This is the multi-page printable view of this section. Click here to print.
WikiTraccs Reference
- 1: How does WikiTraccs work?
- 2: WikiTraccs License Activation
- 3: WikiTraccs FAQ
- 4: Prerequisites
- 5: Installation and Update
- 6: Settings & Configuration
- 6.1: Configuration via WikiTraccs.GUI (blue window)
- 6.1.1: Gray Settings
- 6.1.2: Misc Settings
- 6.2: Confluence Space Inventory
- 6.2.1: How to map Confluence Source Selectors to SharePoint Sites
- 6.2.2: How to migrate Confluence Content using Space Selectors
- 6.2.3: How to migrate Confluence Content using CQL Query Selectors
- 6.2.4: How to migrate Confluence Content using Content ID Selectors
- 6.3: Configuration via Configuration File
- 6.3.1: Sample Configurations
- 7: Migration Samples
- 8: Monitoring Confluence to SharePoint Migration Progress - Overview
- 9: Updating Previously Migrated Pages
- 9.1: Updating Previously Migrated Pages - Quick Approach
- 9.2: Updating Previously Migrated Pages - Granular Approach
- 10: Known Confluence Macros
- 10.1: How Do Confluence Macros Look in SharePoint?
- 10.2: Macro Placeholders and Transformation Templates
- 10.3: Convert Macros to SharePoint Web Parts
- 11: Security
- 11.1: Secure Development and Release
- 11.2: Data Storage and Transmission
- 11.3: Endpoint Reference
- 11.4: Running WikiTraccs in Locked-Down Environments
- 11.5: Data Processing Agreement - WikiTraccs
- 12: Using WikiTraccs.GUI
- 12.1: Source Configuration
- 13: Authentication
- 13.1: Authenticating with Confluence
- 13.2: Authenticating with SharePoint Online
- 13.3: Proxy Authentication
- 14: Migration Waves
- 14.1: Include/Exclude Filters
- 15: Page Refinement
- 15.1: Page Refinement - Log Broken Links
- 15.2: Page Refinement - Fix Broken Links
- 15.3: Page Refinement - Log User Mentions
- 15.4: Page Refinement - Fix User Mentions
- 15.5: Page Refinement - Open Links in Same Browser Tab
- 15.6: Page Refinement - Fix Web Part Drift
- 16: Confluence Inventory
- 16.1: Inventory Scan and Reporting
- 16.1.1: Activate and Configure Inventory Mode
- 16.1.2: Select Spaces to Inventory
- 16.1.3: Inventory Storage
- 16.1.4: Report: Inventory Overview
- 16.1.5: Report: Space Details
- 16.1.6: Report: Open Tasks
- 16.1.7: Report: Link Insights
- 16.1.8: Report: Flagged Pages
- 16.1.9: Report: Users and Groups
- 16.2: Getting the Confluence page count
- 17: File Storage
- 18: Glossary
- 19: Multilingual Pages
- 19.1: Info about Scroll Translations
- 19.2: Migrating all Languages to one SharePoint Page
- 19.3: Migrating to Multilingual Pages in SharePoint Online
- 20: WikiTraccs GUI vs. WikiTraccs Console
- 21: Known Issues and limitations
1 - How does WikiTraccs work?
Overview
WikiTraccs migrates content from Atlassian Confluence to SharePoint Online.
It does more than a simple migration, though. While migrating it will transform Confluence macros, links, images and more to its SharePoint equivalents. Thus it could be called a transformation rather than just a migration.
If you are looking for a solution that transforms your Confluence content into modern SharePoint Online pages WikiTraccs has got you covered.
How does it work?
The process of getting content from Confluence to SharePoint works roughly as follows:
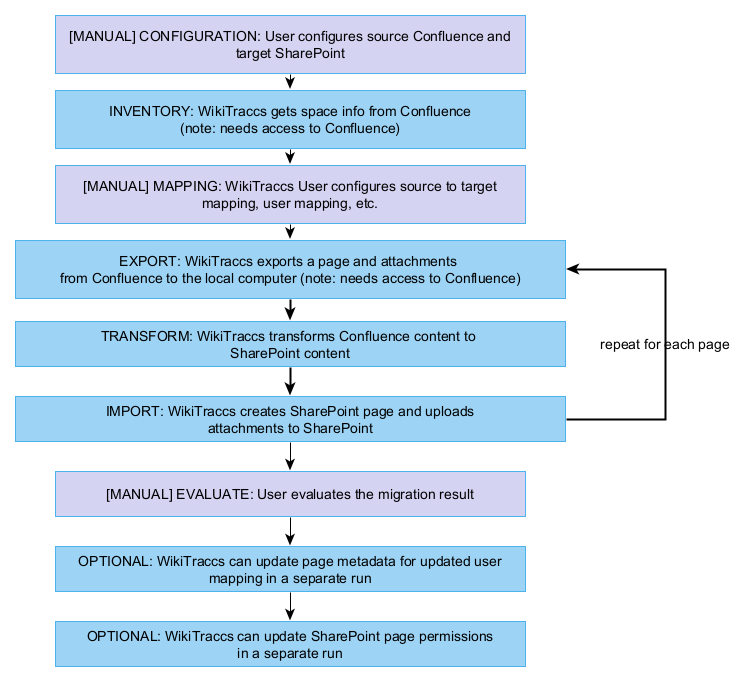
Confluence export and SharePoint import is done page by page. When interrupted WikiTraccs will continue at the page where it left off. Just start the process again.
Transformations can be configured on a per-space basis. You configure which Confluence space is migrated to which SharePoint site. Multiple spaces can be migrated to the same site.
WikiTraccs stores transformation metrics for each page in SharePoint as metadata of the page. You can sort, filter and review directly in SharePoint to check the transformation result.
How to get started?
Read here to learn how to get started: Getting started
2 - WikiTraccs License Activation
After purchasing WikiTraccs a license key will be shown. Furthermore, an email will be sent to the email address entered into the checkout form.
Note
License key delivery time and display modalities vary between marketplaces. With the FastSpring merchant it is instant and the license key will be shown and sent via email, with Lemon Squeezy it takes up to 24 hours and the license key arrives via email.“Activating” a license for WikiTraccs means: storing the license key in a text file where WikiTraccs can find it.
Where to store the license key?
Make sure you have the license key handy that you or your purchasing department received.
Create a new, empty file license.txt file in the WikiTraccs.GUI folder. Open license.txt for editing. Then copy and paste the license key you received to this file. Save and close the file.
If WikiTraccs.GUI or WikiTraccs.Console is running, close it.
Start WikiTraccs. It should now recognize the license file.
Verifying that the license is recognized by WikiTraccs
In the blue WikiTraccs window, have a look at the gray text box, it should show license information:
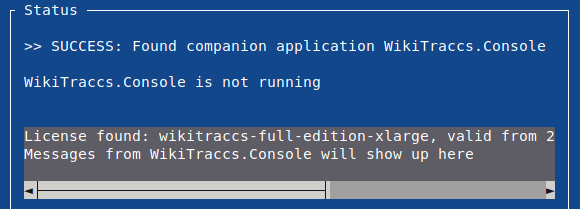
"License found" message after starting WikiTraccs.GUI
During a running migration, WikiTraccs also shows information about the license:

License validity shown during a migration
Tip
The license key converts an existing WikiTraccs trial version to a licensed full version. You don’t need to download a new release package.
Nevertheless, it is recommended to look for WikiTraccs updates here: WikiTraccs Releases.
Troubleshooting Licensing Issues
WikiTraccs logs information about any license files it finds, including locations it expects such a file to be.
Check the common log files that the license file is at an expected location. See the following sections for log samples.
License found
If one or multiple license key files could be found, the log contains entries like those:
[ 21:37:42 INF] Trying to find license... |
[ 21:37:42 INF] Checking if license file exists in: '/home/user/wikitraccs/WikiTraccs.GUI' |
[ 21:37:42 INF] FOUND license file candidate '/home/user/wikitraccs/WikiTraccs.GUI/license.txt' |
[ 21:37:42 INF] Found license files, will now read licenses from them: ["/home/user/wikitraccs/WikiTraccs.GUI/license.txt"] |
[ 21:37:43 INF] License wikitraccs-full-edition-xlarge, valid from 2024-05-13T12:01:00, to 2025-05-13T12:01:00 |
License missing
If no license key file could be found, the log looks like this:
[ 21:59:32 INF] Trying to find license... |
[ 21:59:32 INF] Checking if license file exists in: '/home/user/wikitraccs/WikiTraccs.GUI' |
[ 21:59:32 INF] Did not find license file(s) in: '/home/user/wikitraccs/WikiTraccs.GUI' |
[ 21:59:32 INF] Did not find any license key files. Falling back to Free Edition. Learn where to put the license key: https://www.wikitransformationproject.com/docs/reference/license-activation |
Get in touch if you need help.
3 - WikiTraccs FAQ
This FAQ covers questions folks have while evaluating and using WikiTraccs.
The answers are often short on purpose and nuance might be lost this way. Please refer to the documentation links for an in-depth discussion of the respective topics.
Q: What is the access level needed in SharePoint to migrate spaces to? Same question for Confluence.
A: For Confluence creating a migration account is recommended. The following access levels work for this account: Confluence administrator (recommended), space owner, read-only user. Lesser access means that page restrictions and/or user account information (email address, name) cannot be migrated.
For SharePoint creating a migration account is also recommended. This account should be Site Owner on the SharePoint target sites (or Site Admin when migrating Confluence page restrictions). Furthermore an Entra ID app registration is required. The app needs delegated permissions, ideally FullControl, but Manage works to an extend. Refer to the linked documentation for details.
Further reading:
- More about Confluence permissions here: Authenticating with Confluence
- SharePoint permissions reference (account + Entra ID app, per scenario): Required permissions for SharePoint Online
- SharePoint authentication overview: Authenticating with SharePoint Online
- Step-by-step instructions for creating Entra ID app registration: Registering WikiTraccs as app in Entra ID
Q: What if we don’t have access to a global admin account of SharePoint?
A: You probably don’t need a SharePoint global admin. Here’s what’s needed when preparing the migration:
- in SharePoint Online, create modern sites and assign the migration account permissions - if self-service site creation is enabled then any user can do this
- in Entra ID, register an Entra ID application - this can be done by an account with Application Developer role in Entra ID, but see the linked Microsoft documentation for more details; this has to be done once as prerequisite to using WikiTraccs
- only if a new migration account is to be used for SharePoint: in the Microsoft 365 administration, create a migration account - this needs the User Administrator admin role
- only for WikiPakk: in SharePoint Online, add the WikiPakk app from Microsoft AppSource to the global tenant app catalog - the user doing this needs to be Owner of the tenant app catalog site, although it more commonly is the SharePoint administrator
Further reading:
- More on who can create and configure Entra ID applications: Delegate app registration permissions in Entra ID
- Step-by-step instructions for registering the application in Entra ID: Registering WikiTraccs as app in Entra ID
- Required permissions for the Entra ID application and the migration account: Required permissions for SharePoint Online
Q: Will the links between Confluence pages work properly when migrated to SharePoint?
A: Yes, mostly. When a Confluence page is migrated to SharePoint, links to other Confluence pages, spaces, and attachments are transformed to point to the respective SharePoint pages. This is true for soft links, that means “proper” Confluence links. See the next question about hard links and why it’s harder for WikiTraccs to handle those.
Link transformation is done based on a naming scheme WikiTraccs uses for SharePoint page names, thus the target page doesn’t need to exist, yet. You can migrate Confluence page Foo that links to Confluence page Bar, without having to migrate Bar. The link will be transformed and points to a (yet) non-existing SharePoint page Bar - until you migrate page Bar. Then the link works.
Note about versioning: the link will always point to the current page version in SharePoint since WikiTraccs only migrates the current page version.
Further reading:
- In-depth information: Confluence Link Types Explained
- Details about hard link handling: WikiTraccs 1.6.4 Release Notes
- Feature description: Features ⇒ Links specific to Confluence
- For cross-space links to work the space to site mapping has to be configured in the Space Inventory: Cross-space links and target sites
Q: What is a Hard Link for WikiTraccs? And why is it hard for WikiTraccs to migrate hard links?
A: Hard links are plain old HTML links that Confluence is oblivious of, from a metadata standpoint. Technically, hard links appear like any other text content on a Confluence page. And also technically, they lack important metadata that is needed to locate the target page - a page ID, page title or space key. Sometimes those links make it into a Confluence page, mostly by pasting text into a page. As long as the target Confluence page does not change much those links work. But upon renaming the target page those links might break.
To transform a Confluence link to a SharePoint link WikiTraccs needs to know which Confluence page or space a link points to. As the needed metadata is only present with soft links and missing for hard links, WikiTraccs might not be able to transform hard links.
Since release 1.6.4 WikiTraccs has basic hard link support. WikiTraccs looks for hard links and tries to figure out the target page. If that is successful the hard link is transformed to a proper page link in SharePoint.
Further reading:
- In-depth information: Confluence Link Types Explained
- Details about hard link handling: WikiTraccs 1.6.4 Release Notes
- Feature description: Features ⇒ Links specific to Confluence
Q: How do you know which spaces and pages can/can’t be migrated from Confluence?
Q: Can I choose which space I want to migrate so I can migrate batches of spaces?
Q: What granularity does the selection of migrating give us? Space-by-Space? Page-by-Page?
A: Migration with WikiTraccs is done on a per-space basis. You choose Confluence spaces to migrate, and which target SharePoint site to use as migration target. All pages from the source space will be migrated to the chosen target.
Technically, there is no restriction as to which Confluence spaces can be migrated. Everything the Confluence migration account sees will be seen, and can be migrated by WikiTraccs.
You choose which spaces to migrate in the Space Inventory, a list that WikiTraccs creates in SharePoint. WikiTraccs stores basic information about each space it finds in Confluence in this list. You then tick a box for all spaces that should be migrated. When starting the migration, WikiTraccs looks at this list to know what to migrate, and to which sites.
Migrating spaces in batches can be done by adjusting the space selection in the Space Inventory: select spaces for a batch, then migrate; for the next batches, adjust the space selection accordingly.
Further reading:
- Documentation: Confluence Space Inventory
- For cross-space links to work the space to site mapping has to be configured in the Space Inventory: Cross-space links and target sites
Q: Do the versions of Conflunence pages also get migrated?
A: No. Only the current version of pages and attachments will be migrated.
Q: Is having WikiPakk the only way to keep the left page tree menu like we currently have in Confluence? Is subscription charging the only way for WikiPakk?
A: WikiPakk is the only ready-made option I’m aware of that shows a SharePoint page tree and breadcrumb, for migrated and out of the box SharePoint pages. At this time a monthly subscription is the only supported payment model. A yearly subscription option will be added soon. If you’d prefer another model, please let me know as demand drives development.
Technically you could develop another form of visualization. The metadata that WikiTraccs creates for each migrated page in SharePoint contains the Confluence page ID, parent Confluence page ID and space key. That is all that’s needed to visualize the hierarchy.
Q: If the execution is interrupted during migration, will it restart where it stopped? We have lots of spaces and access restrictions per team.
A: Yes, WikiTraccs is very forgiving with respect to interruptions. The migration can be interrupted at any time and continues where it left off.
Q: Will it also migrate spaces/pages restrictions as well or we will have to do manually? Please, show us how to migrate also the users/team permissions on migrated pages.
A: WikiTraccs can migrate permissions, to the extend possible given the differences between Confluence and SharePoint. In Confluence you have a page hierarchy and access to each page in this hierarchy can be restricted, at each level. SharePoint in comparison has no hierarchy, just a bunch of pages in the Site Pages Library. There is no permission hierarchy on pages in SharePoint.
Furthermore, when moving from Confluence to SharePoint Online, you need to think about groups. Are all groups from all Confluence user directories that take part in the Confluence permission scheme present in Entra ID? WikiTraccs does not create groups.
The bottom line is that permission migrations - while possible to an extent - rarely make sense.
Further reading:
- Refer to this blog post for instructions on how to migrate permissions, and for a list of capabilities and restrictions with regard to permission migration from Confluence to SharePoint: Mapping principals and migrating permissions
Q: Currently our SharePoint only creates “Modern Pages”, and we cannot create “Wiki Style pages” is that a problem?
A: Perfect, WikiTraccs creates modern pages as well. Classic pages are not supported.
Q: In the target SharePoint site I see in the “+ New” button we now have a new option “Site Page (transformed by WikiTraccs)”, why is this?
A: That’s a new page content type created by WikiTraccs, that is derived from the standard SharePoint content type Site Page. It contains additional fields to hold metadata from Confluence and about the migration. It’s a technical artifact and should be hidden from the user. (#76)
Q: If a page or space makes use of a template (Jira Report / Decision / Sprint Review / etc.) can it be migrated to SharePoint and keep the template working in SharePoint?
Q: If the page has buttons will the button continue to work on SharePoint with same behavior?
Q: There are numerous page templates w/in Confluence. How does WikiTraccs handle page templates (page layout/structure)?
A: WikiTraccs migrates Confluence pages to SharePoint Online modern pages. It transforms the content of Confluence pages to something that can be shown in a SharePoint page, and is limited by what SharePoint has to offer (layouts, web parts, formatting, …). WikiTraccs has no explicit knowledge of templates.
What WikiTraccs recognizes is the use of Confluence page layouts with sections, like “two column section” or “three column section with side-bars”. Those will be translated to SharePoint page sections, which are comparable.
Overall, you can think about it this way: WikiTraccs can do in an automated fashion what you can do manually in SharePoint. If you cannot create something in SharePoint, WikiTraccs can’t do it either. But if you can create it, WikiTraccs could be able to do it as well, if it’s not already doing it.
Further reading:
- This overview covers what WikiTraccs can do: Feature Overview. If you think something should definitely be in there, please create a feature proposal.
- Confluence page layouts, sections, columns, and panels.
Q: Will the tool flag if it could not properly migrate a page or space?
A: Yes. WikiTraccs measures migration success on two levels: page and space.
For page content migration success WikiTraccs collects indicators. Those indicators are stored with the page in the Site Pages library. You look at those indicators to find problematic pages, in each target SharePoint site.
For space content migration success WikiTraccs creates progress log files for each migrated space. You can see which pages have been migrated, how many are yet to be migrated, and more.
Further reading:
- Page migration success: Measuring page migration success
- Space migration progress: Monitoring Confluence to SharePoint Migration Progress
- And for general diagnosis of issues: common log files
Q: How does the tool decide if it should create a Team site, Hub site or a communication site when migrating? Can the tool decide this automatically?
Q: Does the tool always require a blank target site in SharePoint?
Q: If we point the tool to target a SharePoint url destination that already has content with same title, will it be overwritten, or the tool will create a new site keeping any existing SharePoint site intact?
A: WikiTraccs does not create SharePoint sites. You need to create or choose target SharePoint sites for the migration. Note: the target sites need to have the Site Pages feature enabled which is on by default for modern sites.
You enter the target SharePoint URLs into the Space Inventory.
Deciding the right type and number of target sites in SharePoint is out of scope of WikiTraccs and would be part of a transformation project of any kind.
Further reading:
Q: Is it better to centralize the migration in one team? WikiTraccs seems to requires us to migrate from the root URL of Confluence, if not, there will be an error.
A: The migration could be done by multiple teams. For that to work you would create clusters of source space and target sites and assign each team one cluster. Each team could use different migration accounts for Confluence and SharePoint. This way each team would only see content from their cluster. Keep in mind that this might break links between pages if WikiTraccs cannot access both the source and target page/space.
Regarding the root URL: WikiTraccs uses the Confluence REST API and needs to know the Confluence base URL to find the correct REST endpoints.
Q: I find it difficult to understand what pages I was selecting comparing against the left page tree view menu. I want to migrate only pages under menu “FAQ”. How can we do that in the “Confluence Space Inventory”?
A: WikiTraccs migrates spaces. It does not allow selecting single pages or parts of the page tree for migration. If you want to migrate only some pages of a Confluence space to SharePoint you need to migrate the whole space and delete the content from SharePoint that you don’t need.
Further reading:
- Feature proposal to allow selecting pages via CQL query: #77
Q: How much time does it take to migrate?
A: The migration time depends on a number of factors. Let’s look at each of those:
Need an estimate?
Try the Migration Duration Estimator.- SharePoint usage and throttling affects migration time
- depending on the usage of Microsoft 365 worldwide and the region you are in the speed of SharePoint-related operations can vary; migrating on a weekend might be faster than during working hours
- also depending on the overall Microsoft 365 service usage clients might be throttled; this means for WikiTraccs that sometimes it has to wait before being allowed to create new content; this is also why it might make limited sense to run parallel migrations - throttling might occur faster
- throttling can happen at any time, slow cloud perforformance can happen at any time
- the speed of a SharePoint tenant as well as throttling limits depend on the number of active licenses in the tenant; thus migrating to a SharePoint test environment might be slower that migrating to a production environment
- page contents affect migration time
- migrating a simple page from Confluence to SharePoint on average seems to take about 4 to 8 seconds
- migration time per page will be higher if the page links to page-external content, like Jira issues (causes request to Jira server), external images (causes download of external image), and other Confluence pages, spaces, or attachments (causes additional requests to those Confluence resources)
- attachments affect migration time
- each attachment has do be downloaded from Confluence and uploaded to SharePoint Online
- downloading from Confluence takes time that is dependent on the Confluence instance’s performance
- uploading to SharePoint can take anything up from half a second
- larger attachments take more time
- the number of pages per space can affect migration time
- when starting and stopping the migration of a Confluence space WikiTraccs requests the list of pages for that space from Confluence, to fuel progress bars and measure migration success
- for spaces with a large number of pages (say 10000 pages and up) getting the list of space pages can take minutes - this is a known Confluence issue
- the time to retrieve pages from such a large space can vary; one Confluence instance might return a list of 25000 pages in 20 seconds, another instance might take half an hour
- Confluence Cloud usage and throttling affect migration time
- your internet download speed, upload speed, and connection stability affect migration time
- fast download speed helps getting content from Confluence
- fast upload speed helps pushing content to SharePoint
- a stable connection helps preventing retry-loops that WikiTraccs has build in to work around unstable network conditions
WikiTraccs migrates pages one by one and does not parallelize. You can parallelize the migration by running a second WikiTraccs instance on another machine.
Further reading:
- How much time will a Confluence to SharePoint migration take?
- Documentation about the challenges of large spaces: Migrating large Confluence spaces to SharePoint
- Feature proposal to speed up migrating large Confluence spaces: #69
- Documentation about throttling by Microsoft
Q: Has WikiTraccs ever done a big migration / Enterprise level like ‘big company’?
Q: We Have at least 350 Confluence wiki spaces to migrate to SharePoint. Is there a batch of so many wiki spaces you can do in one run?
Q: We have multiple attachments currently in the Confluence wiki spaces and is there a limit how many attachments can be migrated to a SharePoint site?
A: The largest successful WikiTraccs-based migration that I know of “in the wild” consisted of ~160 spaces and ~200,000 pages. The largest space had ~20,000 pages. Note that I’m not aware of customers that did restriction/permission migrations and would advise against it, as SharePoint works differently that Confluence with regard to permissions.
The largest migration in a test environment has been ~3,000 spaces, consisting of ~120,000 pages, having ~360,000 attachments that where ~850 GB in size - all migrated from Confluences to a single SharePoint target site collection.
In principle there is no defined technical limit to the number of pages or attachments WikiTraccs an migrate, and SharePoint can ingest within its impressive limits. It’s just that migrating and verifying takes longer with every space, page and attachment that is part of the migration.
The “Is there a batch of so many wiki spaces you can do in one run?” question carries additional topics: the concept of a batch and run. In my view a batch would be the Confluence content to be migrated as configured via the Space Inventory list. You defined the size of the batch. A run would be what WikiTraccs does after kicking off the migration. It will migrate the content one page after another.
One note regarding the you can part of the question; this might just be a phrasing issue, but to be clear: The Wiki Transformation Project does not offer consulting services and does not take part in migration projects. The Wiki Transformation Project provides the tool WikiTraccs that can be a vital part of your Confluence to SharePoint migration tool belt, as well as WikiPakk to provide a SharePoint page tree experience that will make users happy.
Further reading:
- Documentation: Confluence Space Inventory
- How to map Confluence Spaces to SharePoint Sites
- Hints about what you should consider as part of your migration project: Migration Playbook
- More about the SharePoint breadcrumb and page tree experience: WikiPakk
Q: Do you provide consulting services?
Q: Can you provide more details about the PS costs that you can share?
Q: Are there maintenance fees?
Q: Do you offer any professional services to assist our team, if required?
A: The Wiki Transformation Project provides unrestricted break-fix support via email and GitHub.
Read more about your options here: Support Options
With regard to consulting services (advisory services, premier support, alliance support, etc.): The Wiki Transformation Project does not offer consulting services and does not take part in migration projects. The Wiki Transformation Project provides the tool WikiTraccs that can be a vital part of your Confluence to SharePoint migration tool belt, as well as WikiPakk to provide a SharePoint page tree experience that makes users happy. I might recommend consulting partners though, depending on the region you are operating in.
Further reading:
Q: In your experience what determines the success or failure of a migration project from Confluence to SharePoint?
Q: Do you have a “Default Plan” how we should proceed with such a migration?
Q: What do the success stories have in common?
A: You need to have a plan before thinking about migration tooling.
The Migration Playbook hints at that in the Proof of Concept Phase, Decision, and Analysis Phase.
Providing migration guidance or consulting is out of scope of WikiTraccs. But I might recommend a partner that can help. Get in touch if you are interested in a recommendation.
Q: How long is the trial period for your product (30 days, 60 days or 3 months)?
Q: What limitations are there on using the free eval?
A: When WikiTraccs doesn’t find a license key, it runs in trial (or evaluation) mode.
When running in unlicensed trial mode, WikiTraccs slightly changes the SharePoint pages it creates. It inserts a promotional header, sometimes a footer, and replaces some words in the page with “WikiTraccsTestMigration”. This stops as soon as there is a valid license key.
The trial period of WikiTraccs is as long as you need it to be. There is no end. Try as long as it takes to make an informed decision.
All features are available in WikiTraccs trial mode as well, so you can test them thoroughly. You can perform a test migration of all your Confluence pages; no limits on the number of pages, files, or spaces.
Further reading:
- Separate FAQ around pricing and licensing here: WikiTraccs Pricing
Q: Is the look and feel of the Confluence wiki spaces migrated/transformed to SharePoint site same as in Confluence after it is migrated?
A: This question could refer to the look and feel of the actual Confluence spaces - which will become SharePoint sites - or the look and feel of the wiki pages once they have been migrated to SharePoint.
WikiTraccs does not create or configure SharePoint sites. Creating and configuring SharePoint sites is a manual task that usually is part of a transformational project. This is out of scope of what WikiTraccs can do.
With regard to the migrated Confluence pages the answer is No, the look and feel of the SharePoint pages is not the same as in Confluence.
Confluence and SharePoint are different with regard to layout, styling, metadata, permissions, navigation, user management, and integration with other Microsoft 365 services - so the look and feel will certainly differ. This is something that should be taken into account when introducing SharePoint as Confluence replacement.
I strongly recommend getting to know SharePoint before migrating Confluence content to SharePoint. Create some pages and learn their capabilities.
It's important to note that WikiTraccs creates SharePoint modern pages as wiki pages, not classic pages. Modern pages are part of the SharePoint modern experience which is the future.
Furthermore, when creating modern pages, WikiTraccs aims to create standards compliant pages that a user could have created. This approach is different from other products.
Why is this important? Because when a user edits and saves a migrated page, it will behave like a normal SharePoint modern page, without any formatting disappearing. Besides, it will be friendly to mobile use.
Please refer to the linked pages for more information about WikiTraccs’ capabilities and visual migration samples.
Further reading:
- What can be migrated? Read here: WikiTraccs Features
- Visual migration samples: Migration Samples
- Blog post: What about those Confluence Macros?
Q: Do you need to do any type of tweak or adjustment to make the spaces and attachments look exactly same as Confluence wiki spaces in the SharePoint site(s)?
A: It’s impossible to make the SharePoint sites to look exactly like Confluence, or to make the migrated pages look exactly like the Confluence pages. At least with the approach WikiTraccs takes.
It's important to note that WikiTraccs creates SharePoint modern pages as wiki pages, not classic pages. Modern pages are part of the SharePoint modern experience which is the future.
Furthermore, when creating modern pages, WikiTraccs aims to create standards compliant pages that a user could have created. This approach is different from other products.
Why is this important? Because when a user edits and saves a migrated page, it will behave like a normal SharePoint modern page, without any formatting disappearing. Besides, it will be friendly to mobile use.
The configuration of SharePoint sites is entirely up to you. WikiTraccs won’t do much to a SharePoint site that might be relevant to your use cases.
Migrated Confluence pages will become SharePoint pages - which are different in their capabilities from Confluence pages. For example, Confluence macros are not present in SharePoint. That alone makes a big difference.
Migrated Confluence page attachments stay as they are, as they are just files. SharePoint can store files. WikiTraccs downloads Confluence page attachments and uploads them to the SharePoint Site Assets library, the default place for page attachments in SharePoint. Page attachments can be made visible per SharePoint page via a list view web part, that WikiTraccs can insert at the end of a page.
Q: Are there Confluence standard macros which won’t be migrated?
Q: Confluence allows for many “macros” and application integrations. What happens when WikiTraccs encounters such application integrations?
A: For most macros and integrations it’s technically impossible to migrate them to SharePoint.
You can make an experiment: choose a Confluence macro you’d like to see migrated to SharePoint. In a modern SharePoint page, try to rebuild what that macro does.
Could you rebuild the macro functionality in SharePoint? Good! WikiTraccs could do the same. If WikiTraccs does not yet support your scenario - get in touch, tell me about your solution!
But most likely you won’t be able to find anything in SharePoint that could be a drop-in replacement for your chosen macro. And in this case WikiTraccs cannot find one, either.
Further reading:
- See how certain Confluence macros are handled: Known Confluence Macros
- Blog post: What about those Confluence Macros?
Q: Confluence is also integrated with Jira, and most likely utilizing linked/embedded Jira EPICs, FEATUREs, etc. - How does WikiTraccs handle this situation?
A: There are different Jira macros that can be used to show Jira-related content in Confluence pages, as well as link to those contents.
One macro allows to link to a single Jira issue. WikiTraccs converts this macro to a simple hyperlink, that links to the respective Jira issue. When users click those links in SharePoint they are redirected to the external Jira application.
As of this writing, all other Jira macros are replace by a static placeholder text. Corresponding feature request: #102.
Further reading:
- See how certain Confluence macros are handled: Known Confluence Macros
- Blog post: What about those Confluence Macros?
Q: Is it a one to one Confluence wiki space migration to SharePoint? So 350 wiki spaces will be migrated to 350 different pages and spaces in SharePoint site?
A: WikiTraccs migrates the pages of Confluence spaces to SharePoint sites. You configure the space to site mapping.
When migrating a space, all pages of this space are migrated.
Each space can go to its own target SharePoint site.
Multiple spaces can go to one target SharePoint site.
Note: Currently it’s not possible to “split” a space, migrating its pages to different target SharePoint sites.
For migrating 350 Confluence spaces to 350 target SharePoint sites the process would roughly be as follows:
- create 350 target SharePoint sites and configure them according to your concept; using PnP PowerShell and PnP templates is one common approach to automate site creation
- use WikiTraccs to automatically fill the Space inventory list with information about those 350 Confluence spaces
- map each space to its target site URL
- select spaces to migrate
- start the migration using WikiTraccs
Further reading:
- How to map Confluence Spaces to SharePoint Sites
- Feature proposal to allow selecting pages via CQL query, which would allow “splitting” spaces: #77
Q: Can we do all this in one license or we have to purchase multiple licenses?
A: You buy one WikiTraccs license with the appropriate Page Count Tier and are good to go. There are currently no feature-dependent licenses.
Have a look at the Pricing page for details.
Q: What does the “Page Count Tier” (or “number of pages”) mean?
A: The Page Count Tier refers to the sum of pages and blog posts in the source Confluence environment, at the time of purchase.
The following four tiers are available:
- up to 10,000 pages
- up to 50,000 pages
- up to 100,000 pages
- over 100,000 pages
Note that this is not the number of pages you plan to migrate. Also note that this is not the number of page migrations that you can do.
Here are examples for illustration:
- Example 1: There are 20,000 pages and blog posts in Confluence. You plan to migrate all of them. The license needed is “up to 50,000 pages”, because that covers the source environment’s number of pages and blog posts.
- Example 2: There are 45,000 pages and blog posts in Confluence. You plan to migrate 7000 pages to SharePoint. The license needed is “up to 50,000 pages”, because that covers the source environment’s number of pages and blog posts.
- Example 3: There are 9,000 pages and blog posts in Confluence. You migrate all 9000 pages. Something happens and you need to migrate 5000 of those pages a second time. The license needed is still “up to 10,000 pages”, because that covers the source environment’s number of pages and blog posts.
Further reading:
Q: Is it per-license cost or do you provide an enterprise license model?
A: The cost is per WikiTraccs license key. The purchased license key is for internal use, sublicensing or providing services to a third party is not permitted. The third party would have to acquire a separate license key.
Further reading:
Q: How many licenses we need to complete the project?
A: That depends on the duration of your project.
A WikiTraccs license key is valid for a 6-month period, starting with the date of the purchase. After 6 month you would need to purchase a new license, that again is valid for 6 month.
You need one such license for WikiTraccs with the appropriate Page Count Tier. Have a look at the pricing page for details: Pricing.
Q: Do you recommend each Confluence space to a SharePoint Online subsite?
A: Microsoft does not recommend using subsites in SharePoint Online, and WikiTraccs cannot migrate to subsites. So, I would advise against it.
Further reading:
- Introduction to SharePoint information architecture > Guiding principle: the world is flat
4 - Prerequisites
Prerequisites of the Migration Machine
Operating System
WikiTraccs runs on Windows.
Tested so far have been Windows 10, Windows 11, Windows Server 2012 R2, Windows Server 2016, Windows Server 2019, Windows Server 2022.
If Confluence only supports TLS 1.3, choose Windows 11 or Windows Server 2022. See the note about TLS 1.3 below.
Hardware
Note
The following are tested configurations. Others will work as well.| Component | Works |
|---|---|
| CPU | 64-bit 2.6-GHz quad core processor |
| RAM | 16 GB |
| Operating system | Windows 11 client |
| Component | Works |
|---|---|
| CPU | 64-bit 3.1-GHz quad core processor |
| RAM | 24 GB |
| Operating system | Windows Server 2012 R2 Standard |
Provide enough storage for all of Confluence to be downloaded. Confluence has 500 GB of attachments? Provide at least 500 GB of hard drive storage.
Note
The local storage requirement is dependent on the amount of transformed content. Refer to the data storage article for details.Software Requirements
An up-to-date version of either the Google Chrome or Microsoft Edge browser needs to be installed (for authenticating with Confluence, refer to the authentication article for details on authentication)
Note
If your Confluence Cloud is protected by a CASB such as Microsoft Defender for Cloud Apps Conditional Access App Control, interactive (cookie) authentication can fail. See Confluence behind a security proxy.Windows Configuration
The Windows swap file should be at least 12 GB of size. This proved to be helpful in low-memory environments (e.g. only 3 GB of RAM in a Windows VM) to prevent out of memory errors. It probably won’t be necessary with more RAM, but it doesn’t hurt either.
Endpoint Requirements
Refer to the endpoints article on required endpoints.
Security Note
WikiTraccs doesn’t need to run with admin rights, and should not be run with admin rights.
Note that WikiTraccs automatically downloads a WebDriver tool that is used to automate the Chrome or Edge browser window to allow interactive login for Confluence. There have been a couple of cases where either this download, or the WebDriver have been blocked from running. Unblocking the WebDriver or running WikiTraccs with admin rights tended to solve the issue in those cases.
Note about TLS 1.3
When the Confluence server only supports TLS 1.3 connections, you have to run WikiTraccs on a Windows version that officially supports TLS 1.3; those are Windows Server 2022 and Windows 11.
There have been issues reported where the Confluence server was upgraded to only support TLS 1.3 and Windows subsequently failed to properly negotiate a cipher. Please test this scenario before starting the migration or refrain from changing the TLS protocol during the migration. A workaround is available, though, in the form of the WikiTraccs proxy mode.
5 - Installation and Update
Downloading and running WikiTraccs for the first time
Downloading and running WikiTraccs for the first time is covered in the Getting started guide, in section STEP ONE: Download WikiTraccs.
It boils down to downloading and extracting a zip file. No installation needed.
Updating WikiTraccs
Find new WikiTraccs Releases in on GitHub: WikiTraccs Releases.
Tip
Activate notifications for releases on GitHub to stay up to date with new releases.Update Steps
- Download the latest WikiTraccs release zip file from the WikiTraccs GitHub
- Unzip the WikiTraccs release zip file into a new folder
- Note: If you need more details, refer to the Getting started guide, section “STEP ONE: Download WikiTraccs”
- If using a licensed version: Copy license.txt from the previous WikiTraccs installation location to the new location
- Optional: Copy appsettings.json from the previous WikiTraccs installation location (note: only if you use appsettings.json)
- Note: appsettings.json is probably stored in the WikiTraccs.GUI folder, but can also exist in the WikiTraccs.Console folder; handle both
- Optional: Copy macro transformation templates from the previous WikiTraccs installation (note: only if you use macro transformation templates)
- Run WikiTraccs from the new folder
You are now running the new version of WikiTraccs.
Additional Information
You might want to keep the old WikiTraccs release around in case you need to switch back to the old version or have a look at old log files.
The settings configured via the WikiTraccs.GUI “blue window” are preserved automatically across updates, not need to copy anything manually. Those settings are stored in the current Windows user’s app directory. For details about the location, see File Storage. Note that this is not the same as appsettings.json, but a settings file WikiTraccs uses to store settings you configure in the blue WikiTraccs.GUI window. You can back up and restore this settings file.
Note
Don’t modify this settings file, it belongs to WikiTraccs.GUI. Use appsettings.json if you must add settings not available in the user interface.6 - Settings & Configuration
How to configure WikiTraccs
You’ll start configuring WikiTraccs and your Confluence to SharePoint migration at two places:
- inside the blue window that is WikiTraccs.GUI
- in SharePoint lists that WikiTraccs creates, in a SharePoint site you create (the WikiTraccs site)
Tip
Use WikiTraccs.GUI to get started quickly. Use it to configure source, target, and authentication options. Use the quick start guide.In most cases, using the blue WikiTraccs.GUI window and the SharePoint lists for configuration is enough.
Some settings, though, aren’t available for visual configuration in WikiTraccs.GUI. For those you need to use another approach that involves a configuration file.
Both approaches are described in the following sections.
The visual and convenient configuration via WikiTraccs.GUI
Tip
This is the recommended approach.In WikiTraccs.GUI an often-used subset of configuration options is available for visual configuration.
The following settings and functions are available in WikiTracs.GUI (or a SharePoint list it creates), no need to use the config file for those:
- Confluence migration source and spaces
- SharePoint target tenant and sites
- authentication for Confluence and SharePoint
- initial Space Inventory population
- migration mode: migrate content, update date and people fields, update permissions
- re-migrate content that had errors
- add link to source page or not
- macro ignore list
- translation migration mode for pages with translations
This is everything needed to get a migration going.
One SharePoint list central to configuring WikiTraccs is the Confluence Space Inventory list, or short Space Inventory. This list is created and populated by WikiTraccs when you select the Update Space Inventory in WikiTraccs site button.
WikiTraccs overall creates the following lists in the WikiTraccs Site when you select the Update Space Inventory in WikiTraccs site button:
- Confluence Space Inventory - for you to select what to migrate, and where
- Confluence User and Group Mapping - for you to map Confluence user accounts to Entra ID accounts (and groups)
- WikiTraccs Locks - for internal use
- Confluence Permission Snapshots - for internal use
The following resources have more information:
- The quick start guide covers configuring migration source, migration target, and authentication for Confluence and SharePoint: Getting Started
- Migration settings are documented here: Configuration via WikiTraccs.GUI (blue window)
- Everything you need to know about the Space Inventory is covered here: Confluence Space Inventory
The more involved configuration via config file and WikiTraccs.Console
Note
If you are just getting started with WikiTraccs, you probably won’t have to read further. Above section about WikiTraccs.GUI should cover everything you need.More settings are available via WikiTraccs.Console and a configuration file. Only when you want to change those settings you have to use the configuration file.
Use the configuration file for the following advanced scenarios or non-default configurations:
- changing the configuration often, e.g. for automation purposes
- using different authentication methods for different target SharePoint sites
- toggling feature and debug flags not available in the GUI
- changing the location where Confluence content is stored during the migration
- manually configuring the Chrome/Edge driver for Confluence login in a locked-down environment
- configuring timeouts for external domains
- migrating single pages by page ID
The following resources have more information:
6.1 - Configuration via WikiTraccs.GUI (blue window)
This article assumes you are using the blue WikiTraccs.GUI window to configure your migration.
To open the settings dialog, click Settings in the top menu bar.
The following sections describe settings in detail.
Tab “Migration”
Migration Mode
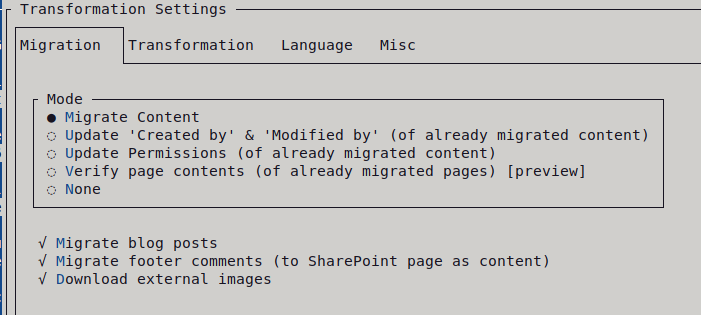
Note: Screenshot of WikiTraccs version 1.17.2; might look different in a recent version.
Mode “Migrate Content”
This mode selects content migration.
Content will be migrated from Confluence to SharePoint. This is probably what you would expect from a migration tool.
You’ll always use this mode first.
WikiTraccs downloads content (pages, attachments, …) from Confluence, transforms it to something SharePoint can understand, and creates corresponding SharePoint content (modern pages, files, …).
Mode “Update ‘Created by’ & ‘Modified by’ (of already migrated content)”
This mode can be used to update the Author and Editor metadata of SharePoint pages.
Background
Confluence pages have an author and an editor. The author created the page and the editor last edited the page. SharePoint pages also have an author and editor.
WikiTraccs can migrate this metadata as well so that the created SharePoint pages have the same author and editor as in Confluence. To be able to do that, WikiTraccs needs a mapping from Confluence user accounts to Entra ID user accounts.
The user mapping is done in the Confluence User and Group Mapping (WikiTraccs) list in the WikiTraccs site. Have a look here on how to configure this mapping: Mapping Confluence users and groups to SharePoint. If Confluence accounts and Entra ID account have the same email addresss WikiTraccs might be able to prepopulate the mapping. Otherwise that is a manual task. Using PnP.PowerShell to automate this is recommended if the number of users is high.
What does the update mode do?
Assume that the user mapping list did not yet contain all user mappings when migrating pages (using mode Migrate Content).
After migrating pages, you’ll end up with SharePoint pages having the migration account as author and editor. That’s because WikiTraccs doesn’t know about the corresponding Entra ID account.
But that’s ok. Actually, that is how it’s supposed to work:
- You migrate content from Confluence to SharePoint
- During the migration, WikiTraccs adds all Confluence users it encounters to the mapping list
- You configure the user mapping
- You use the update mode to update the author and editor of existing SharePoint pages according to the mapping
So, you first run the migration in Migrate Content mode. Then, after configuring the mapping, you run the migration again, in Update ‘Created by’ & ‘Modified by’ mode.
Note
In this mode no content will be migrated from Confluence to SharePoint. This mode is just for updating the author and editor of SharePoint pages.Mode “Update Permissions (of already migrated content)”
This mode is for applying page restrictions from Confluence to already migrated SharePoint pages.
This blog post has all the details about migrating permissions (and also why you should avoid doing it): Mapping principals and migrating permissions
This mode is two-phased like the Update ‘Created by’ & ‘Modified by’ mode:
- You migrate content from Confluence to SharePoint
- During the migration, WikiTraccs adds all Confluence users it encounters to the mapping list, plus it stores information about all restrictions in the Confluence Permission Snapshots library in the WikiTraccs site
- You configure the user and group mapping
- You use the update mode to update SharePoint page permissions according to the mapping
Please refer to the blog post linked above, it has all the details.
Note
In this mode no content will be migrated from Confluence to SharePoint. This mode is just for updating the permissions of SharePoint pages. However, WikiTraccs will reach out to Confluence if (for whatever reason) a permission snapshot cannot be found in the Confluence Permission Snapshots library in the WikiTraccs site.Important
The permissions WikiTraccs applies to already migrated SharePoint pages is based on permission snapshots taken at page migration time. Those snapshots are stored in the Confluence Permission Snapshots library in the WikiTraccs site.
That means that any updates to page restrictions in Confluence will not be reflected in the permission update mode run.
If you want WikiTraccs to update a permission snapshot, you need to delete either the SharePoint page and migrate it again, or delete the permission snapshot from the Confluence Permission Snapshots library. WikiTraccs will then reach out to Confluence to get the latest page restrictions and recreate the permission snapshot.
Mode “Verify page contents (of already migrated pages)”
Currently, you won’t need this mode. It is kind of “for future use”.
If you want more details, please refer to the release notes of WikiTraccs v1.12.5, section Verification Mode.
Migrate blog posts
Choose whether to migrate blog posts or not.
Migrate footer comments
Choose whether to migrate footer comments or not.
Download external images
Choose whether to download external images or not.
Confluence pages can contain images from external sources. Those images are not in the page attachments, but are retrieved from an external source when opening the page in Confluence.
SharePoint Online doesn’t allow adding images from external non-Microsoft sources. All images that you link to have to be a file in SharePoint, or a related Microsoft-owned service. The reasoning behind this decision is probably user privacy. External images can be used to track user behavior.
WikiTraccs can download external images and “convert” them to SharePoint page attachments, so the images can be shown in SharePoint.
One possible caveat is that - especially older - Confluence pages might link to images that don’t exist anymore. WikiTraccs will still try to download them - which can take time, if the external source is responding very slowly.
If downloading external images is slowing down your migration you can use this setting to toggle it off.
6.1.1 - Gray Settings
You can find the Gray Settings group in the WikiTraccs Transformation Settings dialog, on the Migration tab, below a label that reads Gray Settings.
What is a “Gray Setting”?
A gray setting is a setting that activates behavior WikiTraccs cannot fully guarantee will keep working over time. The behavior depends on a mechanism that is not officially documented as supported by Microsoft or Atlassian. It works today, but a future change to SharePoint, Microsoft 365, Confluence, or the underlying editors could break it.
Current Gray Settings
Migrate whiteboards as image [Cloud]
Confluence Cloud whiteboards are migrated as a static image embedded in the SharePoint page. The image is generated by WikiTraccs by interacting with Confluence in an automated browser session.
This is gray because the export relies on automated clicking through the Confluence Cloud whiteboard UI rather than on a stable public API. Any change Atlassian makes to that UI can break the automation.
For details, see Migrating Confluence Cloud Whiteboards.
Migrate whiteboards to draw.io file [Cloud, best effort]
Confluence Cloud whiteboards are migrated to a draw.io diagram file that is added to the SharePoint page as a page attachment, preserving the underlying shapes and connectors as far as practical. The file is not editable inside SharePoint, but it can be downloaded and edited in an external draw.io editor.
This is gray because the conversion is best effort. Whiteboards can use shapes, layouts, and content for which no clean draw.io equivalent exists, so the migrated file may need manual cleanup. It is also subject to the same Cloud-mechanism caveat as the image export above.
For how to download a draw.io attachment from a SharePoint page and open it in the draw.io editor (app.diagrams.net), see Converting Gliffy and draw.io to SVG. For insights into how Confluence whiteboards work internally, and why a structured draw.io export is non-trivial, see Inside Confluence Whiteboards.
Use non-standard table transformation
When checked, WikiTraccs preserves table features that the SharePoint Text web part stores correctly but does not always expose as toolbar buttons in the browser-based page editor. As of 2026, this primarily affects nested tables: a <table> inside a table cell is kept in place rather than being de-nested into a separate area below.
This is gray because, although SharePoint stores and renders the resulting tables, end users cannot create the same structures by clicking buttons in the editor toolbar. A future change to the editor could in theory remove or alter how such tables are handled. In practice this has been working reliably and is on by default.
For background and history, see Making SharePoint Tables Look Pretty. For details on how nested tables are handled - what stays nested and what gets denested - see Nested Tables From Confluence to SharePoint.
6.1.2 - Misc Settings
You can find the following settings in the WikiTraccs Transformation Settings dialog, under the Misc tab.
Check for WikiTraccs updates
WikiTraccs can check if new releases are avaible. It does so by reaching out to GitHub to read the list of WikiTraccs releases.
If new releases are found, their version numbers (both latest published and pre-release) will be shown at the top of the blue WikiTraccs window.
WikiTraccs will not automatically download or install an update. You have to do that manually.
You should leave that checked, as new versions often improve the transformation for existing or new macros.
Add Confluence backlink to SharePoint pages
This adds a link to the original Confluence page to the end of each migrated page. This is mainly for testing, to quickly jump back from SharePoint to Confluence to have a look at the original page.
You probably won’t need that setting.
Proxy Confluence API calls through browser
Normally, once authenticated, WikiTraccs talks to Confluence directly. There were cases, though, where this direct communication was disallowed due to Kerberos configuration. In the affected environments, only the browser was allowed to talk to Confluence.
This setting was introduced to quickly work around that.
What this setting does, when starting a migration run:
- WikiTraccs opens a brower under its control
- You need to authenticate to Confluence in this browser
- WikiTraccs injects a piece of proxy JavaScript into the browser
- WikiTraccs will issue all requests to Confluence to the browser proxy script, which forwards the request to Confluence and returns the result back to WikiTraccs
With this setting, from Confluence’s point of view, all requests originate in the browser.
Note that this will make the migration process slower, as requests to Confluence will be issued in a serial manner, wheras WikiTraccs otherwise would issue parallel requests. The browser will be a bottleneck.
You probably won’t need that setting.
Save page storage XML to disk
This setting tells WikiTraccs to store the Confluence Storage Format for every page to disk.
This setting is mainly for troubleshooting purposes and you probably won’t need it.
Save template XML to disk
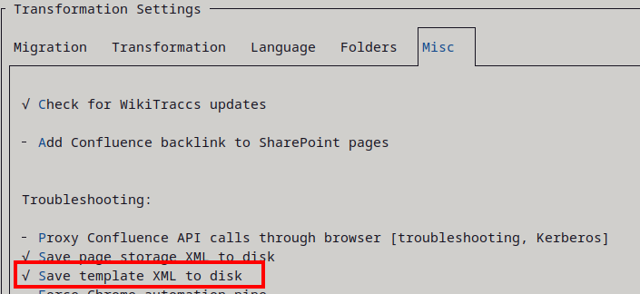
This setting tells WikiTraccs to store the template XML file for every SharePoint page to disk.
This setting is mainly for troubleshooting purposes and you probably won’t need it.
Template files will be stored in the attachment registry. The location of the attachment registry is configured via Settings > Folders > Attachment Registry Folder Path.
For example, given an attachment registry path of D:\attachments, the template files for a page with ID 123456789 might be stored in the following location:
D:\attachments\USERKEY\CONFLUENCEBASEADDRESS\Attachments\123456789__page/pnp-123456789-wikitraccs-attachments-template.xml(attachments template)D:\attachments\USERKEY\CONFLUENCEBASEADDRESS\Attachments\123456789__page/pnp-123456789-wikitraccs-page-template.xml(page template)
Note that the filename starts with pnp- and contains the page ID.
Skip connection checks when starting transformation
Normally WikiTraccs checks connectivity to crucial endpoints on each start of a migration run. This ensures that you can be informed of missing prerequisites early, before running into issues during the migration.
Checking connections takes a bit of time on each migration start, so you might decide that everything is ok, will stay ok, and that the connectivity checks can be skipped. You can use this setting to skip the connection checks.
You can also skip the connection checks when troubleshooting connectivity issues and want to jump faster to the migration run, to diagnose in that context.
Force show all automated browser windows / Force hide most automated browser windows
WikiTraccs will open a real browser window (under its control) to perform certain tasks. Among those tasks are:
- opening Confluence for you to log in (with interactive authentication)
- exporting whiteboards in Confluence Cloud (more info: Migrating Confluence Cloud Whiteboard)
- proxying requests to Confluence if the “Proxy Confluence API calls through browser” setting is checked (more info: Kerberos)
- measuring table sizes (more info: Table Size Optimization)
- creating draw.io preview images (more info: WikiTraccs Creates Draw.io Preview Images)
And the list grows.
WikiTraccs decides which of those browser windows to show, and which to hide.
Using the “Force […] automated browser windows” settings, you can control how many of those browser windows you want to see.
If you want to show all browser windows - for troubleshooting purposes, or out of curiosity - check Force show all automated browser windows.
If you want to hide most browser windows - to reduce visual clutter - check Force hide most automated browser windows. This setting will still leave some browser windows visible, for example the browser window for interactive authentication, as hiding this would make no sense.
Restart WikiTraccs for changes to those settings to take full effect.
Skip table size optimization
Use this setting to disable browser-based table size optimization.
Starting with release v1.30, WikiTraccs opens a browser window for each table it transforms from Confluence to SharePoint, to learn about the size of each table column. Read more about that here: Table Size Optimization.
Note that disabling this setting should still produce tables that look good in SharePoint. Table size optimization is optional. One immediate difference you might see is that narrow Confluence tables will be much wider in SharePoint. It is to get rid of such quirks that the table size optimization has been introduced for.
6.2 - Confluence Space Inventory
Facts about the Confluence Space Inventory
The Confluence Space Inventory - or short Space Inventory - is a SharePoint list that serves the following purposes:
- list all Confluence spaces; those can be marked as migration source, making them a space selector
- allow configuring additional source content selectors (CQL query selectors, content ID selectors)
- serve as the lookup table when transforming Confluence links to SharePoint links
Selectors
A source content selector is either a Confluence space key, a CQL query, or a list of content IDs. When selected for migration, all pages, blogs, etc. covered by the source selector will be scheduled for migration.WikiTraccs creates the Space Inventory list and adds information about Confluence spaces.
You use the Space Inventory to select source content to migrate, and to specify target SharePoint sites. WikiTraccs will use this information to decide which content to migrate, and how to resolve links between pages.
The Space Inventory is created and updated by WikiTraccs.GUI when selecting the Update Space Inventory in WikiTraccs site button:
Note: WikiTraccs.Console will also check and create the Space Inventory, if necessary.
The Space Inventory can be repeatedly updated by selecting the Update Space Inventory in WikiTraccs site button. Use this to have spaces added to the inventory list that are missing, either because they have been newly created in Confluence, or because they have been deleted from the list.
Accessing the Space Inventory
Selecting the Open Space Inventory list to choose sources button opens the Space Inventory in a browser:

When the Space Inventory exists, the browser should show the SharePoint list Confluence Space Inventory (WikiTraccs):
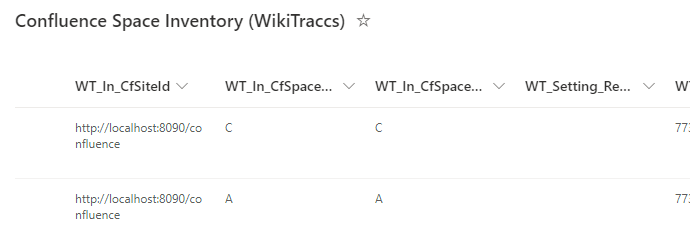
If - for whatever reason - the Space Inventory does not exist, the browser will show an error:
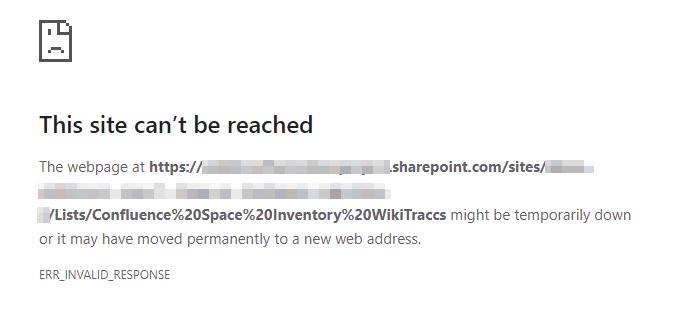
If you see above error, make sure to select the Update Space Inventory in WikiTraccs site button first so that WikiTraccs has a chance to create and update the list.
You can find the Space Inventory without WikiTraccs as well, as it’s just a SharePoint list. Open the WikiTraccs site in a browser, go to Site Contents, and select the Confluence Space Inventory (WikiTraccs) list.
How does it work exactly?
Here’s an image showing how the Space Inventory works:

This image summarized:
- the Space Inventory list contains multiple source to target mappings that tell WikiTraccs what to migrate, and where
- each row contains at least the following mandatory information:
- WT_In_CfSiteId - the Confluence site identifier; this corresponds to the Confluence base URL (example: https://wiki.contoso.com or https://contoso.atlassian.net/wiki)
- WT_In_CfSpaceKey - a source selector, telling WikiTraccs which pages to migrate; this can be the Confluence space key, but starting with release 1.8 of WikiTraccs this field can also contain a CQL query (example for space key: HR, example for CQL query: label=“archive”)
- WT_Setting_RequestTransformation - if this is checked, WikiTraccs will migrate all pages covered by the the source selector from Confluence to SharePoint; otherwise this mapping is only used for link resolution
- WT_Setting_TargetSiteRootUrl - the target SharePoint site for all pages covered by the source selector; this is relevant for migrating pages covered by the source selector, but also for creating the correct links to target pages (example: https://contoso.sharepoint.com/sites/target1); if this is left empty, the default target site URL as configured via WikiTraccs.GUI will be used
- when starting the migration, WikiTraccs will collect content from all source content selectors that have been chosen for migration, and schedule them for migration; this queue is processed one item after another
- when a page contains a link to a space, page or attachment, WikiTraccs will look up the SharePoint target site in the Space Inventory and create the link based on the found mapping; if there is no mapping a transformation error will be logged for the page (see Measuring page migration success on where to find this metric)
Using the Confluence Space Inventory
Here are other resources involving the Space Inventory:
- Which spaces to migrate is covered in the quick start guide: Getting Started
- Why mapping to target sites is important for resolving migrated links: Cross-space links and target sites
- Migration Waves
- How to run parallel WikiTraccs migrations
To learn more about the source-to-target mapping and about the different source content selectors, refer to the following articles:
6.2.1 - How to map Confluence Source Selectors to SharePoint Sites
WikiTraccs needs to know what to migrate and where to migrate it to. It needs a mapping.
Content to migrate is chosen by source content selectors.
Selectors
A selector tells WikiTraccs which Confluence content to migrate.
The following selectors are supported:
- Space selector - to select all pages of a space
- CQL query selector - to select pages via CQL search query
- Content ID selector - to select pages by ID
WikiTraccs also needs to know where to create the migrated SharePoint pages. This is done by configuring a target site collection for each selector.
Note
Attachments are not covered by selectors. They are always migrated together with their parent page or blogpost.The source-to-target mapping is important for two things:
- knowing which Confluence content to get and to which SharePoint site to migrate this content
- transforming Confluence links to proper SharePoint links
Getting the mapping right before starting the migration is crucial for link transformation.
Migrate to one target site by default
WikiTraccs, in absence of any other configuration, migrates everything to one default target site.
When using WikiTraccs.GUI you enter the default target site URL into the Default target site input field:

Default Target Site Configuration in WikiTraccs.GUI
When you don’t configure anything else, WikiTraccs will migrate Confluence content to this SharePoint site.
Note
This default mode is usually not what you want. So read on.Configure a different target site for selectors
When you want WikiTraccs to migrate content from different source content selectors to different target sites, you configure this mapping in the Confluence Space Inventory list in the WikiTraccs site.
The Confluence Space Inventory list has a column WT_Setting_TargetSiteRootUrl. Enter the target site root URL there.
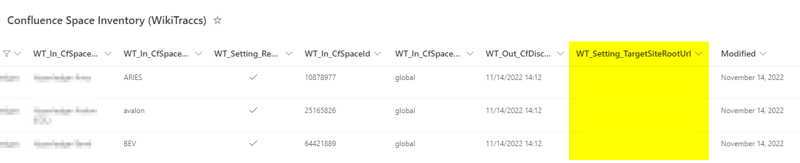
Target Site Root URL Column
When the WT_Setting_TargetSiteRootUrl column is empty, WikiTraccs falls back to using the default target site URL for that space. It is totally valid to set a target site URL only for some spaces.
Cross-space links and target sites
In general, when migrating pages, WikiTraccs translates links between Confluence pages to proper links between SharePoint pages.
Note
Everything in this section applies to attachments as well.The target site mapping is important to properly transform links between Confluence pages to links between SharePoint pages.
When migrating Confluence pages that link to other Confluence pages, WikiTraccs looks up the target site URL for the target page. To be able to do that, WikiTraccs finds the selector that contains the link’s target page and uses its target site URL to construct the page’s SharePoint URL. Note that the link’s target page doesn’t have to be migrated yet for this to work as page names follow a well-known naming convention.
Note
WikiTraccs uses the default target site URL when there is no target site URL configured for a space.The links WikiTraccs creates in SharePoint follow a naming convention. This convention is roughly as follows (for pages):
<TARGETSITEURL>/SitePages/<SPACEKEY>-<PAGETITLE>-<PAGEID>.aspx
(The resulting page file name is stripped of any characters that are not allowed in SharePoint.)
When a Confluence page is migrated to SharePoint and this page links to another page or space that has not yet been migrated WikiTraccs can nevertheless create the link. WikiTraccs doesn’t care if the target exists. It will exist once it will have been migrated.
This allows WikiTraccs to migrate Confluence pages that link to other pages or spaces that have not yet been migrated, while still creating valid links.
Note
When you don’t migrate the pages that WikiTraccs linked to in SharePoint those links will - of cource - be broken, since the target is missing.6.2.2 - How to migrate Confluence Content using Space Selectors
Selecting whole Confluence spaces for SharePoint migration is the easiest way to map and migrate Confluence content.
Why use a space selector?
With space selectors you tell WikiTraccs what to migrate on a per-Confluence-space basis.
Usual scenarios are:
- migrate each Confluence space to a corresponding SharePoint site
- migrate multiple Confluence spaces to one SharePoint site, for example for archiving purposes
If that is a granularity you can work with, do it. It’s easier than CQL query selectors and content ID selectors.
Where to configure space selectors?
Go to the Space Inventory; it should already contain a list of all Confluence spaces WikiTraccs found, when you followed the steps of the Quick Start tutorial.
Set a check mark in the Wt_Setting_RequestTransformation column for every space you want to migrate.
Here’s what the Space Inventory list might look like:
| WT_In_CfSpaceName | WT_In_CfSpaceKey | Wt_Setting_RequestTransformation | WT_Setting_TargetSiteRootUrl | |
|---|---|---|---|---|
| Project Alpha | PALPHA | x | https://contoso.sharepoint.com/sites/ProjectAlpha | |
| Project Beta | PBETA | x | https://contoso.sharepoint.com/sites/ProjectBeta | |
| Miscellaneous | MISC | x | https://contoso.sharepoint.com/sites/Miscellaneous | |
| Marketing | MRKT | https://contoso.sharepoint.com/sites/Marketing | ||
| Sales | SALES | https://contoso.sharepoint.com/sites/Sales | ||
| Customer Service | SERVICE | https://contoso.sharepoint.com/sites/CustomerService | ||
| HR | HR | https://contoso.sharepoint.com/sites/HR | ||
| Finance | FIN | https://contoso.sharepoint.com/sites/Finance | ||
| IT | IT | https://contoso.sharepoint.com/sites/IT |
Note: Other columns have been omitted for brevity.
In the above sample, three spaces have been selected for migration: Project Alpha, Project Beta, and Miscellaneous.
Link Transformation
Space selectors are relevant for link transformation.
When WikiTraccs transforms a cross-space link from PAGE_SOURCE to PAGE_TARGET, all selectors in the Space Inventory will be checked if they contain PAGE_TARGET.
Having found a selector that contains PAGE_TARGET, WikiTraccs uses this selector’s WT_Setting_TargetSiteRootUrl value to create the link.
Be sure to fill those WT_Setting_TargetSiteRootUrl columns for all selectors, not only the ones to be migrated.
6.2.3 - How to migrate Confluence Content using CQL Query Selectors
Note
CQL query selectors have been introduced in WikiTraccs release 1.8.0.WikiTraccs allows selecting source pages for migration using CQL queries.
Migrating spaces vs. migrating via CQL query
Note
Refer to the Atlassian documentation about the CQL query syntax: Advanced Searching using CQL.Before release 1.8.0 WikiTraccs only supported the configuration of entire Confluence spaces for migration and for link resolution. This meant that all pages of a given source space would be migrated to the configured target site.
Feedback from clients let to the introduction of an additional, more flexible way to select source pages: pages can now also be selected via CQL query. This allows to select specific pages for migration.
For WikiTraccs the technical difference is minimal, from a page selection perspective.
For you, the difference is also minimal, from a configuration perspective. The Space Inventory list is still used to configure which pages should be migrated to which target. Simply write your CQL query to the WT_In_CfSpaceKey field.
The following screenshot shows how different CQL queries are used to select pages by their label, migrating each label to a different target site:

Space Inventory list showing CQL query selectors for source page selection.
Note: the field is still named WT_In_CfSpaceKey since initially only a space key was supported there.
Everything else from the space selector article applies as well, so please refer to this article: How to map Confluence Spaces to SharePoint Sites. The target site can be configured. If there is no target site set, the default target site will be chosen.
There are some consequences though, when using CQL queries.
The consequences of using CQL queries source selectors
Note about Page Restrictions
CQL queries will only surface restricted pages when the logged-in user is explicitly listed in the page restrictions (either directly or as member of a group). Confluence admin accounts that are allowed to access all pages (even restricted ones) are often not part of page restriction configurations and thus restricted pages will be missing in the CQL query result. This is Confluence out-of-the-box behavior.Here’s the list of topics that can get more complicated when dealing with CQL queries:
- Restricted Pages: see note above
- Link Resolution: Confluence pages linking to other spaces, pages, or attachments require more time to migrate, and put more load on Confluence
- Query Result Size: using CQL queries you can select a large amount of pages (potentially all)
- Duplicate Pages: one page can be selected by multiple CQL queries, leading to pages being migrated multiple times
Tip
If you want to test a CQL query you can do so in the browser as follows:
- open a browser and log in to Confluence
- in the same browser window, enter the following in the address bar:
https://<confluencebaseurl>/rest/api/content/search?start=0&limit=200&cql=type="page"(note: make sure to replace<confluencebaseurl>with the base URL of your Confluence); press Return
The browser window should now show a wall of text. This is the result for the CQL query type="page" which selects “all pages”.
Link resolution is more difficult
For each CQL query selector you add to the Space Inventory WikiTraccs has to issue one additional request to Confluence for each link it needs to resolve.
Assume you are migrating 10,000 pages, with 2 links to other pages on each of those 10,000 pages. Further assume you configured 100 CQL query selectors in the Space Inventory list. That means that 2*100 callbacks to Confluence would need to be issued for each of those 10,000 pages, amounting to 2,000,000 calls overall during the migration of those 10,000 pages.
Why is that?
To transform links from Confluence to SharePoint, WikiTraccs needs to know which target site a page will be migrated to. But how would WikiTraccs know which CQL query contains which page? To learn this WikiTraccs asks Confluence for each CQL query if a given page is included.
Example:
- page A links to page B with ID 2000
- WikiTraccs needs to find out which SharePoint site page B will be migrated to, to create the proper SharePoint link
- there are two CQL queries configured:
label="one", mapped to target sitehttps://contoso.sharepoint.com/sites/one, andlabel="two", mapped to target sitehttps://contoso.sharepoint.com/sites/two - WikiTraccs creates a modified CQL query
(label="one") AND (id=2000)to check if page B is covered by CQL querylabel="one"- there are no results - page B is not covered
- WikiTraccs creates a second modified CQL query
(label="two") AND (id=2000)to check if page B is covered by CQL querylabel="two"- there is one result - page B is covered!
- WikiTraccs now knows that page B will be migrated to site
https://contoso.sharepoint.com/sites/two - thus the correct link to page B is something like
https://contoso.sharepoint.com/sites/two/SitePages/SPC-Page-B-2000.aspx
Note: WikiTraccs does not have to do this when only performing space-based migrations (without any CQL queries), since the target site can easily be looked up via each page’s space key in the Space Inventory list.
Duplicate pages can be created
You can write CQL queries might include overlapping results.
Take for example the CQL queries label="one" and label="two".
If Confluence pages only ever have one of the labels one or two, those selectors choose two disjuct sets of pages. Which is good.
But what about pages having both labels one and two? Those pages will be chosen by both CQL queries, migrating each of those pages two times.
The consequences are:
- duplicate content in SharePoint as multiple copies of a page are present
- fuzziness when it comes to linking to those pages as other SharePoint pages can only link to one of the duplicates; which one is not defined
Link Transformation
CQL query selectors are relevant for link transformation.
When WikiTraccs transforms a cross-space link from PAGE_SOURCE to PAGE_TARGET, all selectors in the Space Inventory will be checked if they contain PAGE_TARGET.
Having found a selector that contains PAGE_TARGET, WikiTraccs uses this selector’s WT_Setting_TargetSiteRootUrl value to create the link.
Be sure to fill those WT_Setting_TargetSiteRootUrl columns for all selectors, not only the ones to be migrated.
6.2.4 - How to migrate Confluence Content using Content ID Selectors
Note
Content ID selectors have been introduced in WikiTraccs release 1.18.0.WikiTraccs allows selecting Confluence source content for migration using Confluence content IDs.
Why use a content ID selector?
If you have complex requirements with regard to which Confluence content is migrated to which SharePoint site, content ID selectors allow for full flexibility.
You’ll prepare a content ID selector for WikiTraccs that looks like this:
123456789;#page,234567891;#page,345678912;#page,4567891234;#blogpost,5678912345;#blogpost
Above selector contains the content IDs of 3 pages and 2 blogs.
How you end up with the list of IDs to migrate is entirely up to you.
You can run a complex database query in an on-premises Confluence environment. Or you can use Excel-based ID filtering on space content reports for Confluence Cloud.
WikiTraccs’ Content ID Format
WikiTraccs needs each content ID to follow this pattern: ID;#TYPE
IDis the actual Confluence content ID, like123456789;#is a delimiter to separate the ID from the typeTYPEis the Confluence content type likepageandblogpost(note: more content types will be supported in the future)
Multiple content IDs are delimited by comma, like ID;#TYPE,ID;#TYPE,ID;#TYPE.
Where to configure content ID selectors?
For each new content ID selector you want to create, add a new item in the Space Inventory.
Note
When adding new items to the Space Inventory list, SharePoint might consider Title as a required field. Just enter anything, WikiTraccs doesn’t need nor uses the Title value.Use the WT_Setting_ContentSelectorValue field to specify the content ID selector value.
Set the WT_In_CfSiteId field to the Confluence base address (like https://contoso.atlassian.net/wiki or https://wiki.contoso.com). Look at the other entries in the Space Inventory and copy the value from those entries that WikiTraccs created for spaces.
Here’s what the Space Inventory list might look like after adding two content ID selectors:
| WT_In_CfSiteId | Wt_Setting_RequestTransformation | WT_Setting_TargetSiteRootUrl | WT_Setting_ContentSelectorValue | |
|---|---|---|---|---|
| https://contoso.com/wiki | x | https://contoso.sharepoint.com/sites/ProjectAlpha | 123456789;#page,234567891;#page,345678912;#page,4567891234;#blogpost,5678912345;#blogpost | |
| https://contoso.com/wiki | x | https://contoso.sharepoint.com/sites/ProjectBeta | 101;#page,201;#blogpost |
Note: Although content ID selectors are added to the “Space” Inventory, a space key or space ID doesn’t have to be set.
Migrating via CQL query vs. migrating via content IDs
CQL queries allow filtering content by IDs, just like content ID selectors.
But CQL queries in Confluence have one big limitation with regard to restrictions. Restricted contents might be missing from the query result, even when using a migration account that has admin permissions. Have a look at the CQL selector article for details: How to migrate Confluence Pages using CQL Query Selectors.
A WikiTraccs content ID selector does not have this restriction.
Why is that?
When handling a content ID selector WikiTraccs will also try to get chunks of content via CQL queries, to speed up things. WikiTraccs then checks if expected IDs are missing from the CQL query result. If there are IDs missing, WikiTraccs assumes that those are restricted and that the current migration account should be allowed to access them (just not via CQL).
For each ID that is still missing from the query result WikiTraccs will get those one by one via their ID. This will succeed if the content exists and the migration account is allowed to view it.
The consequences of using content ID source selectors
Please refer to the respective section of this article: How to migrate Confluence Pages using CQL Query Selectors. The reasoning about duplicates and links also applies to content ID selectors.
Furthermore, retrieving contents via single IDs for a large selector will take more time than retrieving all contents of a space or CQL query. The more content there is where the migration account is not direct part of the restriction configuration, the longer it takes to retrieve the selector’s content.
SQL Snippets
Note
Running SQL on the Confluence database is only possible in Confluence Server and Confluence Data Center, not Confluence Cloud.Using SQL you can get content IDs for your selector from the Confluence database.
Note
All statements have been tested with PostgreSQL.Here are sample SQL statements to get them in the right format for WikiTraccs (like 123456789;#page,234567891;#blogpost).
Get the content ID selector that includes ALL Confluence pages and blogposts:
SELECT count(*), string_agg(contentId || ';#' || contenttype, ',') AS contentIdSelectorValue
FROM (
SELECT contentId, LOWER(contenttype) AS contenttype
FROM content
WHERE (contenttype='PAGE' OR contenttype='BLOGPOST')
AND prevver IS NULL
AND content_status='current'
ORDER BY contenttype, contentId
) subquery;
Get the content ID selector that includes Confluence pages and blogposts from space MYSPACEKEY:
SELECT count(*), string_agg(contentId || ';#' || contenttype, ',') AS contentIdSelectorValue
FROM (
SELECT contentid, LOWER(contenttype) AS contenttype
FROM content LEFT JOIN spaces ON content.spaceid = spaces.spaceid
WHERE (contenttype='PAGE' OR contenttype='BLOGPOST')
AND prevver IS NULL
AND content_status='current'
AND spacekey='MYSPACEKEY'
ORDER BY contenttype, contentId
) subquery;
Replace MYSPACEKEY with the key of the space you want to get content IDs for.
Link Transformation
Content ID selectors are relevant for link transformation.
When WikiTraccs transforms a cross-space link from PAGE_SOURCE to PAGE_TARGET, all selectors in the Space Inventory will be checked if they contain PAGE_TARGET.
Having found a selector that contains PAGE_TARGET, WikiTraccs uses this selector’s WT_Setting_TargetSiteRootUrl value to create the link.
Be sure to fill those WT_Setting_TargetSiteRootUrl columns for all selectors, not only the ones to be migrated.
6.3 - Configuration via Configuration File
Configuration File: appsettings.json
Note
You have to restart the application to apply changes to settings files.The configuration file works with both WikiTraccs.GUI (the blue window) and WikiTraccs.Console.
The configuration is done in the appsettings.json file. When you run WikiTraccs.GUI then appsettings.json must be placed in same folder as WikiTraccs.GUI.exe. When you run WikiTraccs.Console then appsettings.json must be placed in same folder as WikiTraccs.Console.exe. Create the file, if needed.
Note
appsettings.json can be used together with WikiTraccs.GUI to configure many settings not available in the GUI. Note that not all configuration options might be available. Get in touch if some setting doesn’t seem to be applied.Here is a sample of appsettings.json configured for a straightforward content migration (a second sample follows further down, explaining the options):
{
"CustomSettings": {
"TargetTenants": [
{
"HumanReadableId": "Contoso SharePoint",
"SharePointRootUrl": "https://contoso.sharepoint.com",
"ClientId": "76762071-f1a9-4323-a97a-ab24992032fd",
"Tenant": "82fb6e24-c982-4f08-a009-1916ee226643",
"AuthenticationType": "interactive",
"TargetSites": [
{
"HumanReadableId": "WikiTraccs",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/MigrationStore"
},
{
"HumanReadableId": "WikiTraccsDefaultTarget",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/DefaultTarget"
}
]
}
],
"TransformationMappings": [
{
"SourceTenantHumanReadableId": "Contoso Confluence",
"TargetTenantHumanReadableId": "Contoso SharePoint",
"TargetSiteHumanReadableId": "WikiTraccsDefaultTarget"
}
],
"SourceTenantIncludeList": [
{
"TenantId": "https://www.contoso.com/confluence",
"HumanReadableId": "Contoso Confluence",
"SpaceTransfer": {
// note: spaces to migrate are configured via space inventory list in the SharePoint WikiTraccs site
"Enabled": true
}
}
],
"AttachmentRegistryRootPath": "D:\\FileRegistry",
// ChromeDriver version to download (troubleshooting setting)
"ChromeDriverVersionOverride": null,
// EdgeDriver version to download (troubleshooting setting)
"EdgeDriverVersionOverride": null,
// Directory where WikiTraccs looks for the WebDriver, and also store the downloaded WebDriver here
"WebDriverDirPath": null,
// Path to chrome.exe (troubleshooting setting)
"ChromeBinaryPath": null,
// Path to msedge.exe (troubleshooting setting)
"EdgeBinaryPath": null,
}
}
Here is a larger sample of appsettings.json showing more options for advanced and multi-pass configuration:
{
"CustomSettings": {
"TargetTenants": [
{
"HumanReadableId": "Contoso SharePoint",
"SharePointRootUrl": "https://contoso.sharepoint.com",
// client ID (application ID) of the registered Entra ID Application
"ClientId": "76762071-f1a9-4323-a97a-ab24992032fd",
// SharePoint tenant ID
"Tenant": "82fb6e24-c982-4f08-a009-1916ee226643",
// How to authenticate with Entra ID; valid options are: "interactive" (supports MFA, use this), "credentials" (no MFA support), "devicelogin".
"AuthenticationType": "interactive",
// Optional: configuration for AuthenticationType "credentials", not needed for "interactive".
"AuthenticationParameterSetCredentials": {
"CredentialsUserName": "[email protected]",
"CredentialsPassword": "p4ssw0rd"
},
// contains all sites used in the migration; two are mandatory: "WikiTraccs" and "WikiTraccsDefaultTarget"
"TargetSites": [
{
// This is the "management site" for WikiTraccs that contains space inventory, user and group mapping table etc.; the HumanReadableId MUST be "WikiTraccs".
"HumanReadableId": "WikiTraccs",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/MigrationStore"
},
{
// This is the default migration target for spaces that have no other target configured; the HumanReadableId MUST be "WikiTraccsDefaultTarget".
"HumanReadableId": "WikiTraccsDefaultTarget",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/DefaultTarget"
}
]
}
],
// Configure migrations here; which source should be migrated to which target:
"TransformationMappings": [
{
"SourceTenantHumanReadableId": "Contoso Confluence",
"TargetTenantHumanReadableId": "Contoso SharePoint",
"TargetSiteHumanReadableId": "WikiTraccsDefaultTarget"
}
],
// Confluence configuration
"SourceTenantIncludeList": [
{
// You MUST use the Confluence base URL as TenantId
"TenantId": "https://www.contoso.com/confluence",
// By default, when using interactive Confluence login, the Confluence base URL (as specified by the TenantId) will be opened in a browser.
// If you need to use an address for authentication that is different from the base URL, you can specify this here. This is optional.
"AuthUrl": "https://www.contoso.com/confluence/login.action?force_azure_login=false",
// This can be anything and is used to reference to the source tenant.
"HumanReadableId": "Contoso Confluence",
// Add page IDs here to force-migrate those pages.
"PageIdIncludeList": [
"123456789",
"234567890"
],
// Migrate SharePoint pages with transformation errors again.
"ReprocessContentWithErrors": true,
// Configure content migration here.
"SpaceTransfer": {
// Uncomment this to switch to principal checking mode; this updates the Created by and Modified by fields of pages; configure user mapping first!
//"Operations": ["checkprincipals"],
// Do migrate content.
"Enabled": true,
// Handle those spaces; note that this will be merged with the spaces selected in the space inventory list in SharePoint:
"SpaceIncludeList": [
{
"SpaceKey": "AGILE"
},
{
"SpaceKey": "ARCHIVE"
}
]
},
// Configure permission migration here.
"PermissionTransfer": {
// Do migrate permissions; note: only enable either SpaceTransfer, or PermissionTransfer, _not_ both at the same time.
"Enabled": false,
// Migrate permissions for those spaces.
"SpaceIncludeList": [
{
"SpaceKey": "AGILE"
}
]
}
}
],
"ReprocessContentWithErrors": false,
// Sometimes there are huge wait times if external images don't time out properly. The number of retries and waits can be tweaked here so this does not slow down too much.
"ExternalDomains": [
{
"UrlStartsWith": "https://docs.docker-cn.com",
"HttpTimeoutRetries": 2,
"HttpTimeoutSecs": 2
}
],
// By default WikiTraccs expects chromedriver.exe to be in the same folder as WikiTraccs. It will be downloaded if not present.
// Here you can change the folder WikiTraccs uses, and also place a pre-downloaded exe there.
"WebDriverDirPath": "C:\\Users\\user\\Documents\\00_Portable",
// Only needed in environments where the auto-detection endpoint is blocked; must match the Chrome version (see Troubleshooting > Connectivity for details)
"ChromeDriverVersionOverride": "72.0.3626.52",
// Normally WikiTraccs locates chrome.exe automatically.
// Specify an absolute path to chrome.exe if this fails _or_ you'd like to point to a specific Chrome version.
"ChromeBinaryPath": "C:\\Program Files\\Google\\Chrome Beta\\Application\\chrome.exe",
// By default WikiTraccs stores Confluence attachments in the application folder for the current user.
// Override this location here with an absolute path.
"AttachmentRegistryRootPath": "D:\\FileRegistry",
// Those options can aid debugging.
"Debug": {
"ClearLocalCacheOnStart": false, // default: false
// Set this to true to save the storage format of every transformed page to disk. This can be useful for troubleshooting.
"SaveTransformationInputToDisk": false, // default: false
// Skip connection checks when starting transformation in WikiTraccs.GUI?
"SkipConnectionCheckInWikiTraccsGui": false,
// Ignore errors when preparing a site as migration target (not recommended!)?
"SkipPreparationResultCheck": false,
// Skip caching of API responses (space inventory content, Confluence API calls) that would otherwise be cached for some time (often only some minutes)?
"BypassCaches": false
},
"Features": {
// Trigger update of space inventory? Note that this can also be done from WikiTraccs.GUI.
"FillSpacesList": false,
// Transform page tree macro to static tree of links in SharePoint?
"TransformPageTreeMacro": true, // default: true
// Transform roadmap macro to image placeholder? Note that the image placeholder does not contain all information (e.g. text is missing).
"TransformRoadmapMacro": true, // default: true
// Use a centered dummy image for advanced text control flow around images (>0.1.5)?
// note: this becomes obsolete in newer versions, due to updates to SharePoint pages by Microsoft; don't bother
"EnableDummyImageFloatResetForImages": true,
// Add a link to the source Confluence page?
"AddLinkToSourcePage": false,
// Mark formerly merged table cells?
"TableCellSpanLayoutMode": "UnmarkedAdditionalSlots", // default: "MarkedAdditionalSlots"
// add attachments section to each page (if there are attachments)?
"AddAttachmentsSection": true,
// migrate footer comments (will become page content)?
// release notes: https://github.com/WikiTransformationProject/wikitraccs-releases/releases/tag/v1.9.0
"MigrateFooterComments": true,
// try to resolve hard links?
// release notes: https://github.com/WikiTransformationProject/wikitraccs-releases/releases/tag/v1.6.4
"ResolveHardLinks": true,
// migrate Confluence blog posts to SharePoint
"MigrateBlogposts": true,
// promote migrated blog posts as SharePoint news; note: this may cause notifications for users
"PromoteBlogposts": true
},
"WiggleRoom": {
// set the maximum wait time for callouts to Jira for resolving issue links and issue tables
// set this to -1 to disable reaching out to Jira while migrating pages from Confluence to SharePoint; this is handy when the Jira application link is no longer functional
// release notes: https://github.com/WikiTransformationProject/wikitraccs-releases/releases/tag/v1.11.12
"JiraMaxWaitTimeSec": 60,
// set the maximum number of parallel uploads when migrating attachments from Confluence to SharePoint
// handle with care, a number too high will quickly get you throttled by Microsoft
"ParallelFileOperationsCount": 2,
// number of seconds to wait after a failed page provisioning (e.g. due to connection loss); a multiplier will be applied by WikiTraccs with each try, this is the base value
"WaitTimePerProvisioningRetryBaseSec": 20,
// number of times a page provisioning is retried after failing for whatever reason (e.g. connection loss)
"ProvisioningRetriesCount": 4,
// number of results to get with call to the content API (non-body, with expansions)
// ATTENTION: setting this too high will make content be missing from the migration!
// there are system limits baked into Confluence: 200 is the maximum for retrievals with non-body expansions, which is used by WikiTraccs when bulk-retrieving information about pages
"PageRetrievalPageSizeOverride": 200,
// number of IDs to bundle into one CQL query that will be used to retrieve pages for the content ID selector
// ATTENTION: choosing a number too high will lead to a Server Error from Confluence; lower the number if that is the case
"PageRetrievalByContentIdsCqlPageSizeOverride": 500
}
}
}
When running WikiTraccs.Console you have to use appsettings.json to configure everything. The program will stop with an error pretty fast if the configuration is missing.
6.3.1 - Sample Configurations
The following configurations can be used to control WikiTraccs.Console without the GUI.
Everything that can be configured via WikiTraccs.GUI can also be configured via a settings file, and more. Save the settings to appsettings.json in the same directory where WikiTraccs.Console.exe is located. Create appsettings.json if necessary.
Run WikiTraccs.Console.exe to start the migration according the configuration.
Note
Some settings can also be applied toWikiTraccs.GUI, by putting the appsettings.json in the same folder as WikiTraccs.GUI.exe. Support might instruct you to do that, for advanced configurations or when diagnosing issues.Sample: Migrate contents of one space
The following configuration migrates the content of space identified by space key demo to the SharePoint site https://contoso.sharepoint.com/sites/migration-test. WikiTraccs site (for under-the-hood tables) and migration target site are the same here.
{
"CustomSettings": {
"WebDriverDirPath": "C:\\Users\\user\\00_Portable",
"SourceTenantIncludeList": [
{
"TenantId": "http://localhost:8090",
"AuthenticationType": "cookie",
"HumanReadableId": "Confluence",
"SpaceTransfer": {
"Enabled": true,
"SpaceIncludeList": [
{
"SpaceKey": "demo"
}
],
"Operations": [
"retrievecontents"
]
},
"PermissionTransfer": {
"Enabled": false,
"SpaceIncludeList": []
}
}
],
"AttachmentRegistryRootPath": "D:\\FileRegistry",
"TempPath": "C:\\Users\\user\\AppData\\Local\\Temp\\",
"TargetTenants": [
{
"HumanReadableId": "SharePoint",
"SharePointRootUrl": "https://contoso.sharepoint.com",
"Tenant": "b6e543a2-f741-40a3-80c1-97c168702d56",
"ClientId": "0bf87492-f0bc-4476-a31f-67e016cdf31d",
"AuthenticationType": "interactive",
"TargetSites": [
{
"HumanReadableId": "WikiTraccsDefaultTarget",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/migration-test"
},
{
"HumanReadableId": "WikiTraccs",
"SiteRootUrl": "https://contoso.sharepoint.com/sites/migration-test"
}
]
}
],
"TransformationMappings": [
{
"SourceTenantHumanReadableId": "Confluence",
"TargetTenantHumanReadableId": "SharePoint",
"TargetSiteHumanReadableId": "WikiTraccsDefaultTarget"
}
]
}
}
Snippet: Prevent WikiTraccs from downloading external images
Note
You can configure this setting via the Settings dialog of WikiTraccs.GUI.WikiTraccs downloads external images and converts them to page attachments of the SharePoint page. This is because SharePoint prevents showing images from external sources.
Here’s the configuration snippet to disable that and to prevent WikiTraccs from downloading external images:
{
"CustomSettings": {
"Features": {
"DownloadExternalImages": false
}
}
}
Snippet: Prevent WikiTraccs from reaching out to Jira
WikiTraccs tries to connect to Jira to properly transform Jira issue and Jira issue list macros when migrating pages from Confluence to SharePoint.
If the application link to Jira does not exist anymore, or WikiTraccs is operating in a locked down environment, you can disable this.
Here’s the configuration snippet to prevent WikiTraccs from reaching out to Jira:
{
"CustomSettings": {
"WiggleRoom": {
"JiraMaxWaitTimeSec": -1
}
}
}
Or, instead of disabling, you can set a lower maximum wait time, like 5 seconds:
{
"CustomSettings": {
"WiggleRoom": {
"JiraMaxWaitTimeSec": 5
}
}
}
Note that such a low timeout might be sufficient to retrieve details about a single Jira issue, but not to get information about a larger issue list.
Snippet: Max number of IDs in a single CQL query when using the Content ID Selector
When using the Content ID Selector to choose pages to migrate, WikiTraccs groups those IDs into CQL queries to speed up page retrieval. Different Confluence instances seem to tolerate a different maximum number of IDs that are included in a single CQL query.
Note
Read more about content ID selectors here: Confluence Content ID Selectors.Choosing a number too high can lead to Confluence returning a Server Error, retrieving no pages at all.
Here’s the configuration snippet to set the number of IDs included in a single CQL query:
{
"CustomSettings": {
"WiggleRoom": {
"PageRetrievalByContentIdsCqlPageSizeOverride": 200
}
}
}
Snippet: Change temporary storage folder pathes
Tip
You can now configure those paths in the WikiTraccs settings dialog, available via the menu bar of the blue WikiTraccs window. No need to useappsettings.json anymore.Use those settings to control where WikiTraccs stores temporary files:
{
"CustomSettings": {
"AttachmentRegistryRootPath": "D:\\FileRegistry",
"TempPath": "C:\\Users\\user\\AppData\\Local\\Temp\\",
}
}
Note
The double backslashes are there on purpose, to make this a valid JSON string. If your path looks likeC:\temp you would instead have to enter C:\\temp here.Explanation:
AttachmentRegistryRootPath- all attachments downloaded from Confluence will be stored here
- those files aren’t removed automatically, you must delete them manually (this can also be done during the migration)
- WikiTraccs does not currently use those files after having migrated them to SharePoint
- when files are missing, WikiTraccs downloads them again from SharePoint
TempPath- certain caching-related files will be stored here
- the Chrome/Edge browser profile for the automated Confluence login session will be stored here
- temporary storage location for Confluence attachments, before they are moved to the
AttachmentRegistryRootPath - temporary storage location for the downloaded page HTML (related to resolving hard links)
Tip
Learn more about data that WikiTraccs stores locally in this article: File Storage.Snippet: Don’t promote migrated Confluence blog posts to SharePoint news
SharePoint allows promoting regular pages as news article. This will surface those pages in news-related web parts and might notify users.
WikiTraccs normally promotes migrated Confluence blogposts to SharePoint news.
Prevent that with the following configuration:
{
"CustomSettings": {
"Features": {
"PromoteBlogposts": false
}
}
}
Snippet: Configuring multi-pass migrations
Note
As of WikiTraccs 0.1 you can choose which pass to run via a settings dialog in WikiTraccs.GUI.A configuration file to trigger both permission migration and principal update looks like this:
{
"CustomSettings": {
"SourceTenantIncludeList": [
{
"HumanReadableId": "Contoso Confluence",
"TenantId": "https://www.contoso.com/confluence",
"SpaceTransfer": {
"Operations": [
"checkprincipals"
]
},
"PermissionTransfer": {
"Enabled": true
}
}
]
}
}
Snippet: Configure Chromedriver in Locked-Down Environment
For more context see How to handle blocked Chrome webdriver endpoints.
{
"CustomSettings": {
// WikiTracs will look for chromedriver.exe in this directory; you'll manually put it there; refer to the documentation linked above
"WebDriverDirPath": "C:\\Users\\user\\00_Portable",
// you need to enter the correct value for your environment; refer to the documentation linked above
"ChromeDriverVersionOverride": "136.0.7103.92",
// WikiTracs should locate chrome.exe automatically; you only need to set this if auto-detection fails
"ChromeBinaryPath": null
}
}
Config File Templates for Debugging Purposes
WikiTraccs has some debug and feature toggles to be used when things don’t go as expected and need to be analyzed.
When debugging, put appsettings.json to the WikiTraccs.GUI folder or the WikiTraccs.Console folder, depending on which program you are running.
Snippet: Generic Debug Configuration Template
Here’s a template of appsettings.json to copy:
{
"CustomSettings": {
"Debug": {
"ClearLocalCacheOnStart": true,
"SaveTransformationInputToDisk": true,
// assume the user is logged in when this element is present and enabled
"ConfluenceAuthCssSelector": "#quick-create-page-button",
// don't check that the Confluence context path and the path of the JSESSIONID cookie match
"SkipConfluenceContextPathCookiePathMatching": false,
"SkipPreparationResultCheck": false,
// skip connection check when starting the migration from WikiTraccs.GUI (version > 0.1.4)
"SkipConnectionCheckInWikiTraccsGui": false
},
"Features": {
// force space inventory update when starting a migration
"FillSpacesList": true,
"TransformPageTreeMacro": true,
"TransformRoadmapMacro": true
}
}
}
Snippet: “Clear Cache” Settings Template
This setting clears the cache on every start:
{
"CustomSettings": {
"Debug": {
"ClearLocalCacheOnStart": true
}
}
}
Snippet: Don’t mark formerly merged table cells
For details on merged table cells see this blog post: How to migrate rich Confluence tables to limited SharePoint tables?
{
"CustomSettings": {
"Features": {
"TableCellSpanLayoutMode": "UnmarkedAdditionalSlots"
}
}
}
7 - Migration Samples
Real Results
All content on this page has been generated by WikiTraccs. No tweaking, no cheating. If there is something missing or off you’ll see it here and there will often be an issue link.You’ll find pairs of images in the sections below. The first image shows a screenshot of a Confluence page. The second image shows how the content looks in SharePoint.
Formatting

Confluence Text Formatting
SharePoint Text Formatting
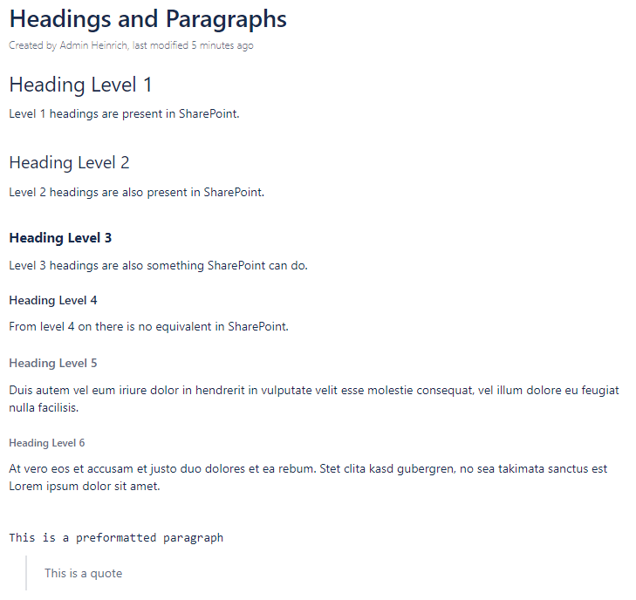
Confluence Headings and Paragraphs
SharePoint Headings and Paragraphs
Confluence Text Alignment and Indentation

SharePoint Text Alignment and Indentation
Confluence Things from the Plus Menu
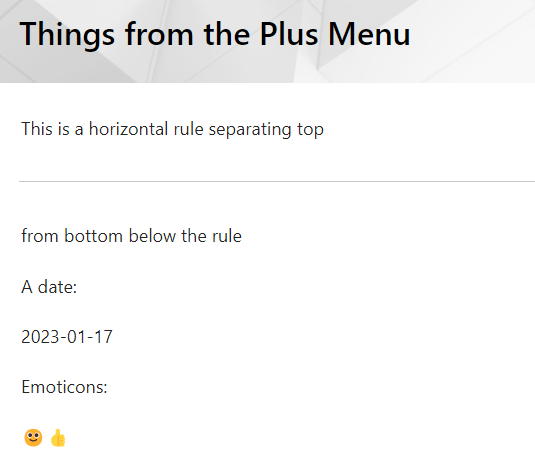
SharePoint Things from the Plus Menu
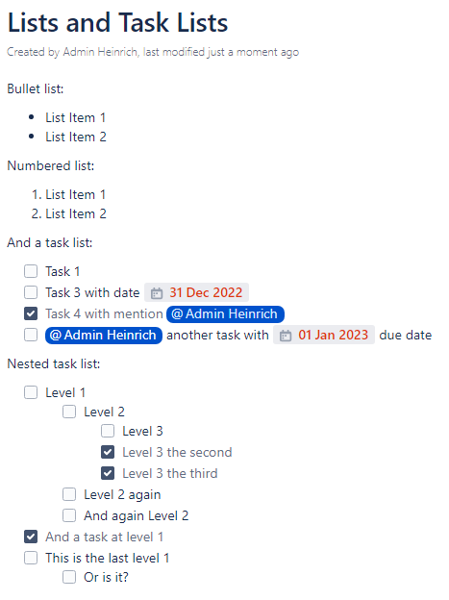
Confluence Lists and Task Lists

SharePoint Lists and Task Lists
Layouts
Standard Layouts
WikiTraccs transforms the Confluence layouts to the matching SharePoint layouts.

Confluence Standard Layouts

SharePoint Standard Layouts
Here’s the edit mode of the two pages containing layouts:

Confluence Standard Layouts in Edit Mode
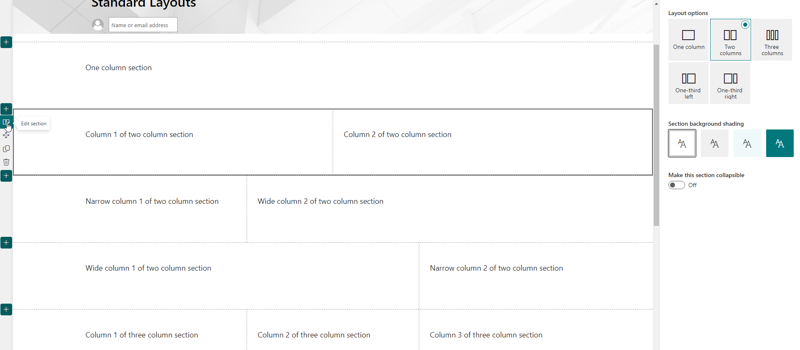
SharePoint Standard Layouts in Edit Mode
Notice how SharePoint only provides one three-column layout. WikiTraccs chooses this for both three-column Confluence layouts.
Sections and Columns
In Confluence users can create arbitrarily nested constructs of sections and columns. Even combinations that don’t make sense are sometimes allowed by Confluence or carried over by faulty migrations. WikiTraccs tries hard to make sense of what it finds.
WikiTraccs converts sections and columns to tables as there is no other equivalent in SharePoint.
Confluence Sections and Columns
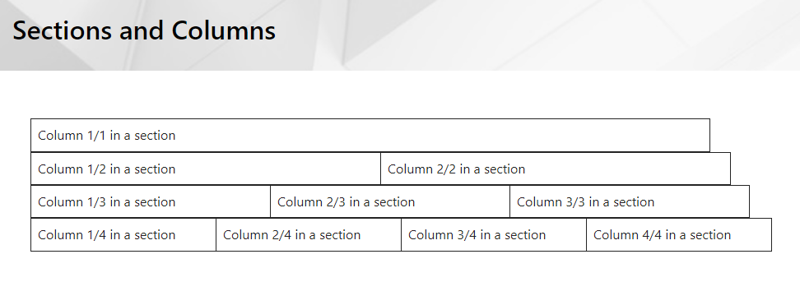
SharePoint Sections and Columns
Note: It would be possible for WikiTraccs to convert the simplest section/column configurations to proper SharePoint sections: Issue Link.
Macros
Note: the following list is not complete. Have a look here for a complete overview: Known Confluence Macros
Confluence Info Warning Tip Note
SharePoint Info Warning Tip Note
Note: WikiTraccs uses colored markers and emojis to indicate the type of note.
Confluence Code Macro
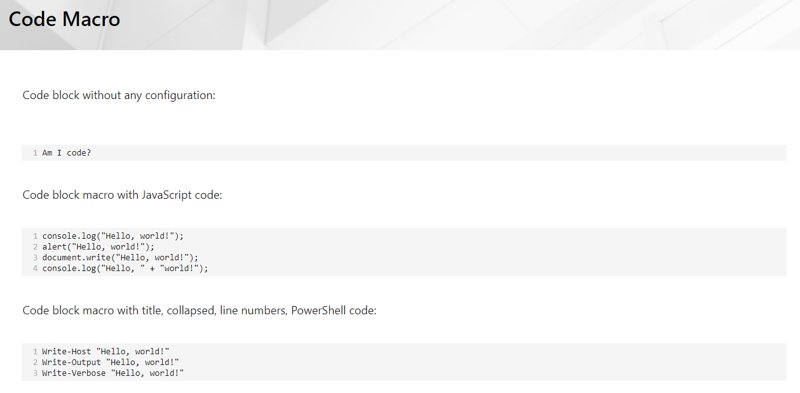
SharePoint Code Macro
Confluence Panels

SharePoint Panels
Note: SharePoint’s formatting is simpler than what Confluence offers.
Confluence Status Macro

SharePoint Status Macro
Files, Images, Links
Images, External Images and Images with Links
Confluence Images

SharePoint Images
Note that a hyperlink has been configured for the first image. The user can click the image to navigate to the link. WikiTraccs migrates the link to SharePoint.
Also note that the Google logo on the Confluence page links to an external image. SharePoint does not allow linking to external images, due to security and privacy concerns. WikiTraccs downloads external images and then migrates them as page attachments.
Note: SharePoint Online currently (2026) does not allow inline images to sit directly next to each other, so adjacent inline images end up on separate lines. This behavior changed over time.
Links to Content outside a Page
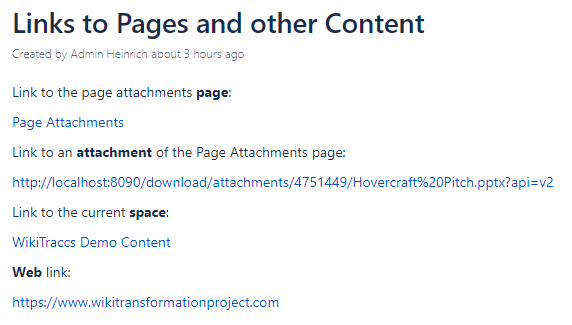
Confluence Links to Pages and other Content
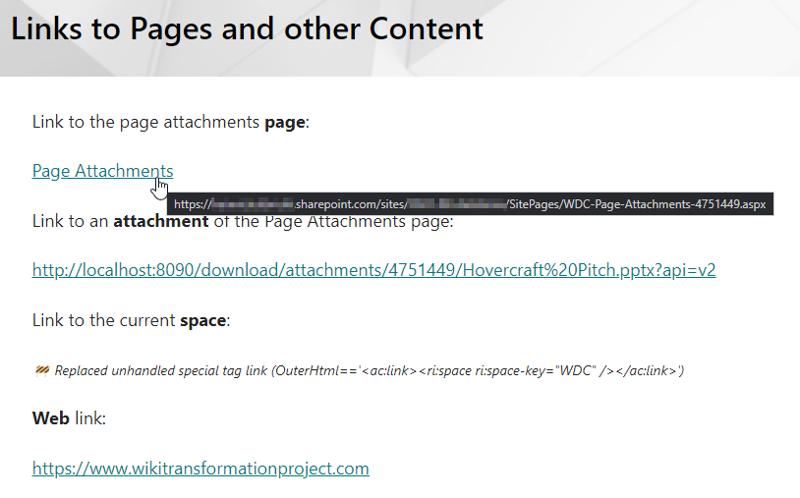
SharePoint Links to Pages and other Content
WikiTraccs changes regular Confluence page links so that they point to the new SharePoint page location.
WikiTraccs will also transform links to other spaces. To do this it needs to know which space maps to which SharePoint site - this is done via the Space Inventory list.
Furthermore, plain text links (“hard links”) are migrated as-is, unless they link to a Confluence page, attachment, or space. WikiTraccs detects those automatically.
Page Attachments
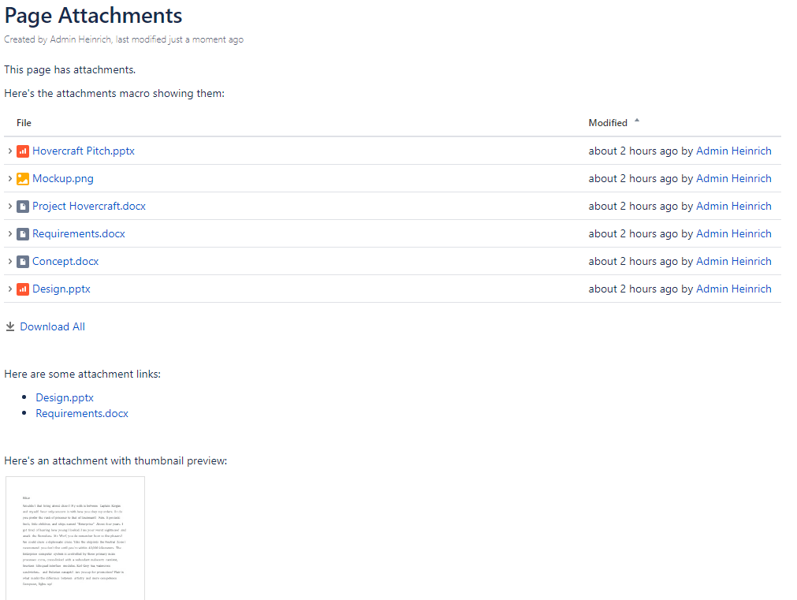
Confluence Page Attachments
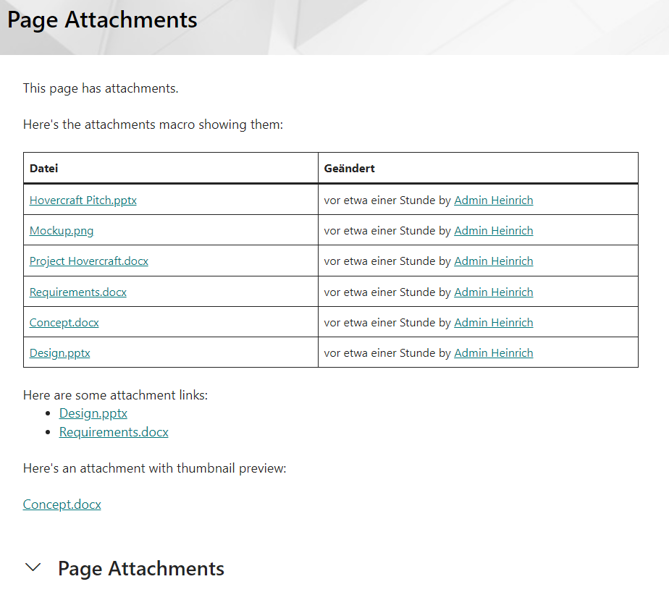
SharePoint Page Attachments
There is more information available in this blog post: New attachments macro transformation
Users and Groups
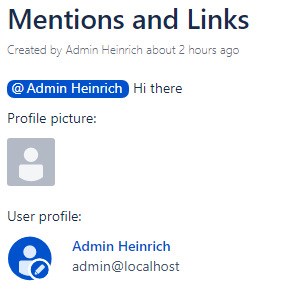
Confluence Mentions and Profiles
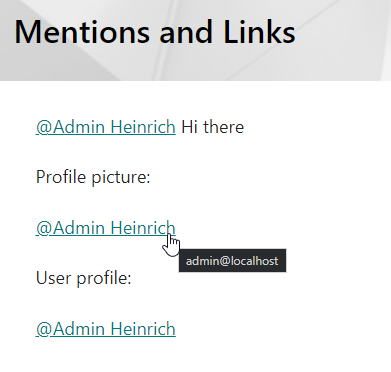
SharePoint Mentions and Profiles
In SharePoint, WikiTraccs creates “mention texts” like in Confluence. Those link to the SharePoint people search where the search field is pre-populated with the mentioned user’s email address.
People profile and image macros are converted to the “mention text” format as well.
Note: When migrating, WikiTraccs needs a certain permission level to access users’ email addresses.
Tables
In Confluence users can do a lot with tables. SharePoint now handles more than it used to - merged cells, cell background colors, and even nested tables all survive the migration. Two blog posts go into detail: Making SharePoint Tables Look Pretty for colored and merged cells, and Nested Tables From Confluence to SharePoint for nesting.
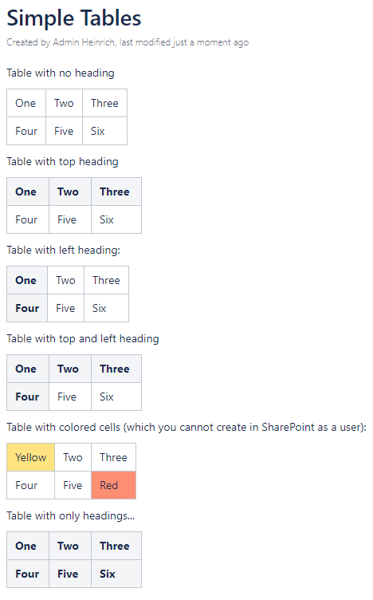
Confluence Simple Tables
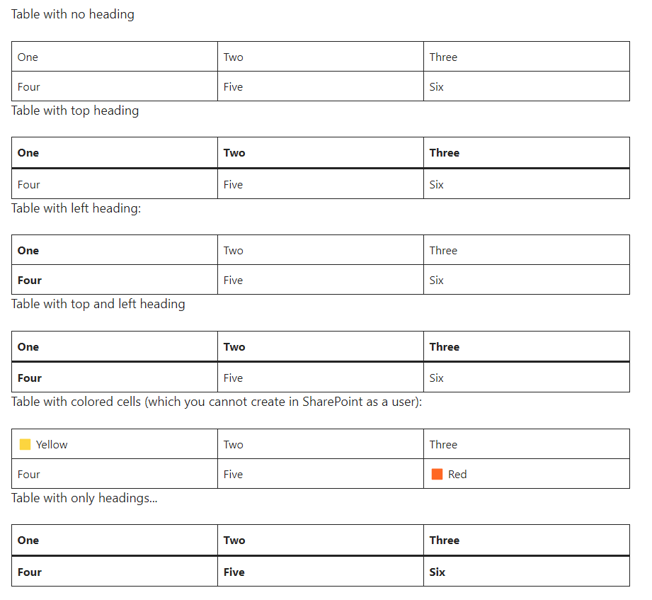
SharePoint Simple Tables
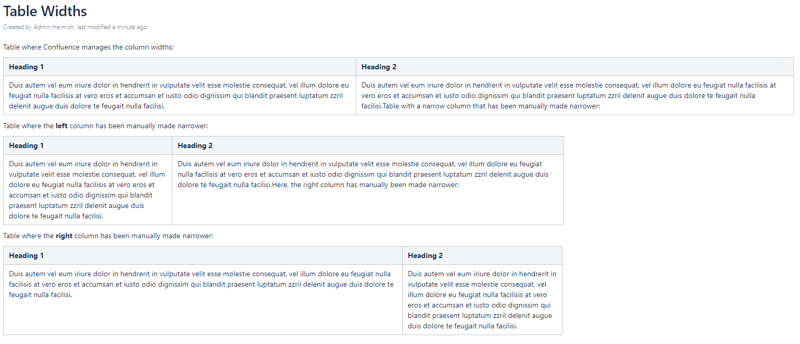
Confluence Table Widths
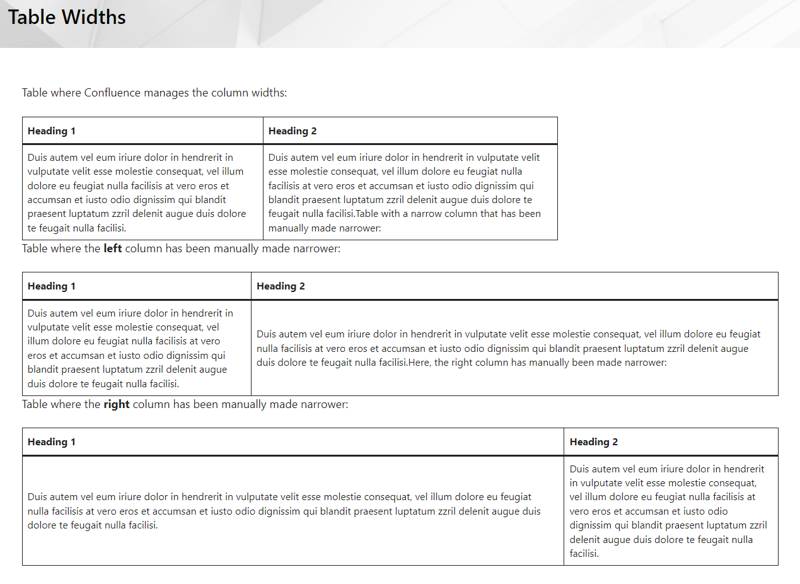
SharePoint Table Widths
WikiTraccs normalizes Confluence tables and the result can be seen below:
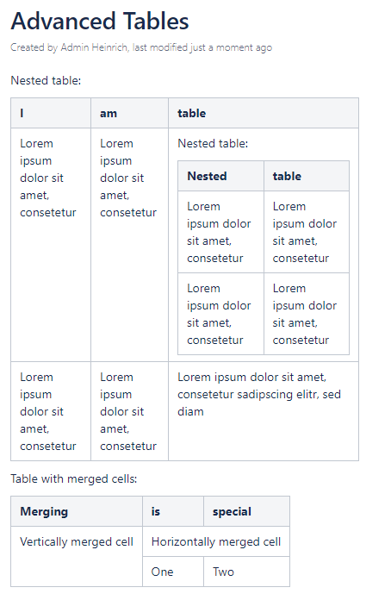
Confluence Advanced Tables

SharePoint Advanced Tables
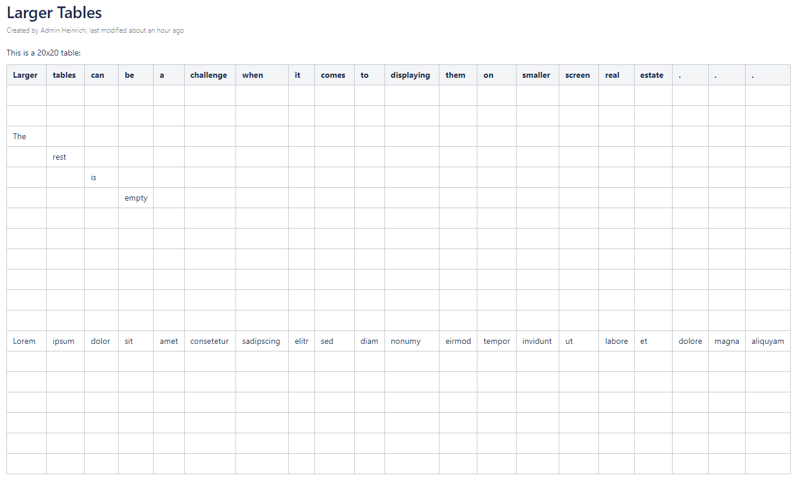
Confluence Larger Tables
SharePoint Larger Tables
Note: Wide tables are usually a challenge for SharePoint because SharePoint pages are narrow compared to Confluence. SharePoint shows a scroll bar if the table is wider than the page.
Standards Note
WikiTraccs aims to create SharePoint pages that look and behave like pages a user could have created in the browser editor.
Merged cells and cell background colors are now supported natively in the SharePoint browser editor. Nested tables are not - the toolbar still doesn’t offer a way to create them - but the SharePoint Text web part stores and renders them correctly. WikiTraccs creates nested tables by default via the Use non-standard table transformation Gray Setting; turn the setting off to fall back to plain, denested tables.
8 - Monitoring Confluence to SharePoint Migration Progress - Overview
There are several places to get insights into the migration progress.
View per-page success metrics
To view migrated pages and to check the migration result per page, you go to the Site Pages library of each migration target site.
Learn more here about the metrics you find there for each page: Per-page progress.
View how many pages have been migrated per selector (e.g. per space)
To learn how many pages have already been migrated for a space - or any other selector - and how many pages are yet to be migrated, you look at the progress log files.
The overall number of pages per selector as well as the number of already migrated pages is also written back to the Space Inventory list (note: starting with WikiTraccs v1.22.1). Look at this SharePoint list to get a quick overview of page counts.
Learn more here: Per-selector progress.
General insights into warnings and errors
Warnings and errors that occurred during the migration are written to the common log files.
Filter those log files for messages marked with WRN and ERR.
Live progress indicators
When running a migration, there are certain numbers shown in the blue WikiTraccs.GUI window, in the black console window, and in the log file. Those numbers show how fast the migration is currently going.
Learn more here: Live Progress Indicators.
8.1 - Monitoring Per Page Progress
The Site Pages library of every target space contains migrated pages and metadata.
Use the library view Recent Pages (WikiTraccs) to gain insights into the migration success for every single page. The SharePoint page’s metadata also includes the space key and content ID.
Read more about the different metrics here: Measuring page migration success.
8.2 - Monitoring Per Selector Progress
Note
Selectors are used to tell WikiTraccs which content to migrate, for example “migrate all pages of space X”. Have a look at the selector documentation to learn about the different selector types.Quick Glance via Space Inventory
Note: This feature is available since WikiTraccs v1.22.11 (released in December ‘24).
After your first migration, the Space Inventory shows the overall number of pages per selector and the number of pages migrated to SharePoint.
The two list columns to look out for are:
WT_In_CfPageCount- the number of pages found in ConfluenceWT_Out_CfTransformedPageCount- the number migrated pages found in SharePoint Online
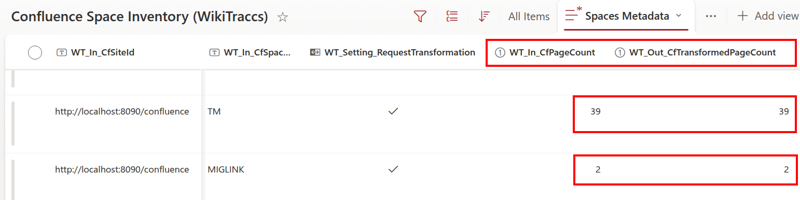
Log files containing information about the Confluence to SharePoint migration progress.
Note: You might have to add the columns to the current list view of the space inventory list, if they are not already visible.
Initially, those fields are empty and show no number.
WikiTraccs updates the numbers when starting a migration run and when finishing a migration run. All selectors that are included in the migration run (those with a check mark set in the WT_Setting_RequestTransformation column) will be updated.
If WT_In_CfPageCount and WT_Out_CfTransformedPageCount are equal, all pages of that selector probably have been migrated. Note that this hides edge cases like “one newly created Confluence page has not been migrated, yet, and a previously migrated page has been deleted in Confluence”; this case would also show the same page count in both columns.
To get deeper insights, refer to the next section and the progress log files.
Using Progress Log Files to Get Insights
Note
Depending on whether you are running WikiTraccs.GUI or WikiTraccs.Console log files will be stored at different locations.
When using WikiTraccs.GUI, look at the WikiTraccs.GUI\logs folder. When using WikiTraccs.Console, look at the WikiTraccs.Console\logs folder.
Progress log files are stored in a sub folder that has the current date as its name, e.g. logs\2023-05-19.
As of release v1.1.0 WikiTraccs provides information about the migration progress in different progress-related log files:
Log files containing information about the Confluence to SharePoint migration progress.
The information you can gather from these files is:
- How many pages are scheduled to be migrated?
- Which pages have already been migrated to SharePoint?
- Which pages are yet to be migrated?
- Which pages have been migrated but need an update?
See below for a quick rundown of the log files and their content.
The values in those files are separated by tabulator. So it’s nearly CSV, but with tab instead of comma. The file name contains a timestamp, the Confluence site ID as specified in the configuration, the space key, and the last part of the target SharePoint site URL.
Progress Log File Documentation
Note
Multiple progress log files will be created with each migration run.
When starting the migration from Confluence to SharePoint WikiTraccs creates progress log files for each analyzed selector. Those reflect the state before the migration of a selector.
After migrating all scheduled selectors WikiTraccs creates a second batch of progress log files for each selector that had pages migrated for. This will be done when going into idle mode. You may interrupt this if you don’t need those files.
When pressing Ctrl+C in WikiTraccs.Console (to cancel the running operation) it is not guaranteed that the final batch of progress log files will be generated. To get the current state just start the migration again and the files will be generated for each scheduled selector.
Keep an eye on the file name and timestamp when you search for the most recent progress log files.
Note
The content of these files is subject to change as customer feedback keeps coming in, pointing to additional information that would be valuable.xxx__10-not-yet-migrated-pages.txt
This file contains information about Confluence pages that are yet to be migrated.
Sample content:
CASIG 78022359 CA2SIG - Meeting November 29 /display/CASIG/CA2SIG+-+Meeting+November+29
CASIG 78022377 2022-11-22 Standard WG /display/CASIG/2022-11-22+Standard+WG
CASIG 80773916 2022 12 06 Standards WG /display/CASIG/2022+12+06+Standards+WG
The tab-separated columns in this file are:
- Confluence space key
- Confluence page ID
- Confluence page title
- Confluence page URL
xxx__20-migrated-pages
This file contains information about migrated pages. It contains information about existing Confluence pages where a corresponding SharePoint page exists as well.
Sample content:
CASIG 24781062 Climate Action and Accounting SIG Home /display/CASIG/Climate+Action+and+Accounting+SIG+Home 97652
CASIG 24781122 Meetings /display/CASIG/Meetings 97653
CASIG 24781124 Member Directory /display/CASIG/Member+Directory 97654
The tab-separated columns in this file are:
- Confluence space key
- Confluence page ID
- Confluence page title
- Confluence page URL
- SharePoint page ID (in the Site Pages library)
xxx__25-update-state-of-migrated-pages
This file contains information about the freshness of migrated pages.
Note
The file format changed with WikiTraccs release v1.7.Sample content:
+++
SourceTenantId = "https://confluence.contoso.com/"
PageSelectorType = "ConfluenceSpace"
PageSelector = "CASIG"
CreationDateUtc = 2023-01-21T15:30:07.1691711
SchemaVersion = 2
+++
CASIG Page 78022313 2022-11-21 Peer Programming Call /display/CASIG/2022-11-21+Peer+Programming+Call 2022-11-30T22:17:28 2022-11-29T23:17:28 2022-11-29T23:17:28 needsupdate
CASIG Page 78022335 CA2 SIG - Meeting November 15 /display/CASIG/CA2+SIG+-+Meeting+November+15 2022-11-24T06:52:40 2022-11-24T06:52:40 2022-11-29T23:17:28 uptodate
CASIG Page 78022347 CA2 SIG - Meeting December 13 /display/CASIG/CA2+SIG+-+Meeting+December+13 2022-12-14T01:46:57 2022-12-14T01:46:57 2022-11-29T23:17:28 uptodate
The file contains a header that is enclosed with +++.
Following the header, the list of page update states starts.
The tab-separated columns are:
- Confluence space key
- Confluence content type: Page or Blogpost
- Confluence page ID
- Confluence page title
- Confluence page URL
- Modification date of the Confluence page
- Stored modification date of the migrated page in SharePoint (this is the Confluence page modification date at the time of migration)
- Modification date of the SharePoint page (note: added in release v1.12.24)
- State of the SharePoint page
- uptodate: this page is up to date
- needsupdate: this page has been updated in Confluence since its migration
- cannotdetermine: metadata in SharePoint is missing, cannot determine if update is needed
Note: WikiTraccs will output additional state values in a verification run.
Tip
This file can be used to update outdated pages. See Updating previously migrated pages for details.xxx__30-aggregated-info
This file contains information that could be gathered from the other files, but already aggregated:
Sample content:
Source Confluence Site: https://wiki.hyperledger.org
Target SharePoint Site: https://contoso.sharepoint.com/sites/migration-target
Space Key: CASIG
Blog posts included in migration and calculation: no
Confluence page count for space space CASIG: 292
Migrated SharePoint pages that correspond to found Confluence pages in space CASIG: 259
Migrated SharePoint pages overall for space CASIG: 259
Pages yet to be migrated for space CASIG: 33
If Migrated SharePoint pages overall for space is larger than Migrated SharePoint pages that correspond to found Confluence pages in space then pages turned inaccessible in Confluence (deleted? permission denied?) but the once-migrated pages in SharePoint still exist.
Progress Log File Cadence
WikiTraccs creates progress log files at specific times:
- when starting a migration run - log files for each scheduled selector will be created
- when stopping a running migration run by pressing Ctrl+C in the console window of WikiTraccs.Console - log files for each selector handled so far will be created
- when the migration run is done - log files for each selector handled so far will be created
This means that multiple progress log files per selector will be created. Look at the ones with the most recent timestamp to see the latest progress information.
Note
WikiTraccs does not create a file if there is nothing to log. So some progress log files can be missing and that’s expected.You can delete or archive old progress log files. Every new migration run will create new files.
Troubleshooting Missing Pages
Have a look at the troubleshooting recipe: Find out why some pages won’t migrate.
8.3 - Live Progress Indicators
Speed metrics in the blue WikiTraccs.GUI window
Note: those metrics are available as of WikiTraccs 1.22.1
Note
Those metrics are only available in Migrate content mode.After migrating a couple of pages, WikiTraccs shows speed metrics:
The meaning is the following:
5-7 s/item: the page migration time in the last n minutes was 5 to 7 seconds per page514-720 /h: the estimated number of pages that will be migrated in the next hourETA 11/12 22:20 ~ 11/12 22:27the estimated finish time
For each of the above, one value is based on mean page migration times, the other value is based on the 75th percentile. WikiTraccs removes outliers by disregarding very fast and very slow pages, using the interquartile range algorithm. Values are calculated over a period of 60 minutes.
With each migrated page the values will be updated.
Those values will change over the course of the migration. If the migration starts with pages that have no attachments, you might see great migration times of maybe 5 seconds per page. But if suddenly pages start to have dozens of attachments, each a couple of megabytes in size, times will go up.
Estimate before migrating
Use the Migration Duration Estimator to forecast the migration duration before starting.Black console window and log files
Looking at the black console window you’ll get more numbers than in the blue WikiTraccs.GUI window.
You can see those numbers in the common log files as well, as everything shown in the console window is stored there. You can open and look at those log files while the migration is running.
Live metrics calculated after each migrated page
Note: those metrics are available as of WikiTraccs 1.22.1
Note: as WikiTraccs evolves, the available metrics and wording will change and evolve as well.
WikiTraccs measures the time it spends on different migration-related activities. Different metrics are calculated from thsoe times.
Those metrics are supposed to roughly show how fast the migration is going over a period of time, as well as some additional insights. This can predict future migration times, but only if pages are similar with respect to certain metrics.
Here’s a sample:
[023 21:32:46 DBG MIG ] [https://contoso.atlassian.net/wiki] Metrics FROM THE LAST 60 MINUTES, covering 21 page-like contents ("items"):
Median time (IQR) : 23 s/item
Median time : 55 s/item
75th percentile (IQR): 87 s/item
75th percentile : 132 s/item
Mean time (IQR) : 68 s/item
Mean time : 90 s/item
Items per hour : 41-156 (based on IQR Median and IQR 75th percentile)
Avg links transformed: 2/item
Have files : 59% of items
File count avg : 23.9 per item that has files
File size avg : 502 KB/file
Download speed : ~451 KB/s
Upload speed : ~91 KB/s
File size sum down : 305.8 MB
File size sum up : 1911.6 MB
Estimated time left for the remaining 322 items: 2.1-7.8 hours (ETA: 12/11/2024 23:36 - 12/12/2024 05:19) (based on IQR Median and 75th percentile)
[023 21:32:46 DBG MIG ] [https://contoso.atlassian.net/wiki] Time spent in the last 60 minutes (excerpt, overlapping, excluding outliers):
(SharePoint, File, Content) : 11.58 min
(Confluence, File, Content) : 3.19 min
(SharePoint, Page, Content) : 2.03 min
(Confluence, Page, Transformation_Macro_Other) : 1.57 min
(Confluence, Page, Link_Soft) : 0.97 min
(SharePoint, WikiTraccs, Prerequisites) : 0.67 min
(SharePoint, Page, Principal) : 0.55 min
(Confluence, Page, Principal) : 0.47 min
(SharePoint, Page, Metadata) : 0.47 min
(SharePoint, File, Metadata) : 0.28 min
(SharePoint, Workspace, Metadata) : 0.26 min
(Confluence, Page, Transformation_UserMention) : 0.26 min
(SharePoint, Page, Stub) : 0.25 min
(SharePoint, Page, Configuration) : 0.23 min
(Confluence, Page, Link_Hard) : 0.21 min
(Confluence, Page, Comments) : 0.20 min
(SharePoint, File, Principal) : 0.17 min
(Confluence, Page, Permission) : 0.14 min
(Confluence, Page, Content) : 0.13 min
(Confluence, Page, Tree) : 0.09 min
Details about above values:
| Metric | Meaning |
|---|---|
| Median time | Median migration time per page |
| Median time (IQR) | Median migration time per page, after removing outliers |
| 75th percentile | 75th percentile of page migration times |
| 75th percentile (IQR) | 75th percentile of page migration times, after removing outliers |
| Mean time | Average migration time per page |
| Mean time (IQR) | Average migration time per page, after removing outliers |
| Items per hour | Pages migrated per hour, based on IQR Median and IQR 75th percentile |
| Avg links transformed | The average number of links on those pages; links increase migration times |
| Have files | The percentage of pages that have attachments or link to external images |
| File count avg | The average number of files that were uploaded per page (of the pages that have any files) |
| File size avg | The average file size |
| Download speed | Average download speed for downloaded files |
| Upload speed | Average upload speed when uploading files to SharePoint Online; this also includes several metadata operations, so it will be lower that the ‘raw’ file content upload speed would be |
| File size sum down | An indicator of downloaded file content; this is not exhaustive and accuracy will be improved in a future release |
| File size sum up | An indicator of uploaded file content; this is not exhaustive and accuracy will be improved in a future release |
Following those metrics is a list of transformation operations that WikiTraccs spent time on. This is a rough indicator of how much time each operation takes.
Most time will probably be spent on (SharePoint, File, Content), which includes file upload to SharePoint, (Confluence, File, Content), which includes attachment download from Confluence, and (SharePoint, Page, Content), which includes SharePoint page creation.
Those values can and will overlap, so their sum will be higher than the actual time spent. For example uploading page content and resolving links can happen in parallel.
Note
Those values are supposed to make transparent where WikiTraccs spends its time. They could also hint at potential points for optimization.
If you think another metric could be valuable in above list, get in touch, I’d like to hear about your use case.
Live progress for large attachment lists
If WikiTraccs migrates a page with lots of attachments (“lots” being ~50 and more), you will see intermittend progress output like this:
Applied provisioning chunk 3/4; handled 41/53 of files; that's 46.6 files per minute and 0.3 minutes to go
This shows the number of already uploaded files (41 of 53), how many files per minute have been uploaded (46.6), and - based on those numbers - an estimated finish time (in 0.3 minutes).
Note
WikiTraccs optimizes file uploads. Files are uploaded to SharePoint Online in parallel, 2 files at a time.
You can configure more files to be uploaded in parallel, but might get throttled faster by Microsoft. Use the WiggleRoom.ParallelFileOperationsCount configuration parameter in appsettings.json to increase the parallelism count. Experience shows, though, that this doesn’t make much of a difference.
9 - Updating Previously Migrated Pages
Why Update Older Migrated Pages?
Updating migrated pages in SharePoint is relevant when the original Confluence pages change after the migration. You might want to update the previously migrated pages in SharePoint with the new content.
When users edit a page in Confluence, but that page has already been migrated to SharePoint, the SharePoint page will be outdated. It does not reflect the current state of the Confluence page anymore.
That’s where the update mode of WikiTraccs comes in, sometimes also referred to as delta migration.
Note
The update mode only covers the case where pages are updated in Confluence, outdating their SharePoint counterparts. It explicitly does not cover the case where the SharePoint pages are updated in any way, outdating the original Confluence content.Approaches
There are two approaches to updating outdated pages in SharePoint:
- The quick approach, where WikiTraccs simply updates outdated SharePoint pages.
- The granular approach, where WikiTraccs lets you choose which outdated SharePoint pages you want to update.
Refer to the following articles for details on both approaches:
9.1 - Updating Previously Migrated Pages - Quick Approach
Note: The functionality described in this article is available as of WikiTraccs v1.29.2.
This article is relevant, if you did already migrate pages from Confluence to SharePoint and now run the migration again. Since your last migration, some of the migrated pages might have changed in Confluence, rendering their SharePoint counterparts outdated. You now want to update those pages in SharePoint as well.
Tell WikiTraccs to Update Outdated SharePoint Pages
In the WikiTraccs settings dialog, in the Migration tab, right below the Mode selection, check Update outdated SharePoint pages:
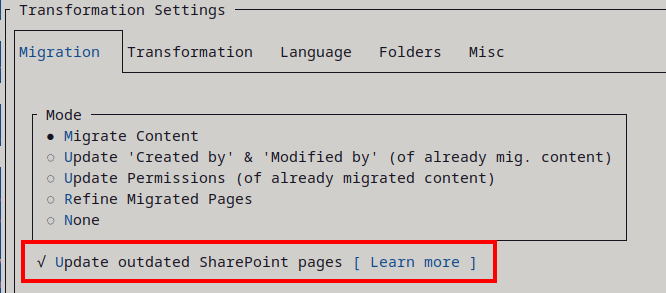
Checking the Update outdated SharePoint pages box tells WikiTraccs to overwrite existing SharePoint pages if an updated Confluence page is found.
Make sure that nobody did work on the pages in SharePoint.
When running the migration again, already existing SharePoint pages will be overwritten, if WikiTraccs detects that the original Confluence pages has been changed since the last migration run. Any changes made to those SharePoint pages will be lost. Also, there is no version history preserved for those SharePoint pages.
Limitations
Please have a look at the Notes about limitations of delta migrations section.By default, this setting is not checked.
Note that this check box is only visible (and relevant) when you choose the Migrate Content mode.
9.2 - Updating Previously Migrated Pages - Granular Approach
With the granular approach you can review the list of previously migrated outdated pages, before updating them.
WikiTraccs will first present you a list of pages that were changed in Confluence since last migrating them to SharePoint. You then choose which of those pages to update (overwrite) in SharePoint Online.
How to detect pages that have been changed since the last migration?
First, you start a migration run to learn about the update state of already migrated pages.
Every time a migration starts, WikiTraccs will check if the SharePoint target site already contains migrated pages (from a previous migration). If such pages exist, it will compare the modification date both in SharePoint and in Confluence. The result is written to progress log files.
Note
This migration run doesn’t have to finish. Just let it work long enough to create the progress log files, then stop the migration. But you can also let it finish.Have a look at the documentation about progress log files: Monitoring Confluence to SharePoint Migration Progress > Using progress log files to get insights.
Note
Each migration will create new progress log files, once when starting and once when finishing the migration run. Look at the date and time of those files to choose the most recent ones.One of those types of progress log files contains information about the update state of already migrated pages; that’s the files with 25-update-state-of-migrated-pages in their name.
Here’s a screenshot showing progress log files for 3 migrated spaces (each having 3 progress log files):
Those spaces have been migrated before and when starting another migration WikiTraccs checked for outdated pages, and found two spaces to have outdated pages.
You can quickly see how many outdated pages there are as WikiTraccs writes this information to the file name of the progress log file, like marker-x-needupdate-y-other.
In the screenshot above, one space has 2 pages that need an update, for the other space it’s 3 pages. One space is up-to-date since the marker part is missing from the file name.
How to tell WikiTraccs to update outdated pages?
You tell WikiTraccs which pages it should update by marking those pages in the progress log files, and copying those files to the WikiTraccs.GUI\input folder.
Here are the steps:
- locate a progress log file with 25-update-state-of-migrated-pages and marker in its file name
- this progress log file contains information about outdated pages
- open the progress log file in a text editor - this files contains a header surrounded by
+++(ignore this), followed by multiple lines, each one representing a migrated page (you want to look at those) - take note of the update state near the end of each line, like uptodate or needsupdate
- a line might look like this:
SPACEKEY Page 123456789 Page Title /display/SPACEKEY/Page+Title 2023-08-31T10:16:22 2023-07-10T13:26:24 needsupdate - the values in this line (like SPACEKEY, page ID 123456789, etc.) are separated by tabulator (the “tab key”)
- note: you might know CSV-files, where values in each line are separated by comma or semicolon; here tabulator is used instead
- a line might look like this:
- mark pages you want WikiTraccs to update by adding an x to the end of the page’s line
- make sure to separate the update state value (like needsupdate) and the x you add with exactly one tab character; note: this tab character might already be there
- the line then should look like this:
SPACEKEY Page 123456789 Page Title /display/SPACEKEY/Page+Title 2023-08-31T10:16:22 2023-07-10T13:26:24 needsupdate x- note the x at the end that marks the page for update
- save the progress log file when you are finished marking pages for update
- now copy this modified progress log file to the input folder, that is located next to the logs folder; note: both the logs and input folder are in the same location as WikiTraccs.GUI.exe, which you used to start WikiTraccs
- run WikiTraccs.GUI
- start a migration as usual, by selecting the Start transformation button in WikiTraccs.GUI
Tip: Excel might help in step 4
You can select all lines after that second+++ marker, copy them to the clipboard, and paste them into Excel. Excel should now properly display the data, allowing filtering and modifications. Set the x marker as needed. Then, in Excel, select all lines again, copy them to the clipboard, and paste them back to the file, replacing the original lines. This should even preserve the tabs that separate the values (but you should double-check that).WikiTraccs looks at the input folder when a migration starts. It automatically processes all progress log files it finds in there. Pages marked for update will now be migrated again, overwriting corresponding existing pages that are present in SharePoint.
After finishing the delta migration, delete the progress log files from the input folder; otherwise WikiTraccs will process them again and again, with each started migration.
How does the delta migration differ from a normal migration?
There are certain differences when WikiTraccs finds and processes progress log files from the input folder.
If there are pages marked for update:
- WikiTraccs will only migrate those pages marked for update and skip any spaces that have been marked for migration in the Space Inventory
- WikiTraccs will not remove any files from the input folder
- you have to remove those files manually, otherwise WikiTraccs will migrate them again and again, for each migration you start
- WikiTraccs will not write progress log files for updated pages
- to get updated progress log files, remove any files from the input folder (to end delta migration mode) and start a regular migration; new progress log files will then be created that should reflect that pages are now up-to-date
Notes about limitations of delta migrations
There are some points to be aware of when it comes to delta migrations.
Modification detection
WikiTraccs can detect changes to Confluence page contents, but not attachments or comments. For example, when an attachment is added to a Confluence page, this does not change the modification date of the page and WikiTraccs still sees this page as up-to-date.
This means that Confluence pages where only attachments changed since having been migrated are reported as uptodate in the progress log file.
Note that you can still mark those uptodate pages for update, if you want to force updating pages that WikiTraccs didn’t detect as changed.
Page titles and page links
WikiTraccs derives the file names of SharePoint modern pages from Confluence page titles. That means that changing a page’s title in Confluence can cause the following:
- duplicate pages being created in SharePoint, since the updated page gets a new file name; WikiTraccs does not rename or remove the existing page
- page links can break in SharePoint, when other SharePoint pages link to a page by a name that now changed due to the page being updated
Note that this does only apply when page titles change in Confluence between an initial migration and a subsequent delta migration. So those changes should be kept to a minimum between migration runs.
Changes of SharePoint pages
Changed SharePoint pages (that have been marked for update) will be overwritten when running a delta migration.
Keep in mind that when marking a page for update, this will forcefully overwrite the target SharePoint page. Even if this SharePoint page was modified since the initial migration.
Performance
The delta migration is less efficient compared to the initial migration. More requests to Confluence might be made compared to bulk operations being done in the initial migration.
Please get in touch if you encounter any issues, or have suggestions that would make your life easier.
10 - Known Confluence Macros
How WikiTraccs handles Confluence macros
WikiTraccs contains explicit transformation rules for a range of Confluence macros, but also applies generic transformations.
Macros are transformed on the fly and ideally the macro is replaced by something native to the SharePoint world. If there is no SharePoint way of replacing a Confluence macro then WikiTraccs tries to find an approximation (which is more the norm than the exception).
Tip
Macros so far unknown to WikiTraccs are also transformed, but in a generic way. The number of such macros is logged by WikiTraccs as “Crystal Ball Transformation Count” metric for each page.Read more about how WikiTraccs transforms macros here: How Do Confluence Macros Look in SharePoint?.
List of Known Macros and How They Are Handled
The following table shows macros that are explicitly known to WikiTraccs and how they are handled.
| Macro | Support Level | Macro Transformation Details |
|---|---|---|
| Status | 💚 | The macro will be transformed to text with a color that tries to match the original (not so many choices here in SharePoint…). |
| Noformat | 💚 | The “no formatting” content formatting will be mirrored in the SharePoint page. |
| Code Block | 💚/🟡 | Code macros are transformed to SharePoint code web parts which provide comparable functionality. But if the code macro in Confluence is part of a table or any other nested structure then there is no 1:1 representation in SharePoint. The web part in this case will be replaced by a placeholder and the web part inserted at a top level place in the SharePoint page. |
| SharePoint Online Document (by Communardo) | 🟡 | The macro will be replaced by a link to the SharePoint document. |
| SharePoint Online List (by Communardo) | 🟡 | The macro will be replaced by a link to the SharePoint site containing the list; the link text contains the SharePoint list ID. |
| Profile Picture | 🟡 | The profile picture will be transformed like user @-mentions in the page (see section below for details). |
| User Profile | 🟡 | The user profile card will be transformed like user @-mentions in the page (see section below for details). |
| Enhanced Profile (by Communardo) | 🟡 | The user profile card will be transformed like user @-mentions in the page (see section below for details). |
| Jira Issue Link | 🟡 | The Jira macro will be replaced by a link to the Jira issue. |
| Jira Issue List | 🟡 | The Jira issue list will be converted to a static table showing links to Jira issues. If the table had multiple pages, a snapshot of only the first page is migrated to SharePoint. So, for a query that covers 1000 issues only the first 20 or so will be shown. A link to Jira is added to the SharePoint page so you can jump to Jira to see the live issue list. Note that in Confluence Cloud this does only work with Interactive authentication; see Confluence Cloud Specialties for details. |
| Spreadsheet (by Elements) | 🟡 | The spreadsheet macro will be replaced by a link to the file attachment. |
| View File | 🟡 | The file card will be replaced by a link to the file attachment of the SharePoint page. |
| Office Powerpoint | 🟡 | The file card will be replaced by a link to the file attachment of the SharePoint page. |
| Office Word | 🟡 | The file card will be replaced by a link to the file attachment of the SharePoint page. |
| Office Excel | 🟡 | The file card will be replaced by a link to the file attachment of the SharePoint page. |
| Microsoft Stream Video | 🟡 | The file card will be replaced by a link to the video. |
| Multimedia | 🟡 | The macro will be replaced by a link to the multimedia attachment file. |
| Panel, Info, Note, Warning, Tip | 🟡 | The macro will be replaced by a table rebuiding the macros’s structure as far as possible; this can introduce nested tables which will be a challenge for page layout (see section below for details on nested tables). |
| Expand | 🟡 | The expand functionality will be lost and the content remains expanded in the SharePoint page. |
| Gliffy | 🟡 | The Gliffy diagram will be replaced by an image of the diagram (that should be present in Confluence as page attachment); if there is no image a placeholder text will be used instead. |
| draw.io, draw.io board/sketch (by //Seibert/Media) | 🟡 | The draw.io diagram will be replaced by an image of the diagram (that should be present in Confluence as page attachment); if the placeholder is missing WikiTraccs can create it. Furthermore, WikiTraccs can migrate images of all diagram pages. |
| BPMN Modeler Enterprise | 🟡 | Diagrams will be exported as image as seen on the Confluence page. The raw diagram file is migrated as page attachment as well. |
| Roadmap | 🟡 | Will be exported as image. |
| Widget Connector | 🟡 | The macro will be replaced by a link to the content it links to (for example a YouTube video), if there is such a link. |
| HTML | 🟡 | The HTML content from the macro will be transformed to a code web part in SharePoint; so the HTML is transformed to code and especially JavaScript will not be executed in the SharePoint page. |
| Tabs Container, Tabs Page (by Adaptavist) | 🟡 | This macro displays multiple tabs which is a challenge because SharePoint has no tabs. So the tabs are each one transformed to “normal” page content and all tabs are added one after another to the page. |
| Attachments | 🟡 | Note that the actual attachments of Confluence pages are always migrated to SharePoint. The Page Attachments macro is migrated as a static view of the macro at the time of migration. So the SharePoint page will show a static table with attachment links and some metadata. |
| Brikit Theme Press | 🟡 | The Brikit Theme Press is recognized by WikiTraccs. Brikit Theme Press layers will be converted to modern SharePoint page sections. Each SharePoint page section will have a number of columns that corresponds to the number of columns in the Brikit Theme Press layer. SharePoint can only have a maximum of three columns in a section, so WikiTraccs will create additional sections if there are more columns in the Brikit Theme Press layer. The content from Brikit Theme Press blocks will be added to the corresponding SharePoint section columns. Note: Introduced in WikiTraccs v1.16.0. |
| Page Tree | 🟡 | The Page Tree macro is migrated as a static view of the macro at the time of migration. The SharePoint page will show a static tree of page links. |
| Table of Contents | 🟡 | Migrated as a static view of the macro at the time of migration. The SharePoint page will show a static tree of page links. |
| Children Display | 🟡 | Migrated as a static view of the macro at the time of migration. The SharePoint page will show a static tree of page links. |
| Include Content Suite (by Keysight Technologies): Shared Block, Include Shared Block | 🟡 | The shared block macro content is migrated as is, without surrounding text placeholders. The include shared block macro is migrated as copy of the referenced “shared block” macro, instead of just a text placeholder. Page links and image references are adjusted. Note: Introduced in WikiTraccs v1.23.16. |
| PlantUml Suite (by avono AG): PlantUml, FlowChart, SpaceGraph, LinkGraph, Database Structure | 🟡 | Those macros are migrated as image. Note: Introduced in WikiTraccs v1.24.18. |
| PlantUml Database Info | 🟡 | Migrated as snapshot of the database info output that is shown on the Confluence page. Note: Introduced in WikiTraccs v1.24.18. |
| Content by Label | 🟡 | Migrated as static snapshot. Note: Introduced in WikiTraccs v1.25.4. |
| Content Report Table | 🟡 | Migrated as static snapshot. Note: Introduced in WikiTraccs v1.25.4. |
| Aura Content Formatting macros (by Seibert - appanvil) | 🟡 | WikiTraccs recognizes a range of styling and container macros of the Aura suite and tries hard to make the migration result look not too bad (SharePoint doesn’t provide the same nesting capabilities of Confluence). Note: Introduced in WikiTraccs v1.25.11. |
| Mosaic Content Formatting macros (by Kolekti/Adaptavist) | 🟡 | WikiTraccs recognizes a range of styling and container macros of the Mosaic suite and tries hard to make the migration result look not too bad (SharePoint doesn’t provide the same nesting capabilities of Confluence). Note: Introduced in WikiTraccs v1.25.11. |
| Handy Macros for Confluence (by Stiltsoft) | 🟡 | Handy Button is converted to hyperlink. Note: Introduced in WikiTraccs v1.29.2. |
| Refined Toolkit (by Refined) | 🟡 | UI Button is converted to hyperlink. Note: Introduced in WikiTraccs v1.28.11. |
| Table Chart (by Stiltsoft) | 🟡 | The chart will be migrated as image (Confluence on-premises only). On Confluence Cloud the chart image is not available from Atlassian’s APIs, so the underlying data table is migrated instead. Note: Introduced in WikiTraccs v1.27.13. |
| Jira Chart | 🟡 | The chart will be migrated as image. Note: Introduced in WikiTraccs v1.31.20. |
| Excerpt, Excerpt Include | 🟡 | WikiTraccs copies content of Excerpt macros to the page that contains the Excerpt Include macro. Note: Introduced in WikiTraccs v1.25.11. |
| MultiExcerpt, MultiExcerpt include (by Appfire) | 🟡 | WikiTraccs copies content of MultiExcerpt macros to the page that contains the MultiExcerpt include macro. Note: Introduced in WikiTraccs v1.26.18. |
| Include Page | 🟡 | Will be replaced by a link to the included page. |
| Comala Document Management (by Appfire) | 🟡 | Some workflow metadata will be migrated as page labels (note: on-premises only) Note: Introduced in WikiTraccs v1.27.7. |
| Display Metadata (by Communardo) | 🟡 | Metadata values will be shown on the SharePoint page, as page content Note: Introduced in WikiTraccs v1.27.14. |
| Cloak, Toggle-Cloak (by CustomWare/Appfire, Composition Tabs plugin v5.16.10+, Data Center) | 🟡 | The toggle/cloak content visibility functionality is lost. Cloak body content is shown inline with toggle section markers. Toggle-cloak is replaced by a compact indicator linking to the corresponding cloak section. Note: Introduced in WikiTraccs v1.33.16. |
| Table Filter (by StiltSoft) | ⏹️ | Filter functionality is lost, the table remains. |
| Single Cite (by Purde Software) | ⏹️ | The macro will be replaced by the citation content. |
| No Print | ⏹️ | The no-print functionality will be lost, the content remains. |
| Linchpin macros | 🔻/⏹ | There is no special handling built in for Linchpin macros, but they seem to transform fine to either text placeholders or macro body. |
| Other macros not explicitly mentioned | 🔻/⏹️ | Each macro will be replaced, either by a text placeholder or its body content. |
Transformation types:
- 💚 “nearly 1:1” - there is a SharePoint or HTML equivalent allowing to rebuild the functionality in SharePoint
- 🟡 “changes in layout or functionality” - transformation with changes to layout or functionality; this is a transformation that is more than just a generic placeholder, but it does not fully meet the original macro functionality
- ⏹️ “to macro body” - this works for macros that contain “richt text content” which is just normal wiki page content; this transformation type will replace the macro by its rich text content, thus kind of “unboxing” it
- 🔻 “to placeholder” - transforms to a non-functional placeholder text, showing the macro’s parameters
All macros not explicitly mentioned here are transformed to placeholders, so are either ⏹️ or 🔻. When macros contain rich content then the macro is replaced by its rich content.
Static macro snapshots
Many macros could be migrated as a static snapshot. WikiTraccs currently does this for the page attachments macro. After transformation, this macro is represented as a table of attachment links in the target SharePoint page. This table is a static snapshot of how the macro looks in Confluence at migration time.
If you’d like to see additional macros migrated as static snapshot, please get in touch by opening an issue describing your use case.
Confluence Cloud ADF Extensions
In Confluence Cloud Atlassian introduced extensions which (currently) cannot be exported, like the Chart extension:
Those elements will be replace by a text placeholder, until there is a proper programmatic way to export them.
Currently the only way to export those seems to print the web page to PDF, or to export a page as PDF. Even the Word export doesn’t contain those extensions.
10.1 - How Do Confluence Macros Look in SharePoint?
The equivalent of Confluence macros in SharePoint are SharePoint web parts.
Confluence has a rich ecosystem of apps and macros. Microsoft is not there, yet, when it comes to providing a marketplace that brings the same to SharePoint Online.
We briefly examine what macros and web parts are, and then discuss the challenges and strategies for migrating macros to SharePoint.
What Is a Confluence Macro?
A Confluence macro is a piece of functionality that you can add to a Confluence wiki page.
Here’s the Info macro in edit and view mode:
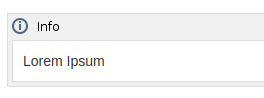
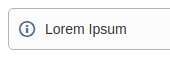
The info macro’s job is to display text that is highlighted with a frame and potentially an icon.
Confluence administrators can install apps from the Atlassian Marketplace to add new macros to Confluence.
What Is a SharePoint Web Part?
A SharePoint web part is a piece of functionality that you can add to a SharePoint page.
Here’s the Text web part in edit and view mode:

SharePoint administrators can install apps from Microsoft AppSource to add new web parts to Confluence.
Migrating Macros to SharePoint Online Is Often Impossible
In most cases, it’s not possible to migrate Confluence macros to SharePoint.
Lack of Available Products
There often is no product available that can serve as a 1:1 replacement for the Confluence macro, either as an out-of-the-box solution or a as a commercial product.
Technical Differences
There are differences between macros and web parts that can make a 1:1 translation technically impossible, even if there was a vendor that tried to provide a 1:1 replacement. This will be covered in another article.
Effort Too High
If there were a product available that could bring a Confluence macro’s functionality to SharePoint, there would be several things that would need to be done:
- Find the product
- Evaluate if the product is a good replacement that covers the use cases
- Purchase the product, or in the case of community solutions
- Make the decision to help maintaining the community solution (one popular solution example is PnP Search)
- Make WikiTraccs transform the macro to the product’s web part
Each of these steps might require a lot of work.
How to Migrate Confluence Macros to SharePoint Online?
Now that we have looked into the difficulties of migrating Confluence macros to SharePoint, let’s talk about solutions.
WikiTraccs uses the following approaches when bringing a Confluence macro to a SharePoint page:
- One-to-one Transformation
- Static Snapshot Transformation
- Generic Macro Body Transformation
- Text Placeholder
The following sections look into each of those approaches.
One-To-One Transformation
Some SharePoint web parts can replace the Confluence macro nearly one-to-one.
An example is the Code Block macro which will be transformed to a Code Snippet web part.
The expectation for a 1:1 transformation would be, that the SharePoint web part does things the same way as the Confluence macro.
There are not many of those transformations.
Static Snapshot Transformation
When WikiTraccs cannot find a 1:1 replacement for a Confluence macro in SharePoint, it might resort to taking a snapshot of the source macro.
Snapshot means, that it will migrate the current view of a macro to SharePoint, where the view will end up either as static page content or as a static image.
The Children Display Macro as an Example of Text Snapshots
One example is the Children Display macro. In the following sample, this macro shows the child pages for the current page, two levels deep:
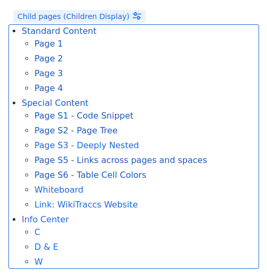
Macro Edit View in Confluence
When migrating this to SharePoint, WikiTraccs takes a static snapshot of this view, and puts that into the migrated SharePoint page:
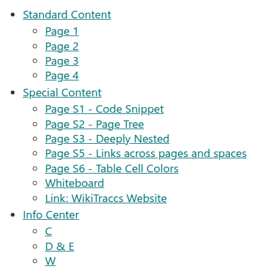
Snapshot View in SharePoint
Those links will work and point to the correct SharePoint pages. But the list won’t change when you add or remove pages, as it’s just a list of links in a SharePoint Text web part:
Text Web Part Edit Mode in SharePoint
In Confluence, when adding child pages to the current page, those pages will be shown by the Children Display macro. On the migrated page in SharePoint, the list is static.
Note
When creating a static snapshot of a macro, the snapshot includes what a user would see when looking at the page in a browser. If the macro supports paging though a long list of content in any way, only the content that is shown when opening the wiki page will be part of the snapshot.The Draw.io Macro as an Example of Image Snapshots
Another popular example is the draw.io macro.
When migrating a draw.io macro to SharePoint, WikiTraccs uses the macro’s preview image and inserts that to the SharePoint page.
So, in SharePoint you’ve got a static image. The raw draw.io file is still around in SharePoint as page attachment, but still, you would have to take the file outside SharePoint to make changes to the diagram.
Generic Macro Body Transformation
WikiTraccs applies the Generic Macro Body transformation to macros that it doesn’t know (yet) or where there is no explicit transformation built-in.
Many Confluence macros act as frame for content. Let’s revisit the Info macro:
The body of the Info macro is the Lorem Ipsum text. When viewing the Confluence page, the Info macro applies formatting to its body - it draws a frame and shows an icon:
Another example is the Aura Background Content macro. This macro can be used to change the background of content, for example add a background color:

At the time of this writing, there was no explicit transformation built in to WikiTraccs for the Aura Background Content macro. So, WikiTraccs uses the default transformation for such macros: it migrates the macro body and surrounds it with text markers, indicating that there was a macro:

You’ll get used to that look after migrating a few pages.
Note
You can remove and change the placeholder texts using Macro Transformation Templates.A drawback of this approach is that it often loses styling and formatting. The benefit is that it preserves the actual content.
Text Placeholder
If WikiTraccs encounters a Confluence macro that has no body and thus no content that could be migrated, it replaces the macro with a text note.
Take the Stiltsoft Handy Button as example:
At the time of this writing there was not explicit transformation for this macro built into WikiTraccs. WikiTraccs transforms the macro to a text placeholder:

Here, the parameter output also shows the button caption and the link it points to. This would be a good candidate for being converted to a plain link by WikiTraccs.
Can WikiTraccs Transform a Macro Differently?
WikiTraccs continuously adds new macro transformations. Each transformation has to be hand-crafted. This is mostly driven by customer demand, so I’d like to hear about your high-priority macros.
When adding macro transformations to WikiTraccs, it is often not immediately clear how the result should look on a modern SharePoint page; or there are multiple ways of doing it.
Help me help you by suggesting a transformation and providing me with additional information. The most important part for me is that the desired result could be built manually by a user, in the browser, on a modern SharePoint page. For when a user can build it, WikiTraccs can do as well.
Please refer to the following blog post for more information on how features are added to WikiTraccs and which information helps getting it done: Can Feature ‘XYZ’ Be Added to WikiTraccs?
10.2 - Macro Placeholders and Transformation Templates
Note: Macro transformation templates are available as of WikiTraccs v1.20.6.
Note: Macro transformation templates got more powerful with release v1.26.1. Make sure to use a current version.
What are Macro Placeholders?
Macro placeholders are text replacements for macros and look like this:
🚧👇 Replaced ‘xyz’ macro, its content follows below (atlassian-macro-output-type==‘INLINE’)
🚧☝️ End of content of replaced ‘xyz’ macro
When migrating wiki pages from Confluence to SharePoint, WikiTraccs has to transform macros to something that SharePoint understands.
If there is no equivalent to a macro in SharePoint (which is the regular case), WikiTraccs often applies a generic transformation that replaces the macro in SharePoint with a text note.
Macro Placeholder Example
Let’s take the div macro as example. It is part of Adaptavist’s Content Formatting Macros offering.
How does the div macro look before and after having been migrated to SharePoint?
The div macro allows to apply formatting to Confluence page content, like setting the text color.
The following configuration applies a blue text color to the macro content when the macro is shown on the Confluence page:

Macro in edit mode, applying the 'color:blue' CSS style to its content, plus some other things.

Macro in view mode, displaying blue text in the Confluence page.
When migrating this macro to SharePoint, WikiTraccs discards the macro container, pulls its content out, and puts that on the page. A text placeholder highlights that this happened:
So, the result of this transformation is:
- all content of the div macro has been migrated
- formatting is gone with the macro container
- a text placeholder highlights that a former div macro has been removed, but the content retained
Now, sometimes you want to get rid of that 🚧 placeholder text. You can create a custom placeholder to do that.
How to Create a Custom Macro Placeholder?
Advanced Topic
This and the following sections cover macro transformation templates which are designed to change how migrated pages look in SharePoint Online.
Originally, they were thought as a simple way to replace the default placeholder texts that WikiTraccs generates. But over time they got so powerful that WikiTraccs now by default uses a combination of built-in transformation logic and customizable transformation templates when adding support for new macros.
WikiTraccs allows to replace many of its built-in macro transformations using transformation templates. This can be used to replace generic macro placeholders with something different.
Note
There might be macros that are handled in such a way that their transformation logic cannot be replaced. One example is the code macro, which is transformed to a code snippet web part.You can use Handlebars templates to describe how the placeholder for a macro should look. Handlebars is a markup language and templating system commonly used in web development.
Note
Refer to the Handlebars documentation to learn how Handlebars templates work. It is out of scope for this article to cover this.Let’s say we want to remove the placeholder text for the transformed div macro, just migrating its body content.
The Handlebars template to do that looks like this:
{{!-- Don't add placeholder text, just render body --}}
{{Body}}
Some facts about above template:
{{Body}}is a variable, referencing the macro body; this tells WikiTraccs to just render the macro body, without additional placeholder text{{!-- --}}marks a comment in the template; this is ignored by WikiTraccs
Using above transformation template, the transformed macro looks like this in SharePoint:

The 🚧 note is now gone.
Where to Put the Transformation Template File?
Custom transformation templates are stored as files in a folder.
When using WikiTraccs.GUI (the blue window), find WikiTraccs.GUI.exe and starting there, find the Templates\Transformation folder. Save your template file there.
When solely using WikiTraccs.Console (this most likely is not the case), find WikiTraccs.Console.exe and starting there, find the Templates\Transformation folder. Save your template file there.
The Transformation folder alreads contains files and should look like this (note that this can change in future WikiTraccs releases):
Each of those .hbs files contains a transformation template.
Note
The .hbs file extension is mandatory.The transformation templates can apply to either
- a single macro type (like div, or rw-ui-tabs-macro), OR
- multiple macro types (like english,belarusian,bulgarian,canadian-en,…)
Transforming a Single Macro Type
When you want to transform a single macro type (like div), you save the transformation template in a file that carries the internal macro name in its filename and has the .hbs extension.
The file containing the transformation template for the div macro would thus be named div.hbs.
To reiterate, the steps to create a transformation template for a single macro type are:
- identify the internal macro name
- you can see macro names in the storage format XML
- note: for our div macro we see
ac:name="div"in the storage format XML
- create a Handlebars template that describes how the custom placeholder should look
- save the Handlebars template in a file, in the Templates\Transformation folder
- the filename follows the pattern MACRONAME.hbs where MACRONAME is the name of the macro
- the file extension must be .hbs for WikiTraccs to recognize the file
Transforming Multiple Macro Types With a Single File
You can also put a special comment as first line into your .hbs file to apply the template to multiple macros, saving you the hassle to create identical files for each of those types.
Here is an example:
{{!-- applyto:english-us,english,belarusian,bulgarian,canadian-en,canadian-fr,catalan,chinese,croatian,czech,danish,dutch,estonian,finnish,french,german,greek,hindi,hungarian,icelandic,indonesian,irish,italian,japanese,korean,latvian,lithuanian,malay,maltese,norwegian-nb,norwegian,polish,portuguese,portuguese-br,romanian,russian,serbian,slovak,slovenian,spanish,swedish,thai,turkish,ukrainian,vietnamese --}}
This tells WikiTraccs to use the template for all the macros listed after the applyto: marker (internal macro names, separated by comma).
The filename doesn’t matter, as long as it has the .hbs ending.
Which Variables Are Available in Templates?
Note
Templates are written in the Handlebars markup language that uses double and triple pairs of curly braces to encapsulate logic and variables. So, any of below variables might need to be enclosed in curly braces - look at existing templates or the Handlebars documentation on how the syntax looks exactly.The following variables are available in transformation templates:
| Variable | Data Type | Meaning |
|---|---|---|
Body | n/a | the macro body (if the macro has one) |
HasBody | boolean | true, if the macro has a body |
HasNoBody | boolean | true, if the macro has no body |
Details.InternalName | text | internal macro name (for example “bgcolor”) |
Details.DisplayName | text | macro display name (for example “Background Color”) |
TypeAsString | text | ‘macro’ for macros, ‘ADF extension’ for ADF extensions, ‘unknown embedding’ otherwise |
IsMacro | boolean | true, if the macro is a macro |
IsMacroEmpty | boolean | true, if the macro is empty; a macro that only consists of whitespace and line breaks is considered empty as well; note that body-less macros may be considered not empty, if they are known to convert to content (like a date macro which seems empty, as it has no body content, but transforms to the current date and is therefore not empty) |
IsAdfExtension | boolean | true, if the ‘macro’ is an ADF extension (so, not really a macro, but covered by macro transformation nevertheless) |
HasParameters | boolean | true, if the macro has parameters |
HasNoParameters | boolean | true, if the macro has no parameters |
ParameterCount | number | the number of macro parameters |
Parameters | collection | macro parameters, if the macro has any; each parameter has a Name and Value property; there is also a Links property that is populated with links parsed from the parameters |
MacroXml | text | contains the raw macro XML as defined in the page’s storage format; note that you most likely need the triple brace syntax (like {{{MacroXml}}}) to work with that variable to prevent escaping |
@CanTransformToTable | boolean | null | internal indicator of WikiTraccs if the macro can be transformed to a table; sometimes set to false to prevent nested table structures, sometimes set to true if nesting is unlikely; might be null |
DefaultPlaceholder | n/a | generates the generic macro placeholder that is output by WikiTraccs if it doesn’t know a macro; this will output a placeholder text, macro parameter values, and the body (if there is any) |
RandomGuid1 | text | a randomly generated GUID value; the variable has the same value during one macro transformation, even if used in multiple places of the template file; this can be useful if you need a random GUID at multiple places in the same template; there is also RandomGuid2 and RandomGuid3 available, providing up to 3 random GUIDs |
Parameter | object | special variable granting access to macro parameters; see section Accessing Macro Parameters below |
The following commands are available as well:
| Command | Meaning |
|---|---|
{{Exit}} | Cancels processing of the current transformation template; can be used to fall back to the built-in transformation logic of WikiTraccs |
{{RemoveMacro}} | Removes the current macro without replacement |
There are also helper functions available like String.Equal (which can be used to compare two text values for equality). Those are sometimes used by WikiTraccs’ own templates and are documented via their usage in those templates.
WikiTraccs brings some transformation template files along. In the Templates/Transformation folder, have a look at the unknown.hbs.sample file for an advanced usage example, or any of the other files.
Note
WikiTraccs more and more transitions to using transformation templates instead of hard-coded macro transformation logic.Working with Macro Parameters
Macro parameters can be accessed via the Parameter variable.
For example the value of the macro parameter title is available via Parameter.title.Value. The parameter name (here title) is always written lowercase, even if the original macro parameter is not.
To get the value of a macro parameter (as text), you use the Parameter.paramname.Value syntax.
To get the raw XML representation of a macro parameter (as text), you use the Parameter.paramname.Xml syntax.
If the macro parameter contains links, those are accessible via the Parameter.paramname.Links collection. Each of the links can have a Title and Href property. The unknown.hbs.sample sample transformation template file shows how to enumerate links.
Sometimes WikiTraccs injects additional macro parameters mainly for internal use in its own transformation templates:
Parameter.wikitraccs-targetreference- added (for example) to Excerpt Include and Multiexcerpt include macros; this parameter contains anac:linkelement, pointing to the page the snippet is included from; it’s used to generate a link to the source page
Multi-Pass Transformation
Macro transformation is done in three phases for each macro:
- prebuiltin
- builtin
- postbuiltin
Prebuiltin can be used to decorate a macro before the built-in transformation logic kicks in.
Builtin executes the built-in transformation logic for a macro. Macro transformation templates can replace this logic.
Postbuiltin is used internally by WikiTraccs where a macro is not yet fully transformed in the builtin stage, but will be in postbuiltin.
Macro transformation templates by default are applied in the builtin stage (and replace the builtin transformation logic), unless marked otherwise.
A transformation template can be marked for a specific stage like this:
expand[prebuiltin].hbs- executed in prebuiltin stageexcerpt-include[postbuiltin].hbs- executed in postbuiltin stageexcerpt.hbs- no marker, builtin stage by default
Templates for SharePoint Web Parts
Have a look at the Convert Macros to SharePoint Web Parts to learn about web part generation.
Templates that generate web parts have a specific structure and the <div data-wikitraccs-webpart-template="true"> element plays a key role. It acts as marker for WikiTraccs to trigger web part generation.
Important Notes About Macro Transformation Templates
Troubleshooting
If your template is not recognized check for the following issues:
- the template file is in the wrong folder
- the template file doesn’t have the .hbs file ending
- the filename doesn’t have the right pattern
- the macro is already handled by a built-in transformation rule and thus no generic placeholder is being generated (note: there is nothing you can do about that; please get in touch and give feedback)
- the template is malformed
Note
When starting WikiTraccs.GUI it will process all transformation templates it can find and log the result to the common log files. If there is an error, it will show an error dialog.
So, after editing template files, start WikiTraccs.GUI and if nothing pops up, at least the syntax is correct.
Note: this behavior is new as of release v1.26.1.
Check the console log output or common log files to see if WikiTraccs loads your template.
This is how the log looks if a template could be successfully loaded:
Found 3 transformation template files in folder '<path>/Templates/Transformation', will handle one by one: ch.bitvoodoo.confluence.plugins.language.hbs div.hbs rw-ui-tabs-macro.hbs
Trying to load transformation template from file 'Templates/Transformation/div.hbs'
Compiling and registering transformation template for 'div'
Any issues should be visible here as well. You can also look at the logs to learn about the path WikiTraccs loads templates from, if you are unsure where to put them.
10.2.1 - Macro Transformation Template Samples
Note: Macro transformation templates got more powerful with release v1.26.1. Make sure to use a current version.
Note
Macro transformation templates replace internal transformation logic of WikiTraccs.Simple Body Replacement
Remove Macros without Body
The following template replaces the macro by its body content, for a list of macros. If the macro has no body, it will be removed.
{{!-- applyto:style,auibuttongroup,auibutton,div,bgcolor,alert,align,bibtex-reference,bibtex-display,center,clickable,auidialog,span,fancy-bullets,footnote,display-footnotes,highlight,auihorizontalnav,htmlcomment,img,table,tr,th,td,thead,tbody,iframe,latex-formatting,ol,li,ul,lozenge,auimessage,p,pre,privacy-policy,privacy-mark,auiprogress,auiprogressstepstatic,roundrect,search-box,span,tooltip,strike,copyright,reg-tm,sm,tm, --}}
{{#if HasBody}}
{{Body}}
{{else}}
{{RemoveMacro}}
{{/if}}
This preserves the macro body, even if it only consists of whitespace or line breaks.
Remove Macros without Body, or with Empty Body
If you want to remove such empty macro bodies as well, use the following approach, which also removes macros with empty body:
{{!-- applyto:style,auibuttongroup,auibutton,div,bgcolor,alert,align,bibtex-reference,bibtex-display,center,clickable,auidialog,span,fancy-bullets,footnote,display-footnotes,highlight,auihorizontalnav,htmlcomment,img,table,tr,th,td,thead,tbody,iframe,latex-formatting,ol,li,ul,lozenge,auimessage,p,pre,privacy-policy,privacy-mark,auiprogress,auiprogressstepstatic,roundrect,search-box,span,tooltip,strike,copyright,reg-tm,sm,tm, --}}
{{#if HasBody}}
{{#unless IsMacroEmpty}}
{{Body}}
{{else}}
{{RemoveMacro}}
{{/unless}}
{{else}}
{{RemoveMacro}}
{{/if}}
10.3 - Convert Macros to SharePoint Web Parts
Note: Converting macros to web parts is available as of WikiTraccs v1.26.1.
Refer to below videos to learn how to configure WikiTraccs to create either Children Display, or Jira web parts.
Convert Children Display Macros to Children Display Web Parts
The WikiPakk app makes Children Display web parts available in SharePoint (note: starting with release 2.9.0). Adding this app to the site is required for the Children Display web part to be available.
Convert Jira Macros to Jira Web Parts
The SharePoint Connector for Jira app makes Jira web parts available in SharePoint. Adding this app to the site is required for the Jira web part to be available.
Note: this only works for Jira issue lists. Single Jira issues, or other Jira macros (charts, …) are not supported by the SharePoint Connector for Jira app (at the time of writing this).
Convert Other Macros to Web Parts
Converting to other web parts might already be possible, although it hasn’t been tested, yet. Have a look at above videos and the macro transformation templates files they mention to get an overview of how the whole process works. It is meant to be adaptable to other web parts as well.
11 - Security
Architectural Overview of WikiTraccs
The following image shows which building blocks are at play when running a WikiTraccs migration. You find details about each building block in the table below the image.
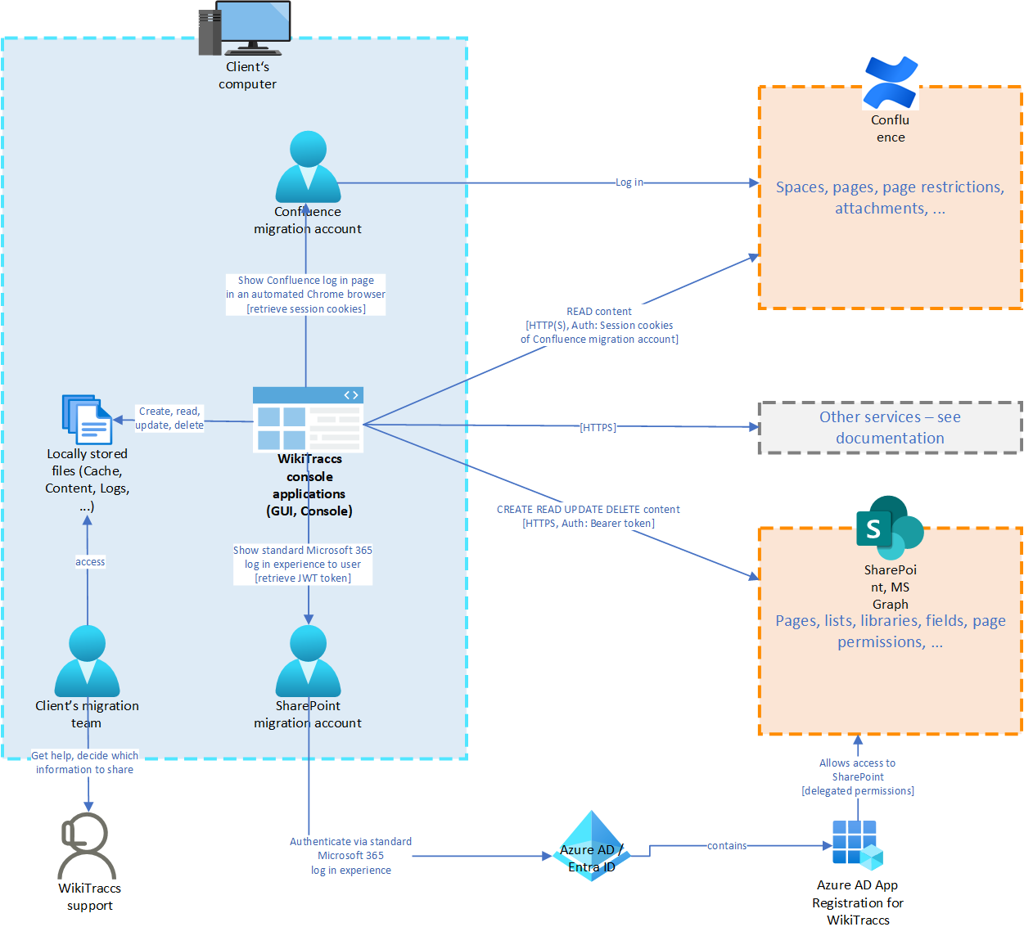
The building block explained:
| Building block | Purpose |
|---|---|
| Client’s computer | A computer running WikiTraccs. Uses Windows as operating system. You control this computer. |
| WikiTraccs console applications (GUI, Console) | WikiTraccs consists of two .NET-based console applications: WikiTraccs.GUI.exe and WikiTraccs.Console.exe. WikiTraccs is portable, no installation is necessary. |
| Confluence | The source Confluence environment that should be migrated to SharePoint. You decide whether this environment is being connected to via HTTP or HTTPS by using the respective URL scheme (http://, https://) in the source address configuration of WikiTraccs. WikiTraccs’ TLS support is determined by the Windows host environment and the Confluence server. Note when enforcing TLS 1.3 with Confluence, you have to use a migration machine with a recent Windows version with proper TLS 1.3 support (Windows 11 or newer, Windows Server 2022 or newer). |
| Confluence migration account | The account used to log in to Confluence. WikiTraccs uses the session of this account and therefor has access to everything this account has access to. |
| SharePoint, MS Graph | The Microsoft 365 target environment that will be migrated to. All connections are HTTPS and TLS-secured. For the state of TLS in Microsoft 365 have a look at Preparing for TLS 1.2 in Office 365 and Office 365 GCC. As Microsoft deprecated connections via TLS lower than 1.2, at minimum TLS 1.2 will be used when connecting to Microsoft 365 services. |
| SharePoint migration account | The account used to log in to SharePoint. The permission that WikiTraccs has is the intersection of this user’s permission and the permissions configured for the Entra ID app registration. |
| Entra ID App Registration for WikiTraccs | Entra ID app registration that allows WikiTraccs to work with Microsoft services on an API level. See Registering WikiTraccs as app in Entra ID for details. |
| Locally stored files | WikiTraccs stores files locally on the system it runs. Those files comprise: attachments downloaded from Confluence, log files, caches, WikiTraccs.GUI configuration, debugging-related files (if certain debug settings are turned on) |
| Client’s migration team | This is your migration team. |
| WikiTraccs support | Support channels, mainly GitHub, email, and Microsoft Teams. Support might ask for log files to diagnose issues. You decide if you want to provide those log files. |
| Other services | See section Other Services below this table. |
Other Services
WikiTraccs has a minimum set of required endpoints that it needs when migrating data from Confluence to SharePoint Online. Those endpoints are documented in the WikiTraccs Endpoint Reference.
WikiTraccs might reach out to other service endpoints to enhance the migration tooling. No migration data is sent to other services except SharePoint Online.
Other service endpoints might be used for
- downloading the Google Chrome WebDriver
- downloading the Draw.io viewer
- checking for new WikiTraccs releases, or
- downloading external images.
Again, no migration data is transmitted to those endpoints.
Please refer to the WikiTraccs Endpoint Reference for a list of recommended and optional endpoints, as well as the article about locked down environments and the consequences of locking down: Locked-down environments.
Further Information
11.1 - Secure Development and Release
Scope
WikiTraccs runs on the customer’s migration machine. No vendor‑hosted systems. Data stays local to the customer environment.
No Subprocessors
No vendor cloud hosting or third-party subprocessors involved in product operation.
Development Workflow
- Issues: public issues in a public GitHub repository; private reports tracked in a private repository
- Branching:
mainfor releases; features and fixes in separate branches
CI Checks
- Antivirus scan
- Static code analysis
- Dependency and license scan
- Known vulnerability scan
- Secret scan
Release Integrity
- Release artifacts are signed in CI
- A checksum file lists per‑file hashes in the package
Testing
- Extensive unit test coverage
- Manual testing of releases
Versioning and Support
- Semantic Versioning (MAJOR.MINOR.PATCH)
- Changelog documents all user-visible changes
- Support policy: current GA and prerelease versions receive fixes; older versions are EOL
Vulnerability Disclosure and Response
- Email reports to [email protected]
- Acknowledge within one business day. Start on high‑impact issues immediately. Target fix in two weeks, subject to complexity.
- Safe‑harbor for good‑faith research
- security.txt
Supply Chain Hygiene
- Dependencies are pinned via lock files
- Builds are reproducible
11.2 - Data Storage and Transmission
This article covers one of the major concerns with any migration tool: handling of data.
WikiTraccs handles data securely.
Big Picture
WikiTraccs is a console application that connects to both Confluence and SharePoint Online during the Confluence to SharePoint migration.
It downloads content like pages and attachments from Confluence to a local directory. It processes this locally stored data and uploads it to SharePoint Online.
Where does WikiTracc run? Is it a cloud service?
WikiTraccs is not a cloud service. WikiTraccs is a .NET-based console application that runs on a Windows workstation of your choosing.
The workstation WikiTraccs runs on can be any machine: your VPN-connected laptop at home, an on-premises server, a cloud VM - as long as it can connect to and authenticate with both Confluence and SharePoint Online it will work.
And because this question sometimes comes up: No, WikiTraccs does not need to run on the Confluence server.
Where does WikiTraccs store data? Is data being sent somewhere?
WikiTraccs stores data locally on the workstation it is running on.
This locally stored data includes:
- page contents
- attachments
- log files
- cached data and temporary files
There is no cloud storage involved, apart from SharePoint Online as migration target. Other migration tools use Azure or third-party storage solutions as temporary storage location before data is being moved to SharePoint Online. WikiTraccs does not do that. It directly uploads to SharePoint.
The data never leaves the workstation, except for SharePoint Online, which is the target of the migration.
This article has details on where WikiTraccs stores data on the migration machine: File Storage.
What level of encryption is used for data at rest?
Data at rest in the context of WikiTraccs is content stored on the workstation that is used to perform the migration and to run WikiTraccs. This data is not encrypted and can potentially be accessed by users of this workstation, depending on file system access permissions.
How is data transmission secured?
Connections use TLS version 1.2. For Confluence, some clients run their instance disconnected from the internet and connect via HTTP from their internal network, which WikiTraccs allows.
WikiTraccs uses the Confluence REST API as well as the SharePoint Online API and Microsoft Graph, when it comes to transmitting migrated content.
A complete list of endpoints used by WikiTraccs is shown in the Endpoint Reference.
Can WikiTraccs access all my data?
No, WikiTraccs can only access data you choose to let it have access to.
The access level of WikiTraccs depends on the migration accounts you choose for Confluence and SharePoint.
When starting a migration, you will authenticate with one user account in Confluence, with another user account in SharePoint. Since WikiTraccs accesses data in the context of those user sessions, it can only see what those accounts can see.
Example for Confluence: when starting the migration, you log in with an account that can only see pages from one space. WikiTraccs will only be able to migrate this one space since it cannot access other spaces.
Example for SharePoint: when starting the migration, you log in with an account that is Site Owner on all migration target sites, but doesn’t have access to other sites in the SharePoint tenant. WikiTraccs now also will only be able to access the migration target sites. Nothing else.
Can Wiki Transformation Project or Heinrich access my data?
No, unless you actively send it to me.
Where can I get an architectural overview, like, a diagram?
Please have a look at the Security article, which dives deeper.
11.3 - Endpoint Reference
Required Endpoints
The following table lists the required endpoints for using WikiTraccs.
Microsoft 365
| Required Endpoint | Purpose |
|---|---|
| login.microsoftonline.com | Authentication with Microsoft |
| aadcdn.msftauth.net | Authentication with Microsoft |
| login.live.com | Authentication with Microsoft |
| COMPANY.sharepoint.com | Access to SharePoint APIs (note: replace COMPANY with the value valid for your environment) |
| graph.microsoft.com | Access to Microsoft Graph API |
Atlassian Confluence REST API
WikiTraccs uses the REST endpoints of Confluence.
The REST endpoints are expected under the following URL:
<confluencebaseurl>/rest/api/(on-prem & cloud)<confluencebaseurl>/api/v2(cloud)
Highly Recommended Endpoints
The following endpoints should be made available to WikiTraccs for ease of use. If those endpoints are blocked, it will lead to:
- higher configuration effort
- repeated configuration effort
- reduced migration capabilities
Refer to the following article for information on the different endpoints and the consequences of blocking them: Locked-down environments.
Automatic Chrome WebDriver download
Note
This section is relevant when using Google Chrome as automated browser (which is the default).The Chrome WebDriver is used by WikiTraccs to show a browser window for Confluence authentication.
| Required Endpoint | Purpose | Owner info |
|---|---|---|
| chromedriver.chromium.org | Chrome WebDriver version detection | Whois registrant: Google LLC (CA, US) |
| chromedriver.storage.googleapis.com | Chrome WebDriver download | Whois registrant: Google LLC (CA, US) |
| googlechromelabs.github.io/chrome-for-testing/latest-patch-versions-per-build-with-downloads.json | Chrome WebDriver version information for Chrome starting with version 115 | Github-Repository owner: Google Chrome team |
| edgedl.me.gvt1.com | Host for Chrome WebDriver downloads | Whois registrant: Google LLC (CA, US) |
| storage.googleapis.com | Host for Chrome WebDriver downloads | Whois registrant: Google LLC (CA, US) |
Refer to the troubleshooting section, specificilly on how to manually work around the restrictions imposed by blocking endpoints.
Automatic Edge WebDriver download
Note
This section is relevant when using Microsoft Edge as automated browser (which can be enabled in the WikiTraccs settings).The Edge WebDriver is used by WikiTraccs to show a browser window for Confluence authentication.
| Required Endpoint | Purpose | Owner info |
|---|---|---|
| msedgedriver.microsoft.com | Detecting the Edge WebDriver version | Whois registrant: Microsoft Corporation (WA, US) (last checked: 2026-01-08) |
| msedgewebdriverstorage.blob.core.windows.net | Downloading the Edge WebDriver | Whois registrant: Microsoft Corporation (WA, US) (last checked: 2026-01-08) |
Draw.io Endpoints
Refer to Prerequisites for Draw.io Preview Image Generation for information about endpoints related to Draw.io migration.
Optional Endpoints
Atlassian Confluence (On-Prem) XML-RPC
WikiTraccs uses the REST endpoints of Confluence with one exception.
There is one endpoint of the old XML-RPC API that is being used to read space permissions, since those are not available via the REST API. This endpoint is expected under the following URL:
<confluencebaseurl>/rpc/xmlrpc/
Space permissions are currently retrieved by WikiTraccs but not processed during the migration. It currently is no problem when this endpoint is not available, but data about space permissions might be missing when a future release of WikiTraccs starts working with them.
11.4 - Running WikiTraccs in Locked-Down Environments
The term “locked-down” in this article mainly refers to networking, where network configuration in an environment prohibits WikiTraccs from calling anything else than Confluence and Microsoft 365-related endpoints.
Endpoints Required at Minimum
Please review the WikiTraccs Endpoint Reference for a list of required endpoints.
How Is the Migration Affected by Limited Endpoint Access?
The following migration tasks need endpoints other than Confluence and Microsoft 365:
- Logging in to Confluence using Interactive authentication (requires downloading Chrome/Edge Webdriver)
- Migrating external images (requires downloading those external images)
- Migrating Confluence Cloud whiteboards (requires Chrome/Edge Webdriver)
- Creating draw.io preview images (requires downloading the draw.io diagram viewer and potentially linked resources like images and fonts, as well as the Chrome/Edge Webdriver)
- Migrating Jira macros (requires reaching out to Jira)
- Checking for WikiTraccs updates (requires reaching out to GitHub)
The following sections describe implications, related WikiTraccs settings, and workarounds for any of the above points.
Major Impact: Blocking Chrome/Edge Webdriver Download
Several migration tasks need to be run in a real browser which is controlled by WikiTraccs.
To remote-control the browser, WikiTraccs will automatically download the required tool, the Chrome/Edge Webdriver.
Required endpoints are documented here: Endpoints - Automatic Chrome Webdriver Download and Endpoints - Automatic Edge Webdriver Download.
If any of the required endpoints is blocked, you can manually provide the correct configuration values and Webdriver version as described here: How to handle blocked browser automation endpoints.
Note that if you cannot provide the Chrome/Edge Webdriver to WikiTraccs, you’ll lose several features like interactive authentication, whiteboard migration, draw.io preview image generation, and access to some Confluence APIs that are not accessible otherwise (mostly Cloud-related).
Refer to some of the following sections for details.
Blocking Interactive Authentication
When choosing Interactive authentication for Confluence, WikiTraccs needs to open and remote-control a browser for you to be able to log in to Confluence, and to get the session cookies.
When Chrome/Edge Webdriver download is blocked, Interactive Authentication is not possible anymore.
Use Personal Access Token or one of the workarounds reserved for harder cases.
Blocking Migration of External Images
Confluence allows using images from external (non-Confluence) locations in wiki pages. When such a page opens, the browser will load the image from the external location.
SharePoint Online doesn’t allow loading images from external locations due to privacy concerns. That’s why WikiTraccs, when migrating such a page, downloads the external image and uploads it as page attachment to SharePoint.
If external endpoints are blocked, those external images will be missing in SharePoint.
Note that you can explicitly turn off downloading of external images in WikiTraccs’ settings, speeding up the migration, as WikiTraccs then won’t reach out to external hosts.
Blocking Whiteboard Download (Confluence Cloud)
Whiteboard download needs to be done in a browser that is controlled by WikiTraccs, which requires the Chrome/Edge Webdriver to be in place.
See above section Blocking Interactive Authentication, the same reasoning applies.
Note that you can explicitly turn off whiteboard migration in WikiTraccs’ settings.
Blocking Draw.io Image Generation
Draw.io image generation needs to be done in a browser that is controlled by WikiTraccs, which requires the Chrome/Edge Webdriver to be in place.
See above section Blocking Interactive Authentication, the same reasoning applies.
Furthermore, at least one additional endpoint is required to download the draw.io viewer application. See Prerequisites for Draw.io Preview Image Generation for details.
When starting a migration run, WikiTraccs tests if draw.io images can be generated. If not, the feature is automatically disabled during this migration run.
Blocking Jira Access
You can prevent WikiTraccs from reaching out to Jira by using this configuration snippet: Prevent WikiTraccs from reaching out to Jira.
Proxy Configuration
When configuring *_PROXY environment variables, make sure to add http://localhost to the NO_PROXY environment variable. This is required for the automated Chrome/Edge browser to work properly.
11.5 - Data Processing Agreement - WikiTraccs
WikiTraccs is a console application that runs on a customer-controlled machine and connects only to the customer’s Atlassian Confluence and Microsoft SharePoint Online.
Product network interactions for transparency:
- If your Confluence pages reference third-party resources (for example external images), your environment may contact those external hosts to fetch them. Those hosts receive your egress IP address and act as independent controllers. You control these calls through your configuration and network policies. (Privacy Policy)
If you choose to send support artifacts such as log excerpts or screenshots, I act as a processor only for those materials under your instructions. Artifacts are handled in Exchange Online with data stored in Germany and are deleted within 30 days after issue resolution.
If you require a support-only DPA for this narrow scope, see the template below.
Support Data Processing Addendum (support artifacts only) [Template]
Parties
- Customer (Controller): [Customer legal name], [Customer address]
- Service Provider (Processor): Wiki Transformation Project - Heinrich Ulbricht (sole proprietor)
Definition
“Support Matter” means a discrete, customer-initiated request for assistance submitted via email or similar channel.
1. Subject Matter and Duration
1.1 Processing is limited to support artifacts that the Customer voluntarily provides (e.g., log excerpts, screenshots, redacted sample pages) for the sole purpose of diagnosing and resolving WikiTraccs support requests. Processing lasts only for the Support Matter.
1.2 Where such processing occurs, the Customer is the Data Controller and the Service Provider is the Data Processor of such Personal Data, except where the Customer acts as a Data Processor of Personal Data, in which case the Service Provider is a Data Sub-Processor.
1.3 The Service Provider deletes all artifacts within 30 days after Support Matter resolution unless law requires longer retention.
2. Nature and Purpose of Processing
Viewing, storing, analyzing, and communicating about the artifacts to provide support for WikiTraccs. There is neither operation of hosted services nor access to the Customer’s production systems.
3. Categories of Personal Data and Data Subjects
3.1 Categories of personal data may include business contact data and any personal data incidentally contained in artifacts.
3.2 Categories of data subjects may include the Customer’s employees or users. Special categories are not expected. The Customer will avoid sending secrets, credentials, or special-category data to the Service Provider.
4. Documented Instructions
The Service Provider acts only on the Customer’s documented instructions in tickets or email. If an instruction appears unlawful under the GDPR, the Service Provider will promptly inform the Customer.
5. Confidentiality
The Service Provider ensures that all persons authorized to process the data have committed themselves to confidentiality.
6. Security Measures (Art. 32 GDPR)
The Service Provider maintains appropriate measures for this limited scope, including access controls, malware-protected workstations, encrypted storage at rest, encrypted transmission, least-privilege access, and secure deletion.
7. Sub-Processors
7.1 The Service Provider uses the following sub-processor solely for email handling of support artifacts:
- Name: Microsoft Ireland Operations Limited
- Service: Exchange Online (Microsoft 365)
- Processing: receipt, storage, and transmission of support emails and attachments containing support artifacts
- Primary data location: Germany (tenant setting)
- Safeguards: encryption in transit and at rest; EU Standard Contractual Clauses and Microsoft data protection terms
7.2 The Customer consents to this sub-processor. The Service Provider will notify the Customer of intended changes to sub-processors with 30 days’ notice, and the Customer may object for justified reasons. No other sub-processors will be appointed without the Customer’s prior written consent.
8. International Data Transfers
No transfers of personal data outside the European Economic Area (EEA) are intended by the Service Provider. To the extent Microsoft, as sub-processor, accesses personal data from outside the EEA for service operations, such access is covered by appropriate safeguards, including the EU Standard Contractual Clauses.
9. Assistance
The Service Provider will reasonably assist the Customer with data subject requests, Data Protection Impact Assessments (DPIAs), and consultations, considering the limited scope and information available to the Service Provider.
10. Notification of Personal Data Breaches
The Service Provider will notify the Customer without undue delay after becoming aware of a personal data breach affecting artifacts.
11. Deletion and Return
At Support Matter resolution, the Service Provider will delete all artifacts, including any copies in Exchange Online mailboxes, within 30 days and, on request, confirm deletion in writing. The Service Provider cannot delete data on the Customer’s systems.
Dormant threads: If the Customer does not respond to a Service Provider request for 30 days, the Support Matter will be deemed resolved for deletion timing.
12. Audit and Information
The Service Provider will make available information necessary to demonstrate compliance with this Addendum and will allow one reasonable, document-based audit per year with 30 days’ notice. No on-site audits. No access to systems unrelated to support artifacts.
13. Precedence
This Addendum governs the processing of support artifacts. If it conflicts with other terms, this Addendum prevails for that processing.
Effective date: Effective on the date of the later signature below.
Accepted by:
Customer
Name: ______________________ Title: ___________ Date: ___________
Signature: __________________________
Service Provider
Name: Heinrich Ulbricht Title: Sole proprietor Date: ___________
Signature: __________________________
12 - Using WikiTraccs.GUI
12.1 - Source Configuration
Confluence Base Address
Enter the Confluence base URL into the Confluence base address field.
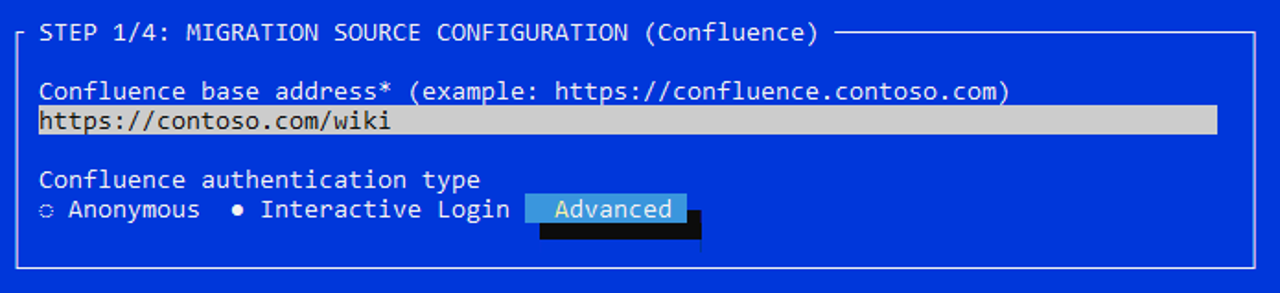
Source configuration
Note that the base URL might differ from the one the end user sees in the browser address bar.
How to manually check that the base URL is correct?
You can check that the base URL is correct by appending /rest/api/user/current and opening the resulting URL in the browser.
Example: Log in to Confluence. Then, assuming the base URL is https://contoso.com/wiki, open https://contoso.com/wiki/rest/api/user/current in the browser. It should show you information about your current user.
Confluence Authentication Type
Choose Anonymous if Confluence is accessible without a logged in user.
Note
Anonymous authentication can be used to migrate content like pages and attachments. What most likely won’t work is migrating permissions and gathering user and group information for user and group mappings. Choose another authentication type instead.Choose Interactive Login to log in interactively. When starting the migration, WikiTraccs will open Confluence in a browser where you can log in. Then, WikiTraccs takes the session cookies from this browser session and uses them when accessing Confluence. To Confluence this looks like the user that was used to log in is accessing the content.
Well-known session cookies
By default WikiTraccs looks for the well-known session cookies with name JSESSIONID, and cloud.session.token. Use the advanced settings only to configure additional cookie names.Advanced Settings
Choose the Advanced button to open the advanced settings dialog.
Additional Mandatory Cookie Names
In the Additional mandatory cookie names input, enter the names of additional cookies WikiTraccs should use to authenticate with Confluence. Separate multiple names by semicolon ;.
SSO Cookies
Some SSO solutions create cookies with names like Contoso_SSO. Enter those names in the Additional mandatory cookie names input.WikiTraccs treats these cookie names as mandatory. It checks their presence when testing the Confluence connection and the test fails if any of them cannot be found. This applies regardless of whether the Copy all browser cookies option is enabled.
Copy All Browser Cookies
Note: This setting is available as of WikiTraccs v1.32.49.
Enable the Copy all browser cookies checkbox to have WikiTraccs copy all cookies from the interactive login browser session, not just well-known session cookies and additional mandatory ones.
This can help when required cookies are difficult to identify by name, unknown, or to work around issues introduced by changes in cookie availability by vendors (Atlassian, marketplace vendors).
Mandatory cookies still apply
Even with Copy all browser cookies enabled, the cookies listed in Additional mandatory cookie names remain mandatory. WikiTraccs still waits for those cookies to appear before considering the login successful. The checkbox only controls whether additional unlisted cookies are copied as well.13 - Authentication
13.1 - Authenticating with Confluence
The following authentication methods are currently supported:
- Interactive authentication (note: this also covers anonymous access)
- Token-based authentication (Confluence 7.9 and later support the use of personal access tokens, and Confluence Cloud)
Interactive Authentication
With this authentication method WikiTraccs uses the context of a logged-in user account. It also covers anonymous access.
Read more: Interactive Authentication
Token-based Authentication
Note: this option is available as of WikiTraccs v1.13 and works with Confluence 7.9 and later, and Confluence Cloud.
Read more: Token-based Authentication
Required permissions in Confluence
The permissions of the Confluence account you log in with determine what can be migrated.
The easiest approach is to log in with a Confluence admin account that has access to all spaces that should be migrated. This allows for content and permission migration.
But maybe you don’t want to use a Confluence admin account. In this case you can also use an account that is space admin in all to-be-migrated spaces. This allows for content and permission migration of those spaces.
The least permissive approach is to use an account that is no admin whatsoever but has normal user permissions like view and edit. This allows for migration of content this account has access to, which might not be all pages. Permission migration is not possible with a non-admin user account.
Certain operations like retrieving user account information or group memberships might be prohibited for non-admin users which might hinder WikiTraccs. If you see such errors in the log try using an account that has more permissions.
Confluence Behind a Security Proxy
Some organizations route Confluence Cloud through a Cloud Access Security Broker (CASB) reverse proxy, like Microsoft Defender for Cloud Apps with Conditional Access App Control (“MCAS”). The sign: after login the address bar shows a rewritten host ending in .mcas.ms (e.g. your-site.atlassian.net.mcas.ms) plus a screen reading “Access to Atlassian is monitored … Access is only available from a web browser.” WikiTraccs then hangs at “Looking for a Confluence session” and reports “Could not get all required Confluence auth cookies”.
The proxy sits between you and Confluence: it rewrites the addresses and cookies (the session cookie even ends up encrypted on the .mcas.ms host) and restricts access to web browsers only. That can interfere with the different ways WikiTraccs connects to Confluence, so authentication may fail. This is your organization’s security configuration, not a WikiTraccs defect, which is why a working migration can stop the day the policy is switched on.
The clean fix is on the Microsoft 365 / Entra side: ask your security team to exclude the Atlassian apps (or just the migration account) from the Defender for Cloud Apps session policy and the Conditional Access “Use Conditional Access App Control” grant for the migration. “Monitor only” / “Report-only” is not enough: monitor mode still proxies, so a proper exclusion is required.
If exclusion is not possible, try token-based authentication instead: it uses a Confluence API token rather than a browser cookie, so it does not depend on the proxied session (though your security team may still need to allow that traffic). Microsoft Edge is sometimes exempt from the proxy and can help, depending on the configuration.
13.1.1 - Interactive Confluence Authentication
With interactive authentication, WikiTraccs uses the context of a user account you log in with.
Interactive Authentication
To authenticate with Confluence, WikiTraccs will open a browser window.
Note
WikiTraccs supports Google Chrome and Microsoft Edge. You might have to configure WikiTraccs, which one it should use.In the browser, WikiTraccs opens Confluence and adds a panel as overlay to the Confluence page, telling you to log in:
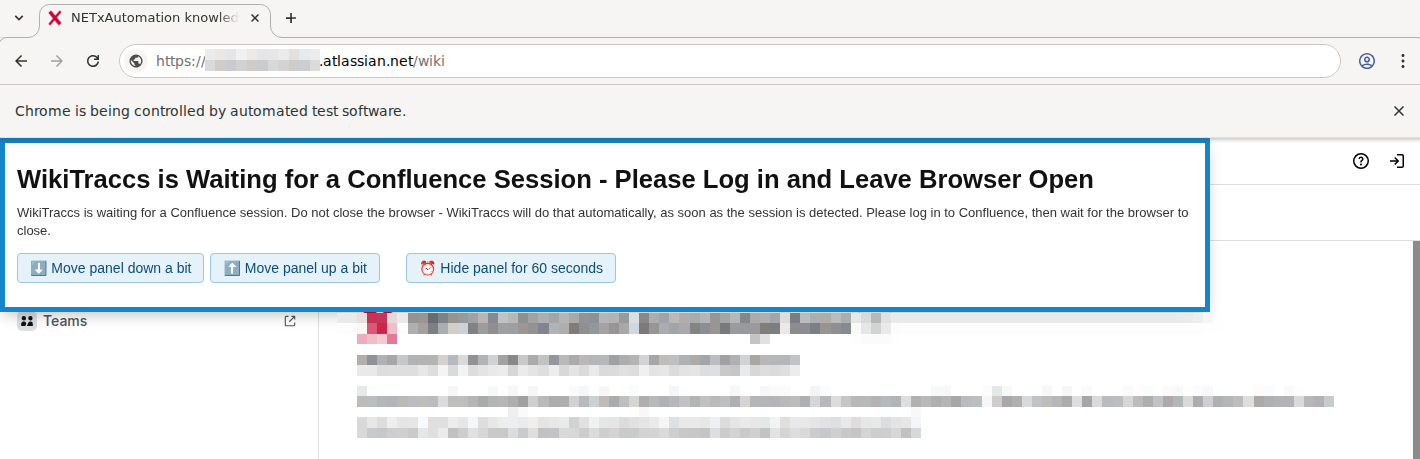
Note: the design and text of the panel might change in future releases.
Now log in to Confluence like you normally would. If the panel that WikiTraccs added is in the way, use its buttons to move it out of the way or hide it.
As soon as WikiTraccs got what it needs, it will automatically close the browser. Wait for the browser to close.
WikiTraccs will use the cookies from the authenticted browser session to access Confluence.
Note
WikiTraccs opens and controls the browser window you use to log in. This is necessary so that WikiTraccs can access cookies. A note about this automation will be shown at the top of the browser window, which is expected: “Chrome is being controlled by automated test software” (for Chrome), or “Microsoft Edge is being controlled by automated test software” (for Edge).The following diagram shows how WikiTraccs uses cookies to make authenticated calls to Confluence:

Kerberos
Kerberos SSO might prevent WikiTraccs from successfully authenticating with Confluence, even when using the correct session cookies.Experimental alternative to obtain cookies (compatible with Kerberos)
When WikiTraccs is unable to make authenticated calls to Confluence and all troubleshooting fails, you might try an experimental option introduced in release 1.10.16.
This changes the flow like this:

All requests to Confluence are routed through the browser, in the context of the authenticated user session.
This mode can be activated in WikiTraccs.GUI via Settings > Misc > Proxy Confluence API calls through browser.
Anonymous Access
If you choose Anonymous authentication mode, WikiTraccs will still open Confluence in the WikiTraccs-controlled browser. You don’t have to log in. The browser will close eventually and WikiTraccs continues, accessing Confluence using an anonymous user session.
13.1.2 - Token-Based Confluence Authentication
Note: token-based authentication is available as of WikiTraccs v1.13 and works with Confluence 7.9 and later, and Confluence Cloud.
Refer to Atlassian’s documentation on how to create a personal access token: Using Personal Access Tokens.
13.2 - Authenticating with SharePoint Online
The following authentication methods are currently supported by WikiTraccs:
- interactive authentication (supports MFA)
- device-code authentication (supports MFA)
- client credentials authentication (no MFA support)
- certificate authentication (app-only, no migration account required)
Each of those authentication methods requires an Entra ID application to exist in Entra ID. WikiTraccs has to know the ID (“client ID”) of this application.
Note
Under the hood WikiTraccs uses the PnP Core library that is also used by PnP PowerShell. Thus concepts regarding authentication are similar. That’s why this documentation will link to PnP documentation at certain points.Tip
Use interactive authentication for starters. It’s the easiest option that gives good interactive feedback if something goes wrong.Prerequisites
When “authenticating with SharePoint Online” you are in fact authenticating with an Entra ID application that must be configured to authorize the access to SharePoint Online. Such an Entra ID application has to either exist or you have to register a new one.
You might have to register a new Entra ID application for use with WikiTraccs. This can be done manually in the Azure Portal or via PnP PowerShell. A sample on how to do this via PnP PowerShell is shown here: Register your own Entra ID App.
Note
This blog post has step-by-step instructions on how to register the app in the Azure Portal: Registering WikiTraccs as app in Entra ID.For the specific permissions to configure on the Entra ID application and the permissions the SharePoint account needs on target sites, see: Required permissions for SharePoint Online.
Ultimately - regardless of the Entra ID application you choose to use - WikiTraccs needs to know the ID of this application, and the application (plus the SharePoint account, under interactive/delegated auth) has to permit a certain amount of access to the target sites where WikiTraccs will migrate Confluence content to.
Interactive authentication
Note
The following assumes you are using WikiTraccs.GUI.Note
In WikiTraccs.GUI there is a Test SharePoint connection button. You can select this button at any time to test if the configuration is right and the authentication succeeds. This also checks that the permission level is sufficient.Interactive authentication allows to sign-in with a user that will be used to access SharePoint Online. The user account needs appropriate permissions on the target SharePoint site - see Required permissions for SharePoint Online for the scenarios and the recommended minimum role.
With interactive authentication multi-factor authentication (MFA) is fully supported.
Choose Interactive as Target: Authentication type.
Enter the Entra ID application ID into the Entra ID Application Client ID input field. (Note: This ID looks like “31359c7f-bd7e-475c-86db-fdb8c937548e”.) The user must be granted access to the Entra ID application that is used to authenticate with.
Also fill the Target SharePoint Site Address and Target Tenant ID fields.
Select the Test SharePoint connection to test connecting. A dialog window will appear to display the result of this test.
Attention
The sign-in experience will be opened in a regular browser window (that might already be open) and not in a new, dedicated window. This is due to cross-platform restrictions that need to be solved. This could cause problems when already being logged in with a user account that is different from the one to be used for WikiTraccs. In this case just copy the URL from the address bar to another browser window where you sign in with the right user.Note
WikiTraccs uses the OAuth 2.0 authorization code flow.Delegated auth with Sites.Selected: not supported
Microsoft added delegated Sites.Selected for Microsoft Graph, but not for the SharePoint REST and CSOM endpoints that WikiTraccs requires. You can use Sites.Selected with Certificate authentication, though, which doesn’t involve interactive user login.Device code authentication
Available.
Client credentials authentication
Available, but often not feasible due to MFA or CA requirements.
Certificate authentication
Certificate authentication is an app-only authentication method: WikiTraccs authenticates as the Entra ID application itself, using a certificate as credential. There is no migration user account, no interactive sign-in, and no browser window.
This is the recommended option for unattended migrations and for environments where creating and maintaining a dedicated migration user account is impractical. It pairs naturally with the Sites.Selected application permission, where an admin grants the app access on each target site individually - but the option is not tied to Sites.Selected and works with broader application permissions as well.
Comparison to interactive authentication
With interactive authentication you sign in as a user, and WikiTraccs inherits the intersection of that user’s permissions and the delegated scopes configured on the Entra ID application. A migration user account is required, with appropriate site permissions (see Required permissions for SharePoint Online).
With certificate authentication there is no user. WikiTraccs authenticates as the app, and SharePoint evaluates the app’s own permissions. No migration account is needed - which is why this mode is the best fit for Sites.Selected.
Prerequisites
- An Entra ID application registered in the target tenant (same as for the other authentication methods - see Registering WikiTraccs as App in Entra ID).
- A certificate whose public key has been uploaded to the app registration (Certificates & secrets → Certificates → Upload certificate). The matching
.pfx(private key) stays on the machine that runs WikiTraccs. - Application permissions configured and admin-consented on the app registration, plus a per-target-site grant if Sites.Selected is used. See Required permissions for SharePoint Online for the full permission matrix, and Configuring Sites.Selected Authentication for WikiTraccs for the end-to-end walkthrough.
Note
Certificate authentication is app-only and therefore bypasses MFA and Conditional Access policies that target user sign-in. Make sure the certificate private key is stored securely on the migration machine.Configuration in WikiTraccs
Choose Cert as the SharePoint authentication type.
Fill the Tenant ID and Entra ID Application Client ID fields at the top of the screen the same way you would for the other auth modes.
In the Certificate field, enter either:
- the absolute or relative path to the
.pfxfile (the path is resolved against the working directory and normalized to absolute when saved), or - the SHA-1 thumbprint of a certificate that has been imported into the Windows certificate store (
CurrentUser\MyorLocalMachine\My)
WikiTraccs auto-detects which form you entered: a 40-character hex string (optionally with spaces or colons) is treated as a thumbprint, anything else as a file path. The Verify button next to the input field checks the certificate on demand - it loads the cert the exact same way the migration will later, and prompts for a PFX password if the file is password-protected. A successful verify shows the certificate’s subject and expiration date.
If the certificate file is password-protected, WikiTraccs prompts for the password the first time it needs it (either via the Verify button or at migration start). The entered password is stored in the configuration file alongside the certificate path, consistent with how WikiTraccs stores other secrets. Subsequent runs reuse the stored password without prompting.
At migration start, WikiTraccs performs a hard certificate check before any network call: the certificate is loaded, the password is validated, and on failure the migration aborts cleanly with a clear error message. This avoids half-started migrations caused by a misconfigured or expired certificate.
See the dedicated blog post for an end-to-end walkthrough of the Sites.Selected configuration and how to run WikiTraccs under certificate authentication: Configuring Sites.Selected Authentication for WikiTraccs.
13.2.1 - Required permissions for SharePoint Online
WikiTraccs requires two distinct permission surfaces to be configured for a Confluence to SharePoint Online migration:
- SharePoint account permissions - the role held by the migration user on each target site (applies to interactive, credentials, and device-login authentication), or the role held by the application on each target site (applies to app-only certificate authentication with
Sites.Selected). - Entra ID application permissions - the scopes configured on the Entra ID app registration that WikiTraccs authenticates through.
This page documents the supported combinations of the two, their limitations, and the configurations that are insufficient.
Recommendation
When unsure which configuration to choose, select the Recommended default in each section below. These configurations cover the broadest range of migration scenarios and require the least tuning.SharePoint account permissions on target sites
The migration account is expected to hold site-scoped admin-level permissions on each site that participates in the migration. The SharePoint Administrator and Microsoft 365 Global Administrator directory roles are not required.
Note
This section applies when WikiTraccs authenticates as a user (Interactive, Credentials, or Device Login). Under certificate or app-only authentication, the equivalent concept is the per-site permission grant on the Entra ID application - see Entra ID application permissions below.Role model
SharePoint Online distinguishes two roles with “Full Control”:
- Site Owner - holds Full Control on the site. Permits creating lists, libraries, content types, and pages; setting page metadata (Author, Editor, Created, Modified); and managing permissions. When permissions inheritance is broken on a specific item (for example, a page), a Site Owner account retains access to that item only if it is still present in that item’s access control list.
- Site Admin (formerly Site Collection Administrator) - holds all Site Owner capabilities and, in addition, retains access to every item in the site collection regardless of the item-level access control list. A Site Admin account is therefore not locked out of items where permissions inheritance has been broken, even when the account is not listed in the item’s permissions. Site Admin also permits managing search, the recycle bin, and site collection features. Reference: Admin center site permissions reference.
Recommended default: Site Owner
For migration runs performed by a single account, Site Owner on every target site (and on the WikiTraccs site) is sufficient. Full Control covers all operations WikiTraccs performs:
- creating lists, fields, content types, and modern SharePoint pages
- setting page metadata: Author, Editor, Created, Modified
- uploading attachments
- breaking inheritance on individual pages and applying page-level restrictions
The migration account is preserved in the page access control list during the break-inheritance step. The account therefore retains access to each page it migrates.
When Site Admin is required
Site Admin only becomes relevant when Confluence page restrictions are migrated to SharePoint. Without permission migration, WikiTraccs does not break inheritance on pages, and Site Owner is sufficient.
Migrating page restrictions is generally not recommended - the Confluence and SharePoint permission models differ in ways that often make direct migration impractical. See Mapping principals and migrating permissions for the full discussion.
If permission migration is enabled, Site Admin is recommended to circumvent access-related issue, for example when multiple migration accounts are involved, or permission-related issues need to be investigated.
Insufficient account permissions
- Contribute, Edit, or Read. Full Control is required to break inheritance, set system fields, and apply provisioning templates.
- SharePoint Administrator or Microsoft 365 Global Administrator alone. Tenant-level roles are not a reliable substitute for per-site access; some per-site operations still require the account to hold at least Read on the site. When in doubt, grant Site Owner or Site Admin explicitly.
Entra ID application permissions
Each authentication mode requires an Entra ID application that WikiTraccs authenticates through. The permissions configured on the application determine which API scopes WikiTraccs can request.
Recommended default for interactive, credentials, and device-login authentication: FullControl delegated
- Microsoft Graph > Sites.FullControl.All (delegated) - requires admin consent
- SharePoint > AllSites.FullControl (delegated) - requires admin consent
Under delegated authentication, WikiTraccs receives the intersection of the signed-in user’s permissions and these scopes. The user account must additionally hold Site Owner or Site Admin on the target sites (see SharePoint account permissions).
Intermediate configuration: Manage delegated
If an administrator is unable to consent FullControl scopes in the target tenant:
- Microsoft Graph > Sites.Manage.All (delegated) - no admin consent required
- SharePoint > AllSites.Manage (delegated) - no admin consent required
Migrations continue to succeed with this configuration, at the cost of reduced capability:
- Page permissions cannot be configured. WikiTraccs cannot break inheritance or apply page restrictions under
Managescopes. - Author, Editor, Created, and Modified cannot be set. Setting these system fields falls under the same permission category as managing permissions.
This configuration is appropriate in tenants where admin consent for FullControl is not available.
Recommended default for certificate and app-only authentication: Sites.Selected application with per-site FullControl
- Microsoft Graph > Sites.Selected (application) - requires admin consent
- SharePoint > Sites.Selected (application) - requires admin consent
On the app registration’s API permissions page, both Sites.Selected entries (the Microsoft Graph one and the SharePoint one) must display the “Granted for [Tenant]” status with the green checkmark. Adding the permission rows alone is not sufficient; admin consent must be granted explicitly.
In addition, the application must be granted FullControl on every target site and on the WikiTraccs site via Microsoft Graph. The roles Read, Write, and Manage are also available, but WikiTraccs requires FullControl for the same reasons interactive authentication requires Site Owner.
For the end-to-end configuration procedure, see Configuring Sites.Selected Authentication for WikiTraccs.
Intermediate configuration for certificate authentication: broader FullControl application permissions
If per-site scoping is not a requirement in the target environment:
- Microsoft Graph > Sites.FullControl.All (application) - requires admin consent
- SharePoint > Sites.FullControl.All (application) - requires admin consent
The application receives tenant-wide Full Control. Configuration is simpler because no per-site grants are needed, at the cost of tenant-wide SharePoint access that defeats the point of choosing app-only authentication for isolation. This configuration is listed for completeness; Sites.Selected is the recommended default.
Quick reference
| Scenario | Minimum account permission | Entra application permission | Notes |
|---|---|---|---|
| Regular migration runs, single account | Site Owner | Sites.FullControl.All + AllSites.FullControl (delegated) | Simplest configuration. |
| Regular migration runs, tenant does not grant admin consent for FullControl | Site Owner | Sites.Manage.All + AllSites.Manage (delegated) | Page permissions and system-field metadata not set. |
| Ongoing administrative access to restricted pages required | Site Admin | Sites.FullControl.All + AllSites.FullControl (delegated) | Required when additional administrators must reach pages restricted by WikiTraccs. |
| Periodic rotation of migration accounts | Site Admin, or certificate authentication | delegated FullControl, or Sites.Selected (application) | Site Admin for user-based authentication; certificate authentication removes the concern. |
| Unattended or automated runs | Not applicable (application-based) | Sites.Selected (application) with per-site FullControl grant, or Sites.FullControl.All (application) | No user account required. Choose the application permission based on security posture: Sites.Selected for per-site scoping, Sites.FullControl.All if tenant-wide access is acceptable. |
| Locked-down tenant where tenant-wide application permissions are not permitted | Not applicable (application-based) | Sites.Selected (application) with per-site FullControl grant | Access is granted per site individually. Sites.FullControl.All is not an option because it requires tenant-wide admin consent. |
Related
- Authenticating with SharePoint Online - reference for the supported authentication modes (Interactive, Device Login, Credentials, Certificate)
- Registering WikiTraccs as App in Entra ID - step-by-step application registration procedure
- Configuring Sites.Selected Authentication for WikiTraccs - end-to-end Sites.Selected configuration, including Microsoft Graph Explorer
- Run an Automated Confluence to SharePoint Migration - unattended migration with certificate authentication
- WikiTraccs FAQ - access levels
13.3 - Proxy Authentication
Note
This article is only relevant if you are running WikiTraccs behind a proxy and the proxy requires authentication.Note: Proxy authentication is available as of WikiTraccs v1.31.10.
You’ll see that your proxy requires authentication when you see an error like this when running the Confluence connection check:

HTTP Status code 407 translates to Proxy Authentication Required
Configuring Proxy Authentication
WikiTraccs allows you to configure proxy authentication.
In the main menu of the blue WikiTraccs window, click Settings ⇒ Configure Transformation to open the Settings dialog.
In the Settings dialog, click the Proxy tab.
Choose the proxy authentication option that is right for your proxy:
- None: No authentication required
- Default credentials: Authenticates using your current Windows login
- Credentials: Set user name and password, as well as an optional domain
- note: the password is stored in cleartext in the appsettings.json file
Restart WikiTraccs after changing those settings.
14 - Migration Waves
You can assign waves to your content selectors in the Space Inventory.
When starting a migration, you can optionally specify the waves to migrate.
Note
Migration wave configuration is optional. When using WikiTraccs.GUI, leave the Waves & filters text box empty to tell WikiTraccs to not care about waves.Tip
The same field also supports filters for spaces and content IDs (note: starting with WikiTraccs v1.33.0). If you want to combine wave selection with ad-hoc filters, have a look at Include/Exclude Filters.What are waves?
In the context of WikiTraccs, waves are labels that you assign to selectors in the Space Inventory.
Those labels can be:
- numbers such as
1,2, or100 - names such as
pilot,review, orarchive
When starting a migration you can tell WikiTraccs which of those waves it should migrate.
Using waves you can prepare a multi-wave migration where each wave is assigned the same label.
Let’s look at an example:
Wave 1: Project Teams and Miscellaneous
- Space “Project Alpha” should be migrated to site “/sites/ProjectAlpha”
- Space “Project Beta” should be migrated to site “/sites/ProjectBeta”
- Space “Miscellaneous” should be migrated to site “/sites/Miscellaneous”
Wave 2: Client-Facing and Support Departments
- Space “Marketing” should be migrated to site “/sites/Marketing”
- Space “Sales” should be migrated to site “/sites/Sales”
- Space “Customer Service” should be migrated to site “/sites/CustomerService”
Wave 3: Core Operational Departments
- Space “HR” should be migrated to site “/sites/HR”
- Space “Finance” should be migrated to site “/sites/Finance”
- Space “IT” should be migrated to site “/sites/IT”
How to configure waves?
When configuring what to migrate in the Space Inventory, you use the WT_Setting_Waves column to assign a wave it belongs to.
Here’s what the Space Inventory list might look like:
| WT_In_CfSpaceName | WT_In_CfSpaceKey | Wt_Setting_RequestTransformation | WT_Setting_Waves | WT_Setting_TargetSiteRootUrl |
|---|---|---|---|---|
| Project Alpha | PALPHA | x | 1 | https://contoso.sharepoint.com/sites/ProjectAlpha |
| Project Beta | PBETA | x | 1 | https://contoso.sharepoint.com/sites/ProjectBeta |
| Miscellaneous | MISC | x | 1 | https://contoso.sharepoint.com/sites/Miscellaneous |
| Marketing | MRKT | x | 2 | https://contoso.sharepoint.com/sites/Marketing |
| Sales | SALES | x | 2 | https://contoso.sharepoint.com/sites/Sales |
| Customer Service | SERVICE | x | 2 | https://contoso.sharepoint.com/sites/CustomerService |
| HR | HR | x | 3 | https://contoso.sharepoint.com/sites/HR |
| Finance | FIN | x | 3 | https://contoso.sharepoint.com/sites/Finance |
| IT | IT | x | 3 | https://contoso.sharepoint.com/sites/IT |
Note: Other columns have been omitted for brevity.
With this configuration everything is prepared for a 3-wave migration.
What's a wave number?
Wave numbers are supposed to be:
- whole numbers
- equal to or larger than 1
Wave numbers don’t have to be consecutive. For example using 100, 200, and 300 (instead of 1, 2, and 3) is fine.
What's a wave name?
Wave names are also supported (note: starting with WikiTraccs v1.33.0).
Wave names are not case-sensitive. For example, pilot, Pilot, and PILOT all refer to the same wave.
Wave names:
- must not contain spaces
- must not contain commas
- must not contain hyphens
- must not contain
* - must not contain
: - must not contain
; - must not contain
# - must not contain
+
Examples: pilot, review, archive2026
How to choose waves to migrate?
In WikiTraccs.GUI you can enter wave clauses into the Waves & filters text box right above the Start transformation button:
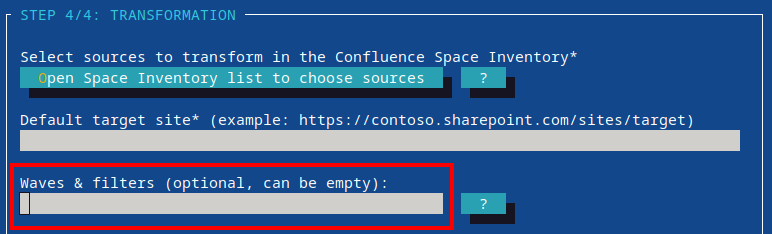
Note
Selecting waves is optional. Leave the Waves & filters text box empty to migrate all selectors that have a check mark set in the Wt_Setting_RequestTransformation column of the Space Inventory.Tip
The same input field also supports filter clauses (note: starting with WikiTraccs v1.33.0). Use those when you want to include or exclude specific spaces or content IDs in addition to the selected waves. For details and examples, see Include/Exclude Filters.You can choose multiple waves to migrate.
Use commas, spaces, or a mix of both to separate wave clauses (note: only commas are supported prior to WikiTraccs v1.33.0).
Here are supported ways of selecting waves:
| Wave selection example | Description |
|---|---|
| 1 | Migrate wave 1 |
| 1 2 3 | Migrate waves 1, 2, and 3 |
| 1,2,3 | Migrate waves 1, 2, and 3 |
| 1-3 | Migrate waves 1, 2, and 3 |
| 1,4-6,8 | Migrate waves 1, 4, 5, 6, and 8 |
| pilot | Migrate the named wave pilot |
| pilot review | Migrate the named waves pilot and review |
| pilot, 2, review | Migrate the named waves pilot and review and wave 2 |
| -4 | Migrate all waves up to and including 4 |
| 4- | Migrate all waves equal to or greater than 4 |
| 1,4- | Migrate wave 1 and all waves equal to or greater than 4 |
| * | Migrate all selectors with wave configuration, but skip selectors with empty WT_Setting_Waves column |
| Migrate all selectors with checked Wt_Setting_RequestTransformation column |
Tip
Above syntax is also valid in the WT_Setting_Waves column. This can be useful to include selectors in multiple migration waves.Note
For a Space Inventory entry to be considered at all for migration, the Wt_Setting_RequestTransformation field has to be checked. This is a requirement independent of any wave configuration.Use cases for waves
Waves are used to partition the migration into different chunks.
Those chunks can then be
- migrated one after another
- migrated in parallel by multiple WikiTraccs instances
Have a look at the How to run parallel WikiTraccs migrations blog post about the latter use case.
14.1 - Include/Exclude Filters
The Waves & filters field in WikiTraccs.GUI supports both wave clauses and filter clauses.
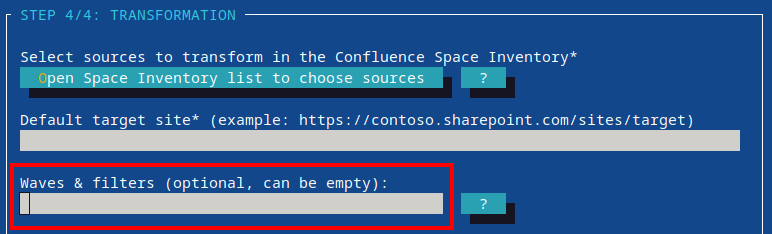
Use waves to mark selectors from the Space Inventory for the next migration run.
Use filters to include or exclude specific spaces or content items on-the-fly, without having to modify any selectors. This is great for testing and iterating quickly on specific pages.
Note
If you have not read about the general wave syntax yet, start with Migration Waves.How filters work together with waves
Waves and filters are evaluated together, but they have different jobs:
- Waves choose selectors from the Space Inventory you want to run.
- Filters include or exclude specific spaces or content IDs, on-the-fly, withoug having to modify selectors in the Space Inventory.
The following example selects the pilot and review waves for migration, as well as the HR space, while excluding the page with ID 12345 from the migration run.
pilot review +space.key:HR -id:12345
Supported filter clauses
The following filter clauses are supported:
| Clause | Meaning | Example |
|---|---|---|
+id: | Include one content ID | +id:12345 |
-id: | Exclude one content ID | -id:12345 |
+ids: | Include multiple content IDs | +ids:12345,67890 |
-ids: | Exclude multiple content IDs | -ids:12345,67890 |
+id!: | Force one content ID to be enqueued; this will force-overwrite the SharePoint page | +id!:12345 |
+ids!: | Force multiple content IDs to be enqueued; this will force-overwrite the SharePoint pages | +ids!:12345,67890 |
+space.key: | Include one space by space key | +space.key:HR |
-space.key: | Exclude one space by space key | -space.key:ARCHIVE |
+space.keys: | Include multiple spaces by space key | +space.keys:HR,FIN,IT |
-space.keys: | Exclude multiple spaces by space key | -space.keys:ARCHIVE,LEGACY |
+space.id: | Include one space by space ID | +space.id:123456 |
-space.id: | Exclude one space by space ID | -space.id:123456 |
+space.ids: | Include multiple spaces by space ID | +space.ids:123,456,789 |
-space.ids: | Exclude multiple spaces by space ID | -space.ids:123,456,789 |
The +id! and +ids! filter variants force existing (previously migrated) SharePoint pages to be overwritten.
The +id and +ids filter variants (without !) behave “normally”:
- if the page already exists in SharePoint and did not change in Confluence, the page is skipped in the migration run
- if the page already exists in SharePoint and did change in Confluence, the page is either skipped, or overwritten, depending on the Update outdated SharePoint pages setting
Content IDs and content types
Content ID filters can optionally include a content type.
Example:
+id:12345;#blogpost
Use this in Confluence Cloud to explicitly address non-page content types like blog posts.
Examples
Migrate one named wave, but exclude one space:
pilot -space.key:ARCHIVE
Migrate two waves and include one specific content item:
1 2 +id:12345
Migrate one wave and include several specific pages:
pilot +ids:12345,67890,77777
Migrate one wave and force one specific page to be overwritten in SharePoint:
pilot +id!:12345
Migrate one wave and explicitly include several spaces:
pilot +space.keys:HR,FIN,IT
Order matters
When multiple filter clauses could match the same item, the first matching filter clause wins.
Because of that, put the more specific filter first.
Example:
pilot +id:12345 -space.key:ARCHIVE
In this example, content ID 12345 stays included even if it belongs to space ARCHIVE, because the specific include clause comes before the broader exclude clause.
If you reverse the order, the exclude clause wins:
pilot -space.key:ARCHIVE +id:12345
Separators
You can separate clauses with spaces, commas, or a mix of both.
Examples:
pilot review +space.key:HR
pilot,review,+space.key:HR
pilot, review +space.key:HR
Inside grouped filter clauses such as +ids: or +space.keys:, the individual values are separated with commas.
Typical usage patterns
- run a wave and add a few specific pages:
pilot +ids:12345,67890 - run a wave and force specific pages to be overwritten:
pilot +id!:12345 - re-migrate a single page:
dummywave +id!:12345(dummywavedoesn’t exist)
For the general wave syntax and examples like wave ranges or wildcards, see Migration Waves.
15 - Page Refinement
Note: Page Refinement is available as of WikiTraccs v1.28.0
What is Page Refinement?
Page refinements are changes to already migrated pages in SharePoint Online.
In Page Refinement Mode, WikiTraccs will analyze and optionally modify migrated pages.
Currently supported refinement actions are:
- check SharePoint pages for broken links and log those
- fix broken links if the correct target page for a link can be found; this also logs all links and the modification result
- change SharePoint page links to open in the same browser tab instead of in a new tab
How to Activate Page Refinement Mode?
Page Refinement Mode can be activated in the WikiTraccs settings:
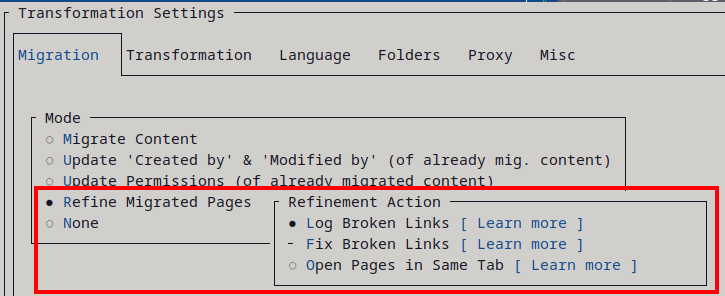
Page Refinement Actions
Refer to any of the child articles for more details:
15.1 - Page Refinement - Log Broken Links
Note: Page Refinement is available as of WikiTraccs v1.28.0
Getting Started Quickly
Here’s how to enable and start the check for broken links:
- Enable Page Refinement mode:
- in the menu bar of WikiTraccs.GUI, click Settings ⇒ Configure Transformation to open the settings dialog
- as Mode select Refine Migrated Pages
- check only the Log Broken Links action

- click Ok to save the settings and close the settings dialog
- Choose selectors in the Space Inventory list, just as you would before starting an actual migration
- Click Start Transformation to start
Note that WikiTraccs highlights the chosen mode (so you can be sure it’s the right one), here Refine - Log Links:
Prerequisites for Logging Broken Links
You need migrated pages. If you did not migrate pages, yet, searching for broken links doesn’t make sense.
Granularity of the Check
WikiTraccs checks SharePoint sites. Within each site, only the pages that WikiTraccs migrated from the currently configured source Confluence are checked - that is, pages whose source-tenant marker matches the Confluence base URL set in your WikiTraccs source configuration. Pages from a different source (migrated from another Confluence instance, or pages that WikiTraccs didn’t migrate at all) are skipped.
Within that scope, the configured migration wave name and include/exclude filters gate refinement the same way they gate migration.
How to Select Sites to Check
Just as when migrating content, you’ll use the Space Inventory list to tell WikiTraccs which sites to check.
In the Space Inventory, WikiTraccs looks for selectors that are marked for transformation (those have a check mark set in the WT_Setting_RequestTransformation column).
For all selectors marked for transformation, WikiTraccs collects the target sites. That’s the value you entered in the WT_Setting_TargetSiteRootUrl column (hopefully before migrating content).
Those are the sites that WikiTraccs will check.
Where to Find the Link Report
WikiTraccs stores the link report in its WikiTraccs.GUI\logs folder.
You can use the Open Log Folder button to open the folder:
The link report file name looks like 2025-06-20-123335 localhost:8090___wt-link-report-v1-[log].txt:
The file name will look different for you, as the date and time of the migration run, as well as the Confluence base address are part of it.
One link report file per day will be created. If you start the check for broken links multiple times per day, WikiTraccs will continue to add to this file. Already checked pages won’t be checked again.
You can delete this file to start over.
The file content looks like this (note: sample for three broken links and no fix possible):
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-WikiTraccs---Confluence-to-SharePoint-Migration-Tool-35848209.aspx 12 1.0 /sites/Default/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx ? ContentSnapshotNotFound,SharePointSearchNoHit
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Metadata-for-the-WikiPakk-Page-Tree-35848235.aspx 14 1.0 /sites/Default/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx ? ContentSnapshotNotFound,SharePointSearchNoHit
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Metadata-for-the-WikiPakk-Page-Tree-35848235.aspx 14 1.0 /sites/Default/SitePages/TREE-Scripting-the-Page-Hierarchy-35848233.aspx ? ContentSnapshotNotFound,SharePointSearchNoHit
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool 14 Site Processing Checkpoint (UTC 2025-06-20 12:33:50, 4 pages checked in this run) wt-checkpoint 638860196303631858
The file content could also look like this (note: sample for three broken links and three fix candidates found):
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-WikiTraccs---Confluence-to-SharePoint-Migration-Tool-35848209.aspx 12 1.0 /sites/Default/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx /sites/WikiPakkPageTree/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx ContentSnapshotFoundWithDifferentLink
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Metadata-for-the-WikiPakk-Page-Tree-35848235.aspx 14 1.0 /sites/Default/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx /sites/WikiPakkPageTree/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx ContentSnapshotFoundWithDifferentLink
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Metadata-for-the-WikiPakk-Page-Tree-35848235.aspx 14 1.0 /sites/Default/SitePages/TREE-Scripting-the-Page-Hierarchy-35848233.aspx /sites/WikiPakkPageTree/SitePages/TREE-Scripting-the-Page-Hierarchy-35848233.aspx ContentSnapshotFoundWithDifferentLink
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool 14 Site Processing Checkpoint (UTC 2025-06-20 12:55:40, 4 pages checked in this run) wt-checkpoint 638860209402343386
https://contoso.sharepoint.com/sites/WikiPakkPageTree 4 Site Processing Checkpoint (UTC 2025-06-20 12:55:40, 2 pages checked in this run) wt-checkpoint 638860209406942630
Each line contains multiple values separated by the tab character. Those values are:
- Page URL - the SharePoint page that WikiTraccs checked
- example:
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-WikiTraccs---Confluence-to-SharePoint-Migration-Tool-35848209.aspx
- example:
- Page Item ID - the SharePoint list item ID in the Site Pages library
- example:
12
- example:
- Page Version - the page version
- example:
1.0
- example:
- Link - link that couldn’t be verified (note: verified links are not logged)
- example:
/sites/Default/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx
- example:
- New Link - if WikiTraccs found the page in another site, this is the link; or
?if no link target could be found- example:
/sites/WikiPakkPageTree/SitePages/TREE-WikiPakk---SharePoint-Page-Tree-35848215.aspx
- example:
- Result - the verification result, indicating where WikiTraccs checked and how it went
- example:
ContentSnapshotNotFound,SharePointSearchNoHit - example:
ContentSnapshotFoundWithDifferentLink
- example:
Lines with the keyword wt-checkpoint are checkpoints set by WikiTraccs so it knows where to continue, should a tranformation run be interrupted and restarted.
How does WikiTraccs Identify Broken Links?
WikiTraccs extracts the space key and page ID from links. This is possible since links to migrated SharePoint pages follow the naming scheme SPACEKEY-some-title-PAGEID.aspx.
Having the space key and the page ID, WikiTraccs looks up the page in the Confluence Content Snapshots list (in the WikiTraccs site). For every page that WikiTraccs migrates, the target URL of the migrated page is stored there as well.
If WikiTraccs doesn’t find an entry in the Confluence Content Snapshots list, it will try to find the target page via SharePoint Search.
When WikiTraccs finds an “authoritative” URL using any of the methods above, it will compare this URL with the link it found in the page. WikiTraccs detects if the authoritative URL points to a different site than the link that is currently in the page.
If the authoritative URL and the link in the page differ, or the link couldn’t be verified at all, then this will be added to the link report file.
Limitations
The following limitations apply:
- performance is not at its peak, yet
- links in text web parts are checked; links in other web parts (for example image web part) are not handled
- handling of page links only; no @-mentions (yet)
- WikiTraccs only handles links to pages that follow its naming scheme:
SPACEKEY-some-title-PAGEID.aspx
For details, refer to issue [WikiTraccs] [Feature] Find and fix broken links #152.
15.2 - Page Refinement - Fix Broken Links
Note: Fixing Broken Links is available as of WikiTraccs v1.28.8.
Getting Started Quickly
Here’s how to enable and start fixing broken links:
- Enable Page Refinement mode:
- in the menu bar of WikiTraccs.GUI, click Settings ⇒ Configure Transformation to open the settings dialog
- as Mode select Refine Migrated Pages
- check the Fix Broken Links action

- click Ok to save the settings and close the settings dialog
- Choose selectors in the Space Inventory list, just as you would before starting an actual migration
- Click Start Transformation to start
Note that WikiTraccs highlights the chosen mode (so you can be sure it’s the right one), here Refine - Fix Links (since “Fix” implies logging, the label omits “Log Links”):
Further Reading
Please refer to the Log Broken Links page about the following topics, as they also apply to fixing links:
- Prerequisites
- Granularity
- How to Select Sites
- Where to Find the Link Report
- How does WikiTraccs Identify Broken Links
- Limitations
Tutorial Video
This 18-minute video shows where broken links come from and how to fix them.
The video shows two migration waves, the first of which creates broken links, and the configuration involved. Then it shows how to run the link fixer to fix those links.
How to See Which Links Where Fixed
The link report file (see Where to Find the Link Report for details about that) for the fix action contains additional status values:
ResultSkippedLink- link could not be fixed (either because the page was not found in SharePoint, or because multiple pages were found)ResultSuccessReplacedSomething- link was replaced by new (working) link
Also, the new page version is logged. Note that each changed web part increases the major page version by one, so, updating three text web parts on a page will increase the major page version by three.
15.3 - Page Refinement - Log User Mentions
Note: Logging User Mentions is available as of WikiTraccs v1.33.28
Getting Started Quickly
Here’s how to enable and start the check for user mentions:
- Enable Page Refinement mode:
- in the menu bar of WikiTraccs.GUI, click Settings ⇒ Configure Transformation to open the settings dialog
- as Mode select Refine Migrated Pages
- check only the Log User Mentions action

- click Ok to save the settings and close the settings dialog
- Choose selectors in the Space Inventory list, just as you would before starting an actual migration
- Click Start Transformation to start
Note that WikiTraccs highlights the chosen mode (so you can be sure it’s the right one), here Refine - Log Mentions:
Prerequisites for Logging User Mentions
You need migrated pages. If you did not migrate pages, yet, checking user mentions doesn’t make sense.
The log action reports on two things at once: user mentions that are already correct (validated no-change) and user mentions that would benefit from a rewrite because a mapping was added, changed, or is missing. The most typical trigger is a change to the WikiTraccs User Mappings list (in the WikiTraccs site) after the initial migration - new mapping rows make previously-unmapped mentions resolvable, and edited rows shift existing mentions to a different target. The log run surfaces both cases so you can decide whether to follow up with the fix action.
You don’t need a fully populated mappings list for the log to be useful. If a mapping is missing, the report records the mention as MentionMappingMissing, which is itself an actionable result - it tells you which source users need a mapping row added before fixing can take effect.
Granularity of the Check
WikiTraccs checks SharePoint sites. Within each site, only the pages that WikiTraccs migrated from the currently configured source Confluence are checked - that is, pages whose source-tenant marker matches the Confluence base URL set in your WikiTraccs source configuration. Pages from a different source (migrated from another Confluence instance, or pages that WikiTraccs didn’t migrate at all) are skipped.
Within that scope, the configured migration wave name and include/exclude filters gate refinement the same way they gate migration.
How to Select Sites to Check
Just as when migrating content, you’ll use the Space Inventory list to tell WikiTraccs which sites to check.
In the Space Inventory, WikiTraccs looks for selectors that are marked for transformation (those have a check mark set in the WT_Setting_RequestTransformation column).
For all selectors marked for transformation, WikiTraccs collects the target sites. That’s the value you entered in the WT_Setting_TargetSiteRootUrl column (hopefully before migrating content).
Those are the sites that WikiTraccs will check.
Where to Find the Mention Report
WikiTraccs stores the mention report in its WikiTraccs.GUI\logs folder.
You can use the Open Log Folder button to open the folder:
The mention report file name looks like 2025-06-20-123335 localhost:8090___wt-mention-report-v1-[log].txt.
The file name will look different for you, as the date and time of the refinement run, as well as the Confluence base address are part of it.
One mention report file per day will be created. If you start the check for user mentions multiple times per day, WikiTraccs will continue to add to this file. Already checked pages won’t be checked again.
You can delete this file to start over.
The mention report is its own file, separate from the broken-links report. Both files can exist side by side when both refinement actions are enabled.
The file content looks like this (note: header row plus sample data rows for three mentions):
SourcePage ItemId Version OldLink NewLink State VersionAfterUpdate MentionSourceMri MentionResolutionMode MentionRegistryResolution MentionMatchedMappingCount MentionTargetUpn MentionTargetDisplayName MentionSourceDisplayName
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Welcome-35848209.aspx 12 1.0 /_layouts/15/sharepoint.aspx?q=heu%40old.com&v=%2Fsearch%2Fpeople&wtmri=user:name:atlassian:|onprem|heu&wtmdn=Heinrich&wtmsn=Heinrich Ulbricht /_layouts/15/sharepoint.aspx?q=henry%40contoso.com&v=%2Fsearch%2Fpeople&wtmri=user:name:atlassian:|onprem|heu&wtmdn=Henry U&wtmsn=Heinrich Ulbricht MentionUrlUpdated,MentionTextUpdated user:name:atlassian:|onprem|heu Tier1Real CacheHitRich 1 [email protected] Henry U Heinrich Ulbricht
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Welcome-35848209.aspx 12 1.0 /_layouts/15/sharepoint.aspx?q=unknown%40old.com&v=%2Fsearch%2Fpeople&wtmri=user:name:atlassian:|onprem|unknown ? MentionMappingMissing user:name:atlassian:|onprem|unknown Tier1Real CacheMissDummyFallback 0
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool 14 Site Processing Checkpoint (UTC 2025-06-20 12:33:50, 4 pages checked in this run) wt-checkpoint 638860196303631858
Each line contains multiple values separated by the tab character. The first line is a header row documenting the columns; data rows follow the same column layout. The columns are:
- SourcePage - the SharePoint page that WikiTraccs checked
- example:
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Welcome-35848209.aspx
- example:
- ItemId - the SharePoint list item ID in the Site Pages library
- example:
12
- example:
- Version - the page version
- example:
1.0
- example:
- OldLink - the mention link as it currently appears in the page
- example:
/_layouts/15/sharepoint.aspx?q=heu%40old.com&v=%2Fsearch%2Fpeople&wtmri=user:name:atlassian:|onprem|heu&wtmdn=Heinrich
- example:
- NewLink - the mention link WikiTraccs would write (or
?if no target could be resolved)- example:
/_layouts/15/sharepoint.aspx?q=henry%40contoso.com&v=%2Fsearch%2Fpeople&wtmri=user:name:atlassian:|onprem|heu&wtmdn=Henry U&wtmsn=Heinrich Ulbricht
- example:
- State - the classification result, indicating what WikiTraccs decided to do
- example:
MentionUrlUpdated,MentionTextUpdated - example:
MentionMappingMissing - example:
MentionValidatedNoChange
- example:
- VersionAfterUpdate - the SharePoint page version after the refinement run wrote changes (empty for log-only runs)
- MentionSourceMri - the source Confluence user’s identifier that WikiTraccs extracted from the anchor (the
wtmriURL parameter added during migration)- example:
user:name:atlassian:|onprem|heu
- example:
- MentionResolutionMode - which recognition path WikiTraccs used
Tier1Real- the anchor carries a real source-user identifier (the normal case)Tier1Placeholder- the anchor carries a null-placeholder identifier (historical anchor from before user info was captured)Tier1Legacy- the anchor has the source-user identifier but no display-name breadcrumb (from before display names were captured in the URL)Tier2Promoted- the anchor pre-dates the MRI breadcrumb entirely; WikiTraccs recovered the source user via the email heuristicTier2Ambiguous- same as above, but more than one mapping row matched the emailTier2NoMatch- tier-2 candidate, but the email heuristic yielded no mapping row
- MentionRegistryResolution - how WikiTraccs looked up the source user in its local cache
CacheHitRich- user found with full breadcrumbs (best case)CacheHitBare- user found but only with mapping-derived dataCacheMissDummyFallback- user not in the cache; WikiTraccs used a minimal fallbackNotAttempted- placeholder anchors and tier-2 paths don’t hit the cache
- MentionMatchedMappingCount - how many rows in the WikiTraccs User Mappings list matched the source user
0- no match (reported asMentionMappingMissing)1- unique match (the rewrite uses this row)>=2- ambiguous match (reported asMentionMappingAmbiguous; no rewrite)
- MentionTargetUpn - the mapped SharePoint user’s UPN (empty when no mapping was found; a comma-separated list for ambiguous matches)
- example:
[email protected]
- example:
- MentionTargetDisplayName - the display name used for the anchor text (falls back to the UPN when the mapping has no title)
- example:
Henry U
- example:
- MentionSourceDisplayName - the source Confluence user’s display name (audit breadcrumb; the
wtmsnURL parameter)- example:
Heinrich Ulbricht
- example:
Lines with the keyword wt-checkpoint are checkpoints set by WikiTraccs so it knows where to continue, should a refinement run be interrupted and restarted. Checkpoint rows are padded with empty columns to keep the TSV rectangular so external tools (Excel, pandas, Import-Csv) can read the whole file as a uniform table.
How does WikiTraccs Identify User Mentions?
WikiTraccs looks for anchors that point to the SharePoint people search endpoint (/_layouts/15/sharepoint.aspx?v=/search/people). Those anchors are the shape WikiTraccs itself produces for user mentions during migration.
During migration, WikiTraccs adds breadcrumbs to the anchor’s URL so it can later recognize which Confluence user the mention originally pointed to:
wtmri- the source Confluence user’s identifier (present for pages migrated with recent WikiTraccs versions)wtmdn- the display name that ended up in the anchor textwtmsn- the source Confluence display name (for auditing purposes)
Having the wtmri, WikiTraccs reconstructs the source Confluence user and looks up the matching row in the WikiTraccs User Mappings list. That’s the same list you maintain for user-metadata mapping during migration. The mapping row’s WT_Setting_MapForDataAndMentions column provides the mapped SharePoint user.
For pages migrated before the wtmri breadcrumb was added, WikiTraccs falls back to a tier-2 heuristic: it compares the anchor’s q parameter (usually the source user’s email) against the WT_In_EmailAddress column of the mapping list. If exactly one row matches, WikiTraccs promotes it to a tier-1-style mention for rewriting.
When WikiTraccs finds a unique mapping row, it builds the “authoritative” mention URL from the mapped target user and compares it with the link in the page. If the authoritative URL and the link in the page differ, or the mapping couldn’t be resolved at all, then this will be added to the mention report file.
Limitations
The following limitations apply:
- user mentions only (no group mentions)
- mention fixing requires the source Confluence user to be present in the WikiTraccs User Mappings list; unmapped users are reported as
MentionMappingMissing - mentions in text web parts are checked; mentions in other web parts are not handled
- WikiTraccs only recognizes mention anchors that follow its own shape (those it produced during migration)
15.4 - Page Refinement - Fix User Mentions
Note: Fixing User Mentions is available as of WikiTraccs v1.33.28.
Getting Started Quickly
Here’s how to enable and start fixing user mentions:
- Enable Page Refinement mode:
- in the menu bar of WikiTraccs.GUI, click Settings ⇒ Configure Transformation to open the settings dialog
- as Mode select Refine Migrated Pages
- check the Fix User Mentions action

- click Ok to save the settings and close the settings dialog
- Choose selectors in the Space Inventory list, just as you would before starting an actual migration
- Click Start Transformation to start
Note that WikiTraccs highlights the chosen mode (so you can be sure it’s the right one), here Refine - Fix Mentions (since “Fix” implies logging, the label omits “Log Mentions”):
Further Reading
Please refer to the Log User Mentions page about the following topics, as they also apply to fixing user mentions:
- Prerequisites
- Granularity
- How to Select Sites
- Where to Find the Mention Report
- How does WikiTraccs Identify User Mentions
- Limitations
How to See Which Mentions Were Fixed
The mention report file (see Where to Find the Mention Report for details about that) for the fix action contains additional status values in the State column:
MentionUrlUpdated- the anchor’shrefwas rewritten to point at the mapped target userMentionTextUpdated- the visible anchor text was rewritten to show the mapped target display nameMentionValidatedNoChange- the anchor already matches the mapped target; nothing needed to be writtenMentionTextPreservedDueToEdit- the anchor’s visible text had been edited after migration; WikiTraccs did not overwrite itMentionNestedFormattingPreserved- the anchor contains nested formatting (for example<strong>); WikiTraccs only updated thehrefand left the inner markup aloneMentionLegacyUrlOnly- the anchor pre-dates the display-name breadcrumb; only thehrefwas rewritten, the visible text was left as-isMentionLegacyNoWtmriUrlOnly- tier-2 promotion (the anchor had nowtmri); only thehrefwas rewrittenMentionMappingMissing- no mapping row was found for the source user; this anchor was left as-isMentionMappingAmbiguous- more than one mapping row matched; this anchor was left as-is; the ambiguous UPNs are listed in the report for your inspectionMentionPlaceholderSkipped- the anchor carries a null-placeholder source-user identifier; WikiTraccs could not look up a target and left this anchor as-is
Also, the new page version is logged in the VersionAfterUpdate column. Note that each changed web part increases the major page version by one, so, updating mentions in three text web parts on a page will increase the major page version by three.
15.5 - Page Refinement - Open Links in Same Browser Tab
Note: This refinement action is available as of WikiTraccs v1.31.20
When migrating content from Confluence to SharePoint, WikiTraccs converts Confluence links to SharePoint links.
Links between Confluence pages become links between SharePoint pages, after the migration. By default, those page links open in a new browser tab when being clicked by a user.
Use the Open Pages in Same Tab refinement action, to change the page links to open in the same browser tab instead.
Steps
First, migrate pages from Confluence to SharePoint, which will create page links that open in a new tab.
After migrating, as a post processing step, run the Open Pages in Same Tab refinement action which will modify the links to open in the same browser tab instead.
15.6 - Page Refinement - Fix Web Part Drift
Note: Web Part Drift handling is available as of WikiTraccs v1.34.11
Note: This refinement is rolling out in two stages. Log mode is available now, so you can scan your migrated pages and see which web parts would be affected. Fix mode, which writes the corrections back to the page, will follow in a later release. The settings dialog only shows the Fix toggle once that stage ships.
Some migrated pages carry Image or Code Snippet web part properties that can collide with the current SharePoint page editor behavior - rarely visible, but able to cause a web part reset on first edit. This Page Refinement mode finds those pages and, in fix mode, rewrites the property in place.
Why Web Part Drift Happens on Migrated Pages
Migrated pages themselves are frozen - WikiTraccs writes them once and they sit untouched on SharePoint until somebody edits them.
Microsoft’s SharePoint page format, on the other hand, keeps evolving. Over time, SharePoint refines how it interprets certain web part properties, and WikiTraccs itself refines how it sets them during migration. A page that was a perfect fit for the format at migration time may, later on, benefit from an adjustment to align with the current format.
As long as nobody edits a page, the alignment doesn’t matter and the page just works. The difference becomes visible the moment a user opens the page in edit mode, where SharePoint re-evaluates the property values.
Re-migrating just to close that gap is rarely an option. By the time a refinement like this becomes relevant, Confluence has often already been replaced by SharePoint and the source content isn’t available to re-migrate from. What’s needed is a way to change a single web part property in place, on the pages that need it, without re-running migration.
That’s what this refinement mode does. WikiTraccs scans already migrated pages, identifies web parts whose properties match a known drift signature, and either logs them (so you can see what’s affected) or rewrites them (so the page behaves correctly going forward).
What gets Corrected
There is currently one drift correction:
Editor pop-ups on already-configured Image and Code Snippet web parts (report Kind:
AddedFromPersistedData)This only matters when a user opens a migrated page in edit mode. Reading or viewing a migrated page is never affected - the page renders correctly to viewers, and the flag has no influence on what they see. The whole behavior described below happens inside the SharePoint page editor only; if nobody edits the affected pages, the refinement is not needed.
Each Image and Code Snippet web part carries a flag whose role is to tell the page editor “show the setup helper when it’s needed” - the file picker for an image, the empty editor surface for a code snippet. On a migrated page the image has already been chosen and the code snippet has already been filled in, so the helper is not needed.
In practice, the editor usually stays out of the way. But under certain conditions it decides to show the helper anyway, and that can come with a web part reset as a side effect - the chosen image is not displayed anymore, the code snippet content is empty. This has been observed under tight memory conditions and when pages are opened in a specific way (for example scrolling very fast, or jumping straight to the end of the page, while the editor loads). The exact mechanism isn’t fully pinned down, but it looks like a timing-sensitive interaction between a one-shot update script that Microsoft runs over the page on first edit and the editor’s own initialization logic.
If a such a reset has happened on a page, two mitigations are available without needing this refinement at all: Ctrl+Z in the editor undoes the change (the image reappears on Image web parts), and the SharePoint page version history lets you roll the page back to the version before the edit. The refinement here is about preventing the trip in the first place.
This refinement sets the flag to the value that says “this web part doesn’t need the first-run editor, I’m sure”. With the flag set this way, neither the Microsoft update script nor the editor has a reason to act on the web part, regardless of which side of the timing race lands first, and the existing image and code snippet content are left alone. Pages migrated with WikiTraccs v1.33.17 or newer already carry that value and don’t need the refinement.
Two Modes: Log and Fix
This refinement supports the same two modes as the link and mention refinements:
- Log Web Part Drift - scan pages, detect drift, write a report; no page changes
- Fix Web Part Drift - same scan, plus rewrite the affected property and save the page; “Fix” implies “Log”, so the report is always written
Use the log mode first to get a feel for how many pages and web parts would be touched. Switch to fix mode when you are ready to apply the change.
How to Enable Web Part Drift Refinement
Here’s how to enable and start the check:
- Enable Page Refinement mode:
- in the menu bar of WikiTraccs.GUI, click Settings ⇒ Configure Transformation to open the settings dialog
- as Mode select Refine Migrated Pages
- check either Log Web Part Drift (log only) or Fix Web Part Drift (log + rewrite)
- click Ok to save the settings and close the settings dialog
- Choose selectors in the Space Inventory list, just as you would before starting an actual migration
- Click Start Transformation to start
WikiTraccs highlights the chosen mode in the GUI: Refine - Log WP Drift or Refine - Fix WP Drift (since “Fix” implies logging, the label omits “Log WP Drift”).
Prerequisites
You need migrated pages. If you did not migrate pages, yet, checking for web part drift doesn’t make sense.
Which Migrated Pages Get Checked
WikiTraccs checks SharePoint sites. Within each site, only the pages that WikiTraccs migrated from the currently configured source Confluence are checked - that is, pages whose source-tenant marker matches the Confluence base URL set in your WikiTraccs source configuration. Pages from a different source (migrated from another Confluence instance, or pages that WikiTraccs didn’t migrate at all) are skipped.
Within that scope, the configured migration wave name and include/exclude filters gate refinement the same way they gate migration.
How to Select Sites to Check
Just as when migrating content, you’ll use the Space Inventory list to tell WikiTraccs which sites to check.
In the Space Inventory, WikiTraccs looks for selectors that are marked for transformation (those have a check mark set in the WT_Setting_RequestTransformation column).
For all selectors marked for transformation, WikiTraccs collects the target sites. That’s the value you entered in the WT_Setting_TargetSiteRootUrl column (hopefully before migrating content).
Those are the sites that WikiTraccs will check.
Where to Find the Web Part Drift Report
WikiTraccs stores the drift report in its WikiTraccs.GUI\logs folder.
You can use the Open Log Folder button in the GUI to open the folder.
The drift report file name looks like:
2025-06-20-123335 localhost:8090___wt-webpart-property-drift-report-v1-[log].txt(log mode)2025-06-20-123335 localhost:8090___wt-webpart-property-drift-report-v1-[fix].txt(fix mode)
The file name will look different for you, as the date and time of the refinement run, as well as the Confluence base address are part of it.
One drift report file per day and per mode will be created. If you start the check multiple times per day in the same mode, WikiTraccs will continue to add to this file. Already checked pages won’t be checked again.
You can delete this file to start over.
The drift report is its own file, separate from the link and mention reports. All three files can exist side by side when more than one refinement action is enabled.
The file content looks like this (note: sample for two image web parts being adjusted on different pages):
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Welcome-35848209.aspx 12 1.0 Image abc123-... AddedFromPersistedData Set addedFromPersistedData=true on Image web part data-sp-controldata.addedFromPersistedData false true ResultSuccessReplacedSomething 2.0
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Topology-35848211.aspx 14 1.0 CodeSnippet def456-... AddedFromPersistedData Set addedFromPersistedData=true on CodeSnippet web part data-sp-controldata.addedFromPersistedData false true ResultSuccessReplacedSomething 2.0
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool 14 Site Processing Checkpoint (UTC 2025-06-20 12:33:50, 4 pages checked in this run) wt-checkpoint 638860196303631858
Each line contains multiple values separated by the tab character. The columns are:
- SourcePage - the SharePoint page that WikiTraccs checked
- example:
https://contoso.sharepoint.com/sites/WikiTraccsMigrationTool/SitePages/WIKITRACCS-Welcome-35848209.aspx
- example:
- ItemId - the SharePoint list item ID in the Site Pages library
- example:
12
- example:
- Version - the page version before the refinement run
- example:
1.0
- example:
- WebPartType - the human-readable web part type label
- example:
Image,CodeSnippet
- example:
- WebPartId - the web part instance identifier on the page
- example:
abc123-...
- example:
- Kind - the stable identifier of the drift analyzer that produced this row
- example:
AddedFromPersistedData
- example:
- Description - a short human-readable description of the change
- example:
Set addedFromPersistedData=true on Image web part
- example:
- Path - the property location inside the web part
- example:
data-sp-controldata.addedFromPersistedData
- example:
- ValueBefore - the property value as found in the page
- example:
false
- example:
- ValueAfter - the property value WikiTraccs would write (or did write, in fix mode)
- example:
true
- example:
- State - the result classification (a comma-separated list of flags); empty for log-only rows that detected drift without attempting a write
- example:
ResultSuccessReplacedSomething- fix mode, the change was written - example:
ResultErrorWebPartSkippedDueToUnexpectedChange- the web part changed in a way that no longer matches the drift signature; left as-is - example:
ResultErrorSentinelMismatch- a pre-save consistency check detected that saving would have altered web part properties beyond the declared change; the save was skipped and the page left untouched
- example:
- VersionAfterUpdate - the SharePoint page version after the refinement run wrote changes (empty for log-only runs)
- example:
2.0
- example:
Lines with the keyword wt-checkpoint are checkpoints set by WikiTraccs so it knows where to continue, should a refinement run be interrupted and restarted. Checkpoint rows are padded with empty columns to keep the TSV rectangular so external tools (Excel, pandas, Import-Csv) can read the whole file as a uniform table.
How WikiTraccs Identifies Web Part Drift
For each web part on each migrated page, WikiTraccs runs a small set of drift analyzers. Each analyzer knows one specific property on one specific web part type, and decides whether the current value matches the drift signature it cares about.
For the AddedFromPersistedData analyzer:
- it only looks at Image and Code Snippet web parts
- it reads the
addedFromPersistedDataflag from the web part’sdata-sp-controldata - it acts only when the flag’s value is exactly
false; web parts where the flag is alreadytrue, or where the value can’t be read, are skipped
In fix mode, the page version increases when WikiTraccs saves the page.
Limitations
The following limitations apply:
- only the web part properties listed under What gets Corrected are detected and rewritten
- WikiTraccs only handles pages that follow its naming scheme (
SPACEKEY-some-title-PAGEID.aspx) and that use the WikiTraccs content type (Site Page (transformed by WikiTraccs)); other pages on the site are skipped - in fix mode, each rewritten page gets a new page version
16 - Confluence Inventory
Getting information about your source Confluence environment helps estimating migration efforts and durations.
The blog post How much time does it take to migrate? has some information about the relationship between content and the time it takes to migrate.
WikiTraccs has an inventory scan built in that provides detailed insights into your Confluence instance. The inventory scan is integrated with the Migration Duration Estimator and provides input values for the estimation.
Have a look at the child pages for more information.
16.1 - Inventory Scan and Reporting
Note: Inventory Scan and Reporting is available as of WikiTraccs 1.32.29, with some parts having been added in later releases.
WikiTraccs has an inventory scan built in. The inventory scan leverages the same data processing pipeline that is used when migrating content from Confluence to SharePoint. It is much faster though, since attachment downloads are skipped and no SharePoint is present nor required.
Note
WikiTraccs can create some “synthetic” attachments during a real migration when they are switched on in the settings: the native Word export and the historical PDF export (via the Scroll PDF Exporter app). Both run only during a content migration, not during an inventory scan.Overview
Using the inventory run, WikiTraccs gathers extensive information about your Confluence instance, including:
- page count
- attachment count and size, as well as information about unlinked attachments
- macro count
- link counts, including link target and broken link information
- open tasks
- drafts and archived pages
- and much more
Information gathered is presented in different graphs and views, some per site and some per space.
Here’s an example of the space link graph, showing linked spaces:
Again, in clustered fashion:
And overview metrics for the whole site, ready to be drilled in to:
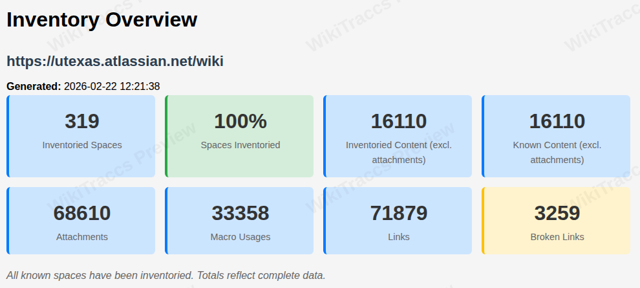
Using this information, you can leverage the Migration Duration Estimator get an estimation of the time if will take to migrate all your Confluence content to SharePoint.
How to Run an Inventory Scan
Follow the steps in Activate and Configure Inventory Mode.
16.1.1 - Activate and Configure Inventory Mode
To put WikiTraccs into inventory mode, click Tools in the WikiTraccs.GUI main menu, then Inventory Mode.

The WikiTraccs user interface will change and look like this:
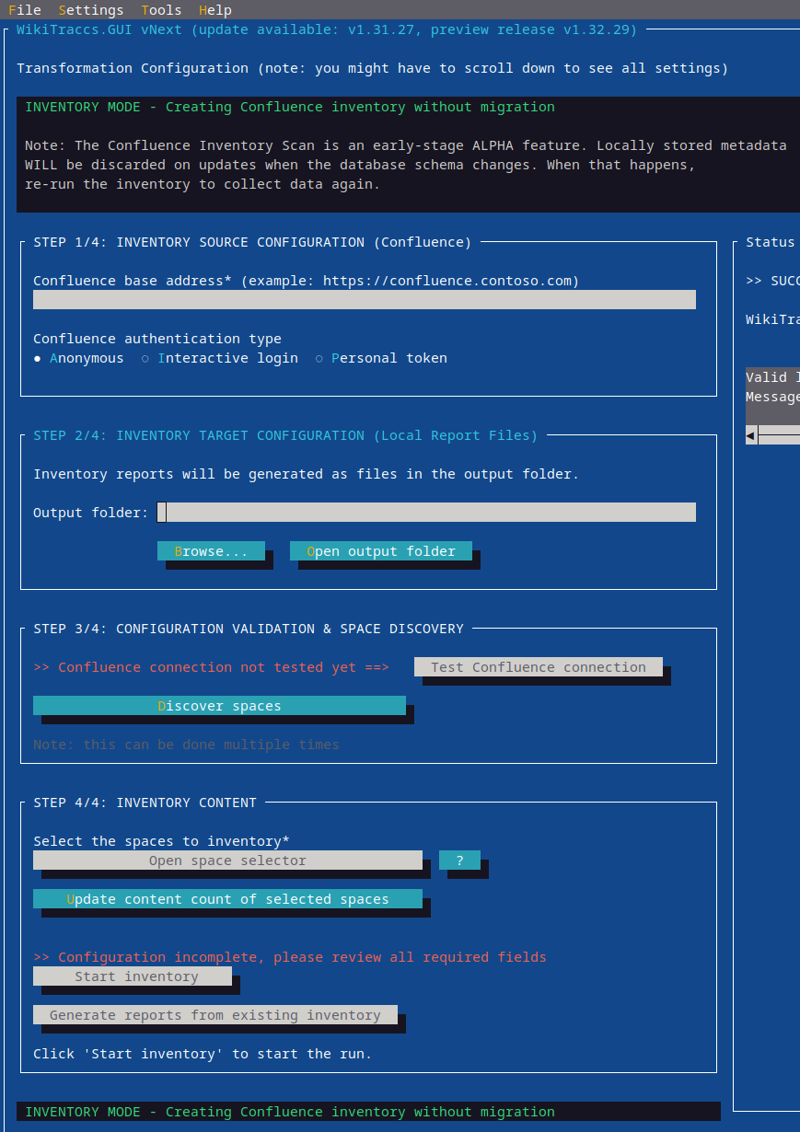
You configure the inventory scan in four steps:
- Step 1: Where is Confluence?
- Step 2: Where to store the reports?
- Step 3: What’s there in Confluence? Validate the Confluence connection and get the list of Confluence spaces.
- Step 4: What to inventory? Select spaces to inventory and start the inventory run.
Step 1: Where is Confluence?
Enter your Confluence base address.
This might look like:
https://wiki.contoso.com(Confluence on-premises)https://contoso.com/confluence(Confluence on-premises, with context path)https://contoso.atlassian.net/wiki(Confluence Cloud, always ends with/wiki)
Choose an appropriate authentication method (read more here: Authenticating with Confluence).
Step 2: Where to store the reports?
Choose a folder to store reports in.
Step 3: What’s there in Confluence?
Click Test Confluence connection to verify that WikiTraccs can communicate with Confluence.
If that worked, click Discover spaces. This gets the list of spaces from Confluence and stores it in a local database. You’ll choose spaces to inventory in the next step.
Step 4: What to inventory?
Click Open space selector to open the space selection dialog. Read more about the space selector here: Select Spaces to Inventory.
After choosing spaces to inventory, click Update content count of selected spaces.
Note
Although not strictly required, the page count update gives you an overview of how many pages WikiTraccs is allowed to see using the selected authentication method.Click Start inventory.
Every time when starting the inventory scan, you can choose how WikiTraccs handles attachments:
Verify attachment downloads will download the first few bytes of every attachment to verify this is working. This can uncover attachment-related errors that only surface when downloading attachment file from Confluence.
Skip attachment download verification will skip over attachments. This is much faster.
Click Generate report from existing inventory to generate a new report, that contains the following:
- if you never ran space discovery, an empty report will be generated
- if you ran space discovery, but never ran a content count update or inventory scan, a report will be generated showing the list of spaces
- if you ran content count update, but no inventory scan, a report will be generated showing the list of spaces and their content count
- if you ran an inventory scan, a report will be generated showing the collected data
- for partial (interrupted) scans, the reports will show incomplete data
Every click generates a new report.
16.1.2 - Select Spaces to Inventory
Use the Space Selector to select spaces to run the inventory scan for, or to update the content count for.
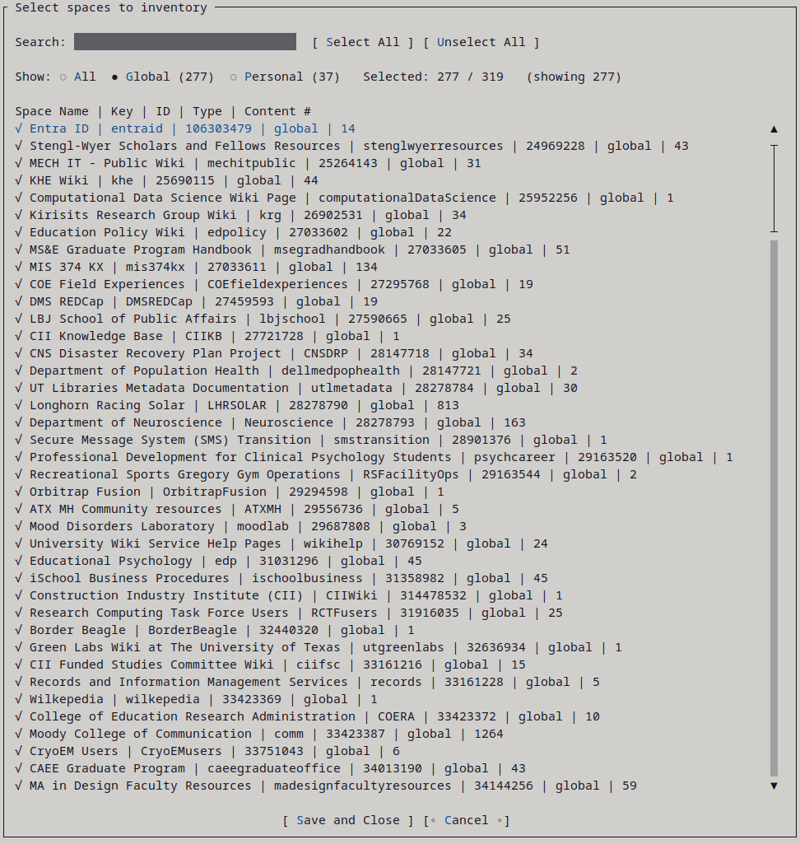
Sample list of spaces from a publicly available Confluence instance.
The dialog shows all spaces that WikiTraccs discovered in Confluence.
For each space the following is shown:
- Space Name
- Space Key
- Space ID
- Space Type
- Content count (excl. attachments), if known
Use the Search box to narrow the list down to spaces matching your search term.
Use the Show All / Global / Personal filter to narrow the space list to those space types.s
Click Select All to select all currently shown spaces. Use Unselect All to unselect all currently shown spaces.
Click Save and Close to confirm and close the dialog.
16.1.3 - Inventory Storage
When running a Confluence inventory scan, WikiTraccs stores data in a local Sqlite database.
The Sqlite database is stored in the non-roaming AppData folder of the current user. Have a look at File Storage on where that is typically found.
Find the wikitraccs-inventory folder, it contains a .db file, e.g. wikitraccs-inventory-store-r3.db. The revision number (“r3”) might change in future releases.
Use and Sqlite browser application to open this file and run your own analysis.
The database schema is subject to changes.
16.1.4 - Report: Inventory Overview
Alpha Feature
Inventory reports are an alpha feature and subject to change. Report data is based on the spaces scanned via inventory scan. Only a complete scan of all spaces guarantees complete insights.The Inventory Overview is the main entry point for all inventory reports. It provides a high-level summary of your entire Confluence instance and links to the detailed per-space reports.
What It Shows
At the top, you will find key metrics across all inventoried spaces:
- Total spaces - how many spaces were scanned
- Total pages - the combined page count
- Attachments - total number of attachments
- Macros - total macro usage count
- Links and broken links - total link counts, including how many are broken
- Flagged pages - pages that may need attention
- Open tasks - total open (incomplete) tasks
- Users and groups - discovered user and group counts
The overview also shows the inventory progress - how many spaces have been fully inventoried versus partially inventoried or not yet scanned.
Space Table
Below the summary, a table lists every inventoried space with per-space metrics such as page count, attachment count, macro count, and link counts. Each space links to its detailed Space Report.
Spaces that have not yet been inventoried are shown separately in a Spaces Pending Inventory section.
Space Link Graph
The overview includes an interactive Space Link Graph that visualizes cross-space links. Each space is shown as a bubble, and arrows between bubbles indicate that pages in one space link to pages in another.
- Blue bubbles represent inventoried spaces.
- Orange bubbles represent spaces that are referenced by links but have not been inventoried.
- Bubble size reflects the number of pages in a space.
- Arrow thickness reflects the number of links between two spaces.
You can toggle a cluster view that groups closely connected spaces together, making it easier to identify space clusters and isolated spaces.
Use this graph to understand how your Confluence spaces are interconnected before planning a migration.
How to Use This Report
The overview helps you:
- Track inventory progress - see at a glance which spaces still need scanning.
- Identify the largest spaces - sort by page or attachment count to find the heaviest spaces.
- Discover space dependencies - use the link graph to find tightly coupled spaces that should be migrated together.
- Drill into details - click any space to open its full space report.
16.1.5 - Report: Space Details
Alpha Feature
Inventory reports are an alpha feature and subject to change. Report data is based on the spaces scanned via inventory scan. Only a complete scan of all spaces guarantees complete insights.The Space Report is generated for each inventoried Confluence space. It provides a detailed breakdown of everything WikiTraccs discovered in that space.
Summary Section
At the top you will find an overview of the space, including:
- Page count - total pages and how many have been inventoried
- Attachment count - total attachments, with a breakdown of successful and failed downloads
- Macro count - number of unique macros used in this space
- Link counts - internal links, external links, and broken links
- Drafts and archived pages - counts for content that was excluded from the main inventory
- Restricted pages - pages with access restrictions
- Workflow pages - pages using Comala or similar workflow plugins
An inventory progress indicator shows whether the space has been fully scanned.
Pages Table
The main table lists every page (and other content types like blog posts or whiteboards) in the space. For each page you can see:
- Title - linking directly to the page in Confluence
- Content type - page, blog post, whiteboard, etc.
- Word count and image count
- Macro count, link count, and broken link count
- Inventory date - when the page was last scanned
- Result - whether the page was processed successfully
The table is sortable and searchable, making it easy to find specific pages or sort by metrics like broken link count.
Macros Section
A dedicated section lists all macros found in the space, along with how many pages use each macro. This helps you understand which Confluence-specific features are in use and may need attention during migration.
Links Section
The links section shows a detailed table of all internal and external links found in the space. You can filter by link state (e.g., broken links only) to quickly find pages with link issues.
Attachments Section
This section provides insight into attachment usage, including:
- Unlinked attachments - files uploaded to a page but not referenced anywhere
- Attachments linked by own page vs. linked by other pages
- A breakdown of failed attachment downloads, if any
Restrictions Section
Lists all page-level access restrictions, showing which users or groups have read or edit restrictions on specific pages.
Integrity Checks
At the bottom of the report, automated integrity checks flag potential issues such as orphaned pages (pages whose parent page is missing).
How to Use This Report
- Prepare for migration - review macros, broken links, and restricted pages before migrating a space.
- Clean up content - identify unlinked attachments, drafts, and archived pages that may not need to be migrated.
- Assess complexity - spaces with many macros, broken links, or workflow pages may require more planning.
16.1.6 - Report: Open Tasks
Alpha Feature
Inventory reports are an alpha feature and subject to change. Report data is based on the spaces scanned via inventory scan. Only a complete scan of all spaces guarantees complete insights.The Open Tasks report gives you a comprehensive view of all incomplete tasks across your inventoried Confluence spaces. It is generated automatically as part of the inventory scan.
What It Shows
The report lists every open (incomplete) task found in your Confluence content. For each task, the following information is provided:
- Task text - the description of the task, linking directly to the task in Confluence
- Assignee - the person the task is assigned to, if any
- Due date - the due date set for the task, if any
- Source page - the Confluence page that contains the task
- Source space - the space the page belongs to, linking to the corresponding space report
Completed tasks are excluded from the report.
How to Use This Report
This report helps you answer questions like:
- Which tasks are still open across my spaces? Get a full picture without having to visit each space individually.
- Are there overdue tasks? Sort or filter by due date to find tasks that need attention.
- Who has open tasks? Identify assignees with outstanding work.
- Are there unassigned tasks? Spot tasks that may have been forgotten or need an owner.
Filtering and Sorting
The report is presented as an interactive table. You can sort by any column and use the search box to filter by task text, assignee, space, or page title.
Where to Find the Report
The Open Tasks report is part of the inventory output. You will find it alongside the Inventory Overview after an inventory scan completes.
It aggregates open tasks across all spaces that were included in the scan. For drill-down, the report links to the corresponding per-space Space Report for each task.
16.1.7 - Report: Link Insights
Alpha Feature
Inventory reports are an alpha feature and subject to change. Report data is based on the spaces scanned via inventory scan. Only a complete scan of all spaces guarantees complete insights.The Link Insights report provides a tenant-wide view of cross-space links - pages in one Confluence space that link to pages in another space.
What It Shows
The report lists every page that contains at least one link to a different space. For each entry you can see:
- Source page - the page containing the link, with a direct link to Confluence
- Source space - the space where the linking page lives
- Target space - the space being linked to
- Link count - how many links from that page point to the target space
Summary metrics at the top show:
- Total cross-space links
- Total source pages - how many pages link across spaces
- Total target spaces - how many spaces are linked to from other spaces
Filtering
The report provides filter controls to narrow the view:
- By target space - select one or more target spaces to see only links pointing there
- By source space - select one or more source spaces to see only links originating there
This makes it easy to answer questions like “Which pages link to Space X?” or “Which other spaces does Space Y depend on?”
How to Use This Report
Cross-space links are an important consideration when planning a Confluence migration:
- Identify space dependencies - if Space A heavily links to Space B, migrating them together (or in the right order) helps preserve link integrity.
- Plan migration batches - group tightly linked spaces into the same migration wave.
- Find unexpected connections - discover spaces that are more interconnected than expected.
This report complements the Space Link Graph in the Inventory Overview, which visualizes the same data as an interactive graph.
16.1.8 - Report: Flagged Pages
Alpha Feature
Inventory reports are an alpha feature and subject to change. Report data is based on the spaces scanned via inventory scan. Only a complete scan of all spaces guarantees complete insights.The Flagged Pages report highlights Confluence pages where the inventory scan detected potential issues. These are pages that may need special attention before or during migration.
What Gets Flagged
A page is flagged when WikiTraccs detects one or more of the following during the inventory scan:
- Failed transformations - parts of the page content could not be fully processed (e.g., an unsupported macro or complex formatting)
- Incomplete text transfer - the text content of the page could not be fully extracted, indicated by a text transfer percentage below 100%
These flags do not necessarily mean the page is broken - they indicate areas where the migration result should be reviewed.
What It Shows
For each flagged page, the report displays:
- Title - linking directly to the page in Confluence
- Content type - page, blog post, etc.
- Space - the space the page belongs to (in the tenant-wide report)
- Failed transformations count - how many transformation issues were detected
- Text transferred percentage - how much of the page text was successfully extracted
- Transformation log - detailed log entries explaining what went wrong, when available
Tenant-Wide and Per-Space Reports
The flagged pages report is available in two forms:
- Tenant-wide - accessible from the Inventory Overview, listing flagged pages across all spaces with a Space column for easy filtering
- Per-space - accessible from each Space Report, listing only flagged pages within that space
How to Use This Report
- Prioritize review - focus on pages with the lowest text transfer percentage or highest transformation failure count first.
- Understand migration risks - a high number of flagged pages in a space may indicate heavy use of complex macros or unusual formatting.
- Plan remediation - decide whether to simplify page content in Confluence before migrating, or handle exceptions after migration.
16.1.9 - Report: Users and Groups
Alpha Feature
Inventory reports are an alpha feature and subject to change. Report data is based on the spaces scanned via inventory scan. Only a complete scan of all spaces guarantees complete insights.The Users and Groups report provides a tenant-wide overview of all Confluence users and groups discovered during the inventory scan.
Users Table
The users table lists every user that WikiTraccs encountered while scanning your Confluence content. For each user, the report shows:
- Display name - the user’s display name in Confluence
- Email - the user’s email address, if available
- Account status - whether the account is active or deactivated
- Account type - the type of Atlassian account (e.g., Atlassian, app, customer)
- Guest flag - whether the user is marked as a guest (Confluence Cloud)
- Source - whether the user was found in a Cloud or on-premises instance
- Discovery references - links to the Confluence pages where this user was encountered (e.g., as page author, mentioned user, or task assignee)
Groups Table
The groups table lists all Confluence groups that were discovered, typically through page restrictions. For each group you can see:
- Group name
- Source - Cloud or on-premises
- Discovery references - links to pages where this group appeared (e.g., in restriction settings)
How to Use This Report
- Plan user mapping - before migrating, identify which Confluence users need to be mapped to Microsoft 365 accounts. Deactivated accounts and guest users may need special handling.
- Review group usage - understand which groups are used in page restrictions, so you can set up corresponding SharePoint groups or permissions.
- Find orphaned accounts - spot deactivated users who are still referenced as page authors or task assignees.
- Assess user volume - get a quick count of how many users and groups exist across your Confluence instance.
The report supports sorting and searching across all columns, making it easy to filter by account status, type, or name.
16.2 - Getting the Confluence page count
The number of pages directly correlates with migration effort and times. This is why it’s a must to determine the number of pages in Confluence in one of the early phases of your Confluence to SharePoint migration project.
There are different approaches to getting the Confluence page count, described in the following sections.
Getting the page count from the database via SQL
Pro:
- returns a guaranteed accurate page count
Contra:
- needs permission to run SQL queries on the Confluence database
- only works with Confluence Server and Confluence Data Center (not Confluence Cloud)
Connect to the Confluence database and run the following SQL query:
select count(*) from content where (contenttype='PAGE' or contenttype='BLOGPOST') and prevver is null and content_status='current';
Note: Depending on the type of database the SQL query syntax might vary.
Atlassian also has some useful snippets here: How to find the number of pages, blogposts, and attachments.
Getting the page count in Confluence Cloud
Via Space Report
Go to Confluence Cloud administration. In the left menu, click the Space Reports option. Create a report and download it.
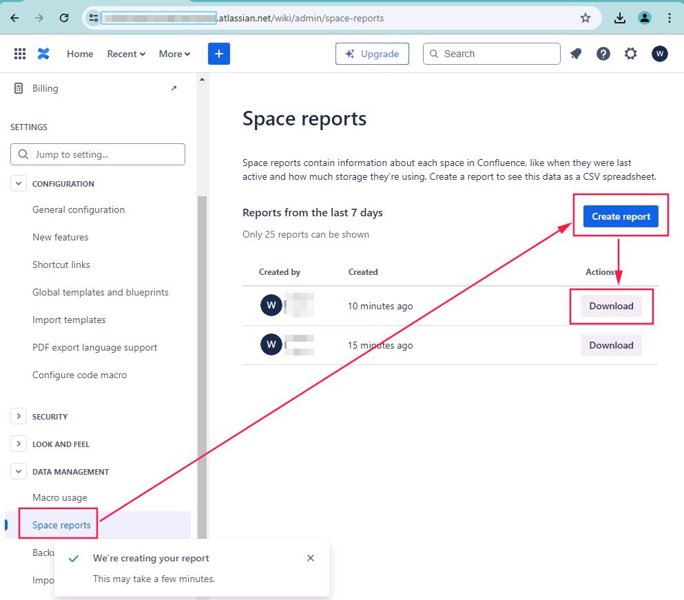
Create a space report at '/wiki/admin/space-reports'.
Those reports include a list of all spaces and the content count per space.
Sum up all those content counts for all spaces and you’ve got the overall “page count”.
Here’s an example of calculating the overall count (57170) in Excel:
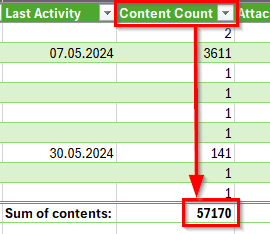
This number is what determines the Page Count Tier for the WikiTraccs license.
Via Analytics
In Confluence Cloud, you can use the Analytics features to get insights into the number of pages. See the discussion here: Page Count?
Getting the page count from the REST API
Getting the page count from the REST API depends on too many factors like permissions, page restrictions and endpoints used. It is thus error-prone and not recommended.
Third-party solutions
Let me know which third-party solutions you’d recommend: Get in touch.
17 - File Storage
Storage Locations
WikiTraccs stores data on the workstation it is running on.
Note
This documentation is valid as of WikiTraccs v1.12.25, as some locations were consolidated in this release.Attachment Registry
The attachment registry contains all attachments so far downloaded from Confluence.
The default storage location is the non-roaming AppData folder of the current user. On Windows this typically is C:\Users\user\AppData\Local, on Linux ~/.local.
You can change the attachment registry folder location via the WikiTraccs settings dialog, or via the appsettings.json > AttachmentRegistryRootPath property.
The attachment registry contains:
All downloaded Confluence attachments
- example: AttachmentRegistryRootPath\<subfolders per Confluence site, user and pages>
- storage requirement: ⚠️ as much space as the accumulating attachments of migrated pages need
- note: you can safely delete folders and files from the attachment registry subfolders; WikiTraccs won’t use them for anything else than uploading a page and its attachments to SharePoint; if files are missing, they will be downloaded again from Confluence
Blob cache for migration-related data
- example: AttachmentRegistryRootPath\wt-blobs.*
- example: AttachmentRegistryRootPath\wt-users_*
- storage requirement: usually < 10 GB
In-progress attachment downloads (when using Selenium proxy option; note: non-standard configuration)
- example: AttachmentRegistryRootPath\WtChromeDownloads
- storage requirement: as much space as the biggest attachment
- note: those attachments are moved to the Attachment Registry after downloading
- note: this folder should ever only contain one file, because each file is moved immediately after being downloaded
WebDriver (chromedriver.exe or msedgedriver.exe)
- note: as of WikiTraccs 1.19.5
Temporary Files
By default, temporary files are stored in the system’s temp folder. On Windows this typically is C:\Users\user\AppData\Local\Temp.
You can change the temporary folder location via the appsettings.json > TempPath property. See this section on how to change the temporary folder path: Change storage folder pathes.
Here’s what WikiTraccs stores at the temporary location:
Confluence Interactive Login Browser Profile
- Browser profile for Confluence login (with Cookie-based auth methods)
- example target path: C:\Users\USER\AppData\Local\Temp\WikiTracccs\HTTPS__WIKI.CONTOSO.COM
- storage requirement: size of a Chrome/Edge profile, ~2 GB
Note that USER is your Windows user’s profile name and HTTPS__WIKI.CONTOSO.COM will resemble your Confluence’s base address (with some special characters replaced).
Tip
Delete the whole HTTPS__WIKI.CONTOSO.COM folder to be asked to log in to Confluence again when starting your next migration. WikiTraccs will recreate the folder.
So, when your configured temp folder is C:\Users\USER\AppData\Local\Temp, and your Confluence base address is https://wiki.contoso.com, you would delete the C:\Users\USER\AppData\Local\Temp\WikiTracccs\HTTPS__WIKI.CONTOSO.COM folder.
Attachment Registry
Temporary storage location for attachment downloads
- example target path: C:\Users\user\AppData\Local\Temp\WikiTracccs
- storage requirement: as much space as the biggest attachment
- note: those attachments are moved to the Attachment Registry after downloading
Storage of intermediary transformation files (XML)
- example target path: C:\Users\user\AppData\Local\Temp\WikiTracccs
- storage requirement: about ~100-500 KB per migrated page (depends on page content)
- note: only if setting is enabled
Confluence Selenium Proxy Browser Profile
- Browser profile for Selenium proxy (only if activated; note: non-standard configuration)
- example target path: C:\Users\user\AppData\Local\Temp\WikiTracccs\https__wiki.contoso.com\api-proxy
- storage requirement: size of a Chrome/Edge profile, ~2 GB
User Profile Application Data
WikiTraccs.GUI configuration file
- local user profile, WikiTraccs folder, e.g. C:\Users\user\AppData\WikiTraccs\WikiTraccsGui_config.json
- note: WikiTraccs < 1.12.25 used the temporary folder, e.g. C:\Users\user\AppData\Local\Temp\WikiTraccsGui_config.json
- storage requirement: < 1 MB
WikiTraccs “recently used” values (the last page ID entered in the diagnostic report dialog, the last group names and fallback account entered in the user list update, and license key file paths)
- non-roaming (Local) user profile, WikiTraccs folder, e.g. C:\Users\user\AppData\Local\WikiTraccs\WikiTraccsRecentlyUsed.json
- note: it survives WikiTraccs upgrades
- storage requirement: < 1 MB
18 - Glossary
What is a Confluence “Page”?
In this documentation, the term page most of the time refers to “page-like content”.
Page-like content is:
- pages
- blogposts
- whiteboards (Confluence Cloud)
- databases (Confluence Cloud)
- smart links (Confluence Cloud)
- folders (Confluence Cloud)
Each of the above will become a page in SharePoint when migrating from Confluence to SharePoint Online.
Note that attachments are explicitly not covered in above list. This is also why the term “content” is (in general) not a good replacement for “page” as it covers attachments as well.
Nevertheless, in some places the term content might be used instead of “page” or “page-like” content. The context should make clear if attachments are excluded or included by that term.
In some places the term item might be used as well.
History note
Historically, with Confluence Server and Confluence Data Center, talking about pages pretty much covered everything, often including blogposts. Saying pages and meaning blogposts seemed ok.
Then came Confluence Cloud. Whiteboards were added. Databases were added. Smart links were added. Folders were added.
Now what? From a migration perspective, they are treated in a similar way in that all of them are migrated to SharePoint and become a SharePoint page.
So, for the time being, when talking about pages the other content types are meant as well. As soon as there emerges a good moniker for “page-like content in the context of a Confluence to SharePoint Online migration” the documentation will likely adopt that.
Term Definitions
| Term | Synonyms | Meaning |
|---|---|---|
| Tenant (Microsoft 365) | - | Refers mostly to a SharePoint Online instance or sometimes the Entra ID that is associated with it, at least in this documentation. Tenants are often referred to by an ID like “170dd63a-3297-6006-8060-493a8304d6fc”. They can also be referred to by a host name like “contoso.onmicrosoft.com”, but that might not always be supported depending on the client used. |
| Tenant (Atlassian Cloud) | - | For details on Atlassian’s tenant concept refer to Atlassian Cloud architecture and operational practices. Throughout this documentation the tenant will refer to a specific Confluence instance (which is technically incorrect, but corresponds to the use of “tenant” to refer to SharePoint). |
| Site (SharePoint) | Site Collection, Subsite | Usually refers to a site collection in SharePoint. It can also refer to a subsite in SharePoint, but those are not so widely used anymore in SharePoint Online. When working with sites they are usually referred to by their URL like “https://contoso.sharepoint.com/sites/sitename". |
| Site (Confluence) | - | In this documentation, a “site” refers to a Confluence instance. In a broader sense a site can contain multiple other products as well, like Jira. The Confluence site in WikiTraccs is referred by URL to Confluence (like “https://wiki.contoso.com” or “https://contoso.atlassian.net/wiki" ). This might change in the future when WikiTraccs handles more products. |
19 - Multilingual Pages
Note
Multilingual pages are pages, whose content has been translated to more than one language.How does the translation work in Confluence?
There are third-party apps that enable users to translate whole pages in Confluence. WikiTraccs currently supports Scroll Translations.
How does the translation work in SharePoint?
SharePoint has a history of more or less usable approaches to multilingual user interfaces and content.
WikiTraccs supports different ways of migrating page translations from Confluence to SharePoint:
Note
Some options will be supported in a future version of WikiTraccs and are not yet available.- migrating only one language, the translation with most content in Confluence (not recommended)
- migrating only one language, as chosen via configuration (not yet documented)
- migrating all translations to a single SharePoint page (default mode, supported as of WikiTraccs 1.4.2, recommended)
- migrating each translation to a separate page in SharePoint
Refer to the following pages for more information
19.1 - Info about Scroll Translations
What is Scroll Translations? How does it make Confluence pages multilingual?
Scroll Translations is a third-party app by K15t that allows to translate Confluence pages to different languages.
Under the hood Scroll Translations creates a macro for every language the page is translated to. Those macros are stored in the page content.
The user can choose which language they want to see in Confluence. Only one language is displayed at a given time.
WikiTraccs can see all languages at once when it migrates a page and can act on them.
How to Activate Scroll Translations for a Space
In case you are wondering how a Confluence space can be made multilingual using Scroll Translations, we briefly look into how it is done.
With the Scroll Translations app installed, the space settings have a new entry Scroll Add-ons:
Clicking that opens the settings where the Translations feature can be activated for the current space:
Upon activation, a default language has to be chosen, here German:
This means that all Confluence pages are by default created in German and can optionally be translated into more languages.
Additional languages can be added as alternatives, here English and Dutch:
Now every page has a language chooser where authors can choose the language the want to edit:
Notes About the Default Language
With Scroll Translations, every Confluence space gets a default language.
Pages are always available in this default language. Additional languages might be available for a page, but translations for those languages can be missing.
Note that SharePoint sites also have a default language. A mismatch between the Confluence space default language and the SharePoint site default language is nothing to worry about, but can lead to empty pages being created in SharePoint.
Pages in the default language must exist. This is true for both Confluence and SharePoint.
Thus, it is recommended to match the default language of a to-be-migrated Confluence space with the default language of the target SharePoint site (at least when performing a space to site migration).
19.2 - Migrating all Languages to one SharePoint Page
Please have a look at the release notes of WikiTraccs 1.4.2 for details.
19.3 - Migrating to Multilingual Pages in SharePoint Online
Note
Make sure to use a WikiTraccs release newer than v1.23.15 when following the guidance in this article.TL;DR (Summary)
This article is pretty long, so here are the key facts up-front on what to do:
- Make sure that the multilanguage solution in Confluence is indeed Scroll Translations, as this is supported.
- Recommendation: Create SharePoint target sites with the same default language that is used in Confluence.
- Enable the multilinguality feature in your target SharePoint site(s) and add languages.
- Create appsettings.json to configure WikiTraccs.
- Start a migration; each language should now get its own page in SharePoint.
A brief introduction to multilingual SharePoint
Over time, there have been many approaches to multilinguality in SharePoint, both out-of-the-box ones and from third parties.
When searching for information on multilingual SharePoint sites remember to look at the date of information you find. Documentation about multilingual SharePoint pages should be newer than 1-2 years, and for SharePoint Online, not SharePoint on-premises.
There are also different approaches depending on whether you want to translate the SharePoint user interface (list titles, content types etc.), or the content of pages (text, web parts).
We shall focus on modern approaches to translating content of modern pages in SharePoint Online.
In general, two approaches of making pages appear in different languages are common in SharePoint:
- providing multiple translations on one page
- using the out-of-the-box feature for multilingual modern SharePoint pages, creating one page per translation
The following sections look at the second option, the out-of-the-box feature to create one page per translation.
How do multilingual pages work in SharePoint?
Microsoft has an out-of-the-box feature for creating page translations documented here: Create multilingual SharePoint sites, pages, and news.
It is disabled by default and has to be switched on on a per-site basis.
Notes from the SharePoint documentation
Pages are not translated automatically. Each page created in your default language can have a corresponding page in a chosen target language that you, or someone you assign, manually translates. After you translate such a page and publish it, it will automatically be displayed to users who prefer that language.
Changes to the original, source page or to other translation pages are not automatically synced with all translation pages. Each translation page must be updated manually.
The language displayed to a user will depend on their personal language and region settings.
We recommend using the steps in this article for multilingual sites. However, if you are using SharePoint Server versions earlier than 2019, see Using the variations feature for multilingual sites.
The multilingual features described in this article are not available on subsites.
Multilingual features will only be available on sites that have publishing infrastructure settings disabled.
When this feature is enabled, a separate page can be created for each supported language. SharePoint takes care of routing the user to the page that matches their profile language.
And that’s basically it. Each language get’s a separate SharePoint page. The pages are connected by metadata.
WikiTraccs can create those translated pages, based on translations it finds in the source Confluence pages.
How to activate multilingual pages in a SharePoint site?
Find your way to the Site settings and click the Language settings link:
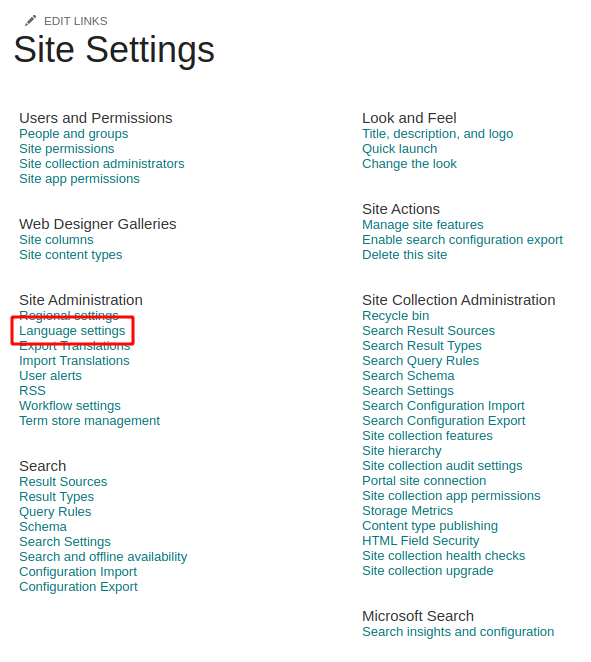
By default, the feature is off:

Enable translations and choose the languages SharePoint pages should be translatable to:
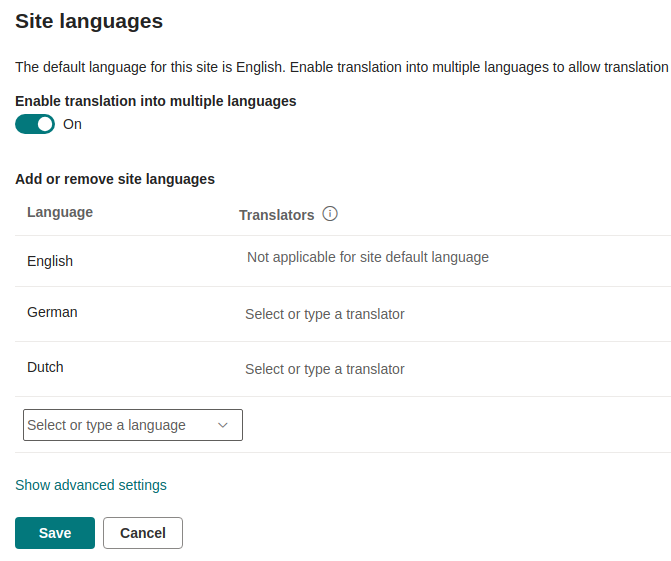
Now each page gets a language chooser:

The authoring experience for pages changes slightly in that additional controls will be available to manage the creation and translation of language-specific pages:
Looking at the Site Pages library you will that SharePoint creates a folder for each language where translated pages are stored.
Here it’s the de folder for German pages and the nl folder for Dutch pages:
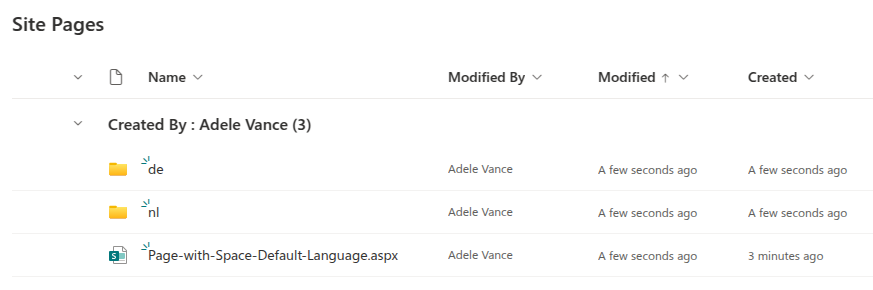
Note
A SharePoint site’s default language is set when creating the site:
Once set, the default language cannot be changed.
How to create multilingual pages with WikiTraccs?
WikiTraccs knows about SharePoint’s multilingual pages feature and can create language-specific pages, based on translations it finds in Confluence.
Since this is an advanced and not-so-often-used feature, WikiTraccs has to be told to use it via its configuration file, appsettings.json.
Create appsettings.json and add the following configuration:
{
"CustomSettings": {
"Translations": {
"TranslationMigrationModes": [
"MultiForSharePointSiteLanguages"
]
}
}
}
Note
Having this configuration in place overrides the translation configuration done via the WikiTraccs.GUI Settings dialog.Restart WikiTraccs after configuring this.
The next migration of multilingual Confluence pages will create a separate page for each language.
Note
A translated SharePoint page will only be created if the target site has the multilingual pages feature switched on and the language has been configured as supported.Migrating a page that is available in English, German, and Dutch will result in all three languages being present in SharePoint as well:
When there is a translation missing in Confluence, it will be in SharePoint as well (here Dutch is missing):
How does WikiTraccs handle…
… a mismatch in default languages?
Let’s assume the default language of a Confluence space is German and the target SharePoint site’s default language is English. Does it matter?
WikiTraccs doesn’t care. It maps each language found in Confluence to a language that has been enabled for the target SharePoint site.
WikiTraccs will always create a page in the target site’s default language, though. If the source Confluence page doesn’t provide a translation for this language, an empty SharePoint page will be created.
… a language not being available in the SharePoint site?
Before migrating, you must configure the list of available languages in each target SharePoint site.
When migrating multilingual Confluence pages, WikiTraccs maps to languages that are available (as per your configuration) for translation in the target SharePoint site.
For example, this configuration enables WikiTraccs to create pages in English, German, and Dutch. But not French:
If the source Confluence page provides a translation for a language that is not enabled in the target SharePoint site, no page will be created for this language. It won’t be available in SharePoint.
So, with above configuration, a French translation would be left behind and won’t be available as SharePoint page. In the log file, there will be a corresponding Warning message.
Limitations of WikiTraccs with Regard to Multilingual Pages
As this feature is rarely used, there are limitations.
Permission Migration
The permission migration doesn’t know about multilingual pages. (But you shouldn’t migrate permissions anyway.)
Migrated Confluence page restrictions will only be applied to the SharePoint page that has the default site language.
Delta Migration, Updating Pages
Before updating already migrated pages, the existing SharePoint pages need to be manually deleted from all language folders in the Site Pages library.
Page Attachments
Confluence page attachments are migrated to the attachments folder of the page that has the default site language. The translated SharePoint pages refer to those files as well.
This has implications for restricting access to single SharePoint pages. When removing or granting access on a single SharePoint page, SharePoint also removes or grants access on the attachment folder.
Caveats of Multilingual SharePoint Pages
There are implications of each translation being a separate SharePoint page. The following points apply to the SharePoint feature in general.
Permissions: Retricting permissions on one translated page doesn’t restrict permissions on the other translated pages.
Attachments: Each page gets its own attachments folder. For three translations this means three attachment folders. This can be confusing and can cause attachments to be unavailable if a subset of translated pages is access-restricted. It might also lead to duplicates if the same attachment is dropped onto different translation pages, each ending up in a different folder.
Search: All pages are indexed separately by search and can be surfaced via search. This might be confusing; or duplicate detection kicks in and hides pages from search results.
Comments: Each translated page has its own comments section.
Metrics: Page views, likes etc. are counted separately per translated page. There is no easy way to get overall metrics for a page that includes all translations.
20 - WikiTraccs GUI vs. WikiTraccs Console
WikiTraccs consists of two applications: WikiTraccs.GUI and WikiTraccs.Console.
Note
When you extract the release package there are two folders: WikiTraccs.GUI and WikiTraccs.Console, containing the respective applications.WikiTraccs.GUI is a graphical frontend that can be used to get started quickly without having to learn how to use the configuration file. When chosing to start the transformation WikiTraccs.GUI launches WikiTraccs.Console and passes along the configuration. From then on the work is done solely by WikiTraccs.Console.
WikiTraccs.GUI
A graphical user interface for WikiTraccs.
The initial size of the window might be a bit small depending on the environment you are running WikiTraccs in:
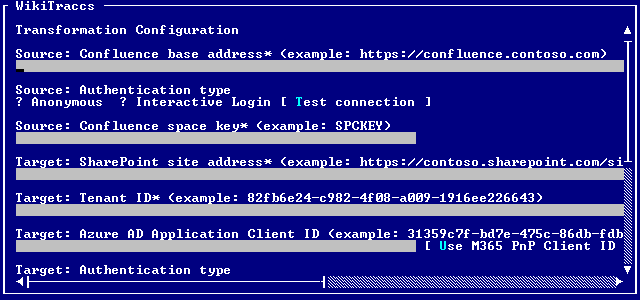
Empty sign-in experience
To make the window larger right-click the console window title bar and select Properties. Increase the size there:
Console window settings
Select OK to confirm the settings.
WikiTraccs.Console
The WikiTraccs console application doing the heavy lifting of transforming content from Confluence to SharePoint. You can skip using WikiGraccs.GUI and start WikiTraccs.Console directly. The configuration then has to be done via the appsettings.json file as described on the Settings page.
21 - Known Issues and limitations
Limitations
Size-Related
Pages with more than 2 MB of page text content cannot be created in SharePoint Online. This is a known limitation of SharePoint Online. Note that this does NOT mean page attachments, but actual page content. Pages hitting this limit would be massively long.
Overly long page titles break page creation in SharePoint. This is tracked in issue #3.
Restrictions/Permissions-Related
When migrating page restrictions, WikiTraccs will only migrate up to 200 user and group restrictions per page.
The principal/metadata update mode of WikiTraccs currently can only handle up to 5000 attachments per page.
Attachment-Related
Modern SharePoint Online team sites have the “no-script” security setting enabled by default, which blocks uploading files with certain extensions. WikiTraccs cannot bypass this and will skip such attachments during migration; a warning of the form [Files] Skipping upload of file '<name>' to '<folder>' is written to the log for each one.
The blocked extensions are: .asmx, .ascx, .aspx, .htc, .jar, .master, .swf, .xap, .xsf.
Delta Mode-Related
Changes to a Confluence page’s attachments or comments are not counted as “page change”. The page is detected as unchanged, even if e.g. attachments are added.
Changes to a Confluence pages’s title will duplicate the page in SharePoint, as the file name of the SharePoint page changes. Those kinds of title changes in Confluence might also lead to stale or broken links in SharePoint. If already migrated pages (in SharePoint) link to the newly migrated page (that now has a new name in SharePoint), those links will point to the old page; or be broken if the old page is deleted manually.
Content-Related
Rich image captions are not supported by SharePoint Online, the text content of the image caption will be used instead.
Macro/Web Part-Related
Macros transformation for macros which include content from other pages, like Excerpt Include and Multiexcerpt include are resolved one level deep. Nesting is not supported.
Draw.io embeddings from OneDrive etc. are not migrated as image, as they have no preview image.
Confluence Cloud
Migrating databases is not yet supported as there is no endpoint provided by Atlassian to export the data.
Link transformation for sharing links that have been pasted to pages (those contain ‘/l/cp/’ ) is not yet possible. Note that those are not tiny links, which are properly transformed. Discussions about this link format: 1, 2.
At the time of this writing, retrieving inline comments might fail in Confluence Cloud. Note that inline comments are currently not surfaced anywhere on migrated pages, but only stored in the WikiTraccs site with the page storage format XML blob. This inline comment retrieval currently seems to be broken with the Confluence Cloud REST API v2.
Hard links of type create page are left as is, pointing to Confluence. WikiTraccs doesn’t know what to do about them as there is no equivalent in SharePoint. Sample link: https://contoso.atlassian.net/wiki/pages/createpage.action?spaceKey=SPC&title=Page.