This is the multi-page printable view of this section. Click here to print.
Recipes
1 - Confluence Macro Usage
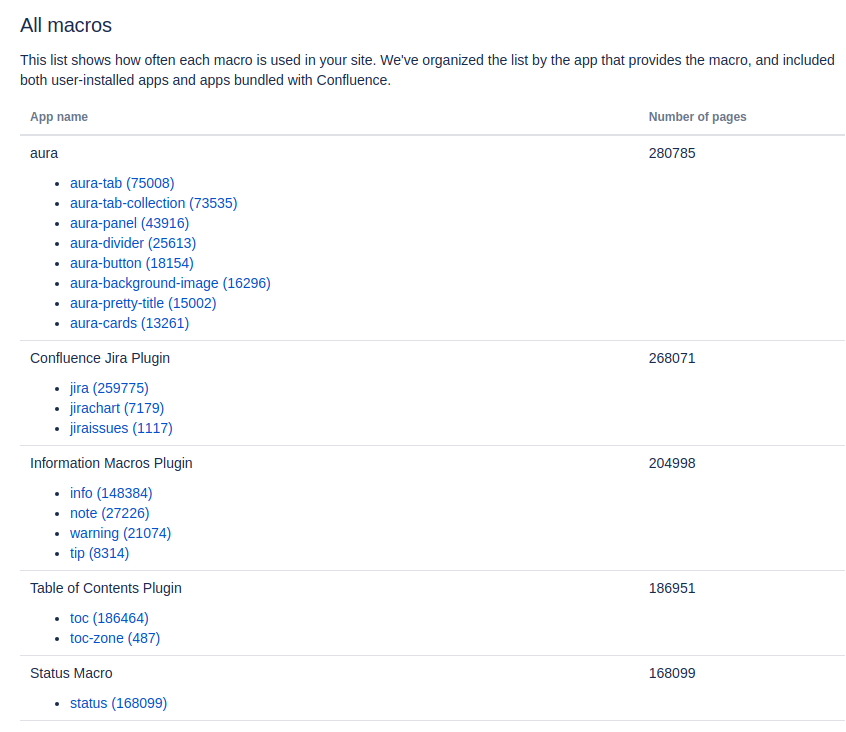
In the Confluence Administration, in the vertical left menu, click Macro Usage.
This will open a page that displays which macros are in use and the number of pages on which they appear:
Note
This works for Confluence on-premises and Confluence Cloud.The link to this page is admin/pluginusage.action (on-premises) or admin/macro-usage (Cloud).
Clicking on any of the macro names opens a search results page showing pages that use this macro.
The link for this kind of macro search is dosearchsite.action?cql=macro = "aura-tab" (here searching for the aura-tab macro).
Feel free to provide me with this list, e.g. for a demo or just for informational purposes.
2 - Getting a list of pages per space [on-premises]
Getting pages per space
This script returns a list of page metadata like content ID and title.
Run the following SQL script on the Confluence database. IMPORTANT: Replace MYSPACEKEY with the key of the space you want to get the page info for:
select contentid, contenttype, title, content_status, spacekey
from content left join spaces on content.spaceid = spaces.spaceid
where (contenttype='PAGE' or contenttype='BLOGPOST') and prevver is null and content_status='current' and spacekey='MYSPACEKEY';
Note: the space key is case SeNsItIvE.
Getting the page count per space
This script returns the page count for a space.
Run the following SQL script on the Confluence database. IMPORTANT: Replace MYSPACEKEY with the key of the space you want to get the page count for:
select count(*)
from content left join spaces on content.spaceid = spaces.spaceid
where (contenttype='PAGE' or contenttype='BLOGPOST') and prevver is null and content_status='current' and spacekey='MYSPACEKEY';
Note: the space key is case SeNsItIvE.
Getting the most recent page change per space
This script returns the timestamp of the most recently modified page or blog post for every space.
Run the following SQL script on the Confluence database.
SELECT
spaces.spacekey,
MAX(content.lastmoddate) AS most_recent_change_date
FROM
content
LEFT JOIN
spaces ON content.spaceid = spaces.spaceid
WHERE
(content.contenttype = 'PAGE' OR content.contenttype = 'BLOGPOST')
AND content.prevver IS NULL
AND content.content_status = 'current'
GROUP BY
spaces.spacekey
ORDER BY
most_recent_change_date DESC;
3 - Find out why some pages won't migrate
Sample Situation
You have migrated a Confluence space that contains 3000 pages. Yet, when looking at the target site’s Site Pages library, you can only see 2900 pages. That’s 100 pages missing.
What’s up with those 100 missing pages? Why won’t they migrate?
What are possible root causes?
There are many reasons why pages fail to migrate. Some of them are temporary.
Here is a list of common issues:
- Connection Issues
- when downloading content from Confluence, there was a service or connection issue
- when creating a page in SharePoint Online, there was a service or connection issue and page or attachment creation failed
- Not enough Disk Space
- there is not enough disk space for WikiTraccs to download all page attachments
- “Interesting” Page Content
- a page contains content that WikiTraccs has never seen before and that it can’t handle well
WikiTraccs has mechanisms built-in to deal with some of those issues. For example, attachment upload and SharePoint page creation will be retried a couple of times to work around temporary connection issues. Missing disk space will cause the migration to be paused, until space is available again.
What to try first?
The first thing you should do is run the migration again, until the number of migrated pages stabilizes.
After the first migration run, 100 pages might be missing (for example due to unstable networking conditions). The second migration run might migrate another 50 pages. And the third migration run doesn’t change that.
Now what you are dealing with is the 50 pages that are still missing.
How to diagnose this?
The first thing we need is to look at the progress log files: Using progress log files to get insights.
Use the __30-aggregated-info progress log file to learn about the expected number of pages and the missing number of pages.
Use the __10-not-yet-migrated-pages progress log file to learn which pages are missing. This file contains page IDs that can be used to look up those pages in the common log files.
Take note that new progress log files are created with each migration run and that each space (or CQL selector) gets its own set of progress log files. So make sure to look at the most recent ones.
The ultimate tool to diagnosing why a page didn’t migrate are the common log files: Common log files.
Using the page IDs from the __10-not-yet-migrated-pages progress log file, we can look up corresponding log messages in the common log file(s) of a migration run.
Ultimately, the common log files should tell what was going on with those pages.
How to solve this?
Sometimes the common log files show something obvious, like a system being down, an authentication failing, or connection errors. This might help you inferring solutions.
But often it’s easier to send me the log files via email, for further diagnosis: [email protected].
Make sure to send the progress log files and also the common log files for a migration run.
4 - How to Make Sure the Space Inventory Shows All Spaces
Sample Situation
You open the Confluence Space Inventory, which is a SharePoint list that contains basic information about all Confluence spaces.
The Space Inventory list is created by WikiTraccs and populated with rows when you click the Update Space Inventory and WikiTraccs Site button:

Click to update the Space Inventory.
Let’s say you did this, look at the Space Inventory, and information about some spaces is missing.
What are possible root causes?
The most common causes are permission-related; the migration account might not be allowed to see all spaces.
Other possible causes include:
- there have been new spaces created since the last update of the Space Inventory
- you are looking at the wrong (outdated) SharePoint site and Space Inventory list, which can happen when experimenting and handling a lot of test sites (note: yes, this happened)
- space permissions or migration user permissions changed since the last update of the Space Inventory
What to try first?
You should update the Space Inventory.
When WikiTraccs shows the login dialog for Confluence, make sure to log in to Confluence with an account that is allowed to access all spaces. Or, if you are using token authentication, make sure to use the Personal Access Token of a migration user that is allowed to see all spaces.
Update the Space Inventory by clicking the Update Space Inventory and WikiTraccs Site button. You can click that button as often as you want, WikiTraccs will check every time if your spaces are present.
How to detect this situation in the first place?
Look up the Confluence space count in the Confluence administration and compare this number with the number of rows in the Space Inventory list. They should match.
Note: WikiTraccs adds information about both current and archived spaces to the Space Inventory.