This is the multi-page printable view of this section. Click here to print.
Troubleshooting
- 1: Connectivity Issues
- 2: Authentication Issues
- 3: Logging
- 4: Troubleshooting Strategies
- 4.1: Get the Confluence Storage Format
- 4.2: Get the SharePoint Storage Format
- 4.3: Troubleshooting Template: Page Migration Result
- 5: Troubleshooting FAQ
- 6: Support Options
- 7: Error Messages
- 8: Common Warnings and Errors in Log Files
1 - Connectivity Issues
The required endpoints are documented in the Endpoint reference.
Testing connectivity
The WikiTraccs GUI allows to test the connection to Confluence and to SharePoint. Select the Test Connection buttons to test.
Messages about blocked connections might look like this:
Note
User interface subject to change.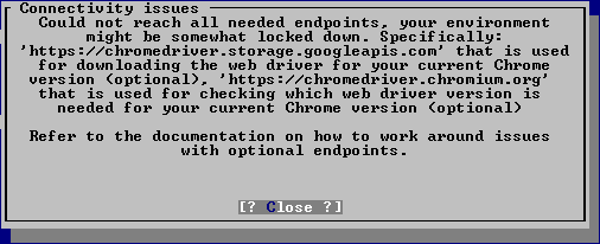
Connectivity note
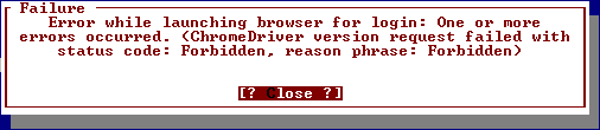
Connectivity error
How to handle blocked browser automation endpoints
In locked-down environments, WikiTraccs might not be able to detect and download required tools. WikiTraccs provides manual settings to work around that.
Refer to the Google Chrome or Microsoft Edge sections below, depending on which browser you are using.
Google Chrome
WikiTraccs uses the Chrome browser to execute certain tasks:
- show you a browser window so you can log in to Confluence (when using Interactive authentication)
- proxy web requests through the browser (when activated in the WikiTraccs Settings)
- export whiteboards as images (in Confluence Cloud, when activated in the WikiTraccs Settings)
- create missing draw.io preview images (when activated in the WikiTraccs Settings)
To remotely control Chrome, WikiTraccs needs a WebDriver program which is provided by Google.
WikiTraccs tries to download the matching WebDriver for the version of Chrome it locates automatically (or for the Chrome binary which is configured to be used via the ChromeBinaryPath setting).
If auto-detection or download fails then manual configuration is necessary. Specifically two configuration options must be set in a configuration file (sample snippet):
ChromeDriverVersionOverrideWebDriverDirPath
Follow the steps in the following section(s) (choose according to the Chrome version that is installed in your environment) to determine the configuration values.
Determining config values for Chrome version 115 and newer
Lockdown Scenario
The instructions below highlight which step needs internet connectivity. If your migration machine is connected to the internet, you’ll execute all steps on the migration machine and are good to go.
If your migration machine is locked down and has no internet connectivity, you have to execute some of the steps on an internet-connected machine. Those steps are marked as such.
Follow these steps to determine the right values for ChromeDriverVersionOverride and WebDriverDirPath which you put into WikiTraccs’ configuration file in a later step:
- [on the migration machine] Open the Chrome browser
- [on the migration machine] Open Chrome ⇒ (Three Dot Menu) ⇒ Help ⇒ About Google Chrome
- [on the migration machine] Take note of the version number (for example 118.0.5993.118)
- [on any machine with internet connectivity] Open https://googlechromelabs.github.io/chrome-for-testing/latest-patch-versions-per-build-with-downloads.json in a browser; a web page opens, showing a wall of text
- On this very page, using the search function of the browser, search for the version number from the previous step minus the last part; so, in this example you search for 118.0.5993 (note: the actual value will be different for you)
- This search should yield some results, showing more version numbers, which can be different from the Chrome version number
- Take note of the version value you see there, in the screenshot below it’s 118.0.5993.70 (in the red rectangle) - this is the
ChromeDriverVersionOverridevalue that you need in a later setp: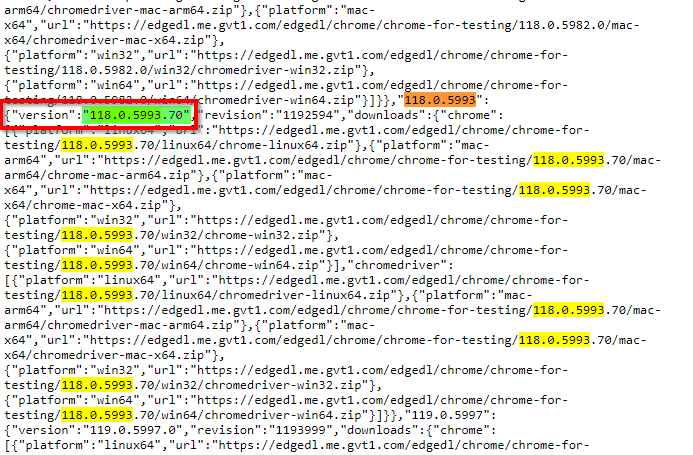
- Using this new 118.0.5993.70 version value you now build the Chrome WebDriver download URL that follows this pattern:
https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/{VERSION_VALUE}/win32/chromedriver-win32.zip- so, the download URL in this sample would be https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/118.0.5993.70/win32/chromedriver-win32.zip
- [on any machine with internet connectivity] Using any browser, open above URL in a new browser tab which should start the download of chromedriver-win32.zip
- Extract chromedriver-win32.zip and find chromedriver.exe:This is the WebDriver.
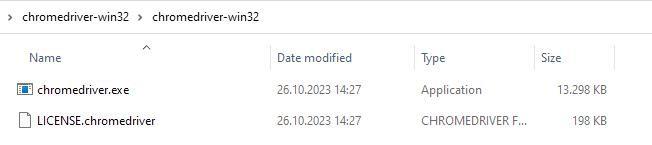
- [only in locked-down scenario] Copy chromedriver.exe from the internet-connected machine to the migration machine
- [on the migration machine] Take note of the folder path where chromedriver.exe is stored in; this folder path is the value for
WebDriverDirPath, that you’ll need in a later step- example path: C:\Users\user\Downloads\chromedriver-win32\chromedriver-win32
Skip the next section and continue with section How to apply the configuration below.
Getting config values for Chrome older than version 115
Old Chrome Version
You should probably skip this section as up-to-date environments will most likely use a newer Chrome version than 115. Refer to the previous section instead, for Chrome versions newer than 115.Follow these steps to determine the right values for * ChromeDriverVersionOverride and WebDriverDirPath:
- Open the Chrome browser
- Open Chrome ⇒ (Three Dot Menu) ⇒ Help ⇒ About Google Chrome
- Take note of the version (e.g. 86.0.4240.75)
- Open https://chromedriver.storage.googleapis.com/LATEST_RELEASE_# in a browser, with # replaced by the version from the previous step, minus the last part; so in this example the URL would be https://chromedriver.storage.googleapis.com/LATEST_RELEASE_86.0.4240 (it will be different for you)
- A web page opens and shows a single number (e.g. 86.0.4240.22) - this is the value you need to use as value for the
ChromeDriverVersionOverrideoption - Now open https://chromedriver.chromium.org/downloads in a browser and search for the section ChromeDriver # where # is the version from the previous step, which in our case looks like this:
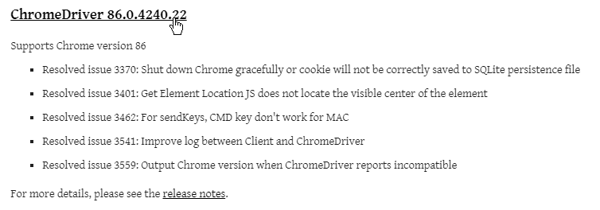
Find the right ChromeDriver version
- Choose the headline which takes you to the download page for this ChromeDriver version:
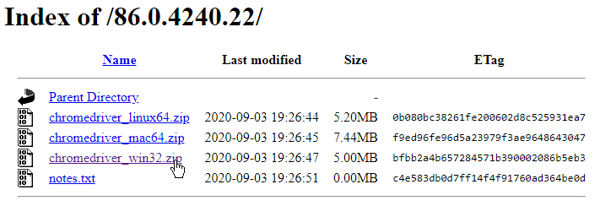
Download ChromeDriver for your platform
- Download the right zip file for your platform (Windows, Mac or Linux); the zip contains a single file (
chromedriver.exeorchromedriver), which is the WebDriver - Extract this single file to a folder; the path to this folder is the value for
WebDriverDirPath
Continue with section How to apply the configuration below.
How to apply the configuration
You now have to tell WikiTraccs about the ChromeDriverVersionOverride and WebDriverDirPath values by putting them into WikiTraccs’ appsettings.json configuration file.
Important
Backslashes need to be escaped in yourWebDriverDirPath since appsettings.json is a JSON file. That means every single backslash \ becomes a double backslash \\.Refer to the Configuration File article for details on how to create appsettings.json and where to store it. Then use the Chromedriver Configuration Sample as template for the file content.
Now WikiTraccs skips the WebDriver version check and download. This should resolve connectivity issues to the endpoints related to the WebDriver discovery and download.
Note
Restart WikiTraccs for the settings to take effect.Repeat on Chrome Updates
After updating Chrome (and it might auto-update) you have to download the matching WebDriver again according to the instructions in this article.Microsoft Edge
The configuration steps are similar to those for Chrome, but settings and endpoints differ. Documentation about that process is created upon request.
2 - Authentication Issues
2.1 - Confluence Authentication Issues
Note
Refer to Confluence Authentication to learn about supported authentication methods.What does a Successful Authentication look like?
To authenticate with Confluence using cookie-based authentication, WikiTraccs opens a browser window to let you log in.
Once you are logged in the browser window should close within about 30 seconds. This is normal behavior, indicating successful authentication.
Note
If no browser window opens at all then we need to go a step back. Internet connectivity issues might prevent WikiTraccs from getting everything it needs to even show the browser window. Refer to the Connectivity Issues article on how to work around those issues.WikiTraccs shows a success message if all authentication cookies could be retrieved. You can stop reading in this case.
If the browser window stays open for a long time after authenticating with Confluence then WikiTraccs is not able to detect your login, for whatever reason. In this case proceed with the troubleshooting sections below.
General Troubleshooting
First, close any open WikiTraccs window and re-start WikiTraccs. Sometimes this resolves issues with authentication. Also close any browser windows that WikiTraccs opened and that is still open.
If re-starting WikiTraccs doesn’t help check if you need additional or different authentication cookies for Confluence. Those can be configured in the advanced authentication configuration dialog. If you are using SSO solutions like Shibboleth you’ll most likely need additional cookies.
If the browser shows a screen reading “Access to Atlassian is monitored”, or the address bar contains .mcas.ms, then your organization routes Confluence through a security proxy (a CASB such as Microsoft Defender for Cloud Apps Conditional Access App Control). Cookie-based authentication cannot work while this is active. See Confluence behind a security proxy for why, and how to resolve it.
Or maybe the Confluence login timed out. WikiTraccs waits for some time for the authentication cookies to appear before giving up. Try to not take too much time for logging in as this might run into a timeout.
Workarounds
If the steps outlined in the previous section didn’t help then something is not right. WikiTraccs might have encountered a yet unsupported configuration of either Confluence or the system it is running on.
WikiTraccs has built-in ways to troubleshoot this. Try the steps outlined in the following sections.
1. Disable Context Path Check for Cookies
WikiTraccs makes assumptions about how the context path of Confluence and cookie data relates. Let’s disable those assumptions.
In appsettings.json, add the following setting:
{
"CustomSettings": {
"Debug": {
"SkipConfluenceContextPathCookiePathMatching": true
}
}
}
If appsettings.json does not yet exist, create it and copy above snippet to the file.
If appsettings.json already exists, find the Debug section and add the SkipConfluenceContextPathCookiePathMatching property. Create the Debug section if necessary.
Re-start WikiTraccs and check if authentication now is possible.
If authentication still cannot be detected, proceed with the next section.
2. Provide Cookies manually
This is a last resort
Depending on the middleware and Confluence server configuration, manually provided cookies can time out, so this approach may fail or stop working during a migration. If interactive login does not work, prefer the Selenium Proxy, which routes Confluence requests through a live browser session and avoids the cookie-timeout problem.WikiTraccs just needs authentication cookie values and does not really care where they come from.
Let’s provide them manually via a text file.
We need to:
- copy cookies from the browser to
cookies.txt - copy the user ID to
appsettings.json
Open Chrome (or Edge), navigate to Confluence and log in.
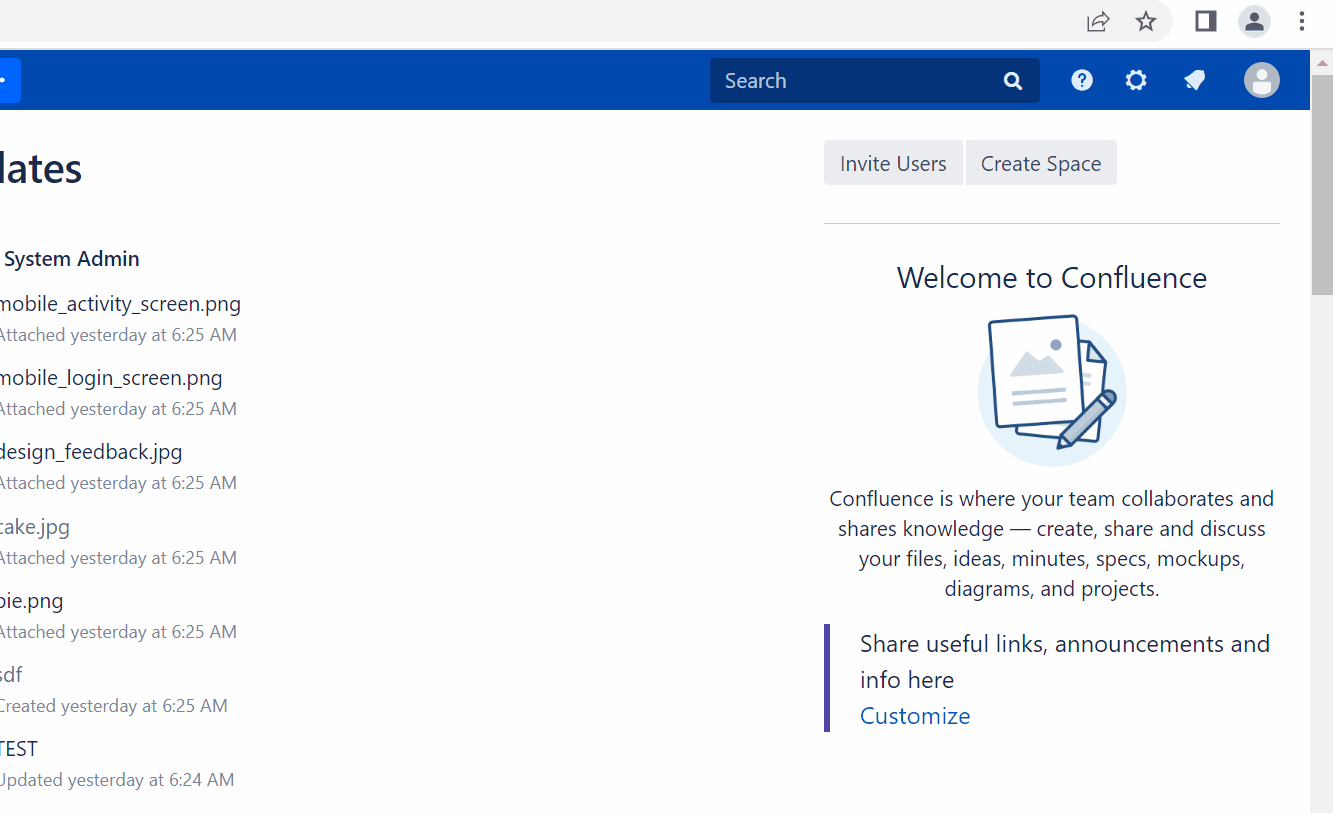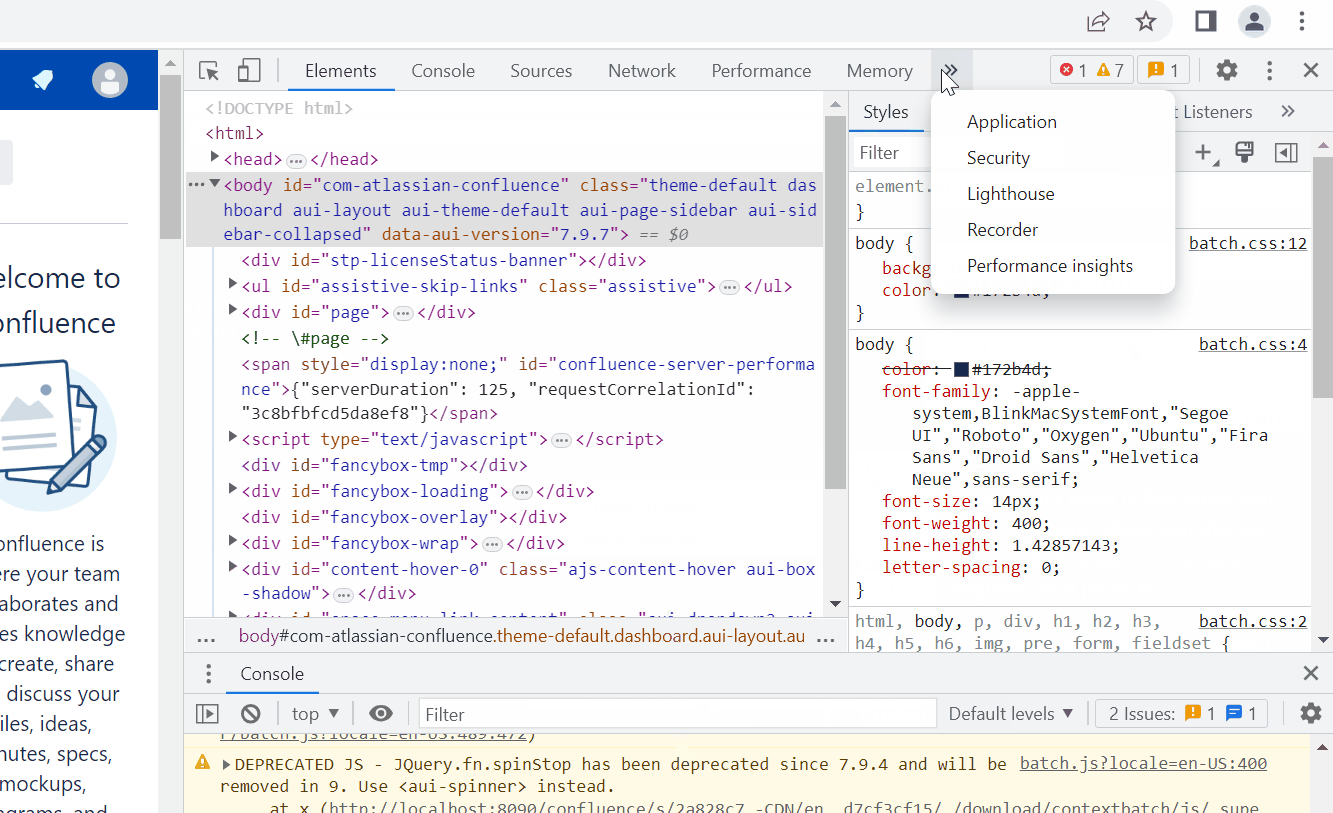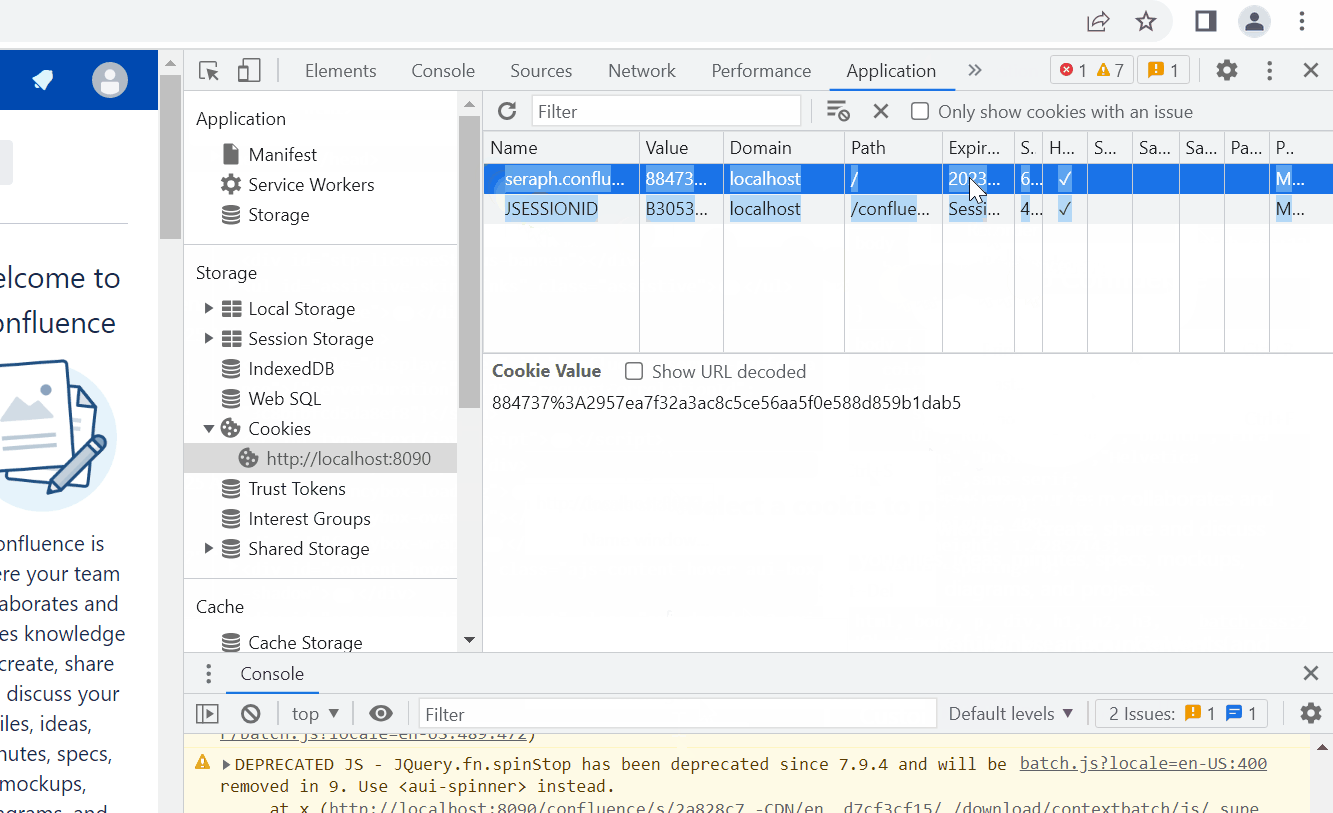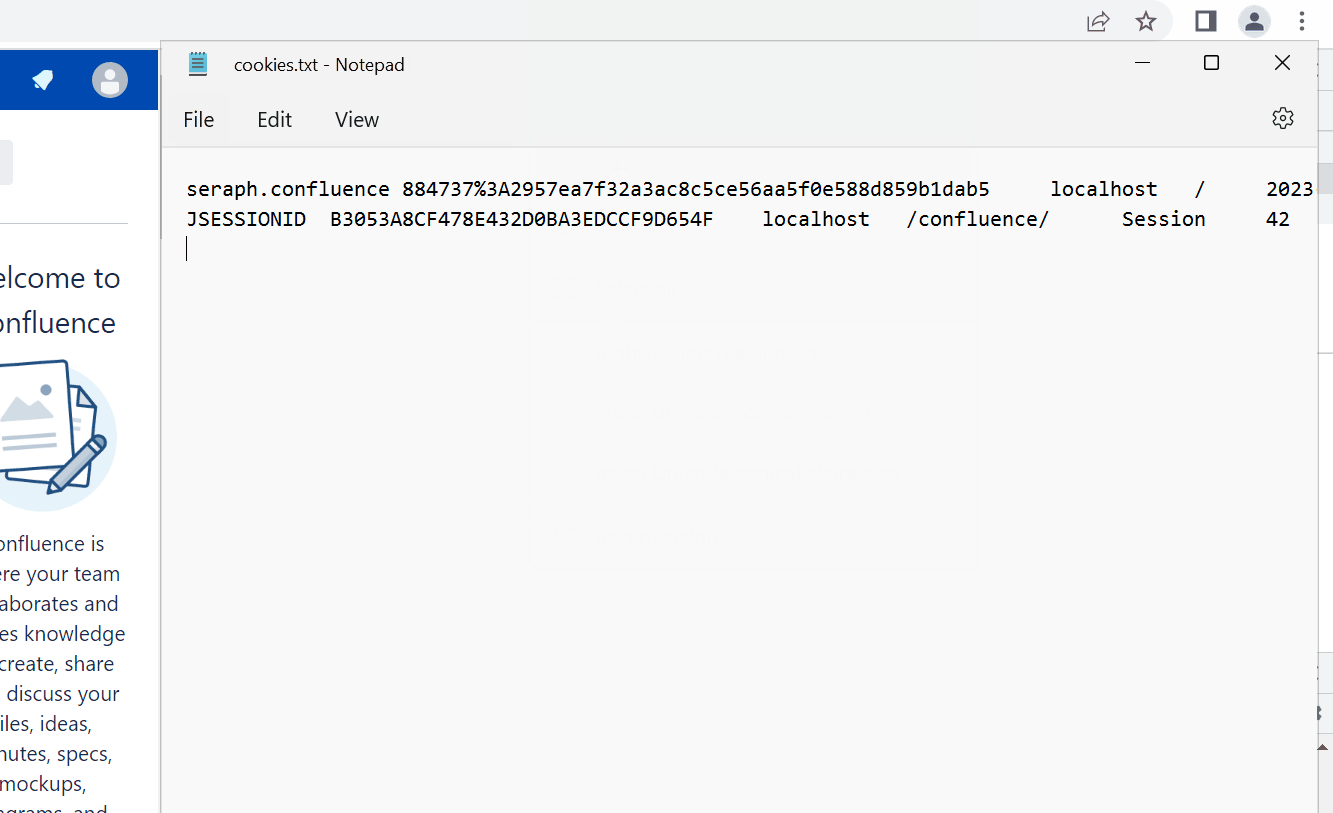
Still in the browser, press F12 to open the developer tools, and choose the Application tab.
Under Cookies, select the Confluence domain. A panel on the right side should show cookies.
Check that JSESSIONID is among those cookies. Unless the cookie name has been changed via server configuration. In this case check the configured name.
In the cookie panel, select all rows with the mouse and copy them to the clipboard.
Create a new file cookies.txt in either the WikiTraccs.GUI or WikiTraccs.Console folder (depending on what your are running). Have cookies.txt open in a text editor.
Paste the cookie values from the clipboard to the open text editor and save cookies.txt.
Here’s an animated GIF showing above steps:
Confluence Cloud: Beware of Truncated Cookies
In Confluence Cloud, the value of the tenant.session.token cookie can get so long that it gets truncated, which is indicated by three dots at the end of the value as seen in cookies.txt:

If that is the case (usually starting at around 1000 characters), you need to also copy the single tenant.session.token cookie value manually to cookies.txt, so that it is not truncated anymore.
Confluence Cloud: No JSESSIONID Cookie
As of 2026 Confluence Cloud doesn’t seem to use theJSESSIONID cookie anymore.Now go back to the browser. The developer tools should still be open.
Choose the Elements tab, expand the HTML head element and search for one of the following entries:
ajs-remote-user-keyfor Confluence on-prem (both Server and Data Center)ajs-atlassian-account-idfor Confluence Cloud
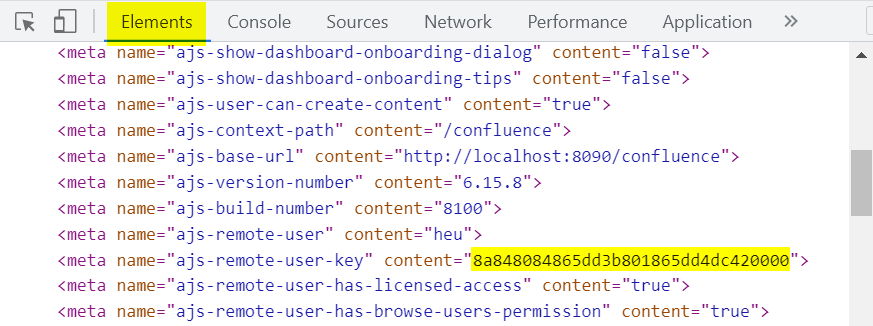
The ajs-remote-user-key content value (sample).
Put the ajs-remote-user-key content (on-prem) or ajs-atlassian-account-id content (Cloud) value to appsettings.json.
Here’s how it looks for Confluence on-prem:
{
"CustomSettings": {
"Debug": {
"AjsRemoteUserKey": "8a848084865dd3b801865dd4dc420000"
}
}
}
Here’s how it looks for Confluence Cloud:
{
"CustomSettings": {
"Debug": {
"AjsRemoteAccountId": "8a848084865dd3b801865dd4dc420000"
}
}
}
Note the name difference in above snippets: AjsRemoteUserKey (on-prem) vs. AjsRemoteAccountId (Cloud)
Anonymous authentication
If you are configuring this for a Confluence instance that can be accessed anonymously, and you want to migrate in anonymous mode, you must set the AjsRemoteUserKey/AjsRemoteAccountId to this exact value:
00000000000000000000000000000001
cookies.txt and the appsettings.json configuration in place, restart WikiTraccs and retry starting a migration.WikiTraccs now checks if cookies.txt exists and uses the cookie values instead of starting an interative browser login session. This should succeed.
Note
Right after having been started, WikiTraccs reports when it finds cookies.txt and the appsettings.json value:


Please get in touch if this still doesn’t work.
How to log out of Confluence?
When you log in to Confluence you can choose the Remember me option to stay logged in. This is very convenient during a migration since you are always logged in to Confluence without having to reenter your credentials.
But how to log out?
The solution is to delete the browser profile of the Chrome browser that WikiTraccs uses to log in to Confluence. The browser profile is stored in a temporary location, which by default is the Temp folder for your Windows user:
C:\Users\<username>\AppData\Local\Temp\<host-name-of-confluence>
- <username> is your Windows user profile name
- <host-name-of-confluence> resembles the host part of the Confluence base address, like confluence.contoso.com
Delete the whole <host-name-of-confluence> folder and you should be asked to log in again when starting your next migration. This will also recreate the folder.
Cannot find the folder? Have a look here on more information about this temporary folder and where you might find it: File Storage - Temporary Files
2.2 - SharePoint Authentication issues
Empty Microsoft sign-in experience
When starting a transformation a browser window opens for you to sign in to SharePoint Online.
On some systems the browser window might stay empty. This was seen on Windows Server 2012 with Internet Explorer 11. When this happens copy the URL from the address bar, open Chrome, and paste the URL there in the address bar to load the page. Authenticate there.
Alternatively configure the system to show the sign in experience.
Empty sign-in experience
3 - Logging
See Troubleshooting Strategies for different log files that can be used to troubleshoot issues.
4 - Troubleshooting Strategies
Confluence migrations to SharePoint, as migrations in general, are rarely without issues.
WikiTraccs has been tested with Confluence instances of different versions and different ages and has been hardened against common issues. Some recurring issues like broken page content (from past migrations) or inaccessible external images are gracefully handled.
But what if something appears broken nevertheless?
This page shows how such issues can be diagnosed and which data WikiTraccs creates to help diagnosing a Confluence to SharePoint migration that appears stuck.
How should you handle migration issues related to SharePoint pages created by WikiTraccs?
The easiest way for you is to put all information in a zip file and send it via email to contact -at- wikitransformationproject.com. I’ll take a look.
My goal is to identify the issue, replicate it in a test environment and make adjustments so that the issue can never occur again.
WikiTraccs grows with every Confluence migrated, since each one is unique. My goal is to make this as painless for you as possible. You can help me helping you by providing as much information as possible to replicate the issue in a test environment, so I don’t have to bother you with more questions.
Of course you can also look at the log files. If there are connectivity issues, or authentication issues the error messages are usually pretty clear, hinting in the right direction.
Which information is available to diagnose issues?
WikiTraccs logs detailed information about everything that it’s doing.
Note
Please include as much of this information as possible when getting in touch. Every bit can help analyzing the situation and providing guidance.Here’s an overview of what is available and helpful for diagnosing issues, more details follow further down.
| What? | Where can I find it? | Why does it help? |
|---|---|---|
| Common log files | in WikiTraccs.GUI\logs or WikiTraccs.Console\logs (depending on whether you are running WikiTraccs.GUI.exe or WikiTraccs.Console.exe) | Contains detailed information about the whole migration process, including warnings and errors |
| Progress log files | in WikiTraccs.GUI\logs\<date-folder> or WikiTraccs.Console\logs\<date-folder> (depending on whether you are running WikiTraccs.GUI.exe or WikiTraccs.Console.exe) | Contains information about migrated and yet-to-be-migrated pages; see Monitoring Confluence to SharePoint Migration Progress for details |
| SharePoint Site Pages library | every target site for the migration contains information about migrated pages | Shows detailed information for every page migrated; see Measuring page migration success for details |
| Confluence page storage format | for any open Confluence page choose View Storage Format; note that the Confluence Source Editor plugin has to be installed for this option to be present | Shows the page as WikiTraccs sees it; page structure and macros can be seen, analyzed and reproduced through a technical lens |
| Confluence page IDs and page titles of missing pages | open the page properties in Confluence for pages that did not migrate to SharePoint and look at the browser address bar - you see the page ID there; and the page title is the page title | the log files contain any errors that hinder migration and page IDs and titles help finding the right places in the log files |
Note
Log files can contain information relating to source and target environments, as well as content.
Examples are:
- Confluence source site URL
- Sharepoint target site URLs
- image URLs
- user names, email addresses, and IDs (e.g. when user mappings fail)
- snippets of content (e.g. when macro transformations fail)
Replace any content you aren’t willing to disclose before sending those files.
Common log files
Common log files cover information about the whole Confluence to SharePoint migration.
Where can I find those logs?
InWikiTraccs.GUI\logs or WikiTraccs.Console\logs (depending on whether you are running WikiTraccs.GUI.exe or WikiTraccs.Console.exe).Why are those files useful?
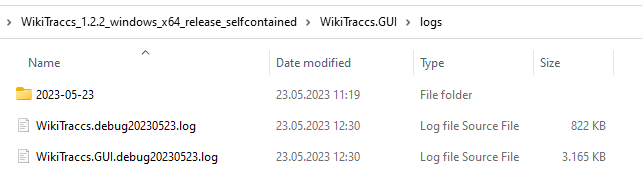
Common log files are useful to troubleshoot all issues, but are essential in root cause analysis when it’s still unclear where the issue originates.The log file names follow this pattern:
<date>-WikiTraccs.Console.log<date>-WikiTraccs.Console.WarningsAndErrors.log(note: as of WikiTraccs v1.22.1)<date>-WikiTraccs.GUI<date>.log
For each application run new log files are created. Here’s a sample logs folder:
Note
The filename format changed slightly over time and might look different depending on the WikiTraccs release you use.The <date>-WikiTraccs.GUI...log (note the GUI part) log file is created when using the blue WikiTraccs.GUI window, for example when testing connections and filling the space inventory. This file is useful to troubleshoot connectivity and authentication issues.
The <date>-WikiTraccs.Console.log log file is created as soon as a migration starts and WikiTraccs.GUI opens the WikiTraccs.Console console window. Or when using WikiTraccs.Console standalone. This file is useful to troubleshoot issues that happen while migrating.
The <date>-WikiTraccs.Console.WarningsAndErrors.log log file contains only warnings and errors. Those can also be found in the <date>-WikiTraccs.Console.log log file, but are duplicated here for convenience.
Note
Make sure to choose the log files where the date and time corresponds to the date and time of the migration run(s) you’d like to diagnose. In general: the more logs, the better.Progress log files
Progress log files conver the page migration state for all spaces that are part of the migration.
Why are those files useful?
Progress log files are helpful for troubleshooting issues around Confluence pages that are expected to be migrated but are not.They are in detail covered in Monitoring Confluence to SharePoint Migration Progress.
SharePoint Site Pages library and page metadata
Once pages have been migrated you should scroll through the Site Pages library to see if there is anything of interest.
Why are screenshots useful?
Screenshots of this view can help diagnosing issues with single pages.This is described in detail in Measuring page migration success.
Specific issues and how to diagnose them
We’ll look at real-world issues and how to diagnose them.
Assume the following migration scenario:
- source environment: Confluence 6 at
http://localhost:8090/confluence, one space 7SE has been selected for migration in the space inventory - target environment: SharePoint Online site
https://contoso.sharepoint.com/sites/arc42-template - the migration is done via WikiTraccs.GUI
The migration is finished when the console window looks like this:

There is nothing left to migrate, the console window can be closed by pressing Ctrl+C.
Issue: Some pages are not migrated from Confluence to SharePoint
The progress log files should tell us more.
But first we look at a successful migration result, to establish a baseline.
Case 1: A successful migration of all pages
There should be 4 log files after successfully migrating one Confluence space:
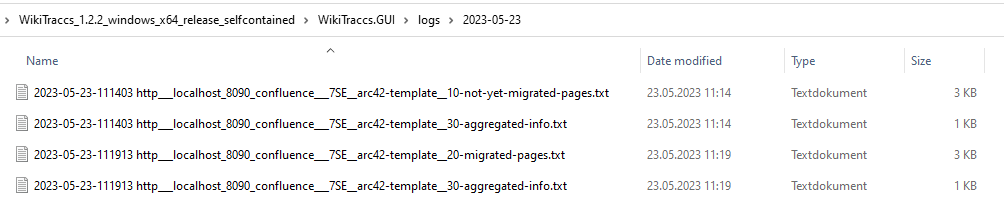
Of the four files, the first two were created before starting the migration. The last two files were created after having finished the migration.
Note
Keep an eye on the file’s timestamp to read them in the right order.Here’s the content of the […]aggregated-info.txt file that was created before migrating the Confluence space to SharePoint:
Source Confluence Site: http://localhost:8090/confluence/
Target SharePoint Site: https://contoso.sharepoint.com/sites/arc42-template
Space Key: 7SE
Blog posts included in migration and calculation: no
Confluence page count for space space 7SE: 32
Migrated SharePoint pages that correspond to found Confluence pages in space 7SE: 0
Migrated SharePoint pages overall for space 7SE: 0
Pages yet to be migrated for space 7SE: 32
This shows that WikiTraccs was able to retrieve information about 32 pages in this space and all have yet to be migrated.
Here’s the content of the second […]aggregated-info.txt file that was created after migrating the Confluence space to SharePoint:
Source Confluence Site: http://localhost:8090/confluence/
Target SharePoint Site: https://contoso.sharepoint.com/sites/arc42-template
Space Key: 7SE
Blog posts included in migration and calculation: no
Confluence page count for space space 7SE: 32
Migrated SharePoint pages that correspond to found Confluence pages in space 7SE: 32
Migrated SharePoint pages overall for space 7SE: 32
Pages yet to be migrated for space 7SE: 0
This time there are 32 migrated pages and there are none left to be migrated.
Success. Now we make it more complicated.
Case 2: Pages appear missing
Pages can appear missing when the migration account is not permitted to view all pages.
Here’s an example where a parent page of two child pages has been view-restricted to only the admin account:
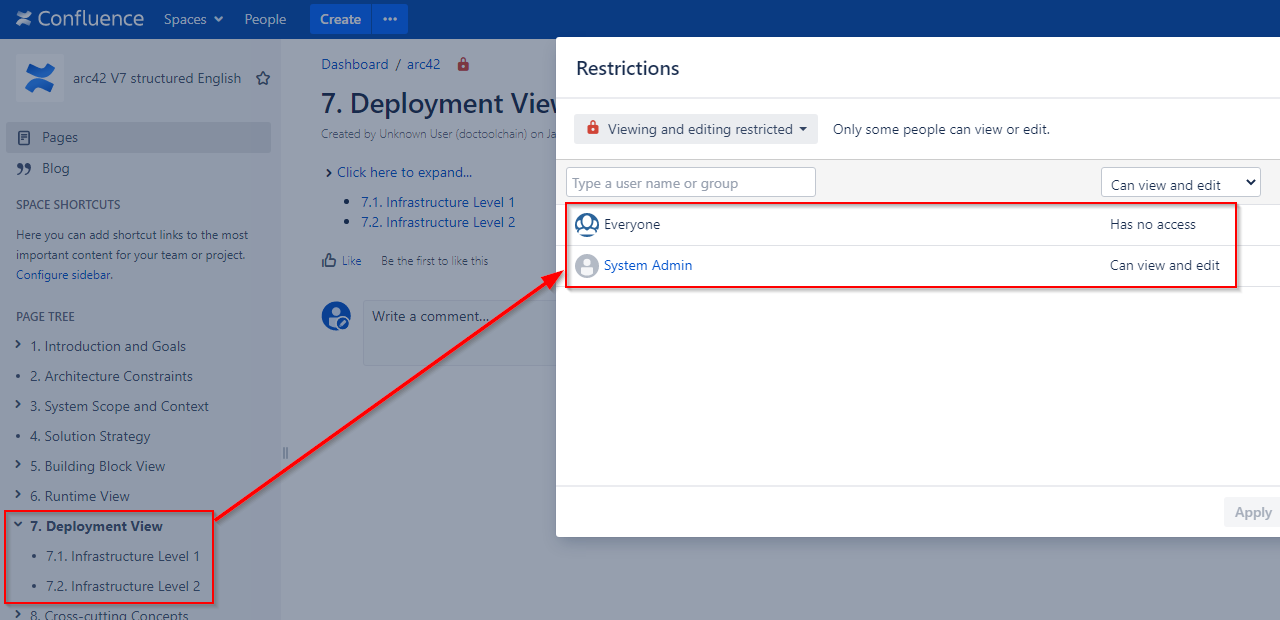
Now, when using another Confluence account as migration account, this account won’t see those three pages.
Thus (after deleting all previously created SharePoint pages and starting a new migration) the […]aggregated-info.txt file looks like this:
Source Confluence Site: http://localhost:8090/confluence/
Target SharePoint Site: https://heinrichulbricht.sharepoint.com/sites/arc42-template
Space Key: 7SE
Blog posts included in migration and calculation: no
Confluence page count for space space 7SE: 29
Migrated SharePoint pages that correspond to found Confluence pages in space 7SE: 0
Migrated SharePoint pages overall for space 7SE: 0
Pages yet to be migrated for space 7SE: 29
Only 29 pages are reported for the space that has in fact 32 pages. But 3 of those cannot be seen by the migration account.
The solution in this case is simple: use a migration account that can access all pages that should be migrated.
Case 3: Pages are missing, even after checking permissions
This could be anything, but it should be visible in the log files.
Please send me the log files and page IDs and ideally page titles of pages you’d expect to migrate from Confluence to SharePoint. This information should help to locate any errors related to those pages in the log files.
Please send information via email to contact -at- wikitransformationproject.com.
Issue: The progress bar in WikiTraccs.GUI is stuck
This is caused by pages that have been migrated before and have been updated in Confluence since. It should only happen when migrating the same space at least twice.
The pages that need to be updated can be seen in the progress log files.
The “update mode” feature request is tracked here: Add update mode for already migrated pages.
Technically everything is correct. You need to delete the SharePoint files you want to update, before starting another migration to have them created again.
Issue: The migrated Confluence page doesn’t look good in SharePoint (visual check)
The layout is off? Content is missing? Macros are missing?
There are probably thousands of special cases that can affect the Confluence page migration to SharePoint, hundreds of which are already handled by WikiTraccs.
If there is something wrong with the resulting page please use the options under Contact to get in touch.
Important note about missing macros
Many macros cannot be represented in SharePoint. So they are expected to be missing.
Here’s a primer on what to expect regarding macros: What about those Confluence Macros?
Here’s a list of macros and how they are handled by WikiTraccs: Known Confluence Macros.
Please open a support ticket with a feature request for macros you’d like to see migrated from Confluence to SharePoint. Please also include a description of your use case and a basic idea or mockup of how the migration result in SharePoint should look like.
Please provide the following for your request to be properly handled:
- Confluence version
- a screenshot of the source Confluence page
- a screenshot of the SharePoint page, with the unexpected parts highlighted
- the storage format of the source Confluence page - see Get the Confluence Storage Format for instructions on how to get that
- the page ID and title of the source Confluence page
- SharePoint page metadata for the affected page, like WT: Text Transferred Percent, WT: Failed Transformations and (most important) WT: Transformation Log (a screenshot is fine, see next section for a sample)
Please report issues via email to contact -at- wikitransformationproject.com.
Issue: The SharePoint page metadata shows Transformation Errors and/or a Text Transferred value that is not equal to 100%
WikiTraccs tracks its migration success per page. It has hundreds of transformation rules built-in.
If WikiTraccs discoveres a new layout or macro it cannot handle, it’ll raise a flag by counting the Transformation Errors or potentially missing text.
Here’s a sample screenshot of such an issue, where certain XML tags caused problems, leading to text being skipped:
Note
Please check the affected pages. Sometimes there is one type of macro causing issues technically for many pages, but it doesn’t make a difference visually. So while it would be nice for WikiTraccs to be less error-y in its messaging the migration result is fine.
Please add information about whether you’ve got a blocking issue or whether you are just raising awareness, when getting in touch.
To diagnose those issues the same information as in the previous section Issue: The migrated Confluence page doesn’t look good in SharePoint is needed. The most important part is the storage format because this hopefully allows to replicate and isolate the issue in a test environment.
Please report issues via email to contact -at- wikitransformationproject.com.
4.1 - Get the Confluence Storage Format
The Confluence Storage Format is the technical under-the-hood view of a Confluence page. It’s what WikiTraccs “sees” and transforms when performing the Confluence to SharePoint migration.
Note
You can learn more about the Confluence storage format in Atlassian’s documentation: How to retrieve Confluence Storage Format.How to view the storage format for a Confluence page? See your options below.
Option 1: View storage format in browser (using an app)
This is the most convenient option.
Note
This option is available when the Confluence Source Editor plugin has been installed.Here’s the Atlassian documentation on how to view the storage format: How to retrieve Confluence Storage Format
It boils down to this:
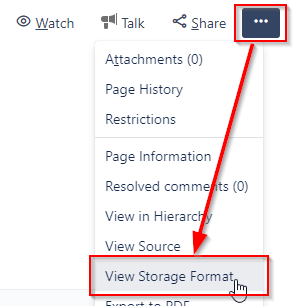
Open a page, choose the three-dot-menu, and choose "View Storage Format".
A new browser window will open, showing the storage format.
Option 2: Configure WikiTraccs.GUI to save the storage format to disk
WikiTraccs knows the storage format of each page it migrates from Confluence to SharePoint.
The storage format by default is only kept in memory and not persisted to a file.
Here’s how to tell WikiTraccs to store the storage format of every page to a file:
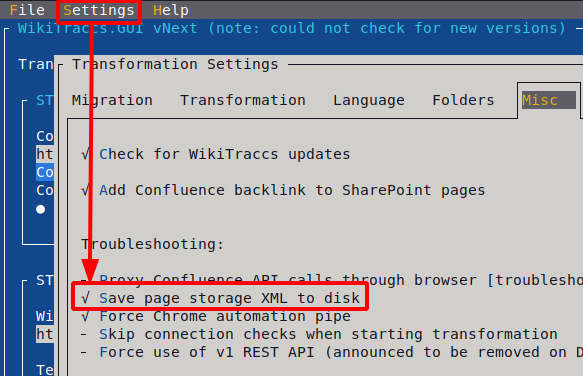
Variant 1: Enable via config file in WikiTraccs.GUI
In WikiTraccs.GUI, go to Settings ⇒ Configure Transformation ⇒ Misc and select the Save page storage XML to disk option.
Variant 2: Enable via config file appsettings.json
Note
Below instructions assume that you did not create appsettings.json before. However, if the file is already present, the additional configuration option needs to be added at the right place. Have a look at the Settings page for documentation of the correct format.- Open the WikiTraccs.GUI folder (this is the folder where WikiTraccs.GUI.exe is stored as well)
- Create an empty file appsettings.json inside the WikiTraccs.GUI folder
- Open the appsettings.json file in a text editor and put the following text in there:
{ "CustomSettings": { "Debug": { "SaveTransformationInputToDisk": true } } } - Save appsettings.json
- If WikiTraccs.GUI is open: close it and any other (console) windows it opened
- Open WikiTraccs.GUI and start a migration
Note
When you need to get the storage format of a page that has already been migrated before, you have to delete the already existing page in SharePoint first. Otherwise WikiTraccs won’t migrate this page again.Where can I find the exported storage format XML?
After following instructions of one of above variants, WikiTraccs now stores the storage format for every newly migrated page in a file, in the attachment registry.
The attachment registry is a folder where attachments from Confluence are downloaded to, while migrating. You can find it in the AppData folder of your local user account.
The attachment registry path for a Confluence page looks like C:\Users\<username>\AppData\Local\WikiTraccs\<confluenceuserkey>\<confluencebaseurl>\Attachments\<pageid>.
Here’s an example screenshot:

Attachment registry path for Confluence page 118587415.
Note
The screenshot above uses the app Everything from voidtools to locate the storage format file. It provides instant search results and is perfect for finding those files and folders by page ID.The storage format for a page is stored in a file that is named like xhtml_before-<spacekey>-<pageid>.xml.
Now you can access the storage format for every page that is part of your Confluence to SharePoint migration.
Note
Not using WikiTraccs.GUI? You can also configure WikiTraccs.Console to store the storage format to file. Just use the appsettings.json in the WikiTraccs.Console folder.Option 3: Use the REST API to view the storage format
You can also use the Confluence REST API to view the storage format of a single page in the browser.
You need two pieces of information to do that:
- your Confluence base address (examples: https://confluence.contoso.com, https://www.contoso.com/confluence)
- the page ID of the page to get the storage format for (example: 123212321)
Using above information you now build the REST API address using this pattern:
- CONFLUENCEBASEADDRESS/rest/api/content/REPLACEWITHPAGEID?expand=body.storage,version,container,history,history.lastUpdated,contributors,restrictions,permissions,ancestors&status=current
So, using the Confluence base address https://confluence.contoso.com and page ID 123212321 the address would look like this:
Paste this whole address into the address bar of a browser where you are already logged in to Confluence. This should show textual information about the page (in JSON format). It should contain the text "body":{"storage":{"value":".
When sending information to support, please provide the whole content shown by the browser.
4.2 - Get the SharePoint Storage Format
The SharePoint Storage Format is the technical under-the-hood view of a SharePoint page. It’s what WikiTraccs creates when performing the Confluence to SharePoint migration.
Use the REST API to view the storage format
You can use the SharePoint REST API to view the storage format of a single page in the browser.
You need the following information to do that:
- your SharePoint site address (example: https://contoso.sharepoint.com/sites/it-support)
- the item ID of the page to get the storage format for (example: 33) (Note: you get that item ID from the Site Pages library; find your page there and add the ID column to the current view, if necessary; the number shown there is the item ID)
- the title of the Site Pages library, in the site’s default language (examples: Site Pages (for English, note the space!), Websiteseiten (for German))
Note
You can figure out the page item ID by adding the ID column to any view of the Site Pages library.Using above information you now build the REST API address using this pattern:
SITEADDRESS/_api/web/lists/GetByTitle('SITEPAGESLIBRARYTITLE')/items(PAGEITEMID)
So, using example data from above the address would look like this:
https://contoso.sharepoint.com/sites/it-support/_api/web/lists/GetByTitle('Site Pages')/items(33)
Paste this whole address into the address bar of your browser where you are already logged in to SharePoint Online. This should show textual information about the page (in XML format). It should contain the text <d:CanvasContent1>.
When sending information to support, please provide the whole content shown by the browser.
Note about Site Pages Library title localization
Figuring out the title of the Site Pages library can be tricky when you are viewing the SharePoint site in a language that is not the default site language. The default site language is the language the site has been created in. When using the wrong title you’ll get the error List ‘…’ does not exist at site with URL. Ask the site owner for the site’s default language and use the localized title that matches this language instead.Cannot figure out the library title?
If you cannot figure out the right title of the Site Pages library, you can use its ID instead.
The address changes slightly and looks like this:
https://contoso.sharepoint.com/sites/it-support/_api/web/lists/GetById('d0dce654-b0b6-4cf6-b305-a83544aa5e10')/items(33)
The ID of the Site Page library is unique across site languages. To get the ID, open the Library Settings of the Site Pages library. Look at the browser address bar, which shows something like /_layouts/15/listedit.aspx?List=%7Bd0dce654-b0b6-4cf6-b305-a83544aa5e10%7D. The ID is enclosed in %7B and %7D, or { and }. Here it is d0dce654-b0b6-4cf6-b305-a83544aa5e10.
4.3 - Troubleshooting Template: Page Migration Result
This article is made to be linked to as part of a support case and short on purpose.
Send the Following Information
Send the following information to [email protected]:
- Screenshot of the Confluence page
- Screenshot of the SharePoint page
- Confluence page ID
- Storage format XML of the Confluence page
- Common log files of the migration run for the page in question
- What did you expect? What are you seeing instead?
In most cases, when the above information is available, the root cause can be identified and appropriate guidance provided.
Thank you.
5 - Troubleshooting FAQ
Why is there no visible progress?
Situation
You started the transformation, the console window of WikiTraccs is open and shows some log messages.
But then nothing happens anymore. No log messages appear in the console window, it just sits there.
Possible explanations
Maybe you did not select any spaces to migrate. Use the space inventory to select spaces. The console window will also contain hints like got no spaces to handle.
Another reason might be that during migration WikiTraccs got throttled by Microsoft 365. This can cause wait times of several minutes. Look for log messages indicating that throttling is happening.
6 - Support Options
What level of service can I expect?
The Wiki Transformation Project provides unrestricted break-fix support for all its offerings. Reported issues will be analyzed and addressed by implementing fixes or suggesting workarounds to minimize disruptions.
Support is best-effort based. You can typically expect a response within 24 hours on business days.
Once an issue with WikiTraccs has been identified, a fix is generally delivered within a few days. Actual turnaround time may vary depending on the complexity of the issue and whether it can be reproduced in a test environment. Take a look at the WikiTraccs release history for insights into the release cadence.
If response times are affected by external factors (such as company holidays or pandemics), it will be communicated via a pinned announcement in the respective GitHub issue list.
How to report an issue?
For non-confidential issues, use GitHub. Each GitHub repository provides a public issue tracker where all clients can chime in on issues and benefit from known resolutions. Find the link on the Contact page.
When reporting issues with confidential information, or sending log files, use the support email: [email protected].
Sharing larger files will be done via SharePoint Online. Support will provide you with a sharing link to a folder, where files can safely be stored.
Data location for both Exchange Online and SharePoint Online is Germany.
From which timezone will support be provided?
Support will be provided from Germany, and the timezone will either be CET (Central European Time, UTC+1) or CEST (Central European Summer Time, UTC+2) depending on the season.
Can we have a call?
I try to keep the communication asynchronous. This approach accommodates various time zones and busy schedules, ensuring efficient and flexible communication for all parties involved.
The usual process for issue resolution is as follows:
- You raise an issue via one of the aforementioned channels (GitHub, email).
- I’ll get back to you with questions, first ideas, links to the documentation, and will often ask for log files; either on the GitHub issue or via email.
- You test and get back to me with more information.
- <Steps 2 and 3 are repeated as necessary>
- The issue is resolved.
But if it becomes clear that we are progressing towards an unproductive back and forth, I’ll propose having a screensharing session to analyze the issue. A Microsoft Teams meeting link will be provided.
Is Microsoft Teams chat available as support channel?
No, please get in touch via [email protected].
How does trial mode support differ from licensed mode support?
Licensed customers are given priority, but beyond that, support for trial users is treated the same.
One of the big advantages of the trial model for both WikiTraccs and WikiPakk is that you can explore the full functionality before making a purchase. You can test everything to see if it fits your needs - and if you run into any issues during the trial, you’ll still get support.
The goal is to help you make an informed decision and feel confident that everything works as expected before buying a license.
Which areas are not covered?
If you need help with any of the following areas, I recommend involving a consultancy, as I do not cover these:
- M365 Architecture Consulting (Which M365 services are utilized? How many sites are required? What does the navigation within the intranet/knowledge base look like? Who has which permissions? How are groups managed? Where is metadata managed? …)
- Process Consulting (How is content published? Approval workflows? Document lifecycle? …)
- IT Strategy Consulting (How should multiple internal systems be consolidated, such as multiple CRMs, Confluence, Jira, Bitbucket, in-house developments, etc.? Decision between 1:1 migration vs. “reimagining in M365.” …)
- Use Case Mapping (How are use cases from Confluence mapped to SharePoint? Which M365 tools replace which Confluence macros (PnP Search, …)? …)
- Project Management
- Custom Script Development (PowerShell scripts for post-migration processing - although I collect these in the library if they are developed.)
- Implementation of Requirements for WikiTraccs (Requirements that could potentially block the migration project timeline; however, I always welcome feedback and suggestions, many of which have been incorporated into the product!)
How about general inquiries?
When you have general inquiries about using the tools for specific use cases, please get in touch. I’m interested in learning about your challenges and how each tool can be enhanced to better support you.
You can use the community options linked on the Contact page, or via the support email address. Please allow for a slightly longer response time for general inquiries as those will be processed two times a week.
7 - Error Messages
“Error while launching browser for login” (Google Chrome)
Variants:
- “Error while launching browser for login: One or more errors occurred. (Google Chrome not found in registry)”
Interaction leading to this error:
- selecting the Test connection button to test the connection to Confluence
Causes:
- Google Chrome is not installed
- Google Chrome is installed, but its executable could not be found at usual places
Solutions:
- Install Google Chrome
- Use the
ChromeBinaryPathsetting to manually configure the path to Chrome’s executable
“Error while launching browser for login” (Microsoft Edge)
Variants:
- “Error while launching browser for login: One or more errors occurred. (Microsoft Edge not found in registry)”
Interaction leading to this error:
- selecting the Test connection button to test the connection to Confluence
Causes:
- Microsoft Edge is not installed
- Microsoft Edge is installed, but its executable could not be found at usual places
Solutions:
- Install Microsoft Edge
- Use the
EdgeBinaryPathsetting to manually configure the path to Edge’s executable
8 - Common Warnings and Errors in Log Files
Errors
Recoverable error messages related to network connectivity
The following error messages might pop up in log files. Many errors are of temporary nature, for example many connection-related errors. WikiTraccs has retries built-in that can recover automatically.
Automatic recovery
WikiTraccs normally recovers automatically from all of the connection errors in this section by retrying what it was doing when hitting the error.[024 01:56:59 ERR MIG 123456789 sitename] [PnP.Framework] ExecuteQuery threw following exception: System.Net.WebException: The SSL connection could not be established, see inner exception.
---> System.Net.Http.HttpRequestException: The SSL connection could not be established, see inner exception.
---> System.IO.IOException: Unable to read data from the transport connection: Connection reset by peer.
---> System.Net.Sockets.SocketException (104): Connection reset by peer
--- End of inner exception stack trace ---
at System.Net.Sockets.Socket.AwaitableSocketAsyncEventArgs.ThrowException(SocketError error, CancellationToken cancellationToken)
at System.Net.Sockets.Socket.AwaitableSocketAsyncEventArgs.System.Threading.Tasks.Sources.IValueTaskSource<System.Int32>.GetResult(Int16 token)
at System.Net.Security.SslStream.<FillHandshakeBufferAsync>g__InternalFillHandshakeBufferAsync|189_0[TIOAdapter](TIOAdapter adap, ValueTask`1 task, Int32 minSize)
at System.Net.Security.SslStream.ReceiveBlobAsync[TIOAdapter](TIOAdapter adapter)
at System.Net.Security.SslStream.ForceAuthenticationAsync[TIOAdapter](TIOAdapter adapter, Boolean receiveFirst, Byte[] reAuthenticationData, Boolean isApm)
at System.Net.Http.ConnectHelper.EstablishSslConnectionAsync(SslClientAuthenticationOptions sslOptions, HttpRequestMessage request, Boolean async, Stream stream, CancellationToken cancellationToken)
Related to a previous connection error:
[004 02:10:12 WRN MIG 123456789 sitename] [https://contoso.atlassian.net/wiki] Got an error while provisioning pages and attachments: Value cannot be null. (Parameter 'clientObject') (this is try 1 of 4) | WikiTraccs.Console.Registries.ConfluenceContentRegistry
System.ArgumentNullException: Value cannot be null. (Parameter 'clientObject')
at Microsoft.SharePoint.Client.ClientRuntimeContext.Load[T](T clientObject, Expression`1[] retrievals)
at PnP.Framework.Provisioning.ObjectHandlers.ObjectFiles.CheckOutIfNeeded(Web web, File targetFile, Expression`1[] additionalRetrievals) in ...
[029 23:16:25 ERR MIG 123456789 sitename] [PnP.Framework] ExecuteQuery threw following exception: Microsoft.SharePoint.Client.ServerException: I/O error occurred.
at Microsoft.SharePoint.Client.ClientRequest.ProcessResponseStream(Stream responseStream)
at Microsoft.SharePoint.Client.ClientRequest.ProcessResponse()
at Microsoft.SharePoint.Client.ClientRequest.ExecuteQueryToServerAsync(ChunkStringBuilder sb)
at Microsoft.SharePoint.Client.ClientRequest.ExecuteQueryAsync()
at Microsoft.SharePoint.Client.ClientRuntimeContext.ExecuteQueryAsync()
at Microsoft.SharePoint.Client.ClientContext.ExecuteQueryAsync()
at Microsoft.SharePoint.Client.ClientContextExtensions.ExecuteQueryImplementation(ClientRuntimeContext clientContext, Int32 retryCount, String userAgent) in ClientContextExtensions.cs:line 191
ServerErrorCode: -1
ServerErrorTypeName: System.IO.IOException
ServerErrorTraceCorrelationId: c68a65a1-c094-a000-bb18-07fa16377196
ServerErrorValue:
ServerErrorDetails:
Additional info:
. 0ms | WikiTraccs.Console.Program
Above error might be followed by this one:
[006 23:16:25 WRN MIG 123456789 sitename] [https://contoso.atlassian.net/wiki] Got an error while provisioning pages and attachments: Value cannot be null. (Parameter 'clientObject') (this is try 1 of 4) | WikiTraccs.Console.Registries.ConfluenceContentRegistry
System.ArgumentNullException: Value cannot be null. (Parameter 'clientObject')
at Microsoft.SharePoint.Client.ClientRuntimeContext.Load[T](T clientObject, Expression`1[] retrievals)
at PnP.Framework.Provisioning.ObjectHandlers.ObjectFiles.CheckOutIfNeeded(Web web, File targetFile, Expression`1[] additionalRetrievals) in ObjectFiles.cs:line 287
You should see the following message after one of above messages: Waiting 0 sec before retrying the provisioning after error - WikiTraccs retries a couple of times which - unless network connectivity is completely lost - often works.
Warnings
Warnings related to links
Those messages are mostly caused by links to content that has been deleted or restricted. WikiTraccs finds those links and tries to look up the link target - a page, an attachment, a space, you name it. If it cannot access or find that content (and there is no way to tell the difference) it will surface in the log files.
Could not get page info from ID <snip>
Linked page '<page title>' could not be retrieved from Confluence
Info retrieved about linked page |spacekey|_|_|'Page Title'|vL|Page| is missing information needed to generate page file name: Id; cannot create link (might be missing page or no access)
A page could not be found for whatever reason.
Warnings related to missing images (mostly external)
'Image' has unexpected content type text/html
Most common cause: an external image is embedded on the page, but accessing this image requires logging in to the external system. WikiTraccs cannot do that.
When WikiTraccs tries to download that image, it will be presented with a login screen instead. This clearly is no image, but a HTML page. Thus the message.
The only way to get rid of this message is replacing the image in the source Confluence file by an image that doesn’t require authentication with an external system.
There is a difference in images between original (8) and transferred page (7).
Note: the numbers will be different, depending on the number of images in the Confluence page.
Most common cause: an external image could not be downloaded, or an image attachment is missing in Confluence. Those images most likely will also be shown as missing on the source Confluence page, indicated by the “broken image” symbol:
Probably nothing to do about that as the image is gone.
Cannot find stored attachment and/or container file name for 'ext-<snip>'
Most common cause: an external image could not be downloaded. This often happens for older Confluence pages that embed images from external web sites. Those sites vanish over the years, breaking the image link.
Nothing to do about that as the image is gone.
TaskCanceledException while downloading file via 'https://shop.contoso.com/wp-mediathek/ER99-navy-800x800.jpg': The request was canceled due to the configured HttpClient.Timeout of 12 seconds elapsing.
Note: the URL name will be different for you.
An external image could not be downloaded because the server did not answer in time. The image is probably gone and nothing can be done about that.
Tipp
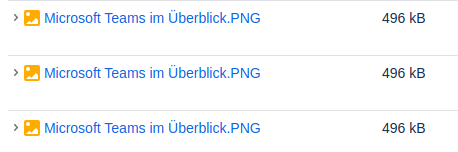
If you’ve got a lot of those external files with timeout and want to shorten the wait time - there is a configuration settting to do that. You can configure different timeouts for different domains. Have a look at theappsettings.json sample file and the ExternalDomains property: Configuration via Configuration File.There are multiple attachments with the same name 'Microsoft Teams im Überblick.PNG' on the page; returning the first one
Note: the file name will be different for you.
A Confluence page contains duplicate attachments. This cannot be transformed to SharePoint, so WikiTraccs chooses one of them. In Confluence, this might look like this:
One solution would be to remove those duplicates in Confluence and to migrate the page again.
Cannot determine target site for image attachment of page |spacekey|_|_|'Image file name.png'|vL|Page|; skipping
Note: the space key and file name will be different for you.
A page embeds an image form another page, and WikiTraccs cannot find the source page. The page might be missing or inaccessible.
Warnings related to attachments
Verification failed: Attachment file 'file.zip' is broken in SharePoint
Note: the file name will be different for you.
A file seemed broken or missing after uploading to SharePoint - this needs to be investigated as an attachment might be indeed broken or missing. One cause can be badly timed connection issues that leave the file in an intermediary state. WikiTraccs checks each file after upload to detect this condition and warns accordingly.
Note that there are some file types that are forbidden to be uploaded to SharePoint, like aspx and jar files.
The solution is to migrate the affected page again, which will also upload all of the page’s attachments.
Warnings related to Jira
[GetClientIdsAsync] Cancelling wait for jiraanywhere after 30 seconds
Trying to get information about a Jira macro time out. This might be a permission issue. When opening the Confluence page, you might see the timeout there as well.
Two options to work around that: increase the timeout and see if data is returned, or decrease the timeout as most successful data retrievals for Jira macros should return faster.
You can configure the timeout in appsettings.json: Snippet: Prevent WikiTraccs from reaching out to Jira.
Information messages of note
[THROTTLED] CSOM request frequency exceeded usage limits. Retry attempt 1. Sleeping for 500 milliseconds before retrying
Microsoft throttled the connection to SharePoint Online, telling WikiTraccs to slow down. WikiTraccs adheres to that.