Confluence Space Inventory
This article is a resource where you can find information about the Confluence Space Inventory list.
Facts about the Confluence Space Inventory
The Confluence Space Inventory - or short Space Inventory - is a SharePoint list that serves the following purposes:
- list all Confluence spaces; those can be marked as migration source, making them a space selector
- allow configuring additional source content selectors (CQL query selectors, content ID selectors)
- serve as the lookup table when transforming Confluence links to SharePoint links
Selectors
A source content selector is either a Confluence space key, a CQL query, or a list of content IDs. When selected for migration, all pages, blogs, etc. covered by the source selector will be scheduled for migration.WikiTraccs creates the Space Inventory list and adds information about Confluence spaces.
You use the Space Inventory to select source content to migrate, and to specify target SharePoint sites. WikiTraccs will use this information to decide which content to migrate, and how to resolve links between pages.
The Space Inventory is created and updated by WikiTraccs.GUI when selecting the Update space inventory and WikiTraccs site button:
Note: WikiTraccs.Console will also check and create the Space Inventory, if necessary.
The Space Inventory can be repeatedly updated by selecting the Update space inventory and WikiTraccs site button. Use this to have spaces added to the inventory list that are missing, either because they have been newly created in Confluence, or because they have been deleted from the list.
Accessing the Space Inventory
Selecting the Open Space Inventory to choose source spaces button opens the Space Inventory in a browser:
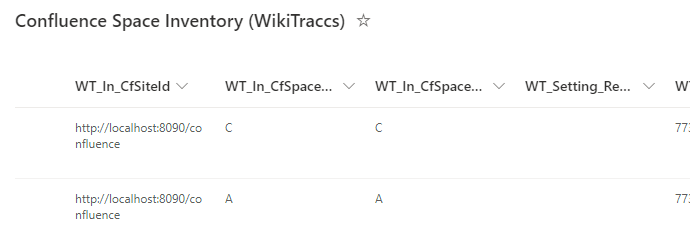
When the Space Inventory exists, the browser should show the SharePoint list Confluence Space Inventory (WikiTraccs):
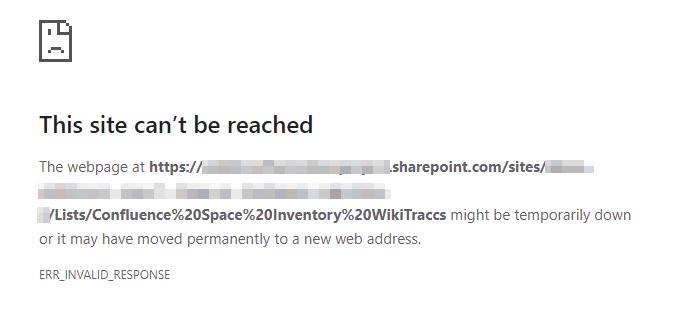
If - for whatever reason - the Space Inventory does not exist, the browser will show an error:
If you see above error, make sure to select the Update space inventory and WikiTraccs site button first so that WikiTraccs has a chance to create and update the list.
You can find the Space Inventory without WikiTraccs as well, as it’s just a SharePoint list. Open the WikiTraccs site in a browser, go to Site Contents, and select the Confluence Space Inventory (WikiTraccs) list.
How does it work exactly?
Here’s an image showing how the Space Inventory works:

This image summarized:
- the Space Inventory list contains multiple source to target mappings that tell WikiTraccs what to migrate, and where
- each row contains at least the following mandatory information:
- WT_In_CfSiteId - the Confluence site identifier; this corresponds to the Confluence base URL (example: https://wiki.contoso.com or https://contoso.atlassian.net/wiki)
- WT_In_CfSpaceKey - a source selector, telling WikiTraccs which pages to migrate; this can be the Confluence space key, but starting with release 1.8 of WikiTraccs this field can also contain a CQL query (example for space key: HR, example for CQL query: label=“archive”)
- WT_Setting_RequestTransformation - if this is checked, WikiTraccs will migrate all pages covered by the the source selector from Confluence to SharePoint; otherwise this mapping is only used for link resolution
- WT_Setting_TargetSiteRootUrl - the target SharePoint site for all pages covered by the source selector; this is relevant for migrating pages covered by the source selector, but also for creating the correct links to target pages (example: https://contoso.sharepoint.com/sites/target1); if this is left empty, the default target site URL as configured via WikiTraccs.GUI will be used
- when starting the migration, WikiTraccs will collect content from all source content selectors that have been chosen for migration, and schedule them for migration; this queue is processed one item after another
- when a page contains a link to a space, page or attachment, WikiTraccs will look up the SharePoint target site in the Space Inventory and create the link based on the found mapping; if there is no mapping a transformation error will be logged for the page (see Measuring page migration success on where to find this metric)
Using the Confluence Space Inventory
Here are other resources involving the Space Inventory:
To learn more about the source-to-target mapping and about the different source content selectors, refer to the following articles:
1 - How to map Confluence Source Selectors to SharePoint Sites
This article describes how to configure which Confluence content is migrated to which SharePoint site.
WikiTraccs needs to know what to migrate and where to migrate it to. It needs a mapping.
Content to migrate is chosen by source content selectors.
Selectors
A selector tells WikiTraccs which Confluence content to migrate.
The following selectors are supported:
WikiTraccs also needs to know where to create the migrated SharePoint pages. This is done by configuring a target site collection for each selector.
Note
Attachments are not covered by selectors. They are always migrated together with their parent page or blogpost.The source-to-target mapping is important for two things:
- knowing which Confluence content to get and to which SharePoint site to migrate this content
- transforming Confluence links to proper SharePoint links
Getting the mapping right before starting the migration is crucial for link transformation.
Migrate to one target site by default
WikiTraccs, in absence of any other configuration, migrates everything to one default target site.
When using WikiTraccs.GUI you enter the default target site URL into the Default target site input field:

Default Target Site Configuration in WikiTraccs.GUI
When you don’t configure anything else, WikiTraccs will migrate Confluence content to this SharePoint site.
Note
This default mode is usually not what you want. So read on.When you want WikiTraccs to migrate content from different source content selectors to different target sites, you configure this mapping in the Confluence Space Inventory list in the WikiTraccs site.
The Confluence Space Inventory list has a column WT_Setting_TargetSiteRootUrl. Enter the target site root URL there.
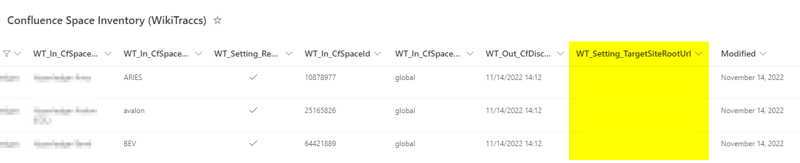
Target Site Root URL Column
When the WT_Setting_TargetSiteRootUrl column is empty, WikiTraccs falls back to using the default target site URL for that space. It is totally valid to set a target site URL only for some spaces.
Cross-space links and target sites
In general, when migrating pages, WikiTraccs translates links between Confluence pages to proper links between SharePoint pages.
Note
Everything in this section applies to attachments as well.The target site mapping is important to properly transform links between Confluence pages to links between SharePoint pages.
When migrating Confluence pages that link to other Confluence pages, WikiTraccs looks up the target site URL for the target page. To be able to do that, WikiTraccs finds the selector that contains the link’s target page and uses its target site URL to construct the page’s SharePoint URL. Note that the link’s target page doesn’t have to be migrated yet for this to work as page names follow a well-known naming convention.
Note
WikiTraccs uses the default target site URL when there is no target site URL configured for a space.The links WikiTraccs creates in SharePoint follow a naming convention. This convention is roughly as follows (for pages):
<TARGETSITEURL>/SitePages/<SPACEKEY>-<PAGETITLE>-<PAGEID>.aspx
(The resulting page file name is stripped of any characters that are not allowed in SharePoint.)
When a Confluence page is migrated to SharePoint and this page links to another page or space that has not yet been migrated WikiTraccs can nevertheless create the link. WikiTraccs doesn’t care if the target exists. It will exist once it will have been migrated.
This allows WikiTraccs to migrate Confluence pages that link to other pages or spaces that have not yet been migrated, while still creating valid links.
Note
When you don’t migrate the pages that WikiTraccs linked to in SharePoint those links will - of cource - be broken, since the target is missing.2 - How to migrate Confluence Content using Space Selectors
This article describes how to migrate whole spaces to SharePoint.
Selecting whole Confluence spaces for SharePoint migration is the easiest way to map and migrate Confluence content.
Why use a space selector?
With space selectors you tell WikiTraccs what to migrate on a per-Confluence-space basis.
Usual scenarios are:
- migrate each Confluence space to a corresponding SharePoint site
- migrate multiple Confluence spaces to one SharePoint site, for example for archiving purposes
If that is a granularity you can work with, do it. It’s easier than CQL query selectors and content ID selectors.
Go to the Space Inventory; it should already contain a list of all Confluence spaces WikiTraccs found, when you followed the steps of the Quick Start tutorial.
Set a check mark in the Wt_Setting_RequestTransformation column for every space you want to migrate.
Here’s what the Space Inventory list might look like:
Note: Other columns have been omitted for brevity.
In the above sample, three spaces have been selected for migration: Project Alpha, Project Beta, and Miscellaneous.
Space selectors are relevant for link transformation.
When WikiTraccs transforms a cross-space link from PAGE_SOURCE to PAGE_TARGET, all selectors in the Space Inventory will be checked if they contain PAGE_TARGET.
Having found a selector that contains PAGE_TARGET, WikiTraccs uses this selector’s WT_Setting_TargetSiteRootUrl value to create the link.
Be sure to fill those WT_Setting_TargetSiteRootUrl columns for all selectors, not only the ones to be migrated.
3 - How to migrate Confluence Content using CQL Query Selectors
This article describes how to use CQL queries to select source pages and how to configure which CQL query selector is migrated to which SharePoint site.
Note
CQL query selectors have been introduced in WikiTraccs release 1.8.0.WikiTraccs allows selecting source pages for migration using CQL queries.
Migrating spaces vs. migrating via CQL query
Before release 1.8.0 WikiTraccs only supported the configuration of entire Confluence spaces for migration and for link resolution. This meant that all pages of a given source space would be migrated to the configured target site.
Feedback from clients let to the introduction of an additional, more flexible way to select source pages: pages can now also be selected via CQL query. This allows to select specific pages for migration.
For WikiTraccs the technical difference is minimal, from a page selection perspective.
For you, the difference is also minimal, from a configuration perspective. The Space Inventory list is still used to configure which pages should be migrated to which target. Simply write your CQL query to the WT_In_CfSpaceKey field.
The following screenshot shows how different CQL queries are used to select pages by their label, migrating each label to a different target site:

Space Inventory list showing CQL query selectors for source page selection.
Note: the field is still named WT_In_CfSpaceKey since initially only a space key was supported there.
Everything else from the space selector article applies as well, so please refer to this article: How to map Confluence Spaces to SharePoint Sites. The target site can be configured. If there is no target site set, the default target site will be chosen.
There are some consequences though, when using CQL queries.
The consequences of using CQL queries source selectors
Note about Page Restrictions
CQL queries will only surface
restricted pages when the logged-in user is explicitly listed in the page restrictions (either directly or as member of a group).
Confluence admin accounts that are allowed to
access all pages (
even restricted ones) are often
not part of page restriction configurations and thus restricted pages will be missing in the CQL query result. This is Confluence out-of-the-box behavior.
Here’s the list of topics that can get more complicated when dealing with CQL queries:
- Restricted Pages: see note above
- Link Resolution: Confluence pages linking to other spaces, pages, or attachments require more time to migrate, and put more load on Confluence
- Query Result Size: using CQL queries you can select a large amount of pages (potentially all)
- Duplicate Pages: one page can be selected by multiple CQL queries, leading to pages being migrated multiple times
Tip
If you want to test a CQL query you can do so in the browser as follows:
- open a browser and log in to Confluence
- in the same browser window, enter the following in the address bar:
https://<confluencebaseurl>/rest/api/content/search?start=0&limit=200&cql=type="page" (note: make sure to replace <confluencebaseurl> with the base URL of your Confluence); press Return
The browser window should now show a wall of text. This is the result for the CQL query type="page" which selects “all pages”.
Link resolution is more difficult
For each CQL query selector you add to the Space Inventory WikiTraccs has to issue one additional request to Confluence for each link it needs to resolve.
Assume you are migrating 10,000 pages, with 2 links to other pages on each of those 10,000 pages. Further assume you configured 100 CQL query selectors in the Space Inventory list. That means that 2*100 callbacks to Confluence would need to be issued for each of those 10,000 pages, amounting to 2,000,000 calls overall during the migration of those 10,000 pages.
Why is that?
To transform links from Confluence to SharePoint, WikiTraccs needs to know which target site a page will be migrated to. But how would WikiTraccs know which CQL query contains which page? To learn this WikiTraccs asks Confluence for each CQL query if a given page is included.
Example:
- page A links to page B with ID 2000
- WikiTraccs needs to find out which SharePoint site page B will be migrated to, to create the proper SharePoint link
- there are two CQL queries configured:
label="one", mapped to target site https://contoso.sharepoint.com/sites/one, and label="two", mapped to target site https://contoso.sharepoint.com/sites/two - WikiTraccs creates a modified CQL query
(label="one") AND (id=2000) to check if page B is covered by CQL query label="one"- there are no results - page B is not covered
- WikiTraccs creates a second modified CQL query
(label="two") AND (id=2000) to check if page B is covered by CQL query label="two"- there is one result - page B is covered!
- WikiTraccs now knows that page B will be migrated to site
https://contoso.sharepoint.com/sites/two - thus the correct link to page B is something like
https://contoso.sharepoint.com/sites/two/SitePages/SPC-Page-B-2000.aspx
Note: WikiTraccs does not have to do this when only performing space-based migrations (without any CQL queries), since the target site can easily be looked up via each page’s space key in the Space Inventory list.
Duplicate pages can be created
You can write CQL queries might include overlapping results.
Take for example the CQL queries label="one" and label="two".
If Confluence pages only ever have one of the labels one or two, those selectors choose two disjuct sets of pages. Which is good.
But what about pages having both labels one and two? Those pages will be chosen by both CQL queries, migrating each of those pages two times.
The consequences are:
- duplicate content in SharePoint as multiple copies of a page are present
- fuzziness when it comes to linking to those pages as other SharePoint pages can only link to one of the duplicates; which one is not defined
CQL query selectors are relevant for link transformation.
When WikiTraccs transforms a cross-space link from PAGE_SOURCE to PAGE_TARGET, all selectors in the Space Inventory will be checked if they contain PAGE_TARGET.
Having found a selector that contains PAGE_TARGET, WikiTraccs uses this selector’s WT_Setting_TargetSiteRootUrl value to create the link.
Be sure to fill those WT_Setting_TargetSiteRootUrl columns for all selectors, not only the ones to be migrated.
4 - How to migrate Confluence Content using Content ID Selectors
This article describes how to use a list of Confluence content IDs to select source content and how to configure which content IDs are migrated to which SharePoint site.
Note
Content ID selectors have been introduced in WikiTraccs release 1.18.0.WikiTraccs allows selecting Confluence source content for migration using Confluence content IDs.
Why use a content ID selector?
If you have complex requirements with regard to which Confluence content is migrated to which SharePoint site, content ID selectors allow for full flexibility.
You’ll prepare a content ID selector for WikiTraccs that looks like this:
123456789;#page,234567891;#page,345678912;#page,4567891234;#blogpost,5678912345;#blogpost
Above selector contains the content IDs of 3 pages and 2 blogs.
How you end up with the list of IDs to migrate is entirely up to you.
You can run a complex database query in an on-premises Confluence environment. Or you can use Excel-based ID filtering on space content reports for Confluence Cloud.
WikiTraccs’ Content ID Format
WikiTraccs needs each content ID to follow this pattern: ID;#TYPE
ID is the actual Confluence content ID, like 123456789;# is a delimiter to separate the ID from the typeTYPE is the Confluence content type like page and blogpost (note: more content types will be supported in the future)
Multiple content IDs are delimited by comma, like ID;#TYPE,ID;#TYPE,ID;#TYPE.
Where to configure content ID selectors?
For each new content ID selector you want to create, add a new item in the Space Inventory.
Note
When adding new items to the Space Inventory list, SharePoint might consider Title as a required field. Just enter anything, WikiTraccs doesn’t need nor uses the Title value.Use the WT_Setting_ContentSelectorValue field to specify the content ID selector value.
Set the WT_In_CfSiteId field to the Confluence base address (like https://contoso.atlassian.net/wiki or https://wiki.contoso.com). Look at the other entries in the Space Inventory and copy the value from those entries that WikiTraccs created for spaces.
Here’s what the Space Inventory list might look like after adding two content ID selectors:
Note: Although content ID selectors are added to the “Space” Inventory, a space key or space ID doesn’t have to be set.
Migrating via CQL query vs. migrating via content IDs
CQL queries allow filtering content by IDs, just like content ID selectors.
But CQL queries in Confluence have one big limitation with regard to restrictions. Restricted contents might be missing from the query result, even when using a migration account that has admin permissions. Have a look at the CQL selector article for details: How to migrate Confluence Pages using CQL Query Selectors.
A WikiTraccs content ID selector does not have this restriction.
Why is that?
When handling a content ID selector WikiTraccs will also try to get chunks of content via CQL queries, to speed up things. WikiTraccs then checks if expected IDs are missing from the CQL query result. If there are IDs missing, WikiTraccs assumes that those are restricted and that the current migration account should be allowed to access them (just not via CQL).
For each ID that is still missing from the query result WikiTraccs will get those one by one via their ID. This will succeed if the content exists and the migration account is allowed to view it.
The consequences of using content ID source selectors
Please refer to the respective section of this article: How to migrate Confluence Pages using CQL Query Selectors. The reasoning about duplicates and links also applies to content ID selectors.
Furthermore, retrieving contents via single IDs for a large selector will take more time than retrieving all contents of a space or CQL query. The more content there is where the migration account is not direct part of the restriction configuration, the longer it takes to retrieve the selector’s content.
SQL Snippets
Note
Running SQL on the Confluence database is only possible in Confluence Server and Confluence Data Center, not Confluence Cloud.Using SQL you can get content IDs for your selector from the Confluence database.
Note
All statements have been tested with PostgreSQL.Here are sample SQL statements to get them in the right format for WikiTraccs (like 123456789;#page,234567891;#blogpost).
Get the content ID selector that includes ALL Confluence pages and blogposts:
SELECT count(*), string_agg(contentId || ';#' || contenttype, ',') AS contentIdSelectorValue
FROM (
SELECT contentId, LOWER(contenttype) AS contenttype
FROM content
WHERE (contenttype='PAGE' OR contenttype='BLOGPOST')
AND prevver IS NULL
AND content_status='current'
ORDER BY contenttype, contentId
) subquery;
Get the content ID selector that includes Confluence pages and blogposts from space MYSPACEKEY:
SELECT count(*), string_agg(contentId || ';#' || contenttype, ',') AS contentIdSelectorValue
FROM (
SELECT contentid, LOWER(contenttype) AS contenttype
FROM content LEFT JOIN spaces ON content.spaceid = spaces.spaceid
WHERE (contenttype='PAGE' OR contenttype='BLOGPOST')
AND prevver IS NULL
AND content_status='current'
AND spacekey='MYSPACEKEY'
ORDER BY contenttype, contentId
) subquery;
Replace MYSPACEKEY with the key of the space you want to get content IDs for.
Content ID selectors are relevant for link transformation.
When WikiTraccs transforms a cross-space link from PAGE_SOURCE to PAGE_TARGET, all selectors in the Space Inventory will be checked if they contain PAGE_TARGET.
Having found a selector that contains PAGE_TARGET, WikiTraccs uses this selector’s WT_Setting_TargetSiteRootUrl value to create the link.
Be sure to fill those WT_Setting_TargetSiteRootUrl columns for all selectors, not only the ones to be migrated.