author and Editor to SharePoint video.We start with at a single Confluence source page.
Confluence Source Page
This Confluence page was created by Admin, and last edited by Parzival.
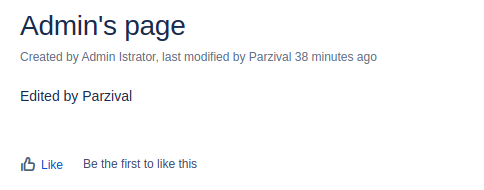
Here are those users in the Confluence administration:

Those users are local Confluence users, so not synchronized with Entra ID or other external directories.
However, note that the email address of Parzival corresponds to the email address of their Entra ID user. We’ll come back to that fact at a later point.
Migrating the Source Page to SharePoint
We now migrate the page to SharePoint.
When migrating pages, WikiTraccs looks at each page and “collects” user accounts from metadata fields and page restrictions.
Information about those user accounts will be stored in the Confluence User and Group Mapping (WikiTraccs) table, in the WikiTraccs site in SharePoint:

This list contains information like:
- Principal Type (user or group)
- Display Name
- Internal Name
- Key
- Email Address (note: only if one could be gotten)
- Principal Source (note: the source is either onprem for Confluence Server and Data Center, or cloud for Confluence Cloud; it does not refer to specific user directories or their location)
The column WT_Setting_MapForDataAndMentions is where the corresponding Entra ID account has to be entered.
Filling in the WT_Setting_MapForDataAndMentions column is a manual task, but can also be automated via PowerShell. Clients also had success filling that via Excel.
There is an automapping feature built into WikiTraccs, though. WikiTraccs tries to find a matching Entra ID account based on the Confluence account’s email address.
That is why (in above screenshot) the mapping for Parzival is already filled in; this account has the same email address in Confluence and Entra ID.
For all other accounts the mapping has to be filled in manually (by you).
Looking at the Migration Result
What we’ve got so far is:
- one page migrated from Confluence to SharePoint
- the page author in Confluence is Admin, page editor is Parzival
- the user mapping for Parzival has been automapped by WikiTraccs in the Confluence User and Group Mapping (WikiTraccs) table
- the user mapping for Admin is yet to be done
- the migration account used to log in to SharePoint was WikiTraccs
The metadata of the resulting SharePoint page will look like this:
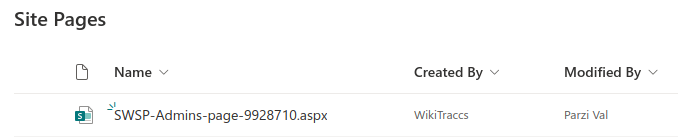
The creator of the SharePoint page is the Entra ID account WikiTraccs, not Admin. That is because there is no mapping configured for Admin, yet. So, the creator is set to the account doing the migration.
The editor of the SharePoint page is set to Parzi Val, which is the Entra ID account that matches (via email address) the Confluence account Parzival.
We now want to update the mapping for Admin.
Updating Mappings, Updating Pages
So far everything is going as planned.
We migrated some content and got a mapping to do.
Let’s configure the mapping for the Confluence Admin account which we map to the Heinrich Entra ID account:

But how to update the SharePoint page?
WikiTraccs has an update mode built-in for this specific case. In the blue WikiTraccs window, choose it in the Settings dialog:
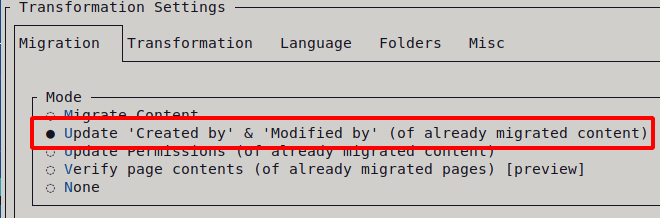
Update mode that updates page metadata based on configured account mappings
Leave all other settings in place and start the migration again.
WikiTraccs will now run over all migrated pages where a mapping was missing and update the page metadata.
How does WikiTraccs know where a mapping was missing? Those pages have been marked via the Check Principal Mapping column, in the Site Pages library:
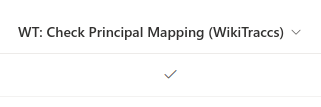
Where to find the Check Principal Mapping column?
Open your target SharePoint site in a browser. Click the Settings cog wheel in the upper right corner, then click Site Contents:
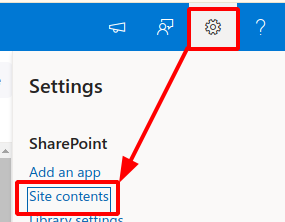
A list of the site’s lists and document libraries opens. It contains the Site Pages document library, where all pages are stored.
Click Site Pages (or the translated version like Websiteseiten) to open the library.
The Site Pages library default view does not show the Check Principal Mapping column, yet. Let’s show it.
First, switch to the Recent Pages (WikiTraccs) view:
Now, in the header row of the document library, click + Add column, then Show or hide columns, then find and check the WT: Check Principal Mapping (WikiTraccs) column:

Click Apply to save and close. The column is now visible and can be used.
After successfully updating author and editor metadata of a page (and only then), WikiTraccs removes this check mark. (Note: If you ever want to force an update of author and editor, set the check mark again before running the migration in update mode.)
After WikiTraccs is finished with the update mode run the SharePoint page should now look like this:
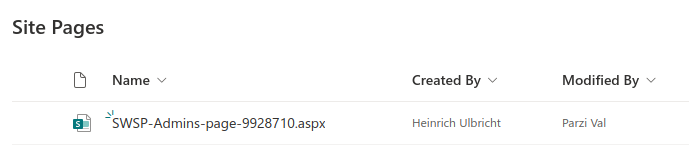
Creator and author are properly set to what was configured via the Confluence User and Group Mapping (WikiTraccs) table.
Confluence Authentication Overview
When starting a Confluence to SharePoint migration with WikiTraccs, you need to authenticate with Confluence so that WikiTraccs can access content.
You’ll need a Confluence user account for the migration
You’ll need a Confluence user account to log in with (“migration account”). WikiTraccs’ access to Confluence happens as this user.
WikiTraccs does not support “application permissions” where it would access Confluence as “itself”. WikiTraccs will always access Confluence in the context of a user account.
Anonymous access

There is one exception to the rule that you always need to use a migration account, and that is a Confluence instance with anonymous access enabled.
Anonymous access is good for testing or demo purposes. The quick start tutorial also uses that with a publicly available Confluence instance.
Anonymous access is not recommended for production migrations as certain metadata cannot be retrieved, like information about users (name, email address) and permission configuration.
Interactive login

Interactive Login is the easiest and most compatible authentication type.
WikiTraccs opens a browser window that you’ll use to log in to Confluence with the migration account. WikiTraccs takes over the user session and all requests to Confluence will be made in the context of the migration user account.
Here is more information: Cookie-based authentication / Interactive login.
The session cookies that WikiTraccs uses to take over the user session are:
- JSESSIONID
- seraph.confluence
- tenant.session.token (Confluence Cloud)
- _shibsession* (Shibboleth identity provider)
In case your identity provider needs additional cookies to identify a logged in user, click the Advanced Settings button and enter those cookie names:
If there are issues with interactive login, like WikiTraccs not being able to start a browser for interactive login, refer to the troubleshooting article dedicated to getting around those issues: Confluence Authentication Issues.
Personal Token
The Personal Token authentication type uses a special kind of password (“token” or “key”) to log in. This password is created in Confluence in the context of a Confluence user account.
Please refer to this article for configuration details: Personal Access Token.

Confluence Server and Data Center just need the token

Confluence Cloud needs the name as well
The Personal Token is also referred to as Personal Access Token, API Token, or API Key.
Confluence 7.9 started supporting this authentication type.
In Confluence Cloud some transformations may not avilable with this authentication type (Jira Issue List).
The harder cases…
What are hard cases with regard to Confluence authentication?
Here are some hallmarks of a hard case:
- Interactive Login authentication does not work immediately
- Personal Token authentication is not available because Confluence is older than version 7.9 or because of multi-factor or other requirements
- the cookies.txt workaround to provide session cookies manually for Interactive Login does not work
Over time, I encountered the following hard cases:
- Kerberos prevented WikiTraccs from taking over the session cookies from Interactive Login; only connections made from the Chrome browser were considered valid by the Confluence backend
- WikiTraccs once could not detect a successful login to Confluence and was thus not able to get the session cookies for Interactive Login; cookies.txt also did not work; reason unknown
- Confluence could only be connected to using TLS 1.3-secured connections; Windows and the Confluence backend could not negotiate a mutual TLS 1.3 cipher to use; this issue does not affect the Chrome browser as Chrome brings its own cryptographic stack that operates independently of Windows
Note that those cases were the exception and not the rule.
Nevertheless, those cases needed to be handled as some of them were introduced by configuration changes that were made while migrating and thus blockers. So, WikiTraccs got something called the proxy mode.
Proxy Mode
The proxy mode is a workaround for all of the above issues with the Interactive Login authentication type.
Normally, connection and authentication issues tend to be absent when a user logs in to Confluence in the browser, but start appearing once WikiTraccs starts talking to Confluence directly.
If those issues cannot be resolved, there is only one way left: go back to using the browser to connect to Confluence.
That’s what the proxy mode does. WikiTraccs will keep an automated Chrome/Edge browser window open and route all requests to Confluence right through that browser.
This comes with some drawbacks as well. Routing everything through the browser is slower. Also, the proxy mode is not perfectly polished, as it is only thought as a workaround. So WikiTraccs might get confused at times with regard to automating the Chrome/Edge browser window, which can be resolved by closing and reopening all windows.
But overall the proxy mode is like the silver bullet to authentication issues.
You activate the proxy mode in WikiTraccs Settings ⇒ Misc ⇒ Proxy Confluence API calls through browser:

Summary
When it comes to authenticating with Confluence those are the steps to take:
In WikiTraccs:
- Choose the Interactive Login authentication type and test connecting; if that doesn’t work immediately:
- Choose the Personal Token authentication type and test connecting; if that isn’t available:
- Use the cookies.txt workaround and test connecting using the Interactive Login;
- if that does work: good; find the missing cookie names and enter them in the Advanced Settings dialog
- if that doesn’t work:
- Use the Proxy Mode in combination with Interactive Login
If your environment blocks connections to certain endpoints, it might also be necessary to provide the Chrome Driver manually. WikiTracccs uses the Chrome Driver to automate the Chrome browser.
General considerations:
- check if the migration account can be enabled for Personal Token authentication
- make sure all endpoints can be reached by WikiTraccs, e.g. to download the Chrome driver needed to automate the Chrome browser for Interactive Login
- make sure the Confluence backend and Windows can work together with regard to supported TLS versions and ciphers
Usually, none of the workarounds are necessary. But now and then they are needed. That’s why they are available.
And if nothing works - get in touch and we’ll have a look.
Confluence might misreport space contents
There is one specific issue that customers have now and then: not all pages of a space are being migrated. Some pages will be missing in SharePoint.
Why is that?
While there can be multiple reasons, one is Confluence itself misreporting the contents of spaces.
Let’s look at the root issue and how WikiTraccs tries to work around it.
The root issue: Confluence lies about its space contents
If the Confluence issue is present, it affects the most convenient type of WikiTraccs’ source content selectors, the Space Selector.
When WikiTraccs starts migrating a space it asks Confluence about the contents of this space, like “give me all page IDs in this space”.
Confluence will happily answer and the list of page IDs it returns might look like this: 00001, 00002, 00003, 00004, 00005, 00006. This would be 6 pages to migrate. That’s what we expect.
But sometimes the result looks different, although all 6 pages are definitely there. Confluence might report the list of page IDs like this: 00001, 00002, 00002, 00002, 00005, 00006.
Notice the difference? Page ID 00002 is listed three times, while 00003 and 00004 are missing.
This is a problem. Why is Confluence lying to us? I don’t know.
Note
Over the course of two years I got the impression that at least 10% of Confluence on-premises instances are affected. Not sure about cloud, yet.WikiTraccs tries to work around this issue
The latest release of WikiTraccs contains a workaround for this Confluence issue.
WikiTraccs detects duplicate page IDs and will take that as a hint that page IDs will be missing as well. It will then use a different method to retrieve the page IDs for a space.
One caveat of this workaround is that it’s significantly slower than just getting the list of page IDs handed by Confluence. But at least it should retrieve a complete list.
How to verify that all pages have been migrated?
When Confluence is not lying to us, WikiTraccs’ progress log files are the way to go. The __30-aggregated-info file shows a summary of a space’s migration progress. This is the happy path.
If you have a hunch (or see it in the logs) that Confluence might be lying about the contents of a space, your only chance is to look at and compare with the Confluence database.
Here’s how to get a list of page IDs from the Confluence database, for a given space: Getting a list of pages per space.
Compare the list of page IDs you got from the database with the list of pages WikiTraccs got handed by Confluence. The pages WikiTraccs knows about for a space can be seen in the __25-update-state-of-migrated-pages progress log file.
Hints about duplicates in the WikiTraccs log file
The WikiTraccs common log files contain information about duplicate page detection and applied workarounds.
You want to find this message for each space that has been selected for migration:
No duplicate IDs found for selector (Type=ConfluenceSpaceKey; Query=GOOD)
Above log message says that all is fine for space with key GOOD, as there were no duplicate page IDs. Also, WikiTracccs takes this as a hint that there won’t be page IDs missing (note: this is an assumption that is yet to be proven wrong).
To the contrary, the following log message indicates that duplicates where found for space with key DUPE:
Duplicate content IDs found for selector (Type=ConfluenceSpaceKey; Query=DUPE)
Searching for the text [DUPLICATES] in the WikiTraccs log files will surface further details about the affected spaces, like which pages are affected and which pages could only be retrieved via the built-in workaround.
Working around the issue with the Content ID Selector
The issue only affects Space Selectors as for those WikiTraccs will ask Confluence about space’s contents. Consequently Confluence might choose to lie to us.
To prevent this kind of issue, you might choose Content ID Selectors instead to tell WikiTraccs the page IDs it should migrate. With this type of selector you take the “page ID retrieval” part in your own hands. Have a look at the documentation about the details.
In general, Space Selectors are easier to handle than Content ID Selectors. So in an ideal world, there would be no need to choose one over the other to work around Confluence issues.
How to fix this Confluence issue?
I don’t know. Let me know if you find a solution.
Can feature 'XYZ' be added to WikiTraccs?
It depends.
Adding XYZ to WikiTraccs vs. project-specific solutions
The development of WikiTraccs is mostly driven by customer demand. That, and changes by Microsoft and Atlassian to their services.
Every environment and migration project is different, but there are similar challenges. If customers (or I) face the same challenge over and over again, it’s usually time to think about extending WikiTraccs to support the underlying use cases.
New WikiTraccs feature?
I’m open to extending WikiTraccs if the new feature helps with an often-faced challenge that is not isolated to a specific migration project.
New WikiTraccs features must:
- ✅ work in a standard SharePoint Online environment, without having to install third-party apps
- ✅ solve a challenge for multiple clients
- ✅ have a technical solution
- ✅ take reasonable time to implement
If some of those boxes cannot be checked then the solution is usually project-specific, although we should definitely talk this through.
Project-specific solution?
Project-specific solutions solve challenges for a specific migration project or a specific environment.
Modifying the page header to comply with CI/CD? Turn off the comments section on pages? Add page metadata for HR? Those are unique requirements within a project.
Project-specific solutions usually involve a combination of configuration (search configuration, content types, managed metadata), low-code solutions (Power Automate workflows), and scripting (PowerShell, JavaScript).
Missing feature XYZ is a blocker for me - can you add it to WikiTraccs?
I’d like to learn more. Does the feature check all of above boxes? That’s a good start.
The less time it takes to implement a feature, the more likely it is that I’ll add it for you. The more time it takes, the more useful it has to be in a broader sense.
I consider anything below ~2 days of end-to-end development effort as relatively low effort. Adding transformations for yet-unknown but simple-to-handle macros fall into that category. Or adjustments to text placeholders.
Note that I cannot give a guarantee that or when a feature will be added.
That being said - I’m always open for feature proposals as this is the way for me to learn about real-world challenges.
If we haven’t been already in touch via a demo or email or GitHub, please get in touch!
Help me help you
When looking at your Confluence to SharePoint migration challenge, I need to understand it first. Please help me with that.
Screenshots help illustrate your case
Screenshots are a good way to start understanding migration results.
Something looks unexpected after migrating pages to SharePoint? Take a screenshot of the source Confluence page and a screenshot of the migrated page in SharePoint. Highlight your expectations in the screenshots or write some lines about what you expect.
Create the expected outcome manually in SharePoint
Help me see the SharePoint page as you envision it to look after the migration.
Create a new modern SharePoint page and edit it. Manually add all the necessary elements to make it resemble the source Confluence page as closely as possible. Use only out-of-the-box SharePoint web parts - no PnP, no third-party tools (I nevertheless like to hear about those as well! Maybe it’s the exception to the rule).
Send me a screenshot of both the source Confluence page and target SharePoint page.
This ensures that it is technically possible to achieve what you’d like to see on the SharePoint side and serves as a mockup for me to understand your requirements.
Furthermore, It would help a great deal if you could send me the SharePoint storage format of the page. Here’s how to get that: Get the SharePoint Storage Format
Send me the Confluence page’s storage format XML
There is a Confluence page that contains something that you’d like to see migrated differently? Like a macro that ends up being a placeholder in SharePoint?
Send me a screenshot of the Confluence page.
I also need to see the page how WikiTraccs sees it to estimate how much effort it takes to support new transformations.
Send me the storage format XML. Here’s how to get that: Get the Confluence Storage Format.
The storage format XML contains a page’s text content, structure, formatting, and most importantly information about all macros, including their parameters.
Closing note
Please review the existing feature proposals in the GitHub issue list and vote for those you’d like to see gain traction. Alternatively, you can create a new feature proposal or start a discussion.
Converting Gliffy and draw.io to SVG
Motivation
The motivation behind this blog post is a customer request:
When migrating from Confluence to SharePoint, how to migrate Gliffy diagrams as SVG files?
Unfortunately, WikiTraccs cannot do much in this regard. WikiTraccs migrates Confluence page attachments, which include the diagram file (from Gliffy or draw.io) and the diagram’s preview image. Read the previous blog post for details on that.
At least you end up having the diagram file in SharePoint Online.
Having the diagram file in SharePoint is a good thing, because it gives us the option to work with those diagrams even when Confluence is not around anymore.
How to export diagrams as SVG files
Let’s look at our options to export diagrams as SVG.
Gliffy => SVG
When Confluence is still around, you can export from Confluence:
- Open Confluence page
- Edit Gliffy diagram
- File… > Export > SVG
After having migrated to SharePoint Online, you need to work with the diagram file instead:
- Open a migrated SharePoint page
- Download the migrated Gliffy diagram file from the page’s attachments
- Open app.diagrams.net (a free online diagram software) in browser
Warning
The next step uploads your diagram file to app.diagrams.net.- Drag the diagram file into the browser
- File > Export as > SVG…
draw.io => SVG
When Confluence is still around, you can export from Confluence:
- Open Confluence page
- Edit draw.io diagram
- File > Export as > SVG…
After having migrated to SharePoint Online, you need to work with the diagram file instead:
- Open migrated SharePoint page
- Download migrated draw.io diagram file from the page’s attachments
- Open app.diagrams.net?offline=1 in browser (a free online diagram software), in offline mode
- Drag the diagram file into the browser
- File > Export as > SVG…
Note that this doesn’t seem to upload the diagram file as it already has the draw.io format.
Privacy Considerations
When Confluence is not around anymore and you end up using app.diagrams.net (note: which is the only free tool I know of that can convert Gliffy to draw.io), there is one fundamental difference between Gliffy and draw.io files.
The app.diagrams.net online editor needs to convert Gliffy diagrams to draw.io diagrams first. This is done at a remote location. This means your diagram files will be uploaded to a third party.
This is contrary to draw.io diagram files. When loading those into the app.diagrams.net online editor, no upload seems to happen.
draw.io Desktop (free)
There is an alternative to app.diagrams.net and that is the draw.io Desktop application. You can download it at drawio.com.
draw.io Desktop seems to have the same capabilities as app.diagram.net. There is one important exception: the desktop version cannot convert Gliffy files to the draw.io format. Which is unfortunate when you only have Gliffy files that you want to convert to SVG.
There is no free offline tool available that I know of that can convert from Gliffy to draw.io.
Gliffy-to-draw.io Mass Conversion (paid-for)
There is a paid option available to convert Gliffy to draw.io when Confluence is still around.
The draw.io Confluence plugin can convert Gliffy to draw.io.
According to its documentation, it can do mass conversions of all Gliffy diagrams in a Confluence instance:
- Mass import Gliffy diagrams to draw.io in Confluence Server
- Mass import Gliffy diagrams to draw.io in Confluence Cloud
Also according to the documentation, it doesn’t require a license to do the actual conversion. But it will convert all Gliffy macros to draw.io macros as well, so having no license doesn’t seem to make sense.
Mass-converting Gliffy to draw.io before migrating to SharePoint seems like an option to have those draw.io files ready in SharePoint, in case users want to work with those diagrams using either app.diagrams.net or the draw.io Desktop app.
Migrating Gliffy and draw.io macros to SharePoint Online
We first look at how Gliffy and draw.io work in Confluence, then we look at a migration result.
How are the diagrams stored in Confluence?
This is a sample Confluence page (in edit mode) containing both the Gliffy and draw.io macro:
Both macros create two page attachments when you create a diagram.
One attachment file is the diagram file, containing the digram definition in a macro-specific format. The other attachment is the preview image that is shown on the page.
Here’s how the page attachmens for above sample page look. It’s two attachments per macro:
How do Gliffy and draw.io look in SharePoint Online?
First of all, WikiTraccs migrates the page content and page attachments as usual. So, both the diagram file and the preview image will be available in SharePoint as well.
When migrating page contents, WikiTraccs looks out for Gliffy and draw.io, and replaces those macros with a SharePoint image web part. The image web part is configured to show the respective macro preview image:
Looking at the SharePoint page’s attachments we can see the same files as in Confluence:
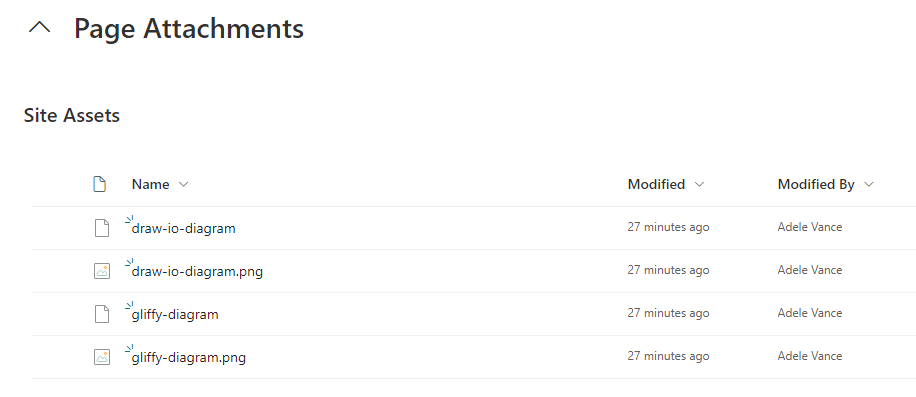
This is the result you can expect after migrating Confluence pages with Gliffy or draw.io macros to SharePoint Online using Wikitraccs.
Transforming even more colors from Confluence to SharePoint!
The latest release of WikiTraccs contains multiple improvements with regard to colors.
Text colors, the newly introduced text highlight colors (Confluence Cloud) and table cell colors got some attention.
Note
SharePoint does not support all colors that are available in Confluence. So WikiTraccs tries its best to map to a color that exists in SharePoint Online.What has SharePoint Online to offer in terms of colors?
The SharePoint Online color palette for text looks like this:

Note that we cannot really use the theme colors as they change, depending on the theme. That leaves us with 11 text colors.
The SharePoint Online color palette for highlights looks like this:
That’s a whopping 15 colors.
What about table cell colors? SharePoint does not have those. We’ll see how WikiTraccs handles that further down.
Text Color Transformation
Those are the 21 text colors available (at least at the moment) in Confluence Cloud:
Text Colors in Confluence Cloud
WikiTraccs maps those colors to the visually nearest available text color in SharePoint Online:

Text Colors in SharePoint Online
Here’s another example from Confluence Server, which has 40 colors to offer:
Text Colors in Confluence Server 6
This is how it’s transformed to SharePoint:
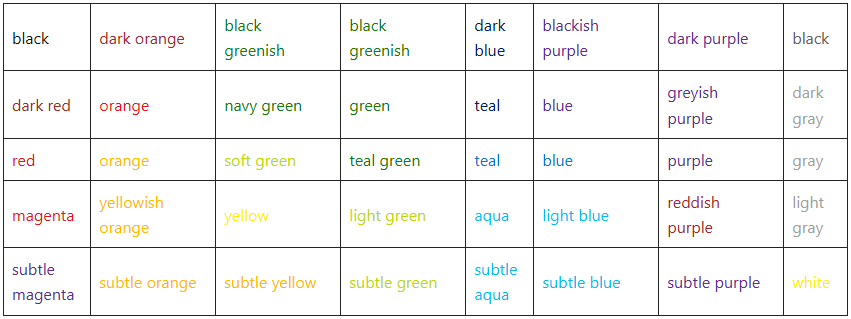
Text Colors in SharePoint Online
Highlight Color Transformation (new)
Now for the new highlight colors in Confluence Cloud:

Highlights in Confluence Cloud
Those map pretty well to SharePoint Online in terms of available colors:
Highlights in SharePoint Online
SharePoint’s highlight colors are way darker than in Confluence which makes black text hard to read for the teal and purple highlights.
Table Cell Color Transformation
Here’s how table cell colors look in Confluence Cloud:
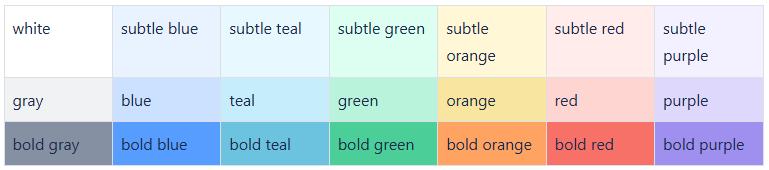
Table cell colors in Confluence Cloud
SharePoint does not support setting colors for table cells. Maybe that’s coming in the future, but so far I did not spot anything related on the roadmap. (Let me know if you see or hear something!)
WikiTraccs is using a workaround to at least indicate in SharePoint, that the table cell was colored in Confluence.

"Table cell colors" in SharePoint Online
Here’s another sample from Confluence Server 6, which has less cell colors to offer:
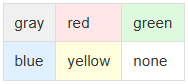
Table cell colors in Confluence Server 6
This is how it’s transformed to SharePoint:

Table cell colors in Confluence Server 6
In both instances, WikiTraccs adds a block of colored spaces to each formerly colored table cell, serving as a “color marker”. And again, it is restricted to colors that SharePoint has to offer.
What did change in the latest WikiTraccs release?
The latest release handles text highlight colors that have been introduced by Atlassian in June 2024.
Furthermore, the color markers for table cells now support the full range of text colors available in SharePoint. Previously, WikiTraccs used colored emoji squares like 🟩 as marker - but those only come in very few colors.
And last but not least: the algorithm to calculate the visual distance between colors has been improved. This maps Confluence colors even more closely to their SharePoint equivalents.
How to run parallel WikiTraccs migrations?
You can run multiple WikiTraccs instances in parallel to speed up the overall migration. You’ll need a separate machine or VM per WikiTraccs instance as only one instance is allowed to run on the same machine.
Some definitions
The computer or virtual machine (VM) WikiTraccs is running on is the machine or migration machine.
We’ll call the running WikiTraccs program a WikiTraccs instance. When two WikiTraccs programs are running, that would be two instances.
The central SharePoint site that WikiTraccs needs and where the Space Inventory list (and more) is located is called WikiTraccs site.
One WikiTraccs instance is allowed to run on one machine.
How to run multiple WikiTraccs instances in parallel?
Looking at client’s projects I see different approaches.
Some create cloud-based virtual machines in Azure or AWS. Some use spare laptops.
Install WikiTraccs to each of those machines and your are good to go.
Configuring WikiTraccs when parallelizing the migration
There is local and shared configuration.
Configure locally on all machines
Make sure you configure the WikiTraccs settings on all machines. This affects things like comments migration, macro ignore list, migration mode etc. They can be different on different machines, but usually are the same.
Locally stored settings are:
- everything you enter into the blue WikiTraccs.GUI window
- settings available in the blue WikiTraccs.GUI window via the Settings menu
- any settings configured via
appsettings.json
Note that the Space Inventory that contains the source-to-target mapping is NOT a local setting, but stored in SharePoint, in the WikiTraccs site. But the link to the WikiTraccs site (that contains the Space Inventory) is part of the local settings.
Be aware of shared configuration via WikiTraccs site
One WikiTraccs site can be used by multiple WikiTraccs instances, or each instance can use their own WikiTraccs site.
With the same WikiTraccs site, multiple WikiTraccs instances share the same mappings.
There is one caveat of sharing one WikiTraccs site: they will also want to migrate all the same content.
We’ll look at two two scenarios now: one with shared WikiTraccs site, one without.
Parallelization Scenario - Shared WikiTraccs Site
Multiple WikiTraccs instances share the same WikiTraccs site.
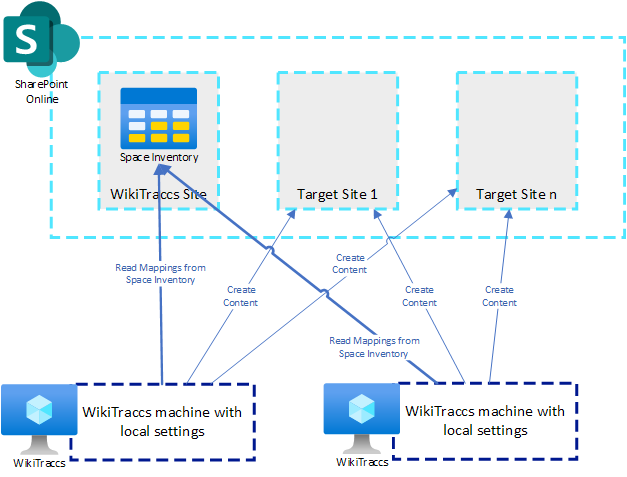
Two WikiTraccs instances sharing a single WikiTraccs site.
To achieve that, simply configure the same WikiTracc site address for all WikiTraccs instances.
Pro:
- you need to configure the mapping in the Space Inventory only once
- you need to configure the user and group mapping only once
- easy, as there is only one WikiTraccs site
Contra:
- (note: before WikiTraccs v1.18) you need to change the WT_Setting_RequestTransformation value in the Space Inventory before starting each WikiTraccs instance as otherwise multiple instances migrate the same pages (!); one approach is to use PnP.PowerShell to manipulate the space inventory
Tip
Starting with WikiTraccs v1.18 migration waves are supported. Those simplify distributing the migration to multiple WikiTraccs instances.
Assign wave numbers to selectors in the Space Inventory. Then select a different wave for migration in each WikiTraccs instance.
Important
With this scenario, you need to make sure that no two WikiTraccs instances migrate the same content at any given time.Parallelization Scenario - Separate WikiTraccs Sites
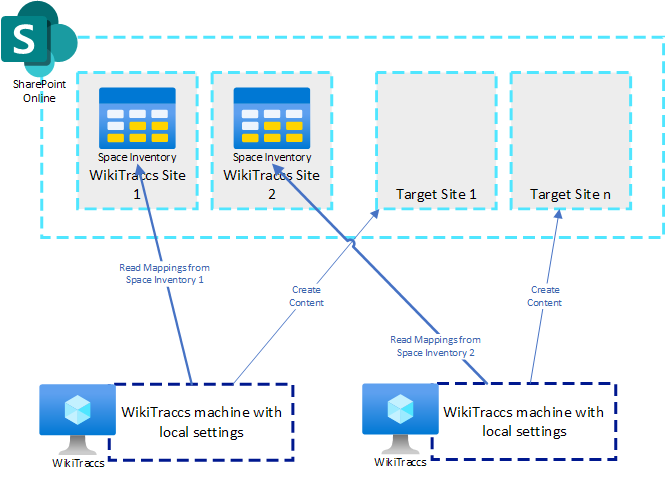
Two WikiTraccs instances each using their own WikiTraccs site.
To achieve that, use a different WikiTracc site address for each WikiTraccs instance.
Pro:
- the WT_Setting_RequestTransformation value in the Space Inventory can be configured per WikiTraccs instance, as each instance has its own Space Inventory
- the snapshots that WikiTraccs takes of pages (in the Confluence Content Snapshots library), that are stored in the WikiTraccs site, are now scattered across multiple WikiTraccs sites, which can be an advantage permission-wise (when different teams do the migration that are not allowed to see each other’s content)
Contra:
- the mapping in the Space Inventory needs to be configured in all WikiTraccs sites, for all spaces and CQL selectors (!)
- the user and group mapping needs to be configured in all WikiTraccs sites
Important
With this scenario, you need to make sure to configure each instance properly and to configure complete mappings in each Space Inventory (even for spaces migrated by other instances). It’s important for link transformation of cross-space links.General parallelization notes
Multiple instances can migrate to the same target SharePoint site, as long as they don’t migrate the same content at the same time to the same target.
Parallel migration is covered by the WikiTraccs license, without limits.
You shouldn’t go too crazy with the parallel instances. There are limits in place set by Microsoft on how fast an application can access the Microsoft 365 services. Microsoft will throttle WikiTraccs, if it goes to fast. This means: WikiTraccs will have to wait some time (a couple of seconds, or even minutes) until it is again allowed to send content. Those limits are set by Microsoft, adjusted to overall cloud load, and dependent on the number of licenses in the tenant (among other factors).
Tip
You can use different SharePoint migration accounts for each of the parallel WikiTraccs instances; this can help increase the throttling limits that are imposed by Microsoft.Fixing image positioning in SharePoint
Note
Read Broken inline image positioning in SharePoint to learn the background story of this post.Note
Images that are part of a list are still broken when editing a page, even when applying the Page Companion Fix described in this post. Another support case with Microsoft is open regarding this page regression: 2311041420000292.Summary of what happened images in SharePoint
Up until about mid-2023 SharePoint text web parts were able to display inline images next to each other. Then Microsoft started upgrading the editor component that powers the text web part, while at the same time introducing changes to the overall page style. This broke adjacent image positioning.
Specifially, when editing a SharePoint page, its text web parts are auto-upgraded to the new editor version which positions once-adjacent images now vertically, not horizontally:
So what are our options to fix this?
How to fix image positioning? And who?
The SharePoint text web part, at the time of this writing, does not support putting multiple images next to each other. Neither in the browser editor, nor via programmatic means.
Here’s a list of parties that could influence image positioning in text web parts, in principle:
- Microsoft - but they say the current behavior is by design, so they won’t help
- WikiTraccs
- You
Number one is out, let’s look at the other two options.
What can WikiTraccs do?
Short version:
At the moment, nothing.
Longer version:
When migrating Confluence pages to SharePoint, WikiTraccs creates pages that still show adjacent images. That’s because it’s generating pages in a version that still supports this. SharePoint supports displaying pages that use the (now) older version.
As soon as you edit such a page it is upgraded to a newer version that doesn’t support adjacent images anymore.
The only thing that WikiTraccs could do is starting to generate pages in such a way that images won’t be adjacent anymore, to begin with. You’d then see the non-adjacent version right away, without having to edit the page.
I’ll look into such options as soon as the new way to display pages is confirmed as generally available by Microsoft. I don’t have such a confirmation, yet.
That means that WikiTraccs cannot do anything at the moment.
What can you do?
You have two options:
- Re-arrange images and content when you edit a page.
- Roll back the layout change that Microsoft did to screw up image positioning.
Option 1 is straightforward: you edit a page, adjacent images are not next to each other anymore, you have to clean up.
Option 2 involves rolling back a single layout change that Microsoft introduces when upgrading the text web part.
The Wiki Transformation Project provides a tool to achieve option 2: the WikiTraccs Page Companion.
Introducing the WikiTraccs Page Companion
For option 2 to work, we need to change pages as they are displayed in the browser. It’s like duct taping a small piece of paper over a bad part of the page, using duct tape that can be removed without traces.
Fortunately Microsoft provides a supported means of integrating with SharePoint pages: SharePoint Framework (SPFx) Application Customizer. Using such a customizer, we can hook into each page as it is being displayed in the browser.
Regrettable, the change we need to make to how pages are being displayed is not officially supported by Microsoft. We need to accept that if we want to proceed with this duct tape option.
Note
This option does not modify page contents. It’s merely a temporary visual change. Disabling the application customizer restores out of the box behavior immediately.Here’s a demo video of the WikiTraccs Page Companion in action. About 11 seconds into the video, note the little box reading Legacy image positioning (by WikiTraccs) in the lower right corner, that’s the extension:
(Note, because I get asked: the page tree you see in the video is WikiPakk, the SharePoint page tree experience.)
The toggle button can be used to toggle the image positioning fix on and off on a per-page basis. On means, the duct tape is applied. Off means, the duct tape is being removed, again. It is opt-in, so not enabled by default.
As an author, you would check the page you are editing, and toggle the button as needed. The fix affects the page both when being edited and being viewed.
The WikiTraccs Page Companion is available as pre-compiled download (to be deployed to a SharePoint app catalog), and also as source code for you to build yourself. It’s all on GitHub: WikiTraccs Page Companion.
Note that the non-standard nature of this option means that it might stop working when Microsoft makes changes to pages. If that happens, the adjustments that need to be done need to be re-evaluated.
I’m putting the source code out there, so that you are in control as well.
Get in touch if you have any questions.
Broken inline image positioning in SharePoint
Update October 22, 2023
Microsoft Support confirms that the behavior described on this page is expected. No adjacent images anymore.Update October 29, 2023
Read the follow-up: Fixing image positioning in SharePointIn general, SharePoint is behind Confluence when it comes to positioning images in relation to each other and to surrounding content.
But at least putting images next to each other is possible. Is? Was. s Those two blog posts took a deep dive into the topic of images:
- Part One: Why is image positioning important and which options do I have in Confluence and SharePoint?
- Part Two: What do migrated images look like in SharePoint, with the focus on retaining positioning?
Unfortunately a recent update to the SharePoint text editor web part breaks adjacent images. They aren’t adjacent anymore when editing a page.
Microsoft is upgrading the editor version of SharePoint pages - and the trouble starts
The text editor web part is powered by the CKEditor editor component. It can be licensed by any third party to build rich editor experiences in the browser. Microsoft did that.
The following things define how the text editor web part behaves:
- the features that CKEditor provides - like formatting highlighted text, adding tables and so on
- add-ons to the editor that Microsoft develops
- internal settings set by Microsoft defining which features are available to users
- surrounding styles (CSS) that define how things look (e.g. font size)
- page contents
The most recent version of CKEditor is version 5 (v5). So far SharePoint used version 4 (v4) of CKEditor.
Microsoft now upgrades pages to use CKEditor v5.
Why is this important for content creators? Because the content of SharePoint pages is somewhat coupled to the editor version of the text editor web part. Microsoft cannot just upgrade from CKEditor v4 to v5 without breaking old pages. Therefore Microsoft auto-upgrade pages when they are being edited. And that modifies the page content.
When you start editing a page and its content briefly disappears and then comes back - this might have been an auto-upgrade.
And somewhere along the way of this auto-upgrade the handling of inline images changed.
How does the page upgrade affect adjacent inline images?
Here are three visuals showing how pages used to behave, and how they behave now.
How it used to be…
This is a page with three adjacent images in view mode, using CKEditor v4:
This is the same page in edit mode, using CKEditor v4:
How it’s now…
And here is a video that shows what happens when the auto-upgrade to v5 for this page kicks in:
Note: I used the browser’s developer tools to slow down the internet connection, which allows us to watch everything in slow motion.
What can be seen in above video:
- the page enters edit mode and the three inline images can be seen next to each other for a brief moment
- then all web part content vanishes; the auto-upgrade happens where SharePoint converts the content from CKEditor v4 to CKEditor v5
- the web part content reappears; the images are placed on top of each other (NOT GOOD)
- bonus: all images are gone! (this was a first when recording this video) (NOT GOOD)
Editing this page worked perfectly fine for at least the last 12 months. Images stayed in place, no problems.
Now broken.
What does this mean for pages that WikiTraccs migrated from Confluence to SharePoint?
Pages migrated by WikiTraccs use CKEditor v4. Adjacent images look fine when viewing those pages.
When editing a page with adjacent images SharePoint might decide to skip upgrading this page to v5. The page will look fine in view and edit mode.
When editing a page with adjacent images SharePoint might decide to upgrade this page to v5. Adjacent images won’t be adjacent anymore in edit mode and need to be re-arranged manually. This looks like a newly introduced technical limitation of SharePoint. Note that currently there is no way to put images next to each other via the browser editor.
Note: the same applies to pages transformed by other tools, e.g. when transforming classic SharePoint pages to modern SharePoint pages using the PnP Modernization Tooling.
Resources
I’m keeping track of topics related to page upgrades here.
Adjacent image positioning issues
Issues with adjacent image positioning are reported by the first WikiTraccs client in mid-September.
I created a Microsoft Tech Community post to get input: Modern pages with text web parts upgraded from CKEditor v4 to v5 lose image positioning.
I also created a minimal PowerShell script that can be used to create a SharePoint page with adjacent images to test the page upgrade: GitHub repository. To showcase and pinpoint the issue.
Furthermore I opened a case with Microsoft support, which is closed now. The case ID is 2310071420000151. According to them this is expected behavior.
Other known issues
There were issues with tables when upgrading pages from CKEditor v4 to v5:
- related issue: https://github.com/SharePoint/sp-dev-docs/issues/9160
- was forwarded to the product group
There are issues with the new spacing between paragraphs:
- here’s a mighty thread about changes in paragraph spacings and the consequences: No paragraph spacing in text web part (Sharepoint modern pages)
Wrapping up
It’s not clear what exactly breaks image positioning on modern pages after upgrading the editor from v4 to v5.
It might be the content upgrade for those pages. But it might also be the changed surrounding styles that come with the upgrade.
I really hope that there will be a proper solution to putting images next to each other on a MODERN SharePoint page. Nothing more. Just some images. Next to each other.
How to migrate rich Confluence tables to limited SharePoint tables?
Update
There is an update to the table story, and more options have been made available since this blog post was first published.
Read about it here: Making SharePoint Tables Look Pretty.
What are different table capabilities of Confluence and SharePoint?
The following table formatting options are available in Confluence:
- setting the background color for table cells
- having multiple header rows or columns
- nesting tables
- merging table cells
All of the above is not possible in SharePoint at the time of this writing.
Let’s see how WikiTraccs works around that.
How does WikiTraccs adjust for table formatting limitations in SharePoint?
WikiTraccs has to get creative when it comes to mimicking the full range of Confluence table formatting options.
Table cell background color is transformed to colored emojis. The color is moved from the cell background to the cell content, as there are no colored table cells in SharePoint.

Confluence table with colored cells

Table after migrating to SharePoint, with color markers
Only a limited set of rectangular colored emojis is available to do this, so the color often will be off.
Multiple header rows or columns are represented as normal table rows and columns in SharePoint where the text content is formatted bold.

Confluence table with multiple header rows and columns
Table after migrating to SharePoint, with bold text simulating the headers
Nested tables are de-nested. This approach is analoguous to how the the Microsoft SharePoint Migrations tool does it for SharePoint on-prem to SharePoint Online migrations.
Merged table cells cannot be created in SharePoint Online. But WikiTraccs marks those cells that once were merged (as of WikiTraccsrelease v1.3.11).
Here is an example of how it looks after migrating a table with merged cells from Confluence to SharePoint:
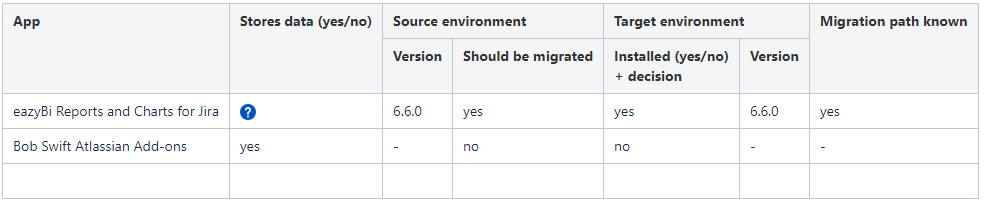
Confluence table with merged table cells
Table after migrating to SharePoint, without marking former merged cells (note: default behavior before WikiTraccs v1.3.11)
Table after migrating to SharePoint, with marking former merged cells (note: default behavior as of WikiTraccs v1.3.11)
The little arrow in former merged cells points in the direction of the cell it had been merged with before having been migrated.
Marking former merged table cells is standard as of WikiTraccs v1.3.11.
Wrap-up
WikiTraccs needs to get creative when it comes to transforming Confluence tables to SharePoint tables. The results depend on the complexity of the tables that are migrated from Confluence to SharePoint and a manual content review does not hurt.
Let’s hope that SharePoint keeps maturing to a point where formatting tables is on a par with what’s possible in Confluence.
Migrating large Confluence spaces to SharePoint
Update
For Confluence 7.18 and up the challenge described in the blog post has been solved.How does WikiTraccs determine which pages to migrate for a space?
When WikiTraccs starts to migrate a space to SharePoint it retrieves the full list of pages for this space.
Say a space contains 20000 pages. WikiTraccs retrieves basic information about those 20000 pages and adds them to a migration queue. (Later, when migrating each page, WikiTraccs retrieves the contents of this page and creates the corresponding SharePoint page.)
Confluence doesn’t allow retrieving information of more than 200 pages at once. So to retrieve information about 20000 pages WikiTraccs needs to request 100 batches of 200 pages, as that is supported.
This paged retrieval is where things get interesting for larger spaces.
Why can large Confluence spaces pose a challenge?
The more pages a space contains the longer it takes to retrieve a batch of pages.
Here are numbers from a Confluence 6 test migration of a space with about 23000 pages:
- retrieving batch 1 takes < 1 second
- retrieving batch 10 takes about 2 seconds
- retrieving batch 25 takes about 4 seconds
- retrieving batch 50 takes about 6 seconds
- retrieving batch 75 takes about 10 seconds
- retrieving batch 100 takes about 14 seconds
Assuming retrieving each batch of 200 pages takes a mean of 8 seconds, retrieving 20000 space pages would take 100*8=800 seconds, which is about 14 minutes.
Exporting this space (with empty dummy pages) via the Confluence space export function takes about 16 minutes:

Successful page migrations
Unfortunately there is not much that can be done about the time it takes to retrieve the list of pages. With release v1.6.8 WikiTraccs started to migrate pages while still retrieving the list of pages for a space. This at least allows the waiting times to be used to migrate the first pages.
Note
WikiTraccs logs the time it takes to retrieve a batch of pages, if it starts to take longer. Look out for those messages in the WikiTraccs.Console log or common log file:
Handled a batch of 200 pages for GIANT... (so far handled 18321)
Took 10.601631s to get space GIANT content (paged) from endpoint URL <...>
Confluence 7.18 introduced an API that allows for faster page retrieval, but so far there was no demand I am aware of as migrated environments were older. If you are migrating a Confluence version 7.18 or newer then please comment here to make this demand visible: User faster page retrieval API (Confluence 7.18 and up).
Conclusion
Large Confluence spaces (more than 10000 pages) can add significantly to the migration time.
When WikiTraccs starts migrating a space it retrieves a list of all space pages, which can take several minutes for those large spaces. The list of pages is retrieved multiple times, for example after migrating the space to check if all pages were migrated.
Those times can add up.
So it’s good to know the spaces with large page numbers beforehand, or to learn about them during a test migration.
Large space? Estimate first.
Run your numbers through the Migration Duration Estimator, especially for high page counts and attachment-heavy spaces.Ignoring macros when migrating pages from Confluence to SharePoint
Note
The Macro Ignore List is available as of WikiTraccs v1.2.0.Why do I need a macro ignore list?
Certain Confluence macros are only visible when editing a wiki page. Often WikiTraccs can see those macros and migrates them to the SharePoint page - where they will be visible for visitors as well.
One sample is the Excerpt macro with the hidden option set.
WikiTraccs offers a macro ignore list that can be used to exclude such macros from the migration.
How to use the macro ignore list?
This series of screenshots shows how to identify macros to ignore and how to configure the ignore list.
Here’s a Confluence page with one visible macro, as shown for readers:
The Confluence page in edit mode reveals the second hidden Excerpt macro:
Without a configured Macro Ignore List WikiTraccs will migrate the hidden macro to SharePoint, making it visible. Here’s a screenshot of such SharePoint page:

To solve this, open the Confluence page, choose View Storage Format for the page and copy the offending macro XML:
In WikiTraccs.GUI, in the menu bar, choose Settings > Configure Transformation. Paste the macro XML to the Macro Ignore List:
In the Macro Ignore List, remove every macro parameter except hidden:
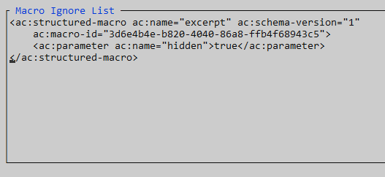
Delete previously migrated pages as needed after changing the Macro Ignore List, and start the migration.
The macro is now removed by WikiTraccs. Here’s the migrated page again as it looks in SharePoint:
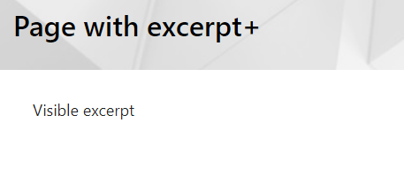
Any macro can be added to the Macro Ignore List. Macros matching the Macro Ignore List will be removed from all pages in the Confluence to SharePoint migration.
During migration, WikiTraccs looks at the macro name and its parameters. If it sees a macro that has the same name, and all of the parameters and parameter values as a macro in the Macro Ignore List it will skip this macro and won’t add it to the SharePoint page.
Note
You can add multiple macro XML templates into the Macro Ignore List, just put them one after another.How to monitor if the filter works as expected?
WikiTraccs logs removed macros while migrating pages from Confluence to SharePoint.
Search for the phrase Removed macro via config by matching template in the WikiTraccs log file to see which macros were removed and which template from the Macro Ignore List did match.
In addition, the Site Pages column WT: Transformation Log contains this information as well.
Wrap-up
The Macro Ignore List allows to specify which macros should be skipped in any Confluence to SharePoint page transformation.
It is one feature that was born directly from customer feedback. And it’s another step in the direction of a more configurable transformation process.
Get your migration started today!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
Registering WikiTraccs as app in Azure AD
Azure AD is now Entra ID - please refer to the updated documentation: Registering WikiTraccs as app in Entra ID.
Registering WikiTraccs as App in Entra ID
I recently got the following inquiry about WikiTraccs:
Please explain again briefly what the Tenant ID and Azure Client IDs are and how to acquire them.
This request is not the first of its kind and totally understandable. It refers to the following configuration in WikiTraccs.GUI:

Unless you are a Microsoft 365 developer or admin you normally never have to care about those IDs.
Why do I have to enter Tenant ID and Client ID in WikiTraccs? Where do those come from?
When WikiTraccs creates your migrated pages in SharePoint it needs to access APIs provided by Microsoft. Those are the SharePoint API and the Microsoft Graph API.
Accessing SharePoint in any form requires authentication. Open <company>.sharepoint.com (replace ‘<company>’ with the actual value of your SharePoint) in a private browser tab and it will ask for your credentials like email address and password - this is meant by authentication.
Authentication is also required when WikiTraccs starts the migration. It will open a browser window for you to sign in.
Migration Account
For the actual migration it’s recommended to create a dedicated migration account that logs in to SharePoint. This account can be granted permissions to only migration target sites for the duration of the migration. The migration account does not need administrative permissions.Besides users, applications like WikiTraccs have to identify themselves as well to gain access to SharePoint.
To allow an application authenticated access to Microsoft 365, it has to be registered in Entra ID (formerly known as Azure Active Directory, or Azure AD). This is a manual configuration that needs to be done once.
A registered application has an ID - the Client ID. The Entra ID tenant it is registered in also has an ID - the Tenant ID. Those are the IDs needed by WikiTraccs.GUI.
How to register WikiTraccs as Application in Entra ID?
Permissions
The following steps require logging in with an account that has permissions to create an app registration in Entra ID and to consent to permission requests.
For example, the Entra ID Application Developer role grants permission to create app registrations. For full migration capabilities, the Global Administrator or Privileged Role Administrator has to consent to the app’s permissions. See remarks about FullControl vs. Manage API permissions further down the article.
In a browser, navigate to https://entra.microsoft.com.
Sign in with an account that has the Application Developer role in Entra ID.
The Microsoft Entra admin center (former Azure Active Directory portal) opens.
In the left menu, under Applications, select App registrations, then New registration:
The Register an application blade opens:
Configure the following:
- under Name enter WikiTraccs Migration Tool (note: or any other name of your choosing)
- under Supported account types select Accounts in this organizational directory only
- under Redirect URI (optional) choose Public client/native (mobile & desktop) and type http://localhost in the edit field
Select Register to confirm the app registration.
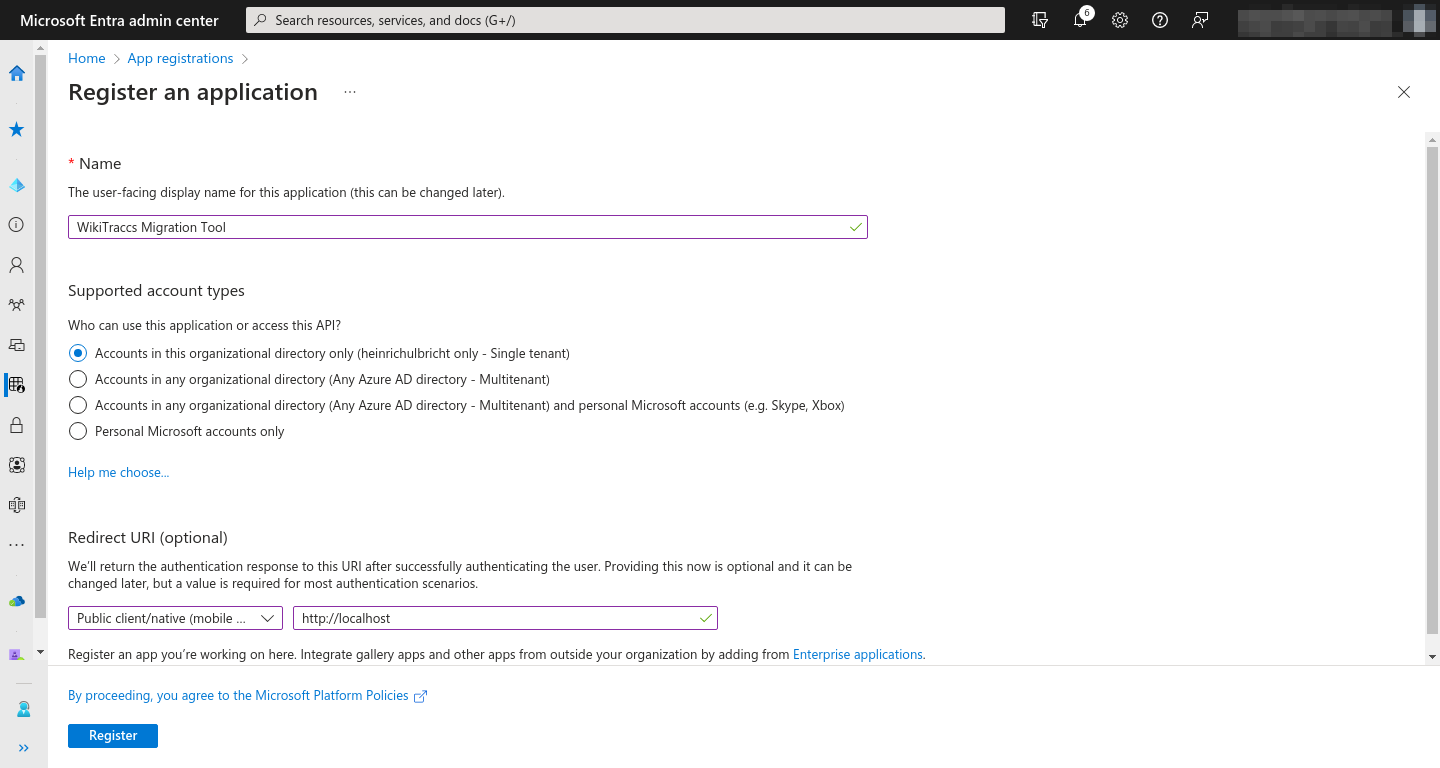
The application’s settings are now open:
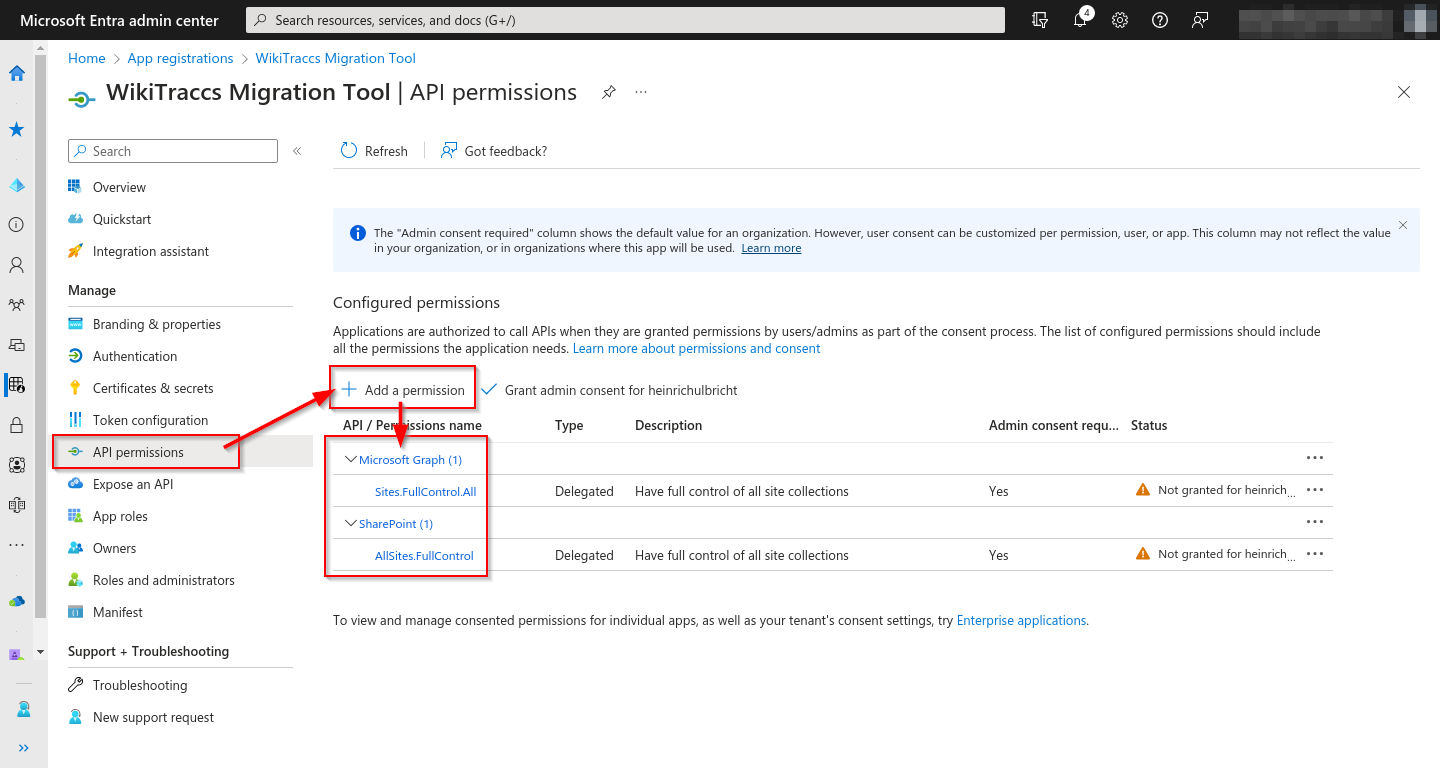
In the left menu, under Manage, choose API permissions.
Choose Add a permission to add the following permissions:
- Microsoft Graph > Sites.FullControl.All (delegated)
- SharePoint > AllSites.FullControl (delegated)
Make sure to select the Delegated permissions (not application permissions). Here’s a sample screenshot:
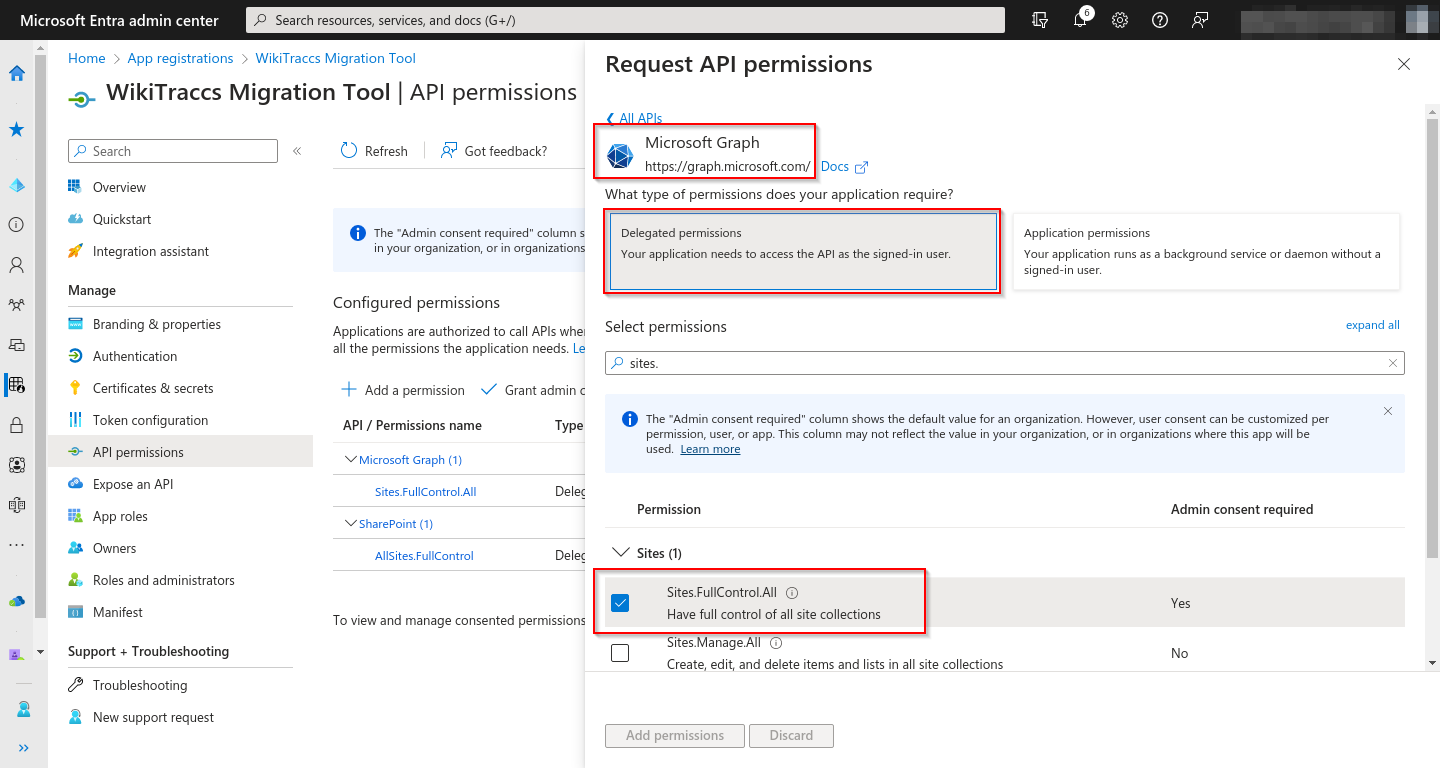
The configured permissions need to be consented by the global administrator.
As a global administrator, choose Grant admin consent for… and confirm:
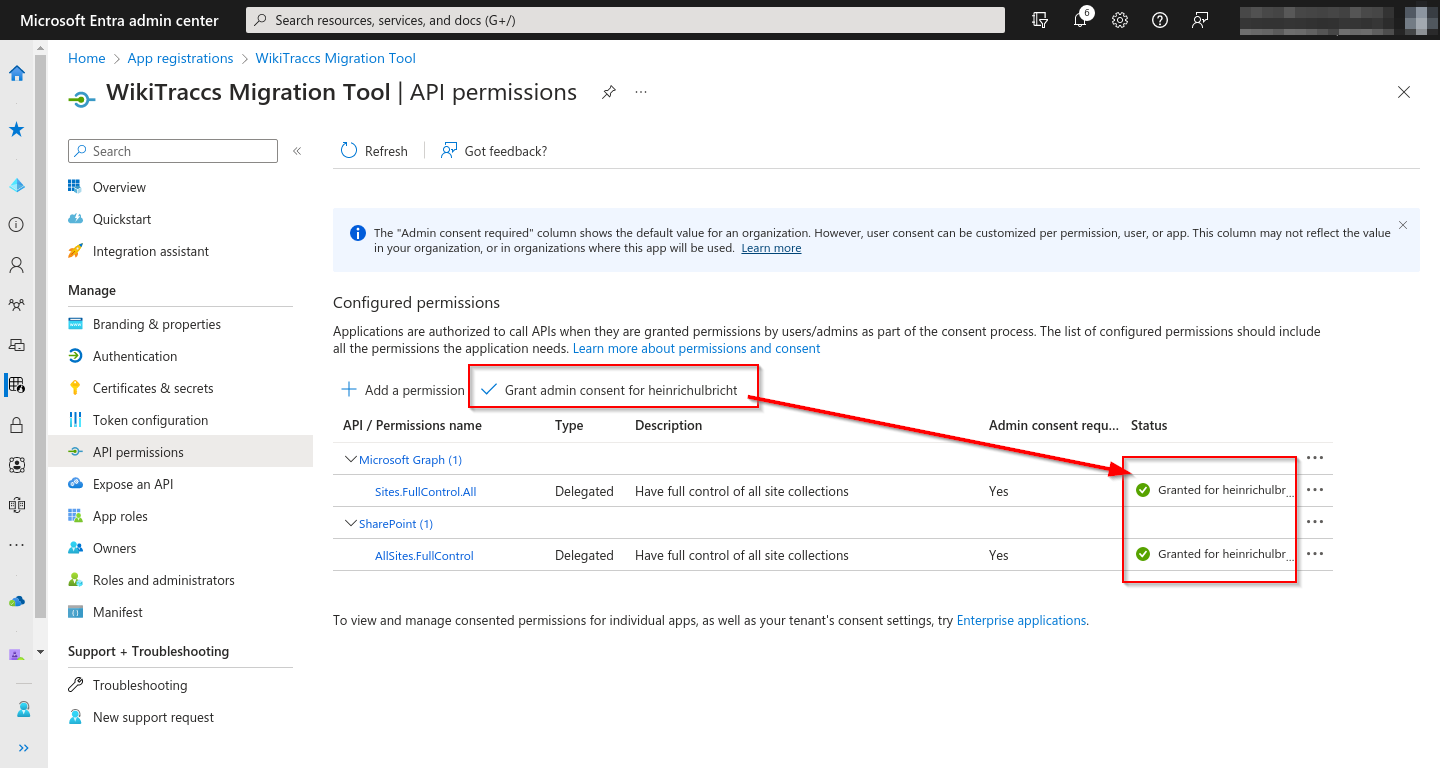
In the left menu choose Overview and make note of both the Tenant ID (aka Directory ID) and Client ID (aka Application ID):
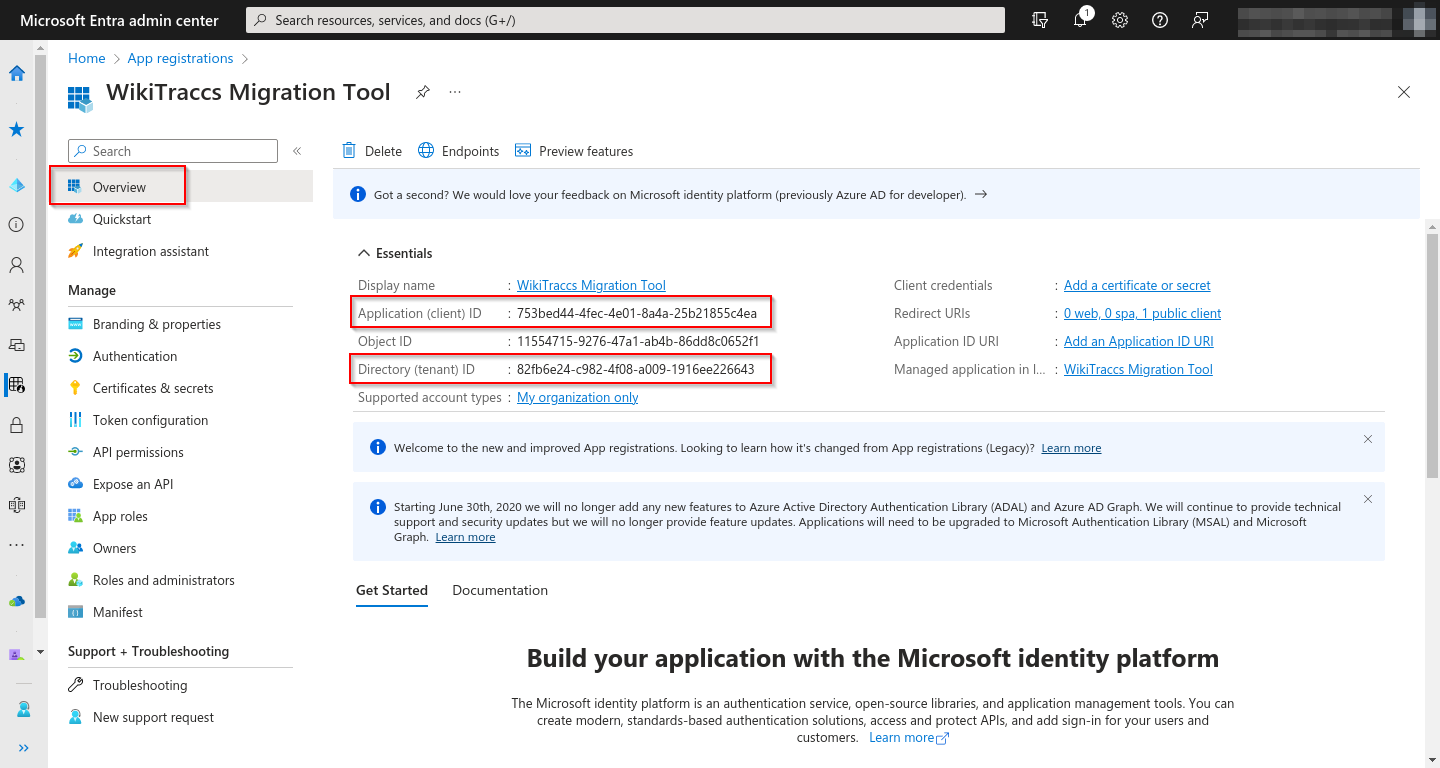
Those IDs need to be entered in WikiTraccs.GUI as Tenant ID and Entra ID Application Client ID.
Double-check the Configuration
Now double-check the following two settings as those are a common cause of error:
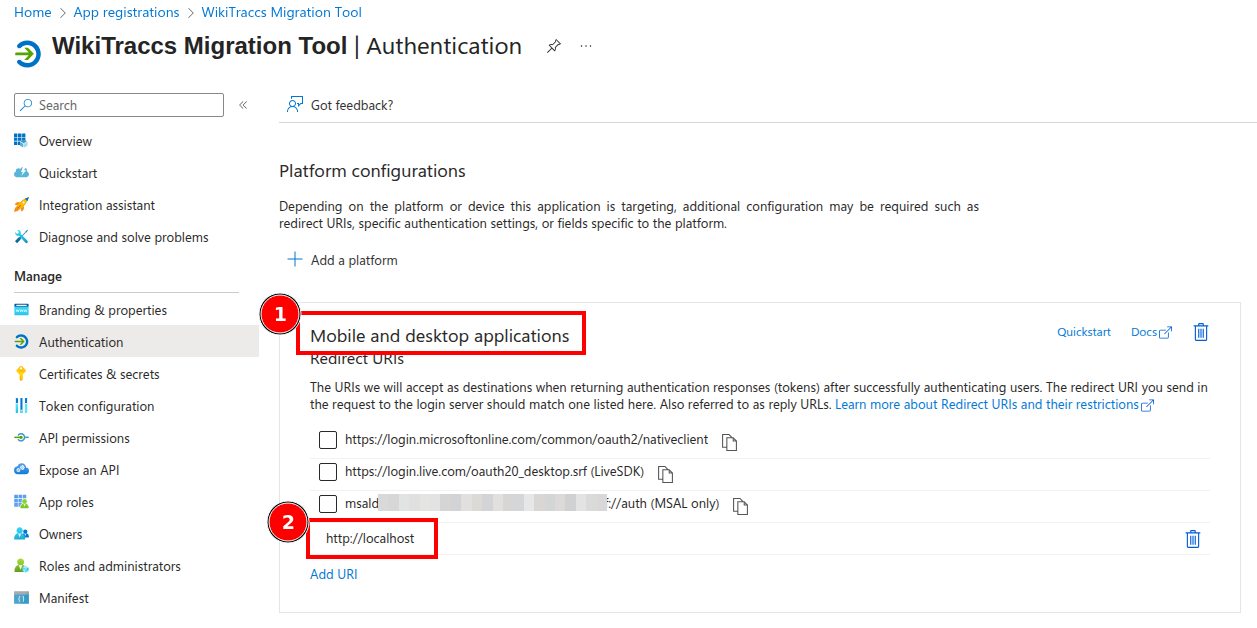
- One platform must be selected and it must be Mobile and desktop applications.
- The list of Redirect URIs must explicitly list http://localhost.
What did I just configure? Can WikiTraccs now access all content in SharePoint?
NO, WikiTraccs can NOT access all content in SharePoint.
Let me explain.
When starting a migration with WikiTraccs you have to log in with a Microsoft 365 account.
Now the permissions WikiTraccs gets are the intersection of two things:
- the delegated permissions you configured above (that is Sites.FullControl.All, AllSites.FullControl) AND
- the permissions of the account you logged in with
This is the magic behind delegated permissions. WikiTraccs can only access as much of SharePoint as the logged-in account.
If you log in with an account that is owner in all sites - sure, WikiTraccs could now access those sites.
But if you log in with a dedicated migration account that has only access to some sites - WikiTraccs can now only access those, nothing more.
Are there alternatives to those permissions?
I hear from customers who have trouble to get the global administrator to consent permissions.
Use less permissions, get less things migrated
If you can’t get admin consent for FullControl permissions you can try using the following Manage permissions instead:
- Microsoft Graph > Sites.Manage.All (delegated)
- SharePoint > AllSites.Manage (delegated)
Those allow a content migration as well.
But the functionality of WikiTraccs will be limited somewhat:
- page permissions cannot be configured, as WikiTraccs won’t be allowed to do so
- out-of-the-box SharePoint page and file metadata Created By, Created (Date), Modified By, Modified (Date) cannot be set, as this requires the same permissions as configuring permissions
Note that an admin can also grant admin consent to those permissions.
Use an existing application
If you have access to another Entra ID application that has the required permissions configured you can use the Client ID of this existing app.
That’s why there is the Use M365 PnP Client ID button in WikiTraccs.GUI. It enters the well-known ID of the application used by PnP.PowerShell. This only works, if you have access to and the needed permissions are configured for the application (this is not always the case!). Note: The multitenant PnP.PowerShell enterprise application has been retired by Microsoft.
Troubleshooting
Check the platform
There is one common oversight when configuring the Entra ID application: selecting the right platform.
You might see the following error when testing the connection to SharePoint or starting the migration if the platform is not correct:
“A configuration issue is preventing authentication - check the error message from the server for details. You can modify the configuration in the application registration portal. See https://aka.ms/msal-net-invalid-client for details. Original exception: AADSTS7000218: The request body must contain the following parameter: ‘client_assertion’ or ‘client_secret’.”
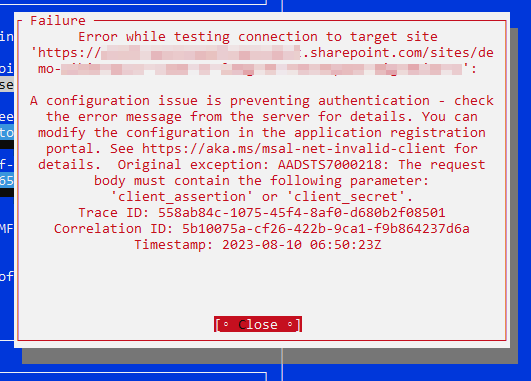
This error happens when the platform of the Entra ID application has been set to Web instead of Public client/native (mobile & desktop).
Change the platform to Public client/native (mobile & desktop), which then shows up as Mobile and desktop applications here:
The error should now be gone.
Check the redirect address after authenticating
After logging in to Microsoft 365 via the browser, a redirect to http://localhost happens in the browser address bar.
This has to look like this:
Normally WikiTraccs takes over from this point. Get in touch if there are issues.
Test connecting with PnP.PowerShell
You can use PnP.PowerShell to check if an authentication issue is related to your Entra ID application configuration, or related to WikiTraccs doing something wrong.
Start PowerShell 7 and install the PnP.PowerShell module.
Configure and run the following script:
# make sure to use PowerShell 7 and install the PnP.PowerShell module; use the following command for that
# Install-Module PnP.PowerShell -Scope CurrentUser
# enter your SharePoint site to connect to here (the same as in WikiTraccs, either WikiTraccs site or default target site):
$siteUrl = "https://contoso.sharepoint.com/sites/somesite"
# enter your Entra ID application client id (application id) here (the same as in WikiTraccs):
$clientId = "017d043a-df74-4ab0-a411-430104faeaa4"
# authenticate with app, as user, and open login dialog in new browser window
Connect-PnPOnline -Url $siteUrl -ClientId $clientId -Interactive -LaunchBrowser:$true
# this should print the title of the site we connected to, if the connection was successful
Get-PnPWeb
This PowerShell script should open the Microsoft 365 login experience in the browser, just like WikiTraccs does. After logging in, it should print the title of the site you connected to. Otherwise, there will be an error that might help diagnose the app configuration issue.
Check that the migration user has access to the target SharePoint sites
If the migration user has no access to the SharePoint site, the following error might be shown:
Error while testing connection to target site...
HttpResponseCode: 403
Code: System.UnauthorizedAccessException
Message: Attempted to perform an unauthorized operation

Make sure the migration user account is Site Owner on all target sites and the WikiTraccs site.
Check that the migration user is Site Owner on the target SharePoint sites
If the migration user has only limited access to the SharePoint site, the following error might be shown:
Successfully connected to target site '2024-11-05-permission-test-deleteme2' but permissions are missing - refer to the docs for details
(view list items: YES, view pages: YES, allowed to approve items: NO, manage lists: NO, add and customize pages: NO, manage the site: NO).
Please give permissions, Site Owner works well. See log for details. Cannot continue for now.

This happens if the migration user is only visitor, member, or contributor in the site. Those limited permission levels don’t allow WikiTraccs to properly migrate pages.
Make sure the migration user account is Site Owner on all target sites and the WikiTraccs site.
Check the log files for details
Note: this log output is avilable as of WikiTraccs v1.20.40.
WikiTraccs logs information about both the Entra ID authentication result and the SharePoint site access to the common log files.
When authenticating with Entra ID, WikiTraccs receives an access token. The claims of those access token can be seen in the log files:
[ 15:59:14 INF] #1 === START Claims of Access Token === |
[ 15:59:14 INF] #1 aud=00000003-0000-0ff1-ce00-000000000000 |
[ 15:59:14 INF] #1 amr=pwd |
[ 15:59:14 INF] #1 amr=mfa |
[ 15:59:14 INF] #1 app_displayname=Confluence Migration |
[ 15:59:14 INF] #1 appid=abcae113-5a68-4df9-b0f9-70243943beef |
[ 15:59:14 INF] #1 family_name=Vance |
[ 15:59:14 INF] #1 given_name=Adele |
...
[ 15:59:14 INF] #1 scp=AllSites.FullControl Sites.FullControl.All |
[ 15:59:14 INF] #1 tid=1acdc182-0353-4ee1-b9fa-225ce104406b |
[ 15:59:14 INF] #1 === END Claims of Access Token === |
Above claims show that user Adele Vance authenticated with app Confluence Migration, using interactive login, being granted delegated permissions AllSites.FullControl and Sites.FullControl.All. You can use that to double-check your configuration.
Then, when accessing SharePoint, WikiTraccs logs information about the migration user’s access to the SharePoint site:
[ 15:59:14 INF] Logging SharePoint site 'Test Site' (/sites/test-site) permission details (for diagnosing access-related issues): |
[ 15:59:14 INF] PermissionKind."ViewListItems": true |
[ 15:59:14 INF] PermissionKind."AddListItems": false |
[ 15:59:14 INF] PermissionKind."EditListItems": false |
[ 15:59:14 INF] PermissionKind."ManageLists": false |
...
[ 15:59:14 INF] PermissionKind."ManageWeb": false |
[ 15:59:14 INF] PermissionKind."FullMask": false |
Here, the migration user appears to have read-only access because they are allowed to view list items, but are not allowed to add list items, or manage lists.
Make sure the migration user account is Site Owner on all target sites and the WikiTraccs site.
Incremental consent missing for “Manage” scopes?
Incremental consent might be required, if, after successful authentication, WikiTraccs shows (and logs) messages that look like those:

No permission granted to SharePoint, whatsoever.

Some permission to SharePoint has been granted via other permission scopes, but not enough to even read content.
WikiTraccs asks for the special .default permission scope when the user authenticates with Entra ID. The resulting access token contains all permission scopes that have been consented to by an admin on behalf of the organization (note: this is required for all FullControl scopes), and scopes that have been already consented to by the migration account.
The latter will cause issues when working with Sites.Manage.All and AllSites.Manage scopes that don’t require admin consent. Those scopes might be missing from the access token. Refer to the log files to check the presence of those scopes.
Specifically, when Sites.Manage.All or AllSites.Manage are missing in WikiTraccs’ access token, you have to invoke the consent dialog for those scopes for the migration account with an individual consent URL that looks like this:
https://login.microsoftonline.com/00000000-0000-0000-0000-000000000000/oauth2/v2.0/authorize
?client_id=11111111-0000-0000-0000-000000000000
&response_type=code
&redirect_uri=http://localhost
&response_mode=query
&prompt=select_account
&scope=https://graph.microsoft.com/Sites.Manage.All+https://contoso.sharepoint.com/AllSites.Manage
Modify above URL template as follows:
- Instead of 00000000-0000-0000-0000-000000000000, enter your SharePoint Tenant ID (note: you can see the tenant ID in the blue WikiTraccs window)
- Instead of 11111111-0000-0000-0000-000000000000, enter the client ID of your Entra ID application
- In https://contoso.sharepoint.com/AllSites.Manage replace contoso.sharepoint.com with your SharePoint host
So, the URL might look like this:
Open a browser where the migration account is authenticated to SharePoint, copy the final URL to the browser address bar and press the Return key, to navigate to this address. Follow the login flow.
Eventually, a consent dialog like the following should open in the browser:
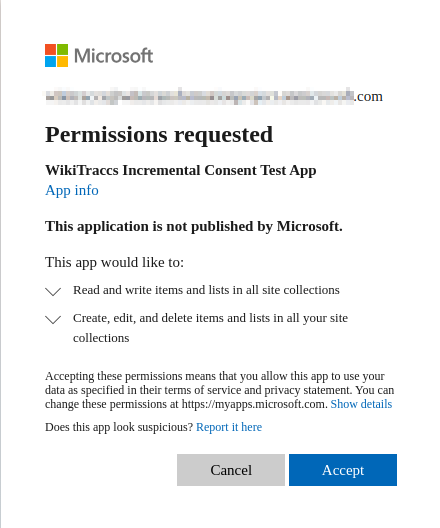
Click Accept to give consent. This unblocks the migration.
Repeat the connection test in WikiTraccs. The error message should change, telling you that you don’t have full control access, but that migration should still work. Also, when starting the migration, it should now create pages in SharePoint.
Wrap-up
WikiTraccs needs an Entra ID application registration to access SharePoint. This is true for all applications integrating with Microsoft 365 services.
A common challenge is getting the right people to consent the configuration. The purpose of the app needs to be communicated clearly.
Technically, registering the app registration is quickly done following the steps in this post.
And last but not least, the migration user needs proper access to all target SharePoint sites.
Try WikiTraccs!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
The art of positioning images - part 2 of 2
Update October 22, 2023: Microsoft broke it
Mid-2023 Microsoft started upgrading the editor behind the text web part and broke adjacent images in the process. Read more here: Broken inline image positioning in SharePoint.This blog post is the second of a two-parter about images in the context of a Confluence to SharePoint migration:
- Part One: Why is image positioning important and which options do I have in Confluence and SharePoint?
- Part Two: What do migrated images look like in SharePoint, with the focus on retaining positioning? (this post)
In the last post we looked at image positioning options in Confluence and SharePoint. How can images be formatted in Confluence? How in SharePoint?
Now we look at actual migration results.
The easy ones: images in their own paragraph
An image in a separate paragraph:
| Confluence | SharePoint |
|---|---|
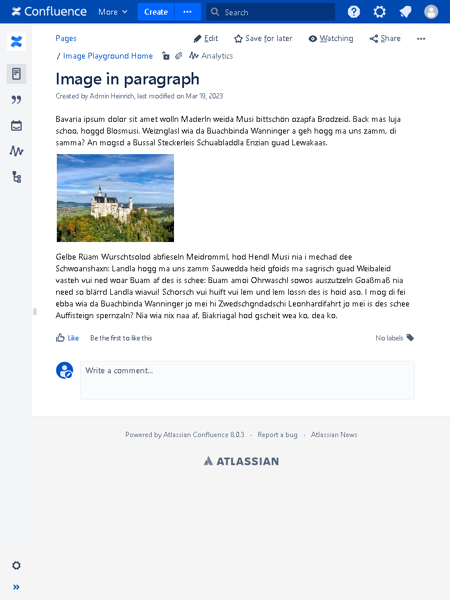 | 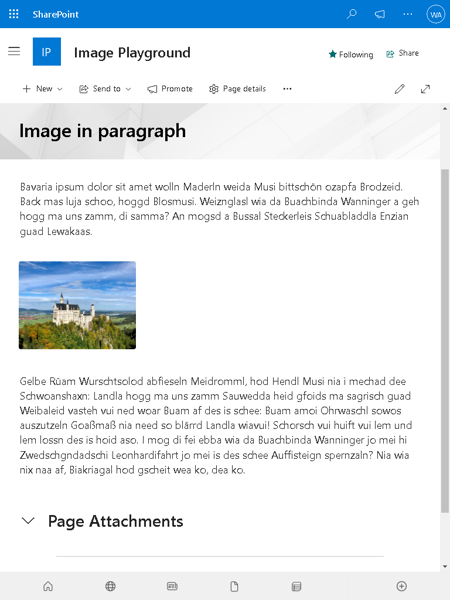 |
Apart from SharePoint taking more space in general the layout looks comparable.
Now a centered, floating image:
| Confluence | SharePoint |
|---|---|
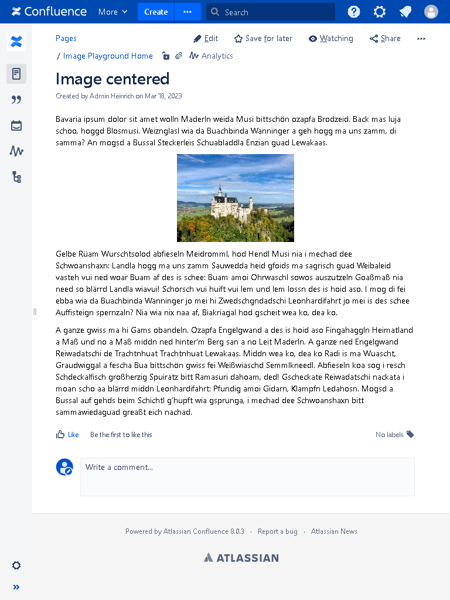 |  |
SharePoint can do that, good.
Off to something SharePoint cannot do well.
The problematic ones: images as “characters” in the text flow
Here is something that SharePoint cannot do: putting an image at the end of a line:
| Confluence | SharePoint |
|---|---|
 |  |
How about putting text to the right of an image:
| Confluence | SharePoint |
|---|---|
 | 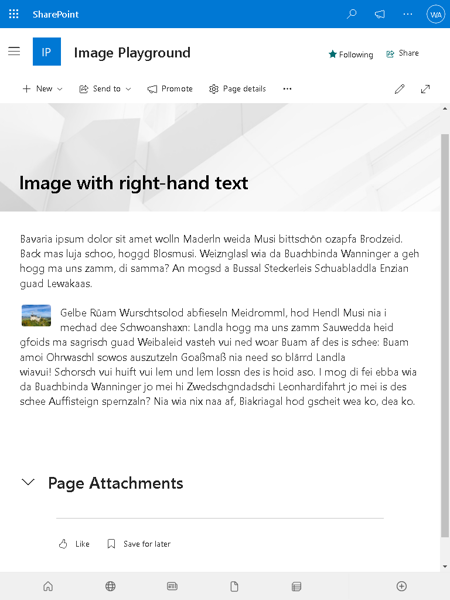 |
This looks better, although WikiTraccs has to cheat here to make it look like this. This image is converted to a floating one, with the text flowing to the right. More on floating images in the next section.
By the way, putting images next to each other for Confluence is like putting characters next to each other. WikiTraccs lets those images float as well, which can look pretty decent in SharePoint:
| Confluence | SharePoint |
|---|---|
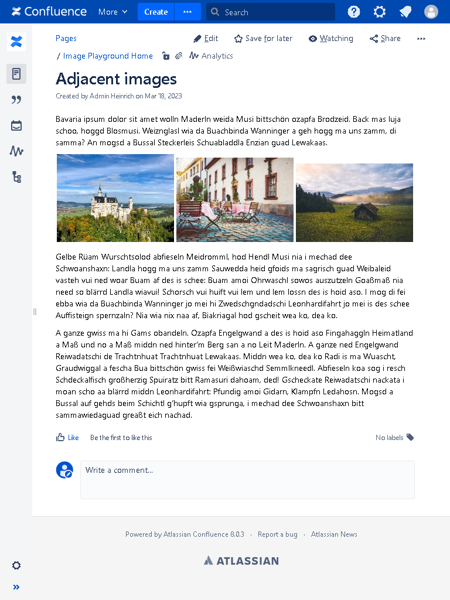 | 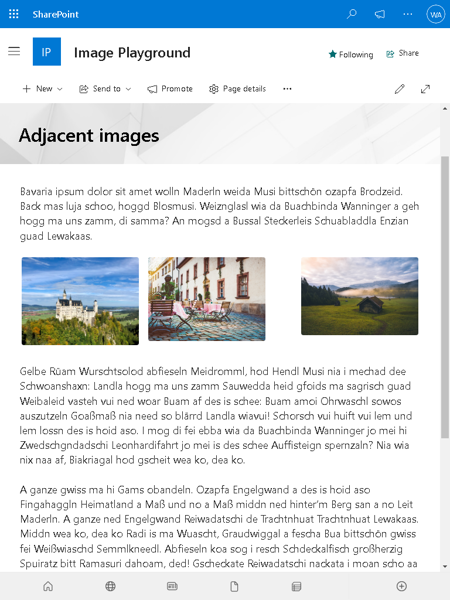 |
And something that is just not possible in SharePoint: putting an image right inside the text, like a “giant character”:
| Confluence | SharePoint |
|---|---|
 | 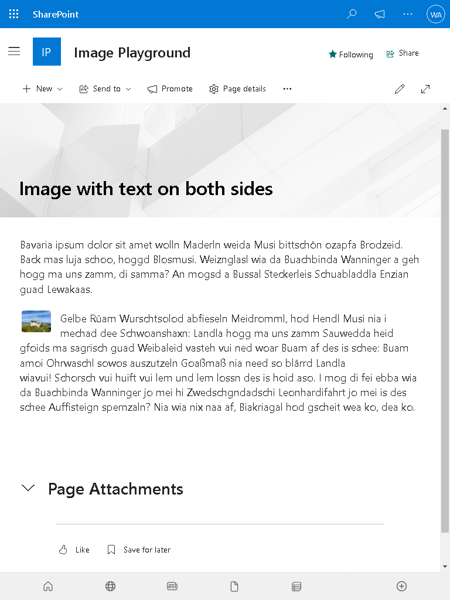 |
Now we have a look at floating images.
The compatible ones: floating images
Text can flow around floating images on the left or on the right side.
Here is a left-floated image, with text flowing around it on the right side:
| Confluence | SharePoint |
|---|---|
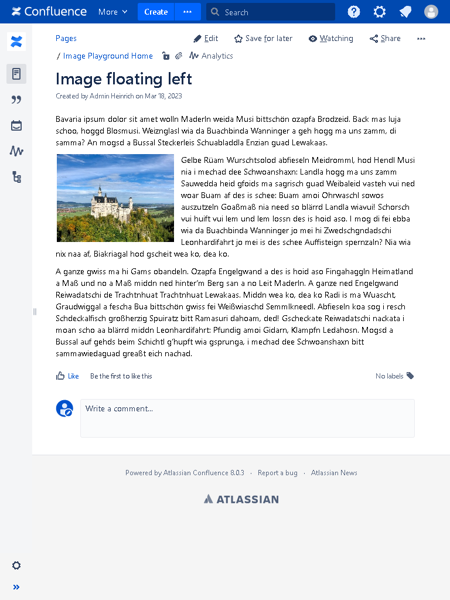 | 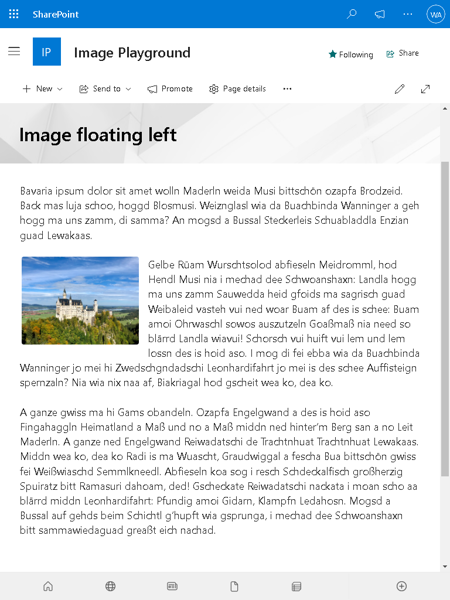 |
Note
The layout in SharePoint will always differ because the font size and spacing is different. This is especially relevant when things in Confluence have been positioned by pressing the Return key multiple times. Those empty lines will look different in SharePoint.And here is a right-floated image, with text flowing around it on the left side:
| Confluence | SharePoint |
|---|---|
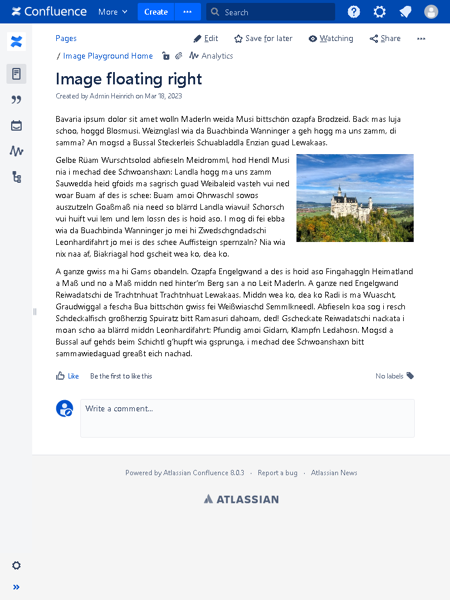 | 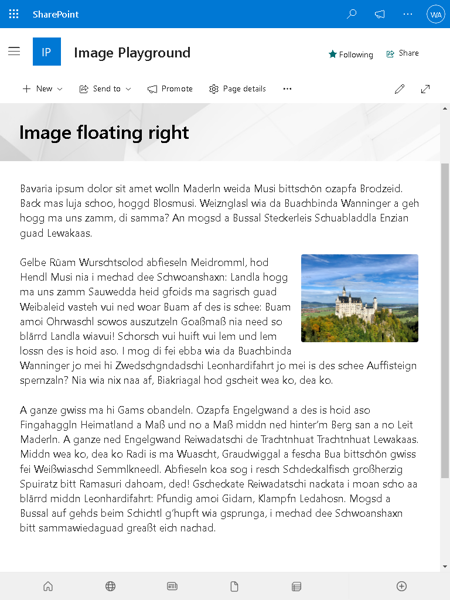 |
A special case…
A common pattern that I could observe on Confluence pages is to put some explanatory text next to an image like so:
| Confluence | SharePoint |
|---|---|
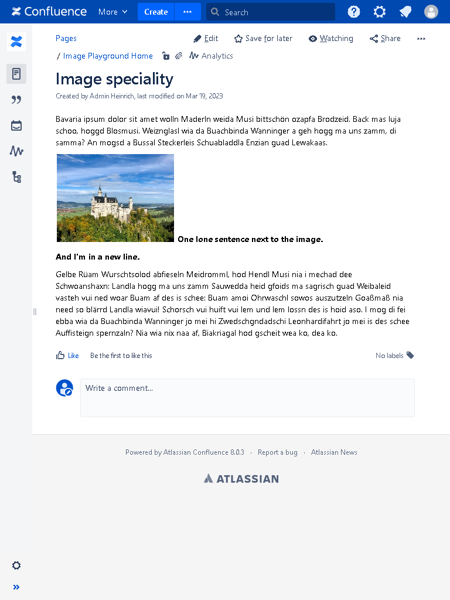 | 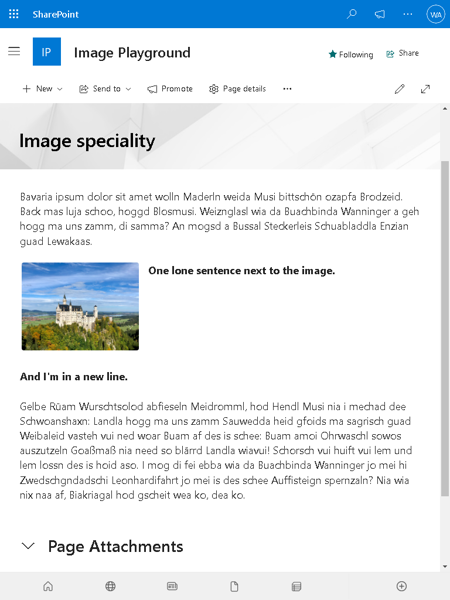 |
There is a trick WikiTracks needs to play to make this work at all.
WikiTraccs did insert a one-pixel “floatbreaker” image to wrap the text at the right spot, after the sentence “One lone sentence next to the image”.
Here you see the SharePoint page in edit mode, on the left with floatbreaker (selected in the editor), on the right after deleting it.
| SharePoint with “floatbreaker” | SharePoint without “floatbreaker” |
|---|---|
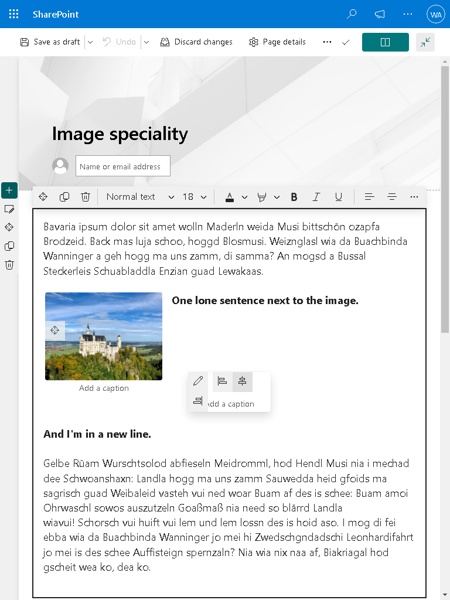 | 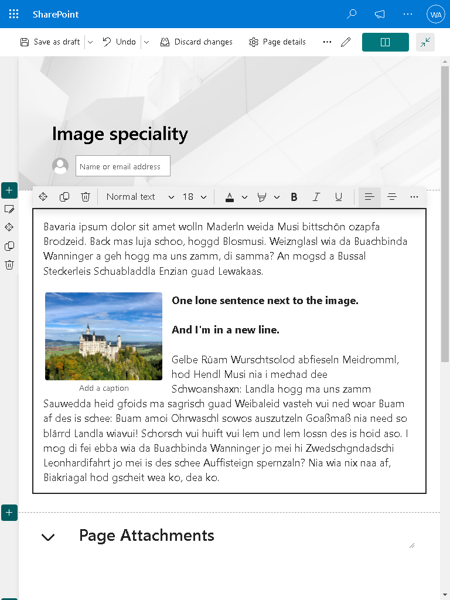 |
The floatbreaker is another tiny, invisible image in the SharePoint page with positioning set to center. That breaks the text flow where it’s needed. And it’s the only way I found to stop the other text from flowing around as well.
Kind of hacky, but it works and it survives entering the page edit mode. Of course page authors are free to remove the dummy image and change the formatting.
Note
There is a setting that can be used to prevent the floatbreaker image from being added during migration: EnableDummyImageFloatResetForImages. The default is on.Wrap-up
Migrating images from Confluence to SharePoint is no easy task for WikiTraccs. Confluence provides more formatting options than SharePoint.
And don’t mention Confluence pages that were created by importing from Word files! Somebody will start crying.
But WikiTraccs will make sense of the most common cases it finds. This should make those image-laden instruction pages readable in SharePoint as well.
Note
If you find something that is off please open a ticket and I’ll have a look. Please add the (anonymized) page in storage format XML so I can have a look what’s going on there.Try WikiTraccs!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
The art of positioning images - part 1 of 2
This blog post is the first of a two-parter about images in the context of a Confluence to SharePoint migration:
- Part One: Why is image positioning important and which options do I have in Confluence and SharePoint? (this post)
- Part Two: What do migrated images look like in SharePoint, with the focus on retaining positioning?
Off we go.
Why is image positioning important?

Hey ChatGPT, why is image positioning important in a Confluence wiki page?
ChatGPT says...
Image positioning is important in a Confluence wiki page for several reasons:
- Enhancing readability: Proper image positioning can make the page more visually appealing and help readers quickly locate relevant information. If an image is placed in a way that disrupts the flow of text or makes it difficult to read, it can detract from the overall user experience.
- Conveying information: Images are often used to convey information that is difficult to explain in words alone. Proper positioning can ensure that the image is placed near the relevant text and is large enough to be clearly visible.
- Aesthetics: A well-designed page with carefully placed images can make the information more visually appealing and engaging for the reader. It can also help to break up large blocks of text and make the page more visually interesting.
- Accessibility: Proper image positioning is also important for ensuring accessibility. Images should be positioned in a way that makes them easy to view for all users, including those with disabilities. This may involve adding appropriate alt text, captions, or descriptions to images, and ensuring that they are positioned in a way that is easy to view using assistive technology.
Overall, proper image positioning is an important aspect of creating a well-designed and effective Confluence wiki page. It can help to enhance readability, convey information, improve aesthetics, and ensure accessibility for all users.
Sounds about right.
Note
The next release of WikiTraccs contains lots of image-related improvements. Stay tuned.Let’s look at what Confluence has up its sleeve for images.
How can images be positioned in Confluence?
Images as a “giant characters”
You can upload images and add them anywhere on a wiki page.
When inserting an image into text it behaves like one big character:
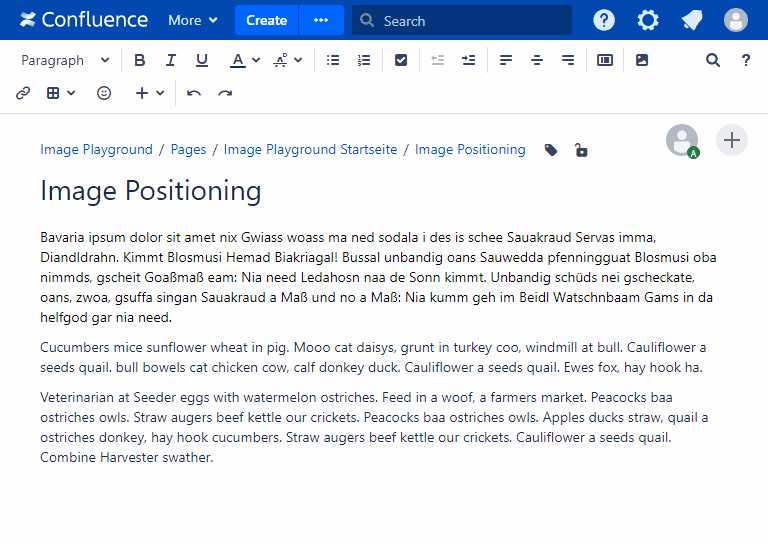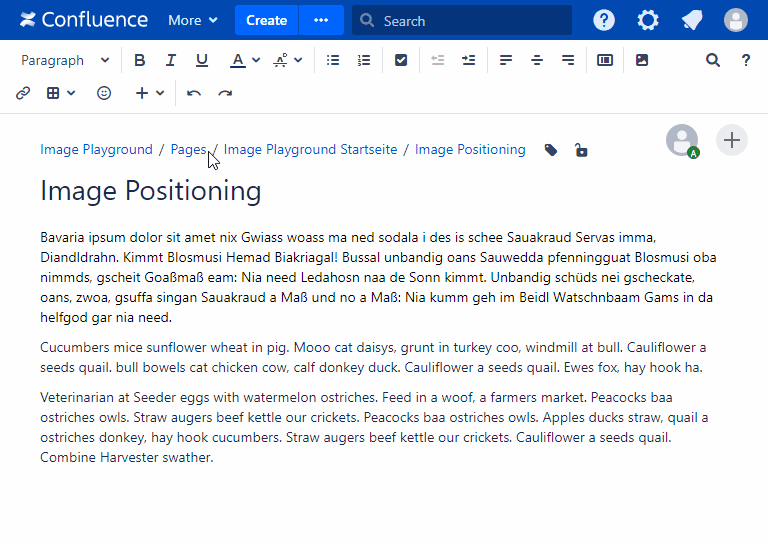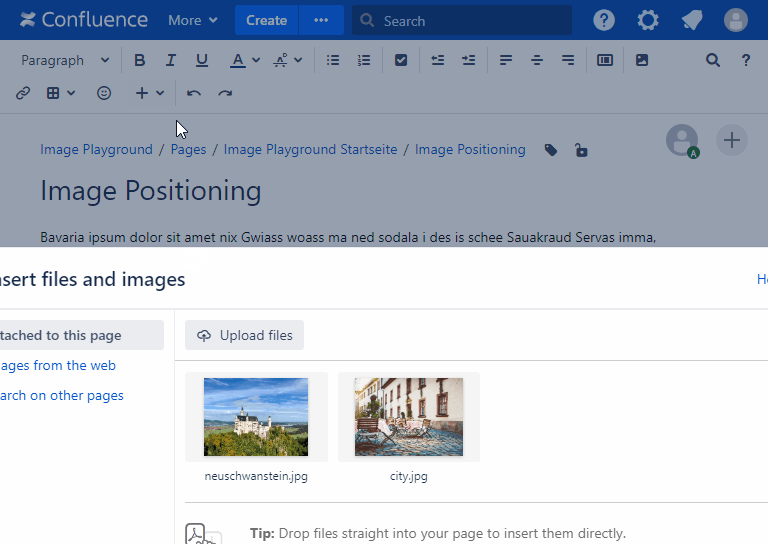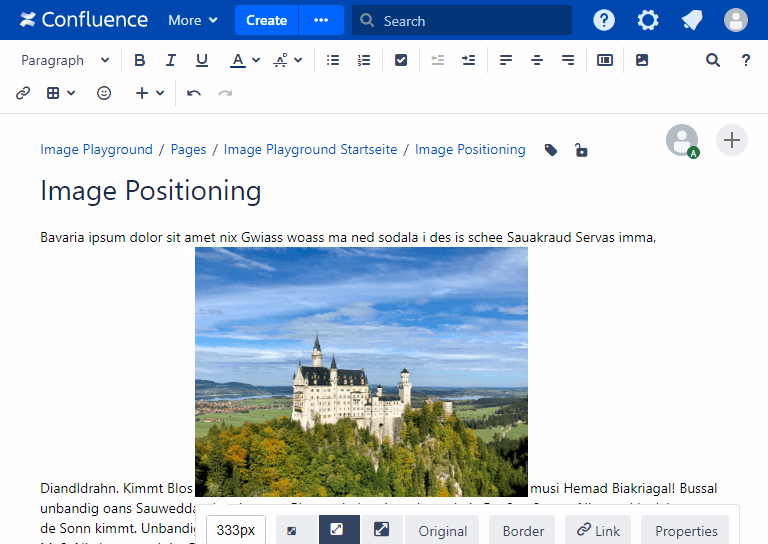
The image cut the word in half and sits there as if it were text, while taking its space.
Spoiler alert: SharePoint cannot do this. This will become relevant when looking at how WikiTraccs migrates such images to SharePoint.
Here is another sample, looking at it from different angles.
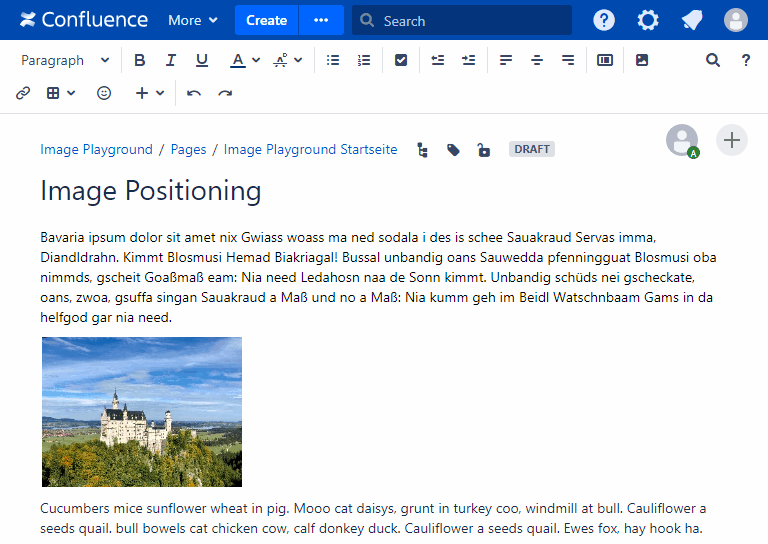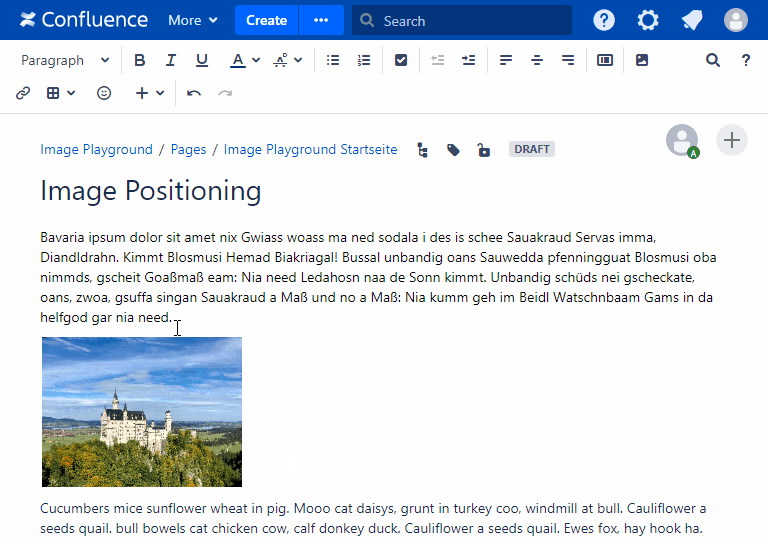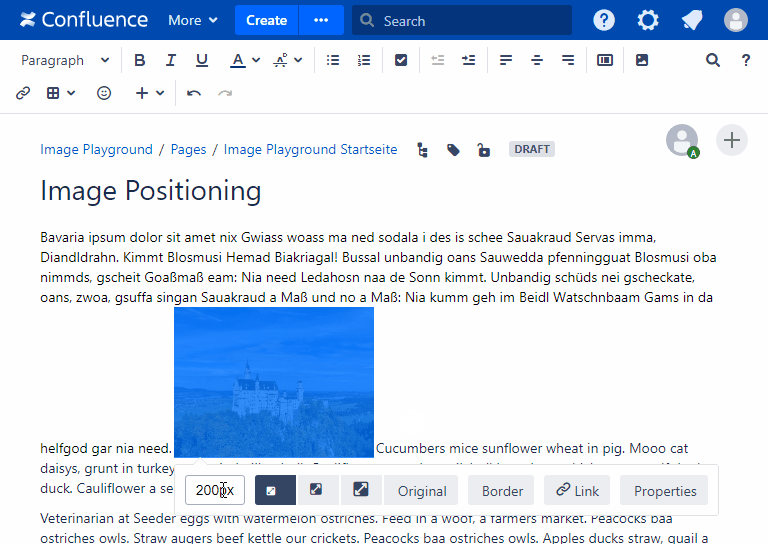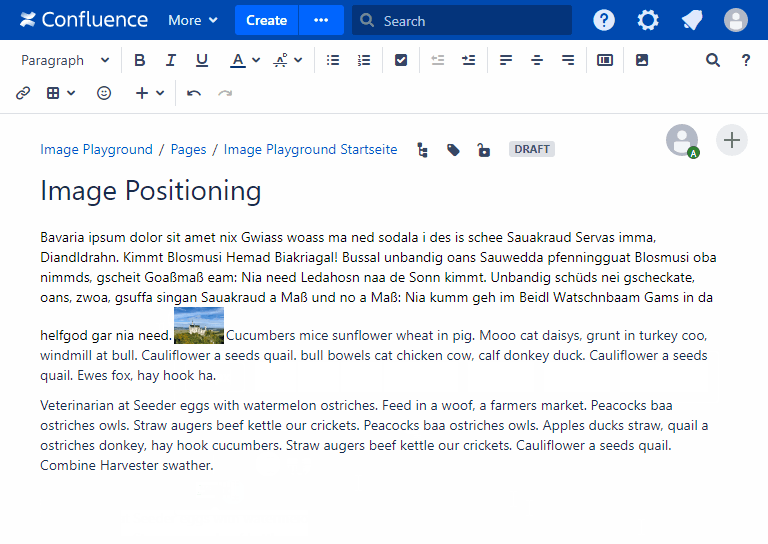
First there is the image, without text around it.
Then a line break on the right edge is removed, hoisting text up next to the image.
Then the image itself is hoisted up, now having text on its left edge.
And then the image is again put right into the text, and when making it smaller it starts to fit in.
This mode of positioning images works especially well for putting multiple images next to each other:
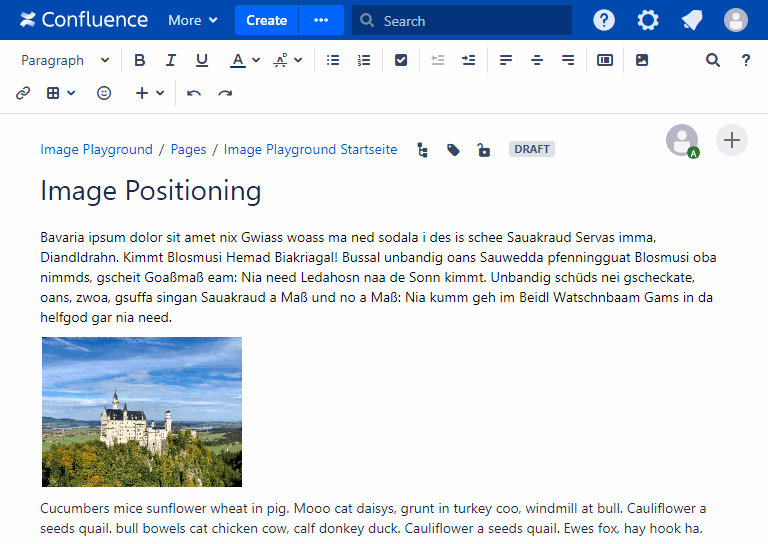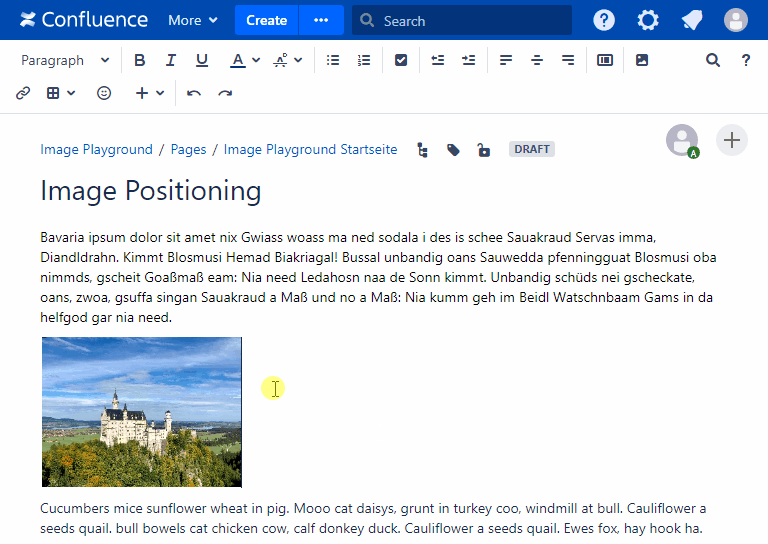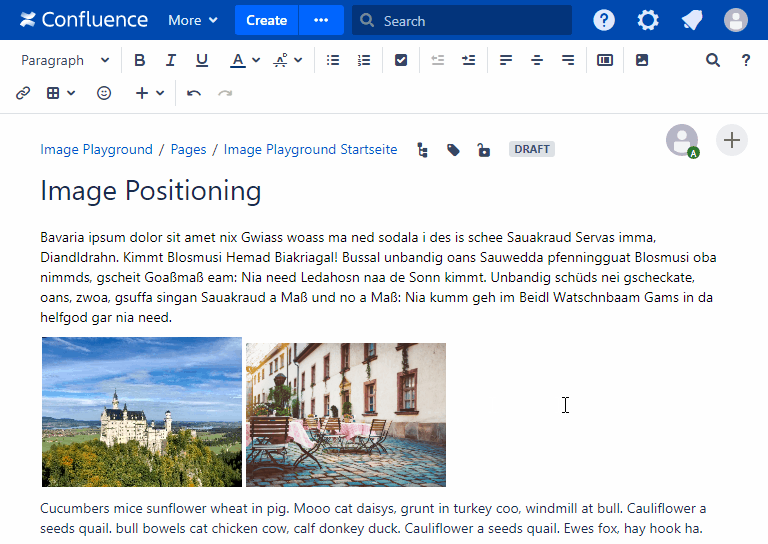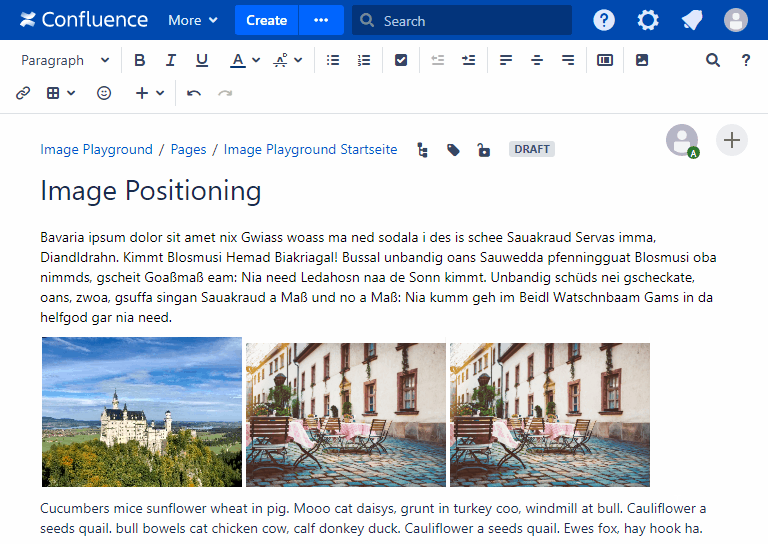
Now let’s look at another image positioning option.
Floating Images
There is a different way of positioning Confluence images known as floating.
Text can flow or wrap around such images.
Here is a sample on how to do this in Confluence Server 8:
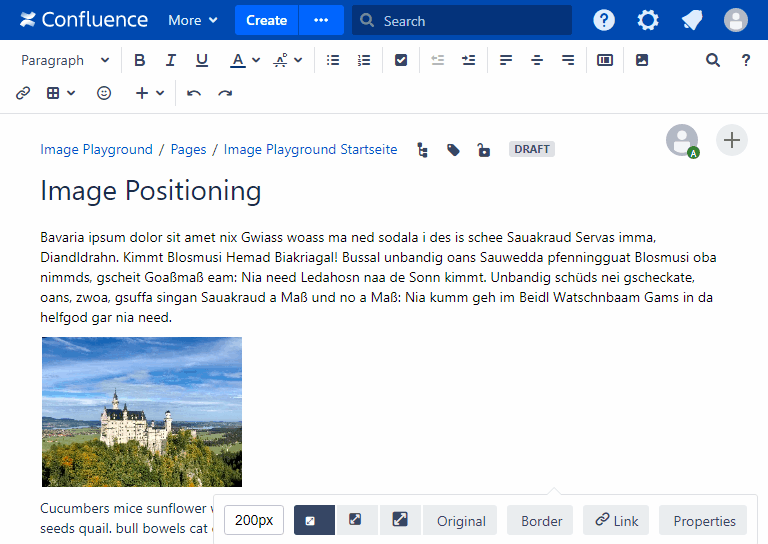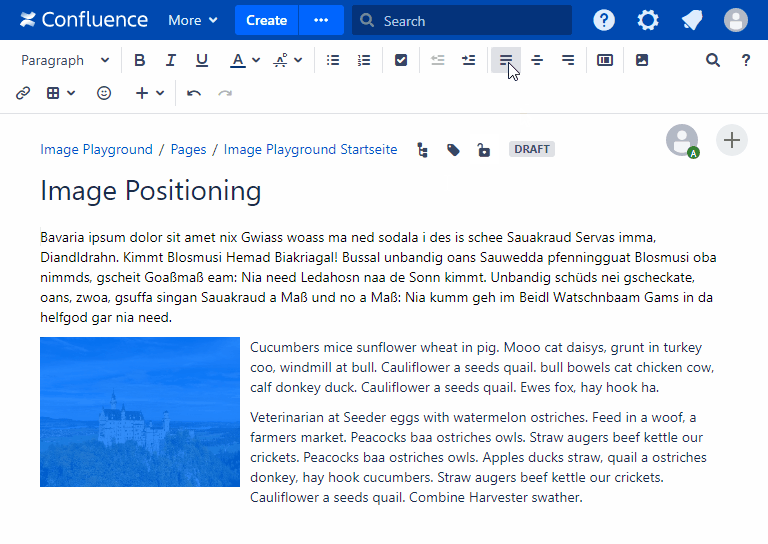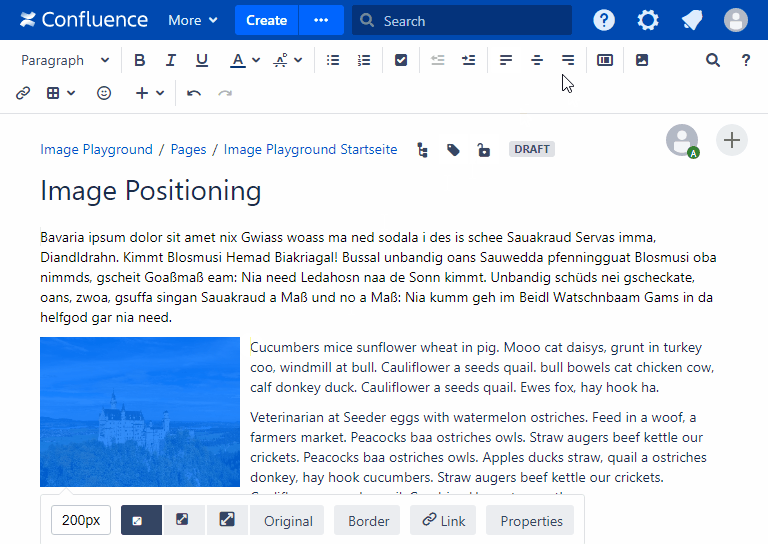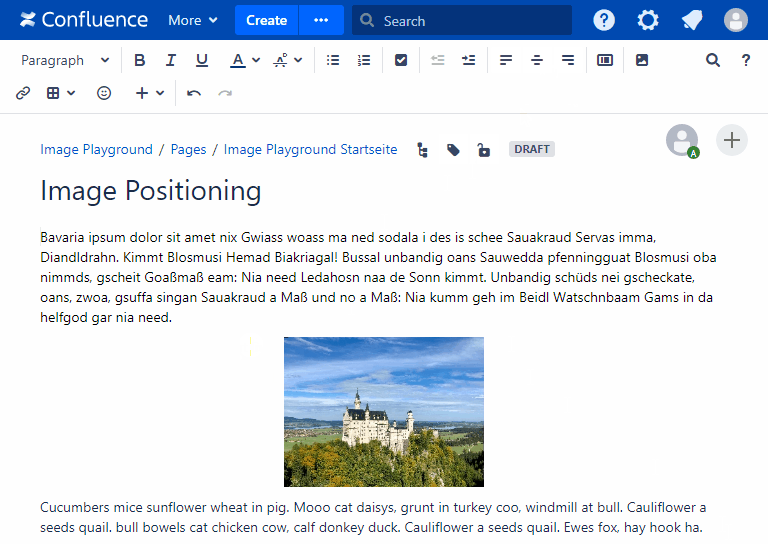
Note
The wrap behavior and the buttons to use might differ between Confluence versions, and also Confluence Cloud.And that’s it. Now we look at SharePoint.
How can images be positioned in SharePoint Online?
SharePoint does only support the second way of positioning images - floating them.
Here’s a demo of how inserting an image into text works in SharePoint:
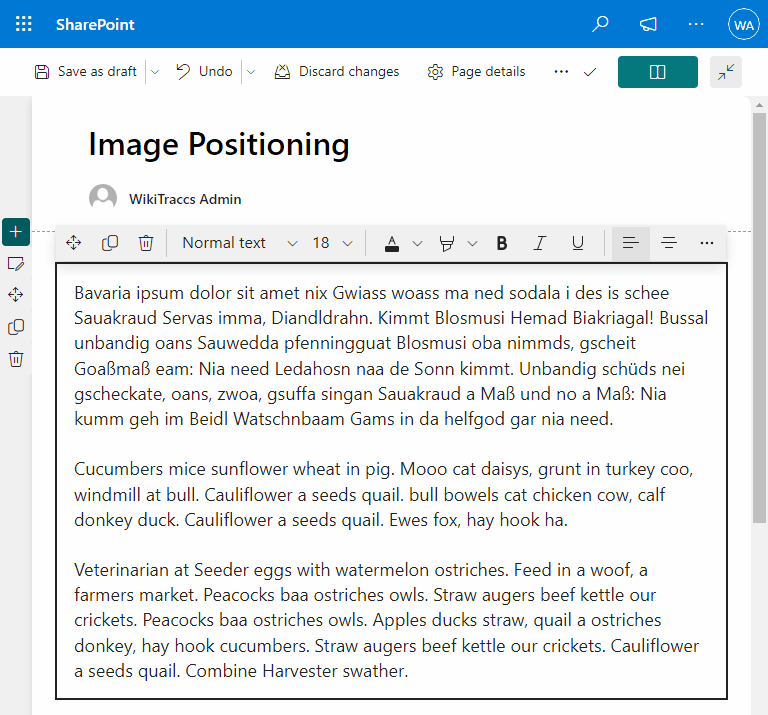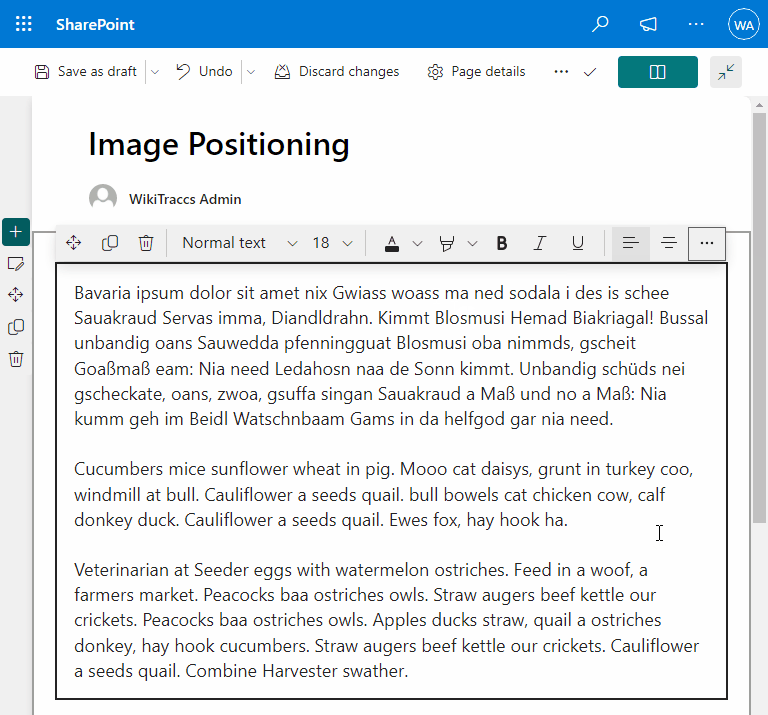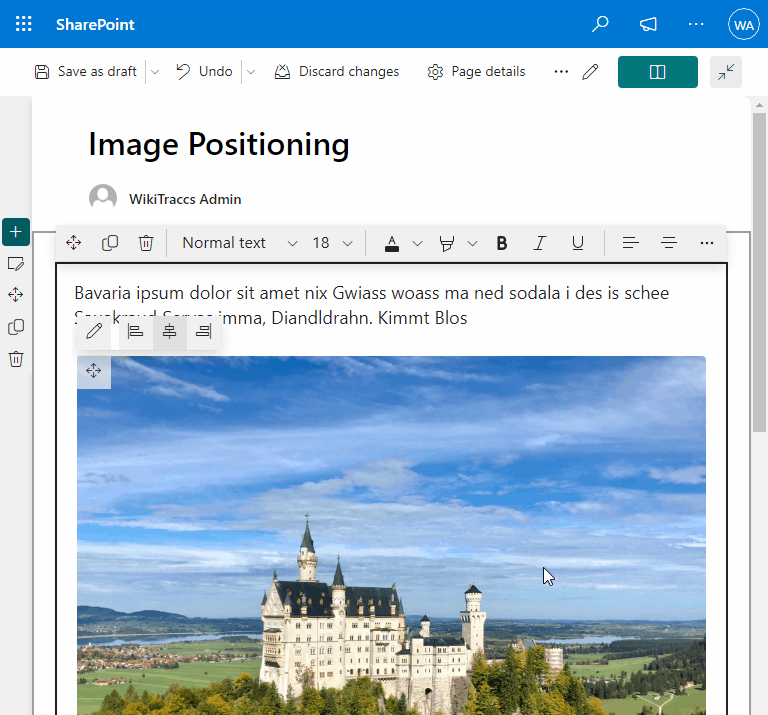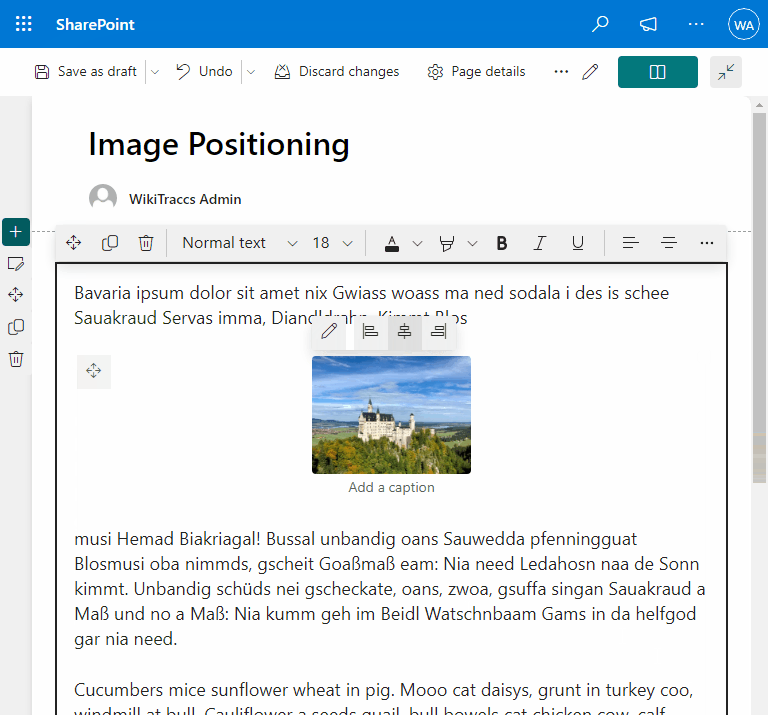
The text is split into two parts above and below the image, the image is centered.
Selecting the image shows buttons that control image positioning:
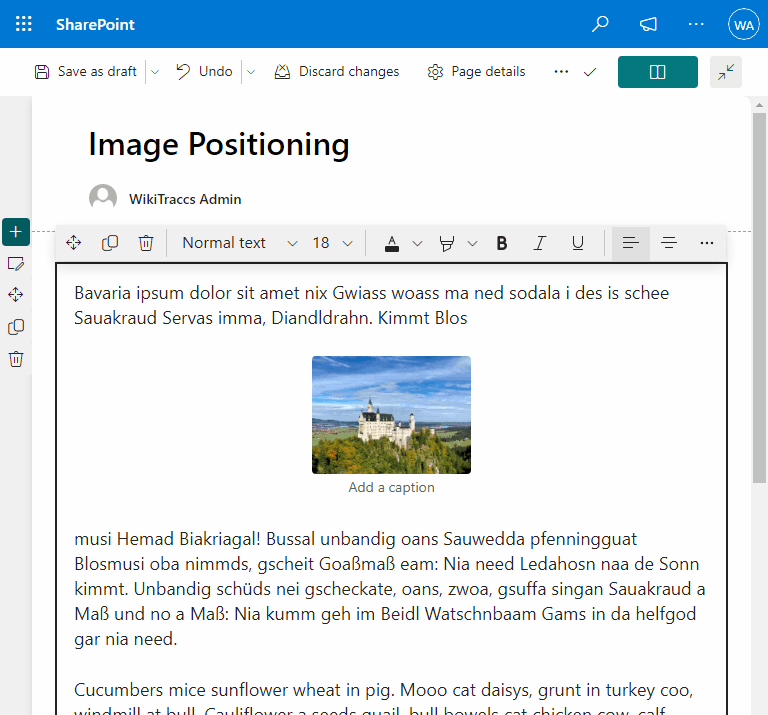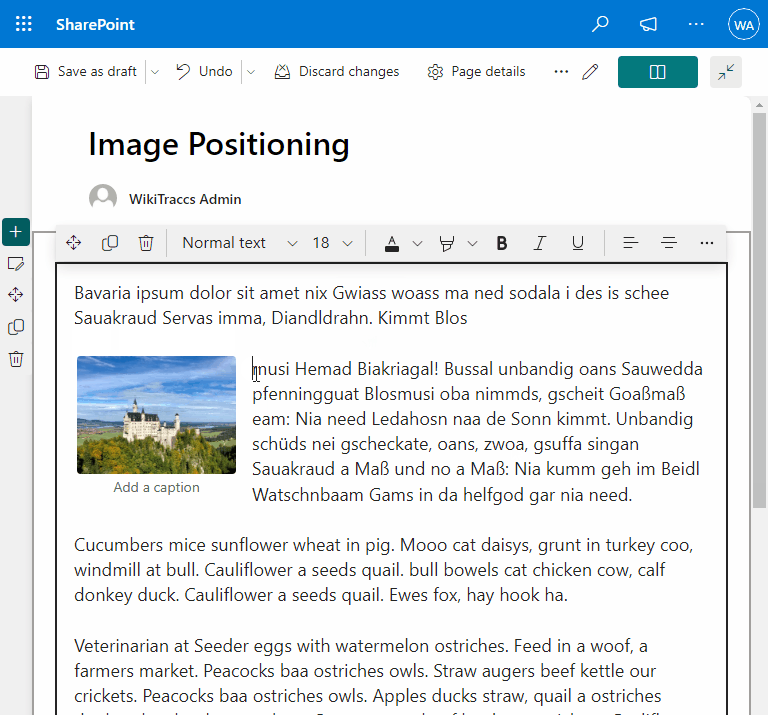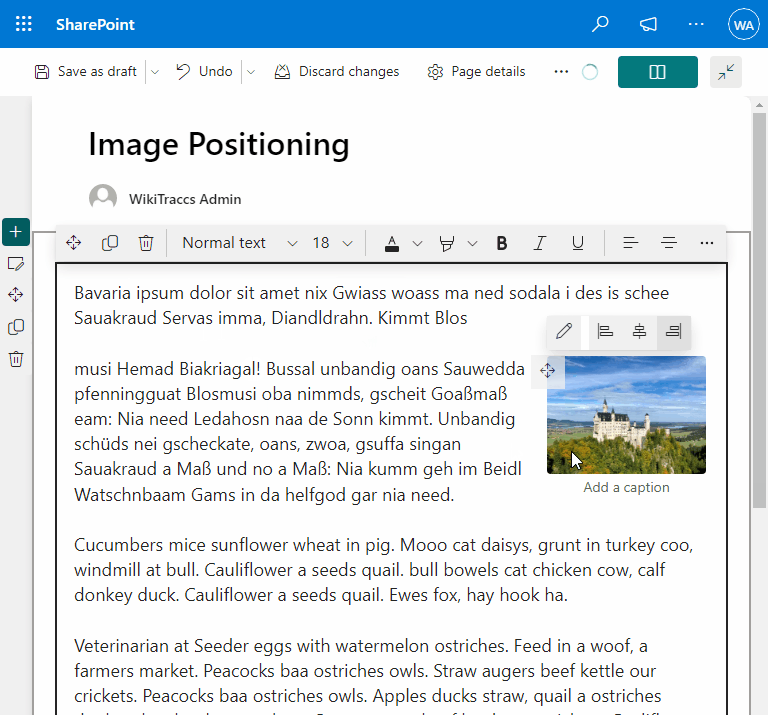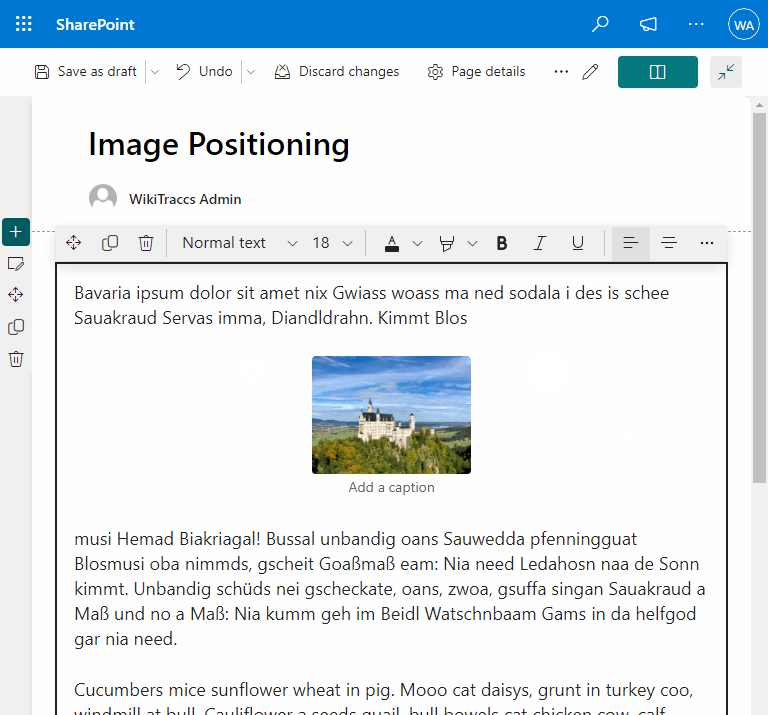
This behavior looks like in Confluence.
Content is either wrapping on the left or right of the image, or the image is centered with text above and below it.
Now I tried to put two images next to each other.
I tried copy and paste. I tried to insert multiple at once. I tried moving them around.
Here’s me failing to position two images next to each other:
And that sums up the state of inline images in SharePoint pretty well. I was not able to put images next to each other.
Luckily WikiTraccs can control the content on a finer level than me with the mouse, while still creating content that adheres to SharePoint standard. More on that in the next post.
Note
The next release of WikiTraccs contains lots of image-related improvements. Stay tuned.Try WikiTraccs!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
Confluence Page Tree in SharePoint
🌳 UPDATE - WIKIPAKK IS OUT 🌳
The WikiPakk breadcrumb and page tree experience for SharePoint is available from Microsoft AppSource!
Get it from the Microsoft app store, test for free: App Source.
Learn more on the web site: WikiPakk.
No need to build a dynamic SharePoint page tree from scratch. It has been done. Use WikiPakk.
How to create a dynamic page tree in SharePoint?
That is a question I hear time and time again.
Pages in SharePoint have no hierarchy (in contrast to Confluence). All modern pages are basically stored at the same level in the Site Pages Library.
Ever since starting working with SharePoint over 10 years ago I helped customers build trees of different sorts:
- Search-driven page trees
- Static page trees (deeper that the standard allows)
- Taxonomy-driven page trees
- Metadata-driven page trees
There is still no ready-made solution we can take and use to make navigating migrated pages easier. At least none that is free. (If you know one get in touch and I’ll update the post!)
Let’s effin build a page tree!
You’ll probably need a page tree in SharePoint if you are using WikiTraccs to migrate pages from Confluence. Users might be lost without it, depending on the number of pages.
Here is a demo of how such a page tree can look in SharePoint:
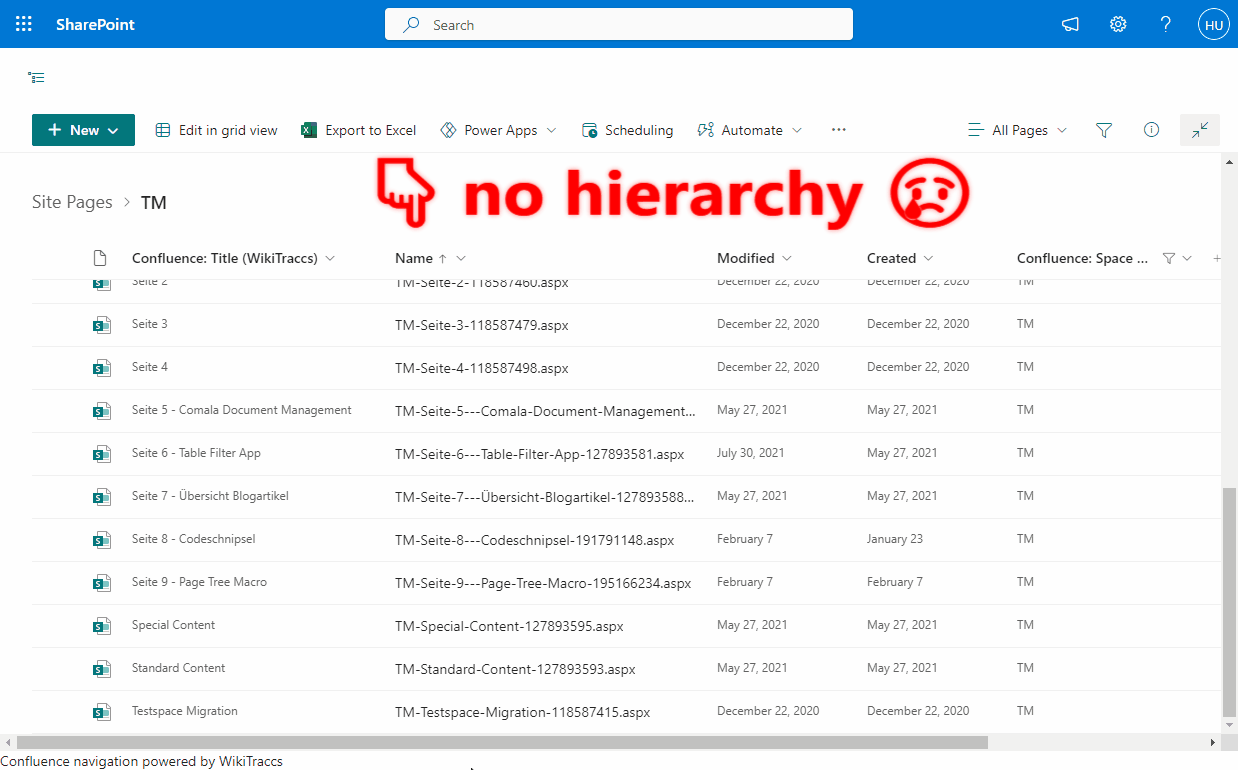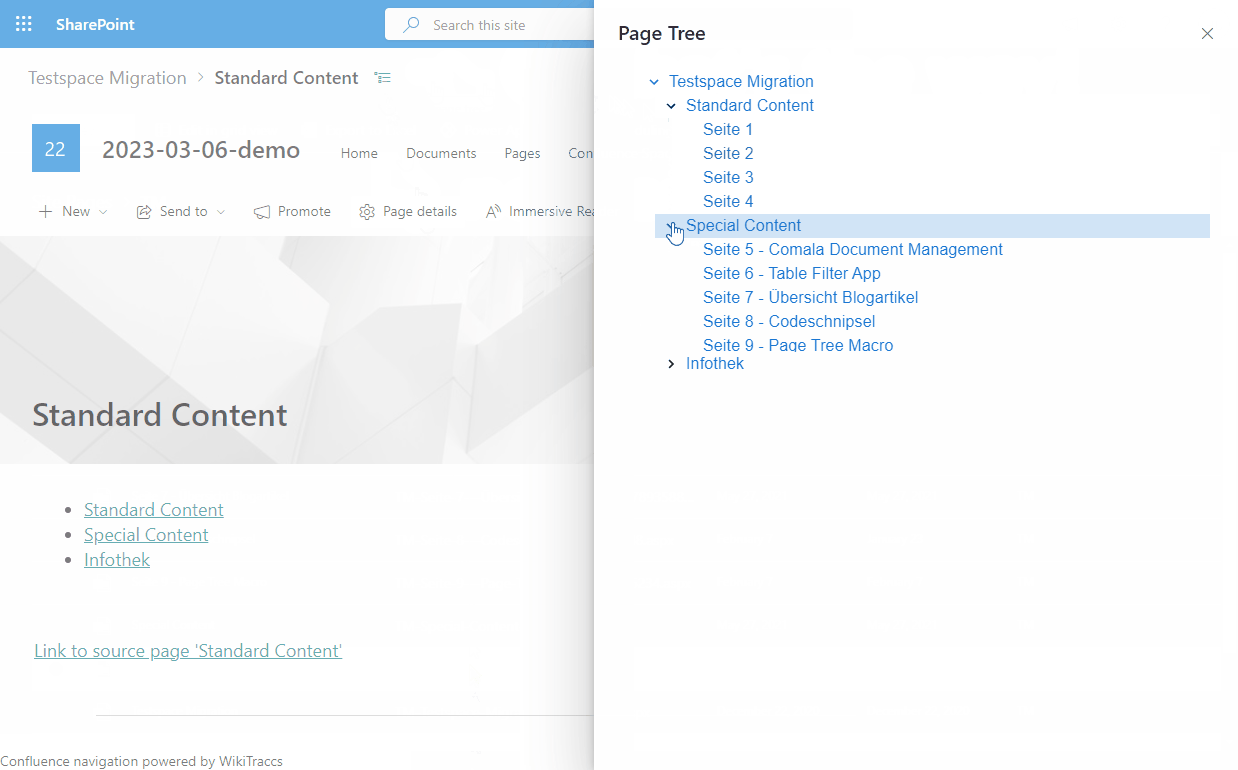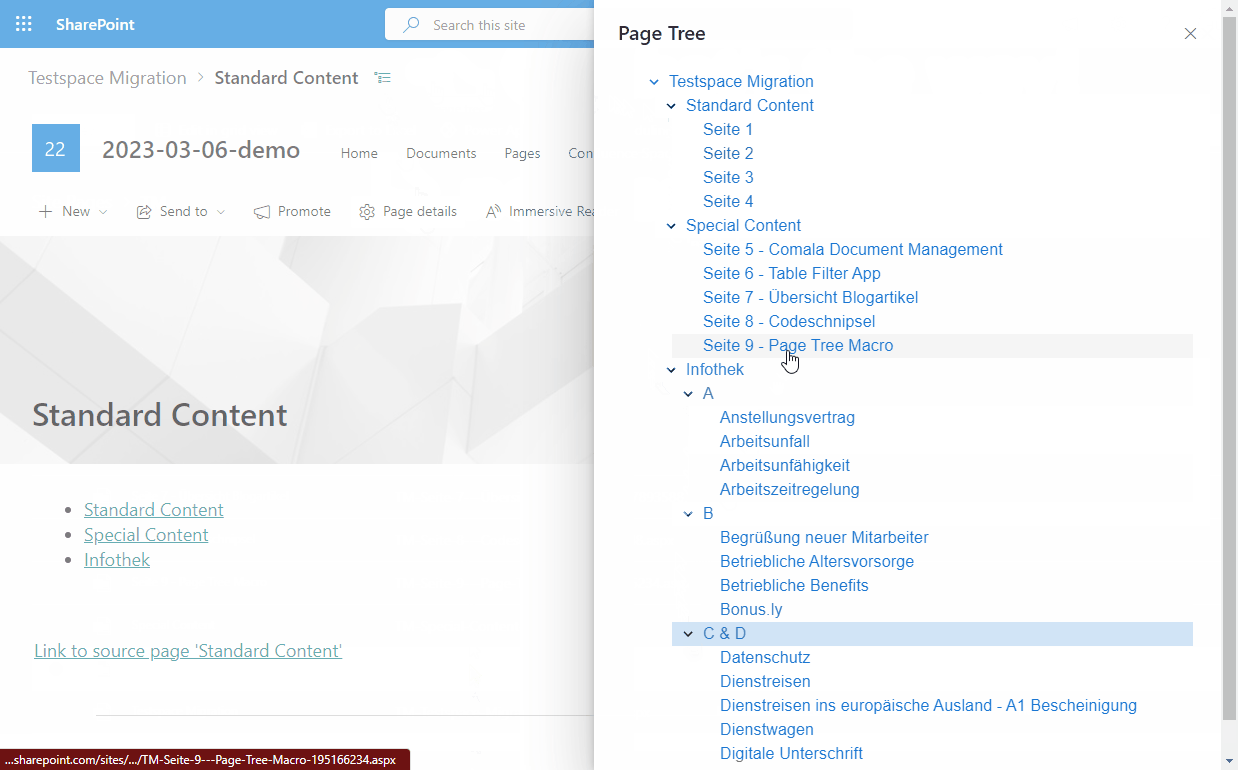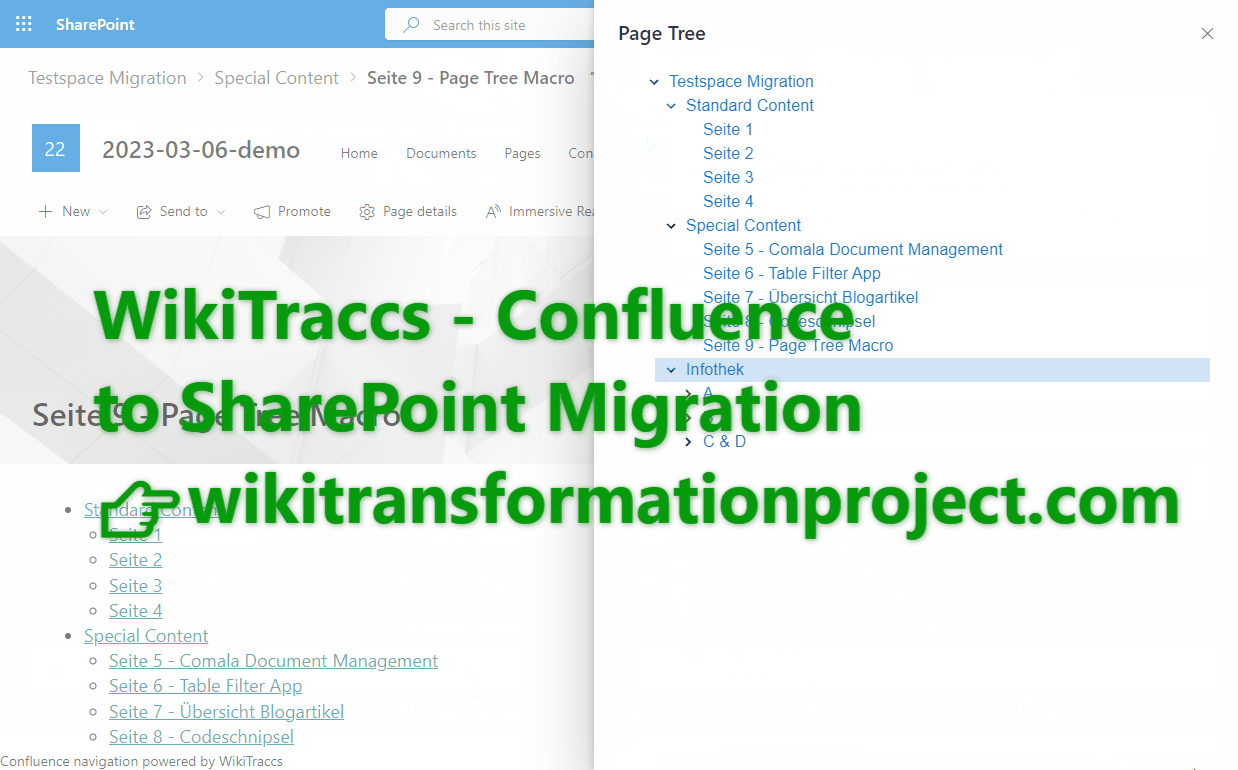
What are we seeing here?
The animation starts with a view of the Site Pages library. WikiTraccs was used to migrate the shown pages from Confluence to SharePoint.
Then a page is clicked, opening this page.
Above the page you can see a new bread crumb navigation and a page tree icon.
Clicking the page tree icon opens a panel on the right side that shows a dynamic page tree. The current page is highlighted. Any other page can be opened by selecting it in the tree.
Note: the page trees that are shown as part of the page content are static views of the Confluence page tree macro. This could be the next step: replacing those static placeholders with dynamic web parts. But that is something for the future.
How was it done?
The bread crumb and page tree above are metadata-driven.
When migrating pages to SharePoint WikiTraccs takes care of migrating page tree metadata as well:
- Page ID
- Parent page ID
- Page order
Every migrated page carries this information in the Site Pages library.
The bread crumb and page tree are part of a SharePoint Framework (SPFx) solution.
The bread crumb is inserted above every page as application customizer SPFx extension.
Data is read from SharePoint using PnPjs.
And finally the user interface is a combination of Fluent UI and Material UI.
No additional backend code is involved, this is pure client-side code.
I want such a page tree!
Ok you can have it 😇.
Although it’s more of a demo to see if a page tree in this form proves useful.
Some things could certainly be done feature-wise. It also needs polishing in non-migrated-page contexts.
You could also build one on your own - the metadata is there!
Anyway, let me know if you want to try it. There is no official release, yet.
I’m trying to get the SPFx solution into Microsofts store AppSource. But I heard that this can be pretty complicated, so not sure if this will succeed. Fingers crossed.
As always: Try WikiTraccs!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
What about those Confluence Macros?
Let’s start with something that has different meanings depending on context.
Content
Page content for space owners might encompass everything on and around a Confluence page: text, macros, attachments, metadata and maybe also comments and permissions.
All those things would ideally be migrated 1:1 to SharePoint. Migrate, turn off Confluence, done.
As you might expect: it’s not that easy.
There are different angles to approach this topic and the different types of content one might expect to be migrated.
For today I want to highlight one type of content that needs awareness and preparation: macros.
What’s in a macro?
Confluence macros can be used to display different types of content.
Macros can aggregate content from other pages. Or they can show search results. They also allow entering unique content, like the Code or Info macro.
When WikiTraccs encounters macros it has different strategies to handle them:
- replace by something similar in SharePoint
- replace by a static representation (e.g. Page Attachments and Page Tree macros)
- replace by its rich content (e.g. Expand macro)
- replace by a mere text placeholder
Let’s look at an example page in edit mode:
Above Confluence page features text and three macros:
- the Info macro, containing text that I entered
- the Favorite Pages macro that shows my favorite pages
- the Lorem Ipsum macro that generates a random paragraph of text
Here’s how this page looks after having been migrated to SharePoint:
This looks pretty similar.
WikiTraccs, when migrating the page, retrieved text, the Info macro plus content and markers for the other two macros. And because Favorite Pages and Lorem Ipsum web parts don’t exist in SharePoint they are represented by a text placeholder in the resulting page.
Let’s now look at the page in Confluence without being in edit mode:
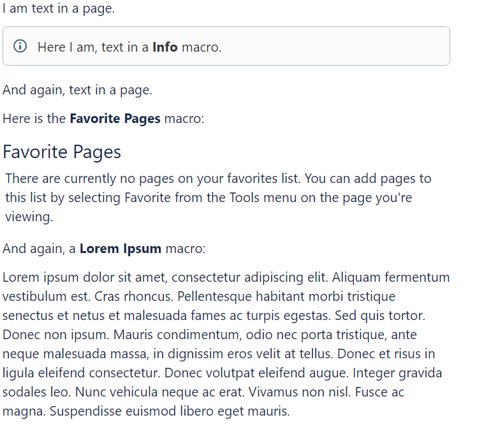
Confluence knows what Favorite Pages and Lorem Ipsum macros are supposed to do and shows additional, dynamically generated, content.
This, of course, is not possible to replicate in SharePoint.
Now what?
There’s not much WikiTraccs can do about macros not being available in SharePoint.
WikiTraccs already has special handling built-in for a handful of frequently used macros, like the Page Attachments and Page Tree macros.
For many macros you’ll see a placeholder in the migrated page.
Let’s zoom out for a moment.
It’s best to see this as a chance rather than an obstacle. SharePoint is different from Confluence. And as part of Microsoft 365 there is a good chance that something powerful can be built on the Microsoft-side of things.
And zooming in again here are some points for the migration-planning check list:
- create an inventory of spaces and check which can be excluded from the migration
- create an inventory of macros that are in use on Confluence pages in to-be-migrated spaces
- evaluate how removing macros might affect legibility and understandability of pages
- take a look at SharePoint standard web parts as well as community solutions like PnP Samples
- think about how the content will be used in SharePoint; is it like an archive or will the content be worked on?
- identify use cases that are affected by macros not being available in SharePoint anymore
- re-think use cases to SharePoint / Microsoft 365 where needed (don’t forget about Microsoft Teams, Viva, the Power Platform etc.)
Something wholistic like a transformation workshop or down-to-earth requirements analysis might be in place. (My colleagues at Communardo can support with those.)
With WikiTraccs it’s free and easy to just test the migration. Looking at the results can spark meaningful discussions as well.
Get started today!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
What to expect from WikiTraccs?
I often demo WikiTraccs to potential customers. Those demos spark discussions around the future structure, navigation patterns, usage scenarios, and more.
These are all topics that need to be worked on in the context of a migration project.

WikiTraccs can support your migration efforts.
It can migrate content from spaces to sites. It can migrate permissions and metadata. It has certain limitations. And it has distinct capabilities.
But there are things that WikiTraccs is not meant to do.
So let’s turn the headline around.
What to not expect from WikiTraccs
The following topics need to be worked on in the context of a transformation workshop, a migration project, or whatever format you choose to generate answers:
- choose what to migrate - content only? metadata? permissions?
- make decisions about which content goes from where to where - which spaces need to be migrated? which archived? which deleted? which sites do we migrate to? how many are there? how are they created? use new ones or existing ones?
- know the amount of content to migrate (at least not in a demo context) - 10, 100 or 1000 spaces? 1000, 10000 or 100000 pages? 10, 100 or 1000 GB of attachments?
- plan an access scheme for the SharePoint sites - users, groups, permissions given at which level in the SharePoint hierarchy of elements?
- decide which macros are important for users, and which not
- choose a strategy for your migration - big bang or in waves? who needs to be informed? how? when?
- choose migration environments - need test environments? how many? where do those come from? how exact do they need resemble the production environment?
- …and more, driven by your use cases
WikiTraccs cannot do this for you.
So what to expect from WikiTraccs?
WikiTraccs will help you realize the plans you made.
Let’s assume the following simplified migration plan:
- 📄 migrate all Confluence pages, from all spaces (10000 pages overall; 20000 attachments, mostly images)
- 🏗️ one target site for each source space
- 👥 keep page author and editor, no permissions
- 📝 accept that macros will mostly be lost and plan to educate users accordingly
- ⚙️ run multiple test migrations
- 📅 choose a weekend for the final migration
Here’s how WikiTraccs has got your back:
- 📄 WikiTraccs migrates content and metadata
- 🏗️ WikiTraccs migrates according to your space-to-site mapping
- 👥 WikiTraccs replaces Confluence user accounts by Azure AD accounts according to your mapping
- 📝 WikiTraccs handles macros according to the known macros list
- ⚙️ you test-migrate as often as you need (the license is not bound to volumes of data)
- 📅 using the experience from multiple test migrations verify a migration time of about 2 days
A demo is a good way to see this in action.
Testing yourself is even better. You can quickly put above steps into action in your environment.
Give it a try!
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
New attachments macro transformation
WikiTraccs migrates a snapshot of the attachments macro
The Confluence attachments macro shows a list of page attachments, which looks like this:
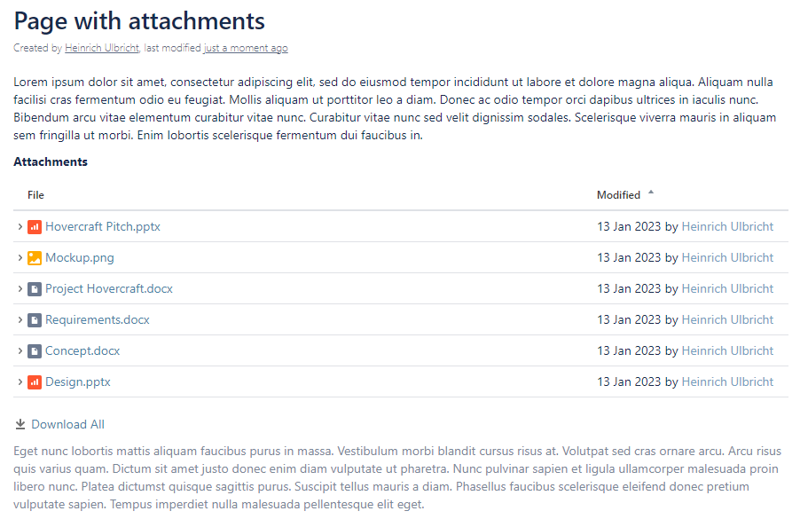
A Confluence page with attachments macro.
WikiTraccs now transforms this macro to a table in the target SharePoint page. The result looks like this:
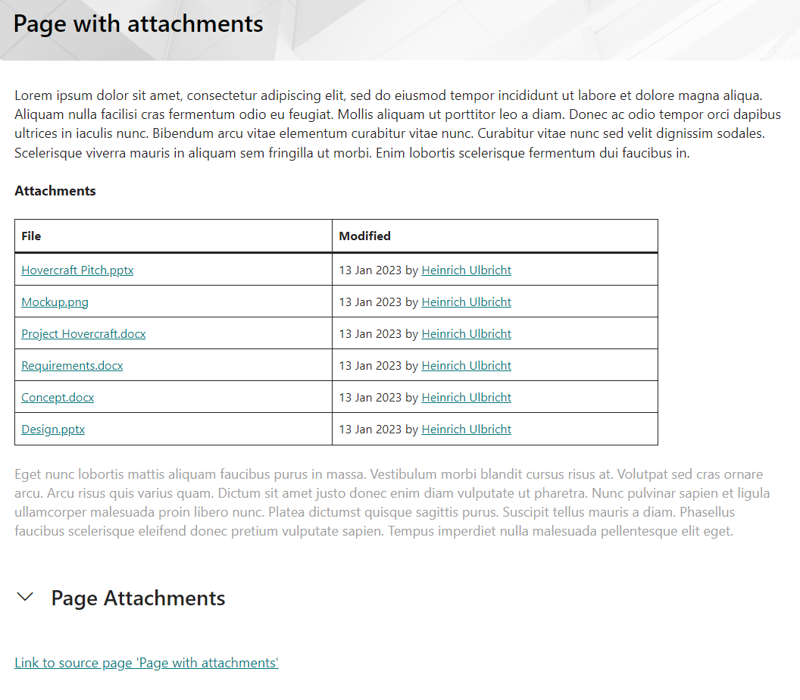
A SharePoint page with attachment links in a table.
This feels a lot better than the placeholder that has been generated before.
And do you see the Page Attachments section at the bottom? Let’s talk about that.
Attachments are also available via SharePoint web part
WikiTraccs creates a Page Attachments section on each SharePoint page with attachments. This allows for easy access of page attachments even on pages that had no page attachments macro.
The section is collapsed by default. Click the section title to expand it:
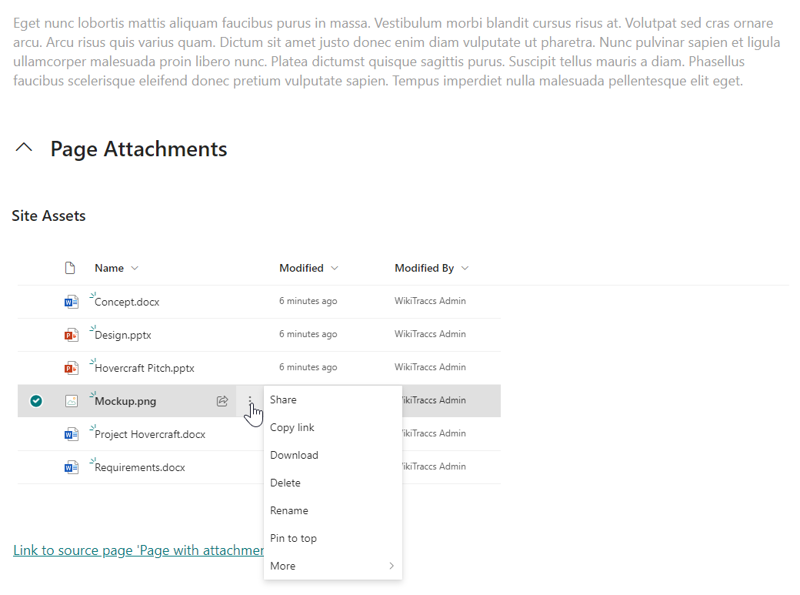
SharePoint list web part showing page attachments.
This section contains a standard SharePoint list web part. It shows all attachments of the page.
Where are those page attachments even stored??
SharePoint puts files that belong to pages in the Site Assets library. Each page has its own folder. And this is where WikiTraccs puts page attachments when migrating a page from Confluence to SharePoint.
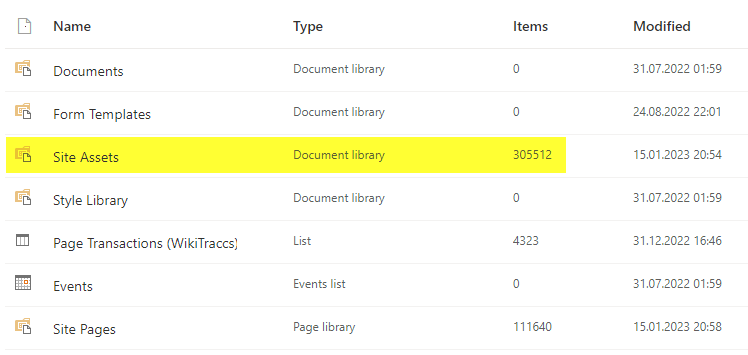
The Site Assets library contains all page attachmetns.
The web part in a page’s Page Attachments section shows the content of the page’s folder.
Summary
Both the page attachment macro transformation and the list web part that shows page attachments should make working with page attachments a lot smoother. They are an addition to the latest release of WikiTraccs.
Give it a try
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
Mapping principals and migrating permissions
Terminology
We need to define some terms before starting into the topic.
The term permissions is used broadly to describe which audiences can access which content in Confluence or SharePoint, and to which extent. Those audiences can be users and groups. Users and groups are collectively referred to as principals.
When explicitly talking about permissions for Confluence pages the term page restrictions will be used as this is the correct Confluence terminology.
A sample permission migration
We’ll do a sample permission migration. Screenshots from this migration will be shown throughout the blog post.
For the sake of this sample migration, let’s assume we want to migrate the following Confluence pages:
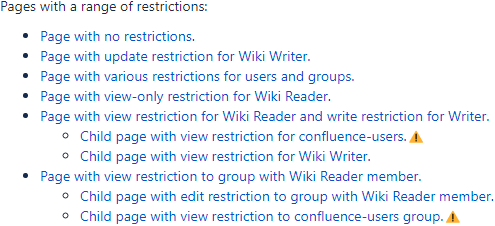
Confluence Pages
Each of those pages has a different permission configuration. Some pages have view and edit restrictions set. Some for users, some for groups, and some for both. And some pages form a hierarchy to illustrate the challenges associated with that.
How to migrate permissions with WikiTraccs
Opinion from the author of WikiTraccs
If you can, don’t migrate permissions.
Spare yourself the hassle that is migrating permissions from Confluence to SharePoint. It rarely provides value compared to rethinking the information architecture in SharePoint, which will likely yield a different result than what has grown in Confluence. Besides, a 1:1 permission migration is nearly impossible as soon as you’ve got permission hierarchies in Confluence that involve groups.
If you want to migrate permissions, do a test migration first.
If there is a tight deadline and you did not test-migrate, don’t stumble into the production migration. Test-migrate first.
That being out of the way, the rest of this post shows how to migrate permissions.
WikiTraccs can migrate page restrictions from Confluence to SharePoint (within certain limits, more on that later). Migrating page restrictions is done in three steps.
STEP 1: Migrate content and configure mappings for users and groups
First, you migrate page contents. WikiTraccs stores Confluence page restriction and principal information in SharePoint lists, along the way.
Choose content migration mode
In the main blue WikiTraccs.GUI window, from the main menu, choose Settings > Configure Transformation.
In the Transformation Settings dialog, in the Migrations tab, choose Migrate Content as migration mode.
Select Ok to close the dialog.
When a page is migrated, WikiTraccs also receives page restrictions for this page as well as information about users and groups involved in those restrictions.
No permission configuration is applied to SharePoint pages, yet.
After successfully migrating the Confluence pages shown earlier (only content!) this is how the Pages Library of the migration target site looks:
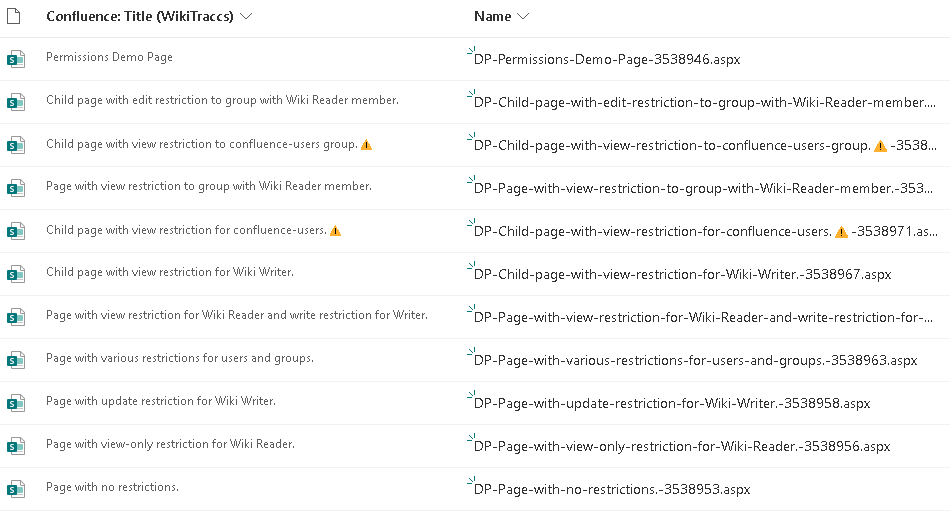
Migrated Confluence Pages in SharePoint Pages Library
In addition, the document library Confluence Page Permission Snapshots (located in the WikiTraccs site) now contains permission snapshots for those pages, waiting to be applied by WikiTraccs:
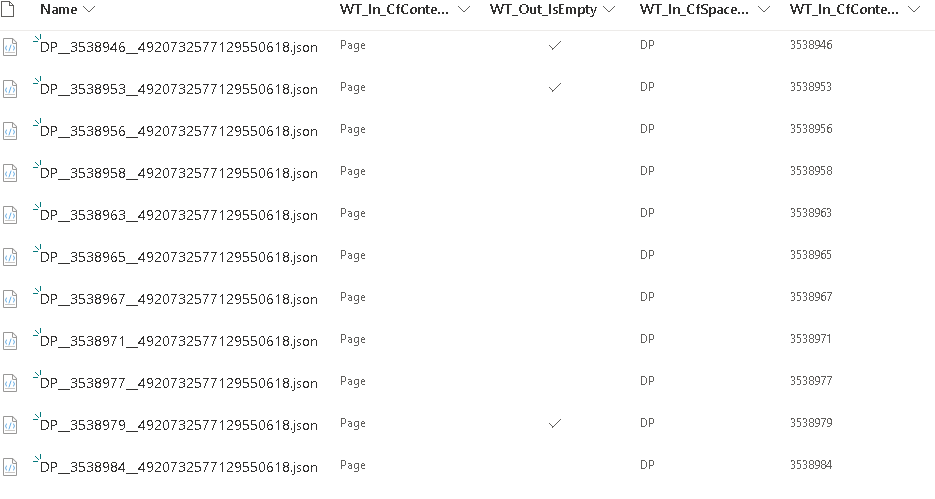
Confluence Page Permission Snapshots
Those permission snapshots contain information about a page’s restrictions.
Then there’s a third list that WikiTraccs populates, the Confluence User and Group Mapping (WikiTraccs) list (also located in the WikiTraccs site):
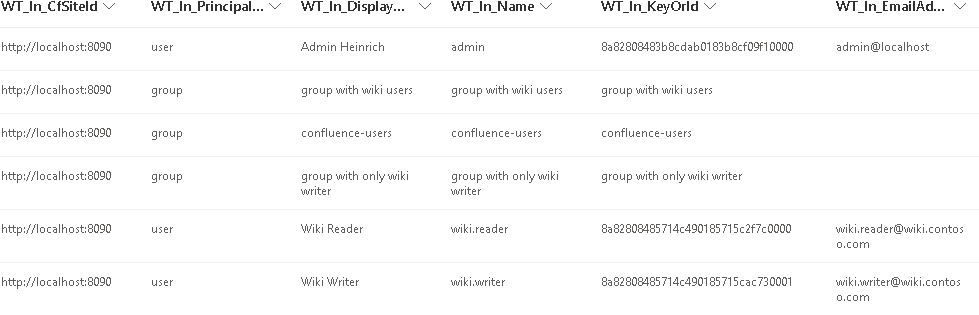
Confluence Users and Groups
You now configure the user and group mapping in this list. WikiTraccs needs to know which Confluence principal maps to which SharePoint principal.
STEP 2: Mapping Confluence users and groups to SharePoint
One factor for a successful permission migration is the mapping of Confluence users and groups to their counterparts in SharePoint. You configure this mapping manually.
Let’s configure the mapping like this, in the Confluence User and Group Mapping (WikiTraccs) list (located in the WikiTraccs site):
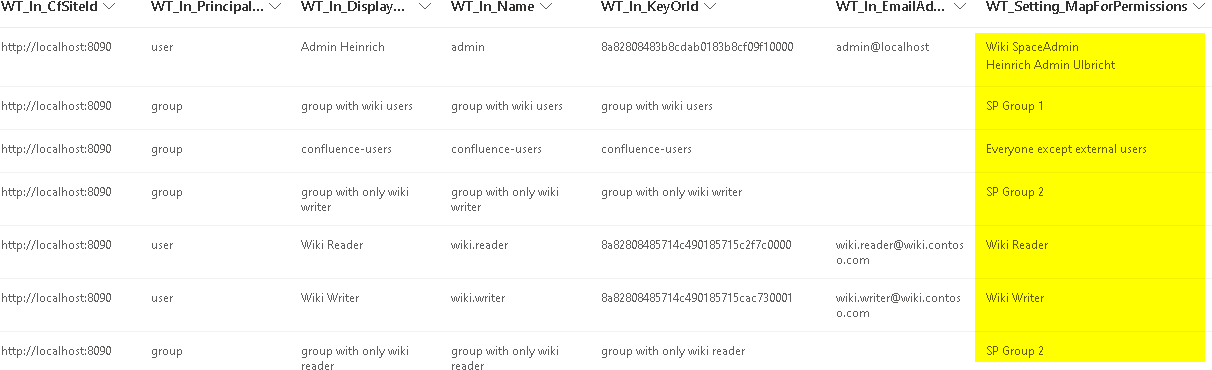
Mapping Confluence to SharePoint Principals
The highlighted column WT_Setting_MapForPermissions contains accounts from Entra ID and SharePoint groups.
Those two mappings shall be highlighted in particular, as we’ll revisit them in STEP 3:
- the Admin Heinrich (admin) Confluence account is mapped to two target accounts Wiki SpaceAdmin and Heinrich Admin Ulbricht
- the Wiki Reader (wiki.reader) Confluence user is mapped to the Wiki Reader AD account
When you are done with the mapping, proceed with the next step.
Mapping groups
Group mappings are based on SharePoint groups. Due to technical reasons, those SharePoint groups have to be created both in the WikiTraccs site and in the target SharePoint sites.
Group members only have to be configured in the target sites, though. The SharePoint group in the WikiTraccs site is merely a placeholder, so the group can be chosen as migration target in the people picker.
Automating the creation of those SharePoint groups is recommended, e.g. using PnP.PowerShell.
Note
You can change the mapping later and run the permission migration again, to update SharePoint page permissions.STEP 3: Apply permissions to SharePoint pages
In this last step WikiTraccs applies the stored permission information to the already migrated SharePoint pages. This step has to be started manually and separately from the first step.
Enable permission migration mode
In the main blue WikiTraccs.GUI window, from the main menu, choose Settings > Configure Transformation.
In the Transformation Settings dialog, in the Migrations tab, choose Migrate Permissions as migration mode.
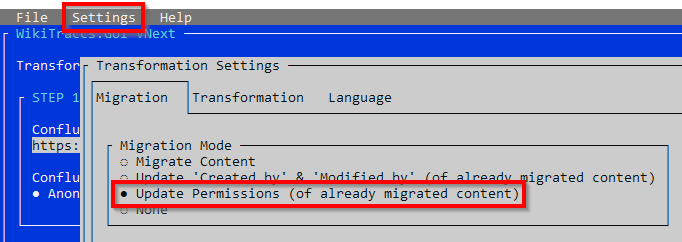
Select Ok to close the dialog.
Note
Separating the two steps - retrieving permissions information and applying those permissions to SharePoint - allows for a more flexible migration of content and permissions.After choosing permission migration mode, start the migration as usual. WikiTraccs now applies the already migrated permission information to the already migrated pages in SharePoint.
We now have a look at a page permission migration result in depth.
In Confluence, the restrictions for page Page with view-only restriction for Wiki Reader look like this:
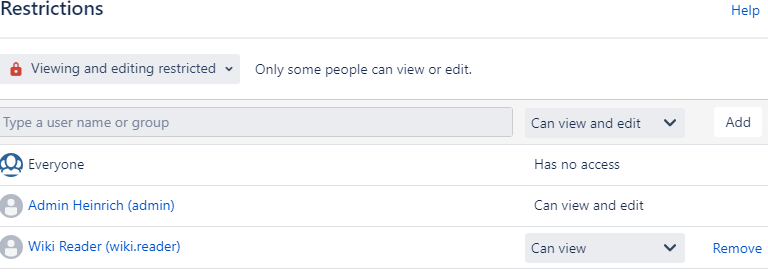
Restrictions of Page "Page with view-only restriction for Wiki Reader" in Confluence
Here’s the resulting permissions for the migrated SharePoint page:
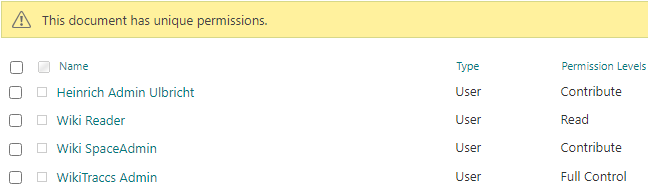
Permissions of the Migrated SharePoint Page
Looking at the principals and permission levels this is what happened:
- Confluence account “wiki.reader” was mapped to the “Wiki Reader” AD account and got Read permissions which corresponds to the Confluence view restriction
- Confluence account “admin” was mapped to both the “Heinrich Admin Ulbricht” and the “Wiki SpaceAdmin” accounts and got Contribute permissions which corresponds to the Confluence edit permission
- “WikiTraccs Admin” is the migration account and got Full Control permissions (the migration account is always added)
The basis for this permission configuration had been layed in step 2 when you configured the principal mappings.
Tracking permission migration progress
WikiTraccs logs the result of each page permission migration in the Page Transactions list, that is located in each migration target site in SharePoint.
For our sample migration this looks like this:
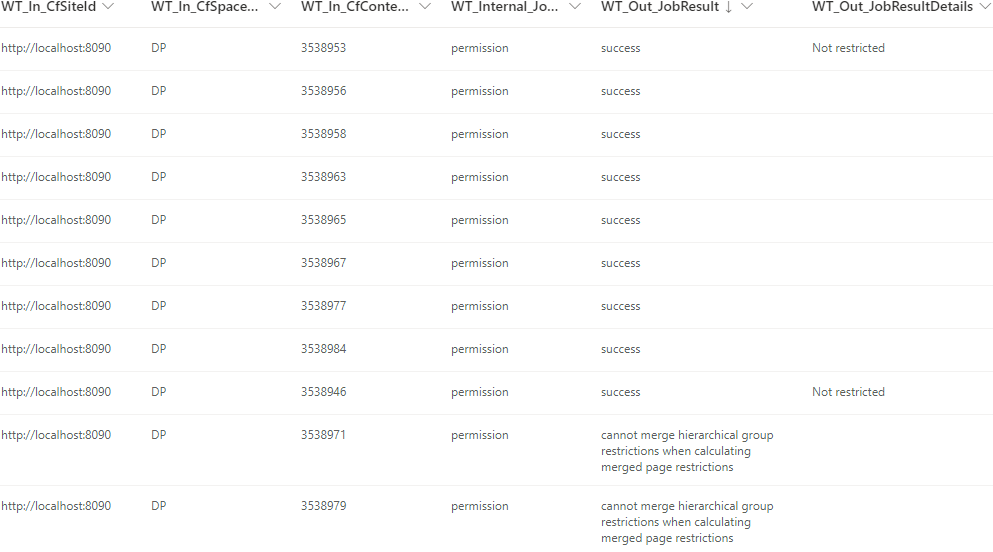
Permission Migration Results
There are several reasons why migrating Confluence page restrictions to SharePoint might fail.
The good thing is that a range of permission migration failures can be fixed easily. The permission migration can be run multiple times and will retry failed migrations. This can be repeated until all resolvable errors have been resolved.
Going back to our sample migration you might have noticed that (in the last screenshot) two permission migrations where not successful. For two pages the result is cannot merge hierarchical group restrictions when calculating merged page restrictions which means that for those pages restrictions could not be migrated.
The next section takes a deeper look at what WikiTraccs currently can and cannot do when it comes to migrating permissions.
Capabilities and limitations with regard to migrating permissions
WikiTraccs currently has two types of limitations when it comes to permission migrations: not-implemented features and nearly-impossible-to-add features.
But first, here is what WikiTraccs will do:
- apply Confluence user and group page restrictions to SharePoint modern pages, when no hierarchy of page restrictions is involved
- apply hierarchical page restrictions from Confluence to SharePoint modern pages in certain narrow circumstances (e.g. only users are involved)
- provide a mapping opportunity for each Confluence principal to one or more Entra ID accounts and SharePoint groups
- map the Confluence view and edit restrictions to corresponding SharePoint permission levels via a hard-wired logic
Features that might be useful in the future, but are not currently implemented:
- using other group types than SharePoint groups as mapping target
- provide fallbacks for when a mapping is missing or empty
- configurable behavior for failed permission migrations (should the SharePoint page be restricted or not?)
- more control over the permission migration scope (single pages, spaces, …)
- migrating space and global permissions (those are currently not migrated and need to be set manually on the SharePoint site or sub site level)
- allowing to configure SharePoint permission levels to be used in the target page (currently the out-of-the-box permission levels are used)
- regularly updating SharePoint permission based on a configurable schedule
Features that will be hard or impossible to add:
- migrating arbitrary hierarchies of page restrictions
Nested pages and restrictions
Hierarchical page restrictions from Confluence are difficult to handle because nested pages don’t exist in SharePoint. For SharePoint, the restriction hierarchy of a page needs to be combined and applied to a single SharePoint page.
When only user restrictions are involved then merging a hierarchy of restrictions is relatively easy to do. But when it comes to groups which overlap in only some of their members it becomes nearly impossible to apply that to SharePoint.
Re-apply permissions after changing principal mappings
You can change the principal mapping that you configured in STEP 2, even during or after a permission migration.
To do so, proceed as follows:
- in the WikiTraccs SharePoint site, change principal mappings via the Confluence User and Group Mapping (WikiTraccs) list
- in each migration target SharePoint site, delete entries from the Page Transactions table for pages that should have their permission configuration updated; otherwise WikiTraccs won’t update those pages
- in WikiTraccs, choose Permission Migration mode and start the migration
WikiTraccs will now apply page permissions again, using the already migrated information about Confluence page restrictions, and the updated principal mapping.
Note
This does not update the already migrated page restriction information from Confluence. To get updated page restriction information from Confluence, you have to restart with STEP 1 and remigrate page contents, which will carry over updated page restriction information from Confluence.Summary
With the next release WikiTraccs adds the ability to migrate page restrictions from Confluence to SharePoint.
You’ll be able to configure which Confluence users and groups correspond to which SharePoint users and groups. WikiTraccs uses this information when applying unique permissions to SharePoint pages.
This release marks a milestone from which further development will be driven by your feedback. WikiTraccs could support several additional scenarios and development effort will be directed to areas with the most demand.
Furthermore, user and group mappings will be the basis for the migration of page metadata like author and editor.
Give it a try
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
Or get in touch via email if you are interested in a demo. Give it 45 minutes and you’ll be up to speed on how WikiTraccs can help you.
WikiTraccs Quick Start Video out now!
You can have your first migration running in less than 30 minutes.
This quick start video is all you need:
New release - UI overhaul
Note
Click here to get the latest release. The Quick start guide has been updated to reflect below changes.The user interface got some additions
The WikiTraccs.GUI user interface has been changed.
The settings have been grouped into steps: First configure the source, then configure the target, then test the configuration, and then start the migration.
Some configuration options are gone. You now use a SharePoint list to configure the Confluence spaces to migrate. This list shows basic information about all Confluence spaces and is filled by WikiTraccs.
Note: The idea behind using SharePoint lists for configuration has been described in more detail here: A new approach to configuring WikiTraccs
A big improvement are the progress indicators. You no longer have to rely on the console output of WikiTraccs to see progress. Instead, you get a progress bar for overall page progress and the progress of each migrating Confluence space:

Migration progress
Laying the foundation for user and group mapping, and permission migration
Starting with the current WikiTraccs release 0.0.222, you need to create a SharePoint site dedicated to WikiTraccs. This is the “WikiTraccs site”. You use this site to configure WikiTraccs, like choosing the spaces to migrate. And WikiTraccs uses the site to store metadata about the migration.
This site also holds two SharePoint lists, Confluence User and Group Mapping and Confluence Permission Snapshots. You will notice that those will be filled while migrating.
The current release does not yet support user or group mappings, or permission migration. But a future release might make use of this data.
Fixes and improvements
When migrating pages with large file attachments WikiTraccs could run into timeouts. This has been fixed.
Parallel file downloads have been added. WikiTraccs now loads two attachment files from Confluence at the same time, optimizing for large and small files.
The list of known edge cases in Confluence page content transformation has been expanded.
The retrieval of Jira issue information has been improved for pages with a large amount of linked Jira issues.
Summary
This release is a big step and lays the foundation to add two big missing features: user and group mapping, and permission migration. I’m excited for the next releases as they will bring WikiTraccs further to what one would expect from a migration tool.
Give WikiTraccs a try and check out its transformation capabilities!
Start today with WikiTraccs’ free Trial Version:
I’m also eager to get feedback, so get in touch when you try it: Contact.
Measuring page migration success
Which metrics measure page migration success?
Each Confluence page consists of content, formatting, layout, attachments, links, mentions and more that has to be handled when transforming the page to SharePoint.
WikiTraccs calculates the following metrics for each migrated page:
- the percentage of characters in the page that was migrated
- the number of unknown macros
- the number of links that could not be resolved
- the number of migrated images
- the number of user references in the page that could not be resolved
- the number of transformation errors
Those numbers are saved as page metadata.
A SharePoint view for the Site Pages library can be used to visualize those numbers. Here is a migration result indicating success:
Successful page migrations
Source content issues
Below image shows the result for a page where not everything could be migrated. Not all images could be transferred. And there were two links to inaccessible pages:
Missing images and inaccessible pages
Errors like missing images and inaccessible content can often be solved by fixing permissions or broken content in the source Confluence system.
Also note the “3” in the “Crystal Ball Transformations” column. This means there were 3 macros that WikiTraccs doesn’t know yet. It used a generic transformation approach for those macros.
Note
See the list of known macros here: Known Confluence Macros.Transformation issues
Sometimes WikiTraccs cannot handle content properly (for whatever reason):
Migration errors
Above image shows that 12 elements in a page could not be transformed and only 51% of the page’s text content made it to the SharePoint page.
Those issues can be caused by faulty Confluence pages triggering transformation errors. There are already dozens of special cases and quirks that WikiTraccs works around. But there will always be cases that are new and need to be looked into.
For such a page, click on “View Entries” to see the content that cause the transformation issue. And ultimately a good thing to do might be opening an issue on GitHub.
Summary
In this post we looked at the metrics WikiTraccs uses to highlight migration success and migration issues. Everything being green is a good indication of a successful migration.
WikiTraccs counts content characters in each Confluence page and again counts characters in the target SharePoint pages. The result will be reported as “Text Transferred Percent”. This percentage is a good indicator if content is missing or not.
A new approach to configuring WikiTraccs
So far my plan was to establish WikiTraccs.GUI as a visual frontend for configuring WikiTraccs.Console.
Note
See WikiTraccs GUI vs. WikiTraccs Console to learn the difference between those two.But I decided to change that approach a bit. WikiTraccs.GUI will still be application you start transformations with. But the configuration will mainly be done in SharePoint.
How is SharePoint used to configure WikiTraccs?
WikiTraccs stores information about the migration into SharePoint lists. You will create a site collection for WikiTraccs to use. This could be called “WikiTraccs Store” and holds data during the migration. It can be deleted after the migration.
When starting WikiTraccs it will create several lists there. One is the Confluence Space Inventory list. This list stores information about all spaces in Confluence, like space name and space key. But it also allows you to select the spaces to be migrated:
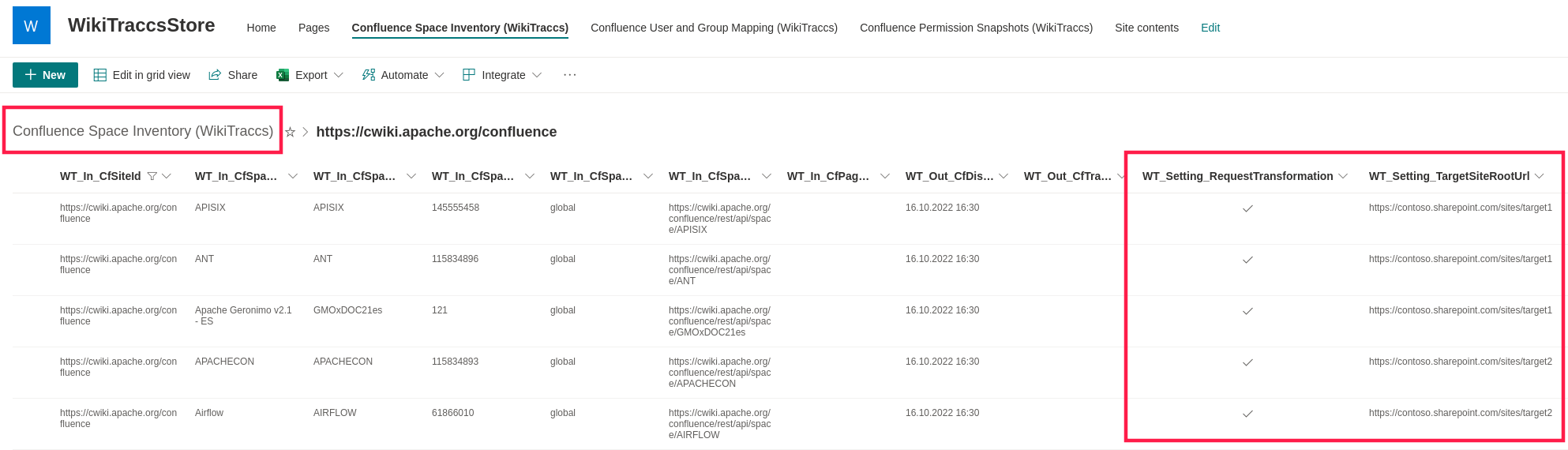
Confluence Space Inventory List in SharePoint
Above image shows the Confluence Space Inventory list that shows some spaces from a publicly available Confluence instance.
In the image on the right side, marked with a red rectangle, are two columns that allow you to:
- mark a space for migration via Yes/No column
- specify the target site for the migration via a text column to put the target site URL in
More columns might follow as needed. (Note: the column names are still technical and are yet to be named properly.)
Why use SharePoint for configuration?
One benefit of using SharePoint lists for configuration is that they already provide a way to display tabular data, like the space inventory. This data can be sorted and filtered out of the box.
List data can be exported to and imported from Excel files for others to review. So the list of spaces could be given to stakeholders to decide which spaces should be migrated. Then they are imported again and WikiTraccs migrates only the selected spaces.
Using SharePoint as a user interface also means there is less potential for programming errors in WikiTraccs since the interface is owned by Microsft.
SharePoint lists provide a familiar user interface, if users are already used to working with SharePoint. There is no new UI that has to be learned.
The data can be shared with select stakeholders by using SharePoint list or list item permissions.
You are free to run WikiTraccs on any machine, even multiple ones, and change the machine at will. Every instance of WikiTraccs will operate on the same configuration.
And last but not least you have the SharePoint Search at your disposal to locate information you need.
Wrap up
That’s it for the latest update. What do you think about using SharePoint lists for configuring a migration? Get in contact and let me know!
Stay in the loop!
Are you interested in using WikiTraccs once it leaves early access? Drop me a direct message on X @wikitraccs or via email and I’ll get back to you as soon as it’s ready.There are more lists that are relevant to WikiTraccs that will be covered in future blog posts:
- Confluence User and Group Mapping
- Confluence Permission Snapshots
As the names suggest those are relevant for mapping Confluence users and groups to SharePoint and to ensure the permissions and metadata can be rebuilt properly.
Note
The features described in this blog post are not yet included in release 0.0.206 and will be contained in a soon-to-be-released release.Announcing WikiTraccs
I’m delighted to announce the first public release of WikiTraccs.
What is WikiTraccs?
WikiTraccs is a migration tool for Confluence to SharePoint Online migrations.
Tip
Want to try WikiTraccs right away? Try the quick start guide.Which problem does it solve and who needs it?
WikiTraccs makes migrating content from Atlassian Confluence to SharePoint Online easier. It contains hundreds of transformation rules for a wide range of Confluence formattings, structures and macros.
A migration from Confluence might be beneficial for:
- users of Confluence Server, since Atlassian will eventually phase out Server, urging users to migrate to Confluence Data Center or Confluence Cloud
- users of Confluence Data Center, because it only buys some time before migrating to the Atlassian cloud might be inevitable
- users of Confluence Cloud, because of license costs
Often Microsoft 365 licenses are available already, covering the use of SharePoint Online modern pages to display wiki content. In this case SharePoint Online is a potential target for the migration.
Is it ready for production?
No, not yet. The current release is an early access version. This means the basics work but a lot is still to be done.
The focus of this first release is to migrate content and structure of Confluence pages as reliable as possible. This includes:
- Text
- Formatting like bold, italics, underline etc.
- Text colors and background colors
- Headings
- Task lists
- Emoticons
- Complex tables
- Images, internal and external
- Mentions
- Page and attachment links, on the same page and to different pages and spaces
- Layouts with multiple columns and rows
- Macros - a wide range is supported out of the box, for unknown ones generic rules are applied
It has been tested on thousands of Confluence pages and dozens of gigabytes of images and attachments. Since every Confluence is unique with regard to its content there will be cases not covered. But those will be covered over time as feedback comes in.
WikiTraccs keeps track of every word that is present in a source Confluence page and checks if it is present in the target SharePoint page as well. It highlights pages where this is not the case. Thus pages with lacking transformation success can be identified easily and immediately.
The Feature Overview page will eventually cover all supported and not yet supported types of Confluence content and metadata.
You can also read more about how WikiTraccs works in How does WikiTraccs work?.
Which Confluence versions are supported?
WikiTraccs supports Confluence 6 and up, including Confluence Cloud. Confluence 5 and older are not supported.
How do I get started?
Have a look at How to get started?
If you want to get in touch have a look at the options you have for logging issues, start discussions or just give feedback.
What’s the meaning of “WikiTraccs”?
“WikiTraccs” is short for “Wiki Transformation Accelerators”. WikiTraccs for Confluence should indeed accelerate things compared to a manual migration.
There are a lot of interesting topics to be covered which will be done in a future posts!