Confluence migrations to SharePoint, as migrations in general, are rarely without issues.
WikiTraccs has been tested with Confluence instances of different versions and different ages and has been hardened against common issues. Some recurring issues like broken page content (from past migrations) or inaccessible external images are gracefully handled.
But what if something appears broken nevertheless?
This page shows how such issues can be diagnosed and which data WikiTraccs creates to help diagnosing a Confluence to SharePoint migration that appears stuck.
How should you handle migration issues related to SharePoint pages created by WikiTraccs?
The easiest way for you is to put all information in a zip file and send it via email to contact -at- wikitransformationproject.com. I’ll take a look.
My goal is to identify the issue, replicate it in a test environment and make adjustments so that the issue can never occur again.
WikiTraccs grows with every Confluence migrated, since each one is unique. My goal is to make this as painless for you as possible. You can help me helping you by providing as much information as possible to replicate the issue in a test environment, so I don’t have to bother you with more questions.
Of course you can also look at the log files. If there are connectivity issues, or authentication issues the error messages are usually pretty clear, hinting in the right direction.
Which information is available to diagnose issues?
WikiTraccs logs detailed information about everything that it’s doing.
Note
Please include as much of this information as possible when getting in touch. Every bit can help analyzing the situation and providing guidance.Here’s an overview of what is available and helpful for diagnosing issues, more details follow further down.
| What? | Where can I find it? | Why does it help? |
|---|---|---|
| Common log files | in WikiTraccs.GUI\logs or WikiTraccs.Console\logs (depending on whether you are running WikiTraccs.GUI.exe or WikiTraccs.Console.exe) | Contains detailed information about the whole migration process, including warnings and errors |
| Progress log files | in WikiTraccs.GUI\logs\<date-folder> or WikiTraccs.Console\logs\<date-folder> (depending on whether you are running WikiTraccs.GUI.exe or WikiTraccs.Console.exe) | Contains information about migrated and yet-to-be-migrated pages; see Monitoring Confluence to SharePoint Migration Progress for details |
| SharePoint Site Pages library | every target site for the migration contains information about migrated pages | Shows detailed information for every page migrated; see Measuring page migration success for details |
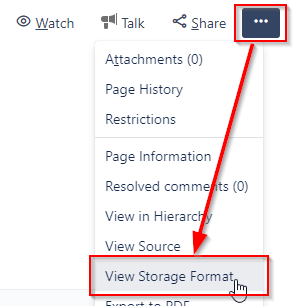
| Confluence page storage format | for any open Confluence page choose View Storage Format; note that the Confluence Source Editor plugin has to be installed for this option to be present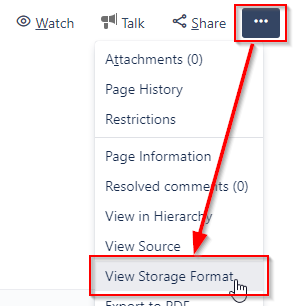 | Shows the page as WikiTraccs sees it; page structure and macros can be seen, analyzed and reproduced through a technical lens |
| Confluence page IDs and page titles of missing pages | open the page properties in Confluence for pages that did not migrate to SharePoint and look at the browser address bar - you see the page ID there; and the page title is the page title | the log files contain any errors that hinder migration and page IDs and titles help finding the right places in the log files |
Note
Log files can contain information relating to source and target environments, as well as content.
Examples are:
- Confluence source site URL
- Sharepoint target site URLs
- image URLs
- user names, email addresses, and IDs (e.g. when user mappings fail)
- snippets of content (e.g. when macro transformations fail)
Replace any content you aren’t willing to disclose before sending those files.
Common log files
Common log files cover information about the whole Confluence to SharePoint migration.
Where can I find those logs?
InWikiTraccs.GUI\logs or WikiTraccs.Console\logs (depending on whether you are running WikiTraccs.GUI.exe or WikiTraccs.Console.exe).Why are those files useful?
Common log files are useful to troubleshoot all issues, but are essential in root cause analysis when it’s still unclear where the issue originates.The log file names follow this pattern:
<date>-WikiTraccs.Console.log<date>-WikiTraccs.Console.WarningsAndErrors.log(note: as of WikiTraccs v1.22.1)<date>-WikiTraccs.GUI<date>.log
For each application run new log files are created. Here’s a sample logs folder:
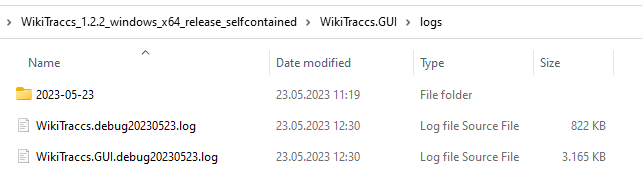
Note
The filename format changed slightly over time and might look different depending on the WikiTraccs release you use.The <date>-WikiTraccs.GUI...log (note the GUI part) log file is created when using the blue WikiTraccs.GUI window, for example when testing connections and filling the space inventory. This file is useful to troubleshoot connectivity and authentication issues.
The <date>-WikiTraccs.Console.log log file is created as soon as a migration starts and WikiTraccs.GUI opens the WikiTraccs.Console console window. Or when using WikiTraccs.Console standalone. This file is useful to troubleshoot issues that happen while migrating.
The <date>-WikiTraccs.Console.WarningsAndErrors.log log file contains only warnings and errors. Those can also be found in the <date>-WikiTraccs.Console.log log file, but are duplicated here for convenience.
Note
Make sure to choose the log files where the date and time corresponds to the date and time of the migration run(s) you’d like to diagnose. In general: the more logs, the better.Progress log files
Progress log files conver the page migration state for all spaces that are part of the migration.
Why are those files useful?
Progress log files are helpful for troubleshooting issues around Confluence pages that are expected to be migrated but are not.They are in detail covered in Monitoring Confluence to SharePoint Migration Progress.
SharePoint Site Pages library and page metadata
Once pages have been migrated you should scroll through the Site Pages library to see if there is anything of interest.
Why are screenshots useful?
Screenshots of this view can help diagnosing issues with single pages.This is described in detail in Measuring page migration success.
Specific issues and how to diagnose them
We’ll look at real-world issues and how to diagnose them.
Assume the following migration scenario:
- source environment: Confluence 6 at
http://localhost:8090/confluence, one space 7SE has been selected for migration in the space inventory - target environment: SharePoint Online site
https://contoso.sharepoint.com/sites/arc42-template - the migration is done via WikiTraccs.GUI
The migration is finished when the console window looks like this:

There is nothing left to migrate, the console window can be closed by pressing Ctrl+C.
Issue: Some pages are not migrated from Confluence to SharePoint
The progress log files should tell us more.
But first we look at a successful migration result, to establish a baseline.
Case 1: A successful migration of all pages
There should be 4 log files after successfully migrating one Confluence space:
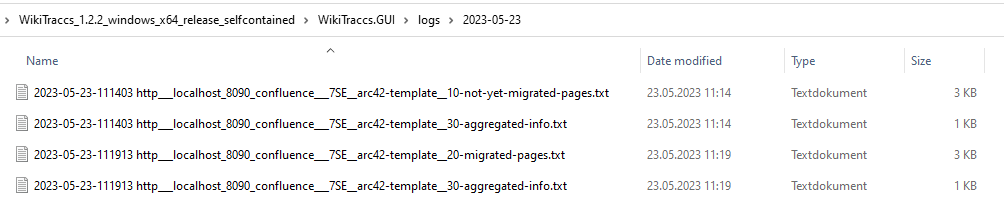
Of the four files, the first two were created before starting the migration. The last two files were created after having finished the migration.
Note
Keep an eye on the file’s timestamp to read them in the right order.Here’s the content of the […]aggregated-info.txt file that was created before migrating the Confluence space to SharePoint:
Source Confluence Site: http://localhost:8090/confluence/
Target SharePoint Site: https://contoso.sharepoint.com/sites/arc42-template
Space Key: 7SE
Blog posts included in migration and calculation: no
Confluence page count for space space 7SE: 32
Migrated SharePoint pages that correspond to found Confluence pages in space 7SE: 0
Migrated SharePoint pages overall for space 7SE: 0
Pages yet to be migrated for space 7SE: 32
This shows that WikiTraccs was able to retrieve information about 32 pages in this space and all have yet to be migrated.
Here’s the content of the second […]aggregated-info.txt file that was created after migrating the Confluence space to SharePoint:
Source Confluence Site: http://localhost:8090/confluence/
Target SharePoint Site: https://contoso.sharepoint.com/sites/arc42-template
Space Key: 7SE
Blog posts included in migration and calculation: no
Confluence page count for space space 7SE: 32
Migrated SharePoint pages that correspond to found Confluence pages in space 7SE: 32
Migrated SharePoint pages overall for space 7SE: 32
Pages yet to be migrated for space 7SE: 0
This time there are 32 migrated pages and there are none left to be migrated.
Success. Now we make it more complicated.
Case 2: Pages appear missing
Pages can appear missing when the migration account is not permitted to view all pages.
Here’s an example where a parent page of two child pages has been view-restricted to only the admin account:
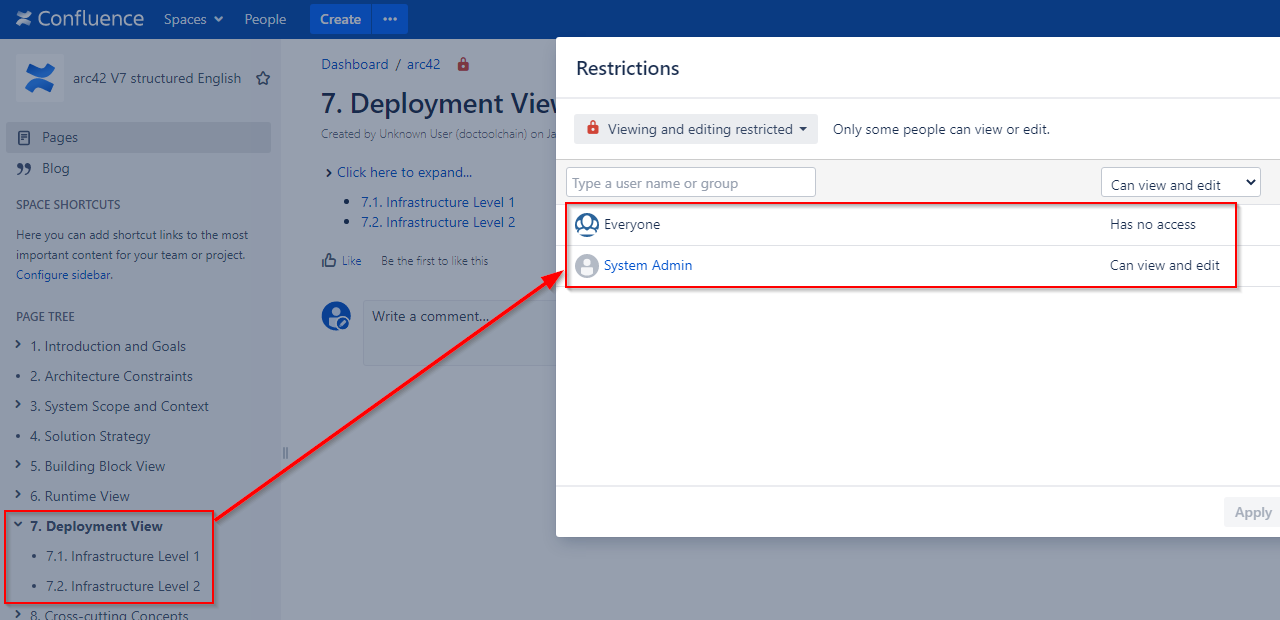
Now, when using another Confluence account as migration account, this account won’t see those three pages.
Thus (after deleting all previously created SharePoint pages and starting a new migration) the […]aggregated-info.txt file looks like this:
Source Confluence Site: http://localhost:8090/confluence/
Target SharePoint Site: https://heinrichulbricht.sharepoint.com/sites/arc42-template
Space Key: 7SE
Blog posts included in migration and calculation: no
Confluence page count for space space 7SE: 29
Migrated SharePoint pages that correspond to found Confluence pages in space 7SE: 0
Migrated SharePoint pages overall for space 7SE: 0
Pages yet to be migrated for space 7SE: 29
Only 29 pages are reported for the space that has in fact 32 pages. But 3 of those cannot be seen by the migration account.
The solution in this case is simple: use a migration account that can access all pages that should be migrated.
Case 3: Pages are missing, even after checking permissions
This could be anything, but it should be visible in the log files.
Please send me the log files and page IDs and ideally page titles of pages you’d expect to migrate from Confluence to SharePoint. This information should help to locate any errors related to those pages in the log files.
Please send information via email to contact -at- wikitransformationproject.com.
Issue: The progress bar in WikiTraccs.GUI is stuck
This is caused by pages that have been migrated before and have been updated in Confluence since. It should only happen when migrating the same space at least twice.
The pages that need to be updated can be seen in the progress log files.
The “update mode” feature request is tracked here: Add update mode for already migrated pages.
Technically everything is correct. You need to delete the SharePoint files you want to update, before starting another migration to have them created again.
Issue: The migrated Confluence page doesn’t look good in SharePoint (visual check)
The layout is off? Content is missing? Macros are missing?
There are probably thousands of special cases that can affect the Confluence page migration to SharePoint, hundreds of which are already handled by WikiTraccs.
If there is something wrong with the resulting page please use the options under Contact to get in touch.
Important note about missing macros
Many macros cannot be represented in SharePoint. So they are expected to be missing.
Here’s a primer on what to expect regarding macros: What about those Confluence Macros?
Here’s a list of macros and how they are handled by WikiTraccs: Known Confluence Macros.
Please open a support ticket with a feature request for macros you’d like to see migrated from Confluence to SharePoint. Please also include a description of your use case and a basic idea or mockup of how the migration result in SharePoint should look like.
Please provide the following for your request to be properly handled:
- Confluence version
- a screenshot of the source Confluence page
- a screenshot of the SharePoint page, with the unexpected parts highlighted
- the storage format of the source Confluence page - see Get the Confluence Storage Format for instructions on how to get that
- the page ID and title of the source Confluence page
- SharePoint page metadata for the affected page, like WT: Text Transferred Percent, WT: Failed Transformations and (most important) WT: Transformation Log (a screenshot is fine, see next section for a sample)
Please report issues via email to contact -at- wikitransformationproject.com.
Issue: The SharePoint page metadata shows Transformation Errors and/or a Text Transferred value that is not equal to 100%
WikiTraccs tracks its migration success per page. It has hundreds of transformation rules built-in.
If WikiTraccs discoveres a new layout or macro it cannot handle, it’ll raise a flag by counting the Transformation Errors or potentially missing text.
Here’s a sample screenshot of such an issue, where certain XML tags caused problems, leading to text being skipped:
Note
Please check the affected pages. Sometimes there is one type of macro causing issues technically for many pages, but it doesn’t make a difference visually. So while it would be nice for WikiTraccs to be less error-y in its messaging the migration result is fine.
Please add information about whether you’ve got a blocking issue or whether you are just raising awareness, when getting in touch.
To diagnose those issues the same information as in the previous section Issue: The migrated Confluence page doesn’t look good in SharePoint is needed. The most important part is the storage format because this hopefully allows to replicate and isolate the issue in a test environment.
Please report issues via email to contact -at- wikitransformationproject.com.